











Die Entwicklung von Software für die Cloud erfordert eine Veränderung des Denkens. Traditionelle monolithische Architekturen basierten auf eng miteinander verbundenen Komponenten, die sich Speicher und lokale Dateisysteme teilen. Cloudbasierte Anwendungen hingegen arbeiten in verteilten Umgebungen, die häufig mehrere Netzwerke und Sicherheitsgrenzen überschreiten. Um diese Komplexität zu bewältigen, benötigen Ingenieure klare visuelle Darstellungen, wie Informationen durch das System fließen. Hier kommt das Datenumlaufdiagramm (DFD) als unverzichtbares Werkzeug ins Spiel. Indem es den Datenfluss zwischen Prozessen, Speichern und externen Entitäten abbildet, können Teams robuste, skalierbare und sichere Systeme gestalten, ohne auf Vermutungen angewiesen zu sein.
Diese Anleitung untersucht, wie DFD-Prinzipien speziell für cloudbasierte Kontexte angewendet werden können. Wir werden die zentralen Komponenten, die notwendigen Anpassungen für verteilte Systeme sowie die praktischen Schritte zur Erstellung von Diagrammen betrachten, die auch bei sich verändernder Infrastruktur nützlich bleiben. Unabhängig davon, ob Sie ein Mikroservices-Ökosystem oder eine serverlose Funktionskette entwerfen – das Verständnis des Datenflusses bildet die Grundlage zuverlässiger Ingenieurarbeit.
🌩️ Verständnis der Verschiebung hin zu cloudbasiertem Modellieren
In einer traditionellen On-Premise-Umgebung existiert ein System oft innerhalb einer einzigen physischen Grenze. Daten fließen lokal zwischen Prozessen. In einer cloudbasierten Umgebung sind die Grenzen fließend. Eine einzelne logische Anwendung kann aus Dutzenden unabhängiger Dienste bestehen, die in Containern laufen und über verschiedene Regionen oder Verfügbarkeitszonen orchestriert werden. Die Netzwerklatenz, die eventuelle Konsistenz und die Sicherheitsrichtlinien führen Variablen ein, die in monolithischen Designs nicht existieren.
Beim Erstellen eines Datenumlaufdiagramms für diese Umgebung müssen Sie berücksichtigen:
- Netzwerkgrenzen:Daten fließen häufig über öffentliche Netzwerke oder sichere VPCs. Jeder Sprung stellt einen potenziellen Ausfallpunkt oder eine Latenz dar.
- Zustandsverwaltung:Cloud-Dienste sind oft zustandslos. Prozesse müssen den Zustand aus externen Speichern abrufen, anstatt ihn im Speicher zu halten.
- Asynchrone Kommunikation:Synchronisierte Aufrufe (Anfrage-Antwort) sind nicht immer die beste Wahl. Nachrichtenwarteschlangen und Ereignisströme verändern, wie Daten zwischen Komponenten fließen.
- Sicherheitszonen:Daten, die eine Perimetergrenze betreten, müssen authentifiziert und verschlüsselt werden, bevor sie interne Prozesse erreichen.
Die frühzeitige Visualisierung dieser Einschränkungen verhindert architektonisches Verschuldung. Ein Diagramm, das die Netzwerktrennung oder die Anforderungen an zustandslose Systeme ignoriert, führt zu einem System, das schwer zu debuggen und zu skalieren ist. Das Ziel besteht nicht nur darin, zu zeigen, wohin Daten fließen, sondern auch darauf hinzuweisen, wo sie transformiert, gespeichert und geschützt werden.
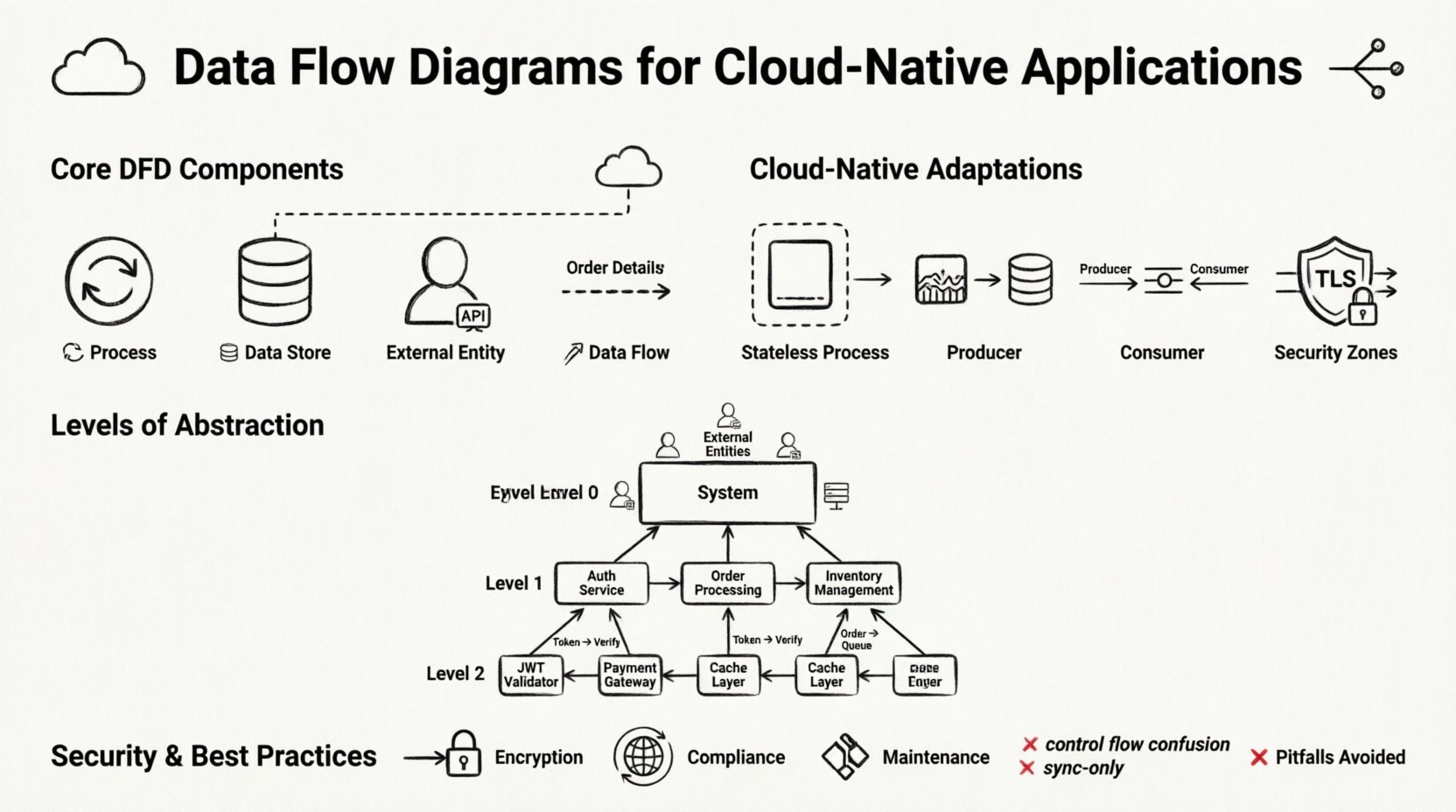
🧩 Kernkomponenten eines Datenumlaufdiagramms
Bevor wir diese Diagramme für die Cloud anpassen, müssen wir die Standardbausteine festlegen. Ein DFD ist kein Flussdiagramm; er zeigt keine Steuerlogik oder Zeitabläufe. Er zeigt die Bewegung von Daten. Die vier Hauptelemente bleiben auch in verteilten Systemen konstant.
1. Prozesse 🔄
Ein Prozess stellt eine Aktivität dar, die Eingabedaten in Ausgabedaten umwandelt. In einem cloudbasierten Kontext ist ein Prozess oft eine Funktion, eine containerisierte Anwendung oder eine Instanz eines Mikroservices. Es ist wichtig, Prozesse danach zu benennen, was sie tun, nicht danach, wie sie technisch heißen. Zum Beispiel sollte statt „UserService API“ „Benutzerberechtigungen überprüfen“ verwendet werden. Dadurch bleibt das Diagramm auf die Logik der Datenumwandlung fokussiert.
- Transformation:Jeder Prozess muss die Daten auf irgendeine Weise verändern. Wenn Daten ohne Änderung durchlaufen, sollte dies nicht als Prozess dargestellt werden.
- Kapselung:In Mikroservices ist jeder Prozess gekapselt. Die interne Logik bleibt verborgen; für das Diagramm sind nur die Eingabe- und Ausgabeschnittstellen relevant.
- Zustandslosigkeit:Die meisten cloudbasierten Prozesse sind flüchtig. Sie behalten kein Gedächtnis an frühere Interaktionen. Dies muss in den Anforderungen des Datenflusses berücksichtigt werden.
2. Datenbanken 🗄️
Ein Datenbank stellt einen Ort dar, an dem Daten ruhen, während sie nicht verarbeitet werden. In der Cloud könnte dies eine relationale Datenbank, ein NoSQL-Dokumentenspeicher, ein Objektspeicherbucket oder ein verteilter Cache sein. Im Gegensatz zu einem Dateisystem werden Cloud-Datenbanken oft über ein Netzwerk zugegriffen.
- Dauerhaftigkeit:Daten müssen in einem Speicher gespeichert werden, wenn sie einen Prozessfehler oder einen Neustart überstehen sollen.
- Zugriffsmuster: Leseintensive Speicher unterscheiden sich von schreibintensiven Speichern. Das Diagramm sollte den Zugriffstyp angeben, wenn er die Architektur erheblich beeinflusst.
- Sicherheit:Sensible Datenspeicher erfordern unterschiedliche Zugriffssteuerungen. Diese Unterscheidung ist für Sicherheitsprüfungen entscheidend.
3. Externe Entitäten 👥
Externe Entitäten sind Quellen oder Ziele von Daten außerhalb der Systemgrenze. Dazu können menschliche Benutzer, Drittanbieter-APIs, veraltete Systeme oder Hardwaregeräte gehören. In einem cloud-nativen Diagramm stellen externe Entitäten oft die Grenze des Internets oder anderer Cloud-Dienste dar.
- Vertrauenswürdig gegenüber Unvertrauenswürdig:Unterscheide zwischen Daten, die von einem bekannten internen Dienst stammen, und öffentlichem Internetverkehr.
- Auslösen:Entitäten lösen den Fluss oft aus. Eine Benutzeranfrage löst einen Prozess aus; ein geplanter Job löst eine Daten-Synchronisierung aus.
4. Datenflüsse 📡
Datenflüsse sind die Pfeile, die die Komponenten verbinden. Sie stellen die Übertragung von Daten dar. In Cloud-Umgebungen durchlaufen diese Flüsse oft Netzwerke. Beschriftungen auf den Pfeilen sind entscheidend. Sie sollten das Datenpaket beschreiben, nicht das Protokoll. Beispielsweise sollte der Pfeil mit „Bestelldetails“ beschriftet werden, anstatt mit „HTTP POST“. Dadurch bleibt das Diagramm protokollunabhängig und zukunftssicher.
- Richtungsabhängigkeit:Flüsse sind einseitig. Wenn Daten hin und her bewegt werden, zeichnen Sie zwei separate Pfeile.
- Volumen:Hochvolumige Datenflüsse erfordern möglicherweise eine andere Infrastruktur (z. B. dedizierte Bandbreite) im Vergleich zu niedrigvolumigen Steuerflüssen.
- Verschlüsselung:Flüsse, die Sicherheitsgrenzen überschreiten, müssen als verschlüsselt gekennzeichnet werden, um die Compliance-Anforderungen hervorzuheben.
☁️ Anpassen von DFDs für verteilte Systeme
Standard-DFDs gehen von einem zusammenhängenden System aus. Cloud-native Systeme sind verteilt. Um ein DFD in diesem Kontext nützlich zu machen, müssen Sie die verteilte Natur der Infrastruktur explizit modellieren. Dazu gehören abstrakte Ebenen, die Netztopologie und Dienstgrenzen darstellen.
Dienstgrenzen
Microservices sind die Standardbausteine cloud-nativer Anwendungen. Jeder Dienst sollte idealerweise als ein eigenständiger Prozess in Ihrem Diagramm dargestellt werden. Allerdings kann die Darstellung jedes einzelnen Dienstes zu Überladung führen. Ein verbreiteter Ansatz besteht darin, verwandte Dienste in einem logischen Bereich zusammenzufassen, beispielsweise „Rechnungsstellungsbereich“ oder „Benutzerverwaltungs-Bereich“. Dadurch können Sie den Überblick über den Hoch-Level-Fluss behalten, während die interne Komplexität verborgen bleibt.
API-Gateways
Die meisten cloud-nativen Anwendungen befinden sich hinter einem API-Gateway oder Lastverteilungs-Server. Dieses Komponente fungiert als einziger Einstiegspunkt. In einem DFD ist der Gateway ein Prozess, der Anfragen weiterleitet. Er verarbeitet Authentifizierung, Rate Limiting und Protokollübersetzung. Behandeln Sie den Gateway nicht wie eine einfache Leitung; er verändert den Datenfluss aktiv.
Ereignisgesteuerte Architekturen
Viele moderne Systeme verwenden ereignisgesteuerte Muster. Ein Produzent erzeugt ein Ereignis, das ein Verbraucher später verarbeitet. Dadurch wird die synchrone Verbindung zwischen Prozess und Datenfluss aufgehoben. In einem DFD stellen Sie dies durch eine Ereigniswarteschlange oder -strömung als Datenspeicher dar. Der Produzent schreibt das Ereignis; der Verbraucher liest es. Diese Entkopplung ist entscheidend für Resilienz.
| Komponente | Traditionelles Monolith | Cloud-native Anpassung |
|---|---|---|
| Prozess | Funktion im Speicher | Containerisierte Microservice / serverlose Funktion |
| Datenbank | Lokale Datei / SQL-Datenbank | Verwaltete Cloud-Datenbank / Objektspeicher |
| Fluss | Aufruf des lokalen Speichers | HTTP / gRPC / Nachrichtenwarteschlange |
| Zustand | Geteilter Speicher | Extern verwalteter Zustandspeicher |
📉 Ebenen der Abstraktion in der Cloud-Architektur
Komplexe Systeme erfordern mehrere Ebenen von Diagrammen. Versuche, alle Details in einer einzigen Ansicht zu erfassen, führen zu Verwirrung. Der Standard-DFD-Ansatz mit den Ebenen 0, 1 und 2 funktioniert gut für Cloud-Systeme, wenn er korrekt angewendet wird.
Ebene 0: Kontextdiagramm
Das Kontextdiagramm zeigt das gesamte System als einen einzigen Prozess. Es hebt die externen Entitäten hervor, die mit dem System interagieren. Bei einer Cloud-Anwendung definiert dies die Grenzen. Es beantwortet die Frage: „Was tritt in das System ein, und was verlässt es?“ Dies ist die höchste Abstraktionsebene und nützlich für Stakeholder, die den Umfang verstehen müssen, ohne technische Details zu kennen.
- Schwerpunkt: Systemgrenzen und externe Schnittstellen.
- Detail: Minimal. Ein zentraler Prozess.
- Anwendungsfall: Definition des Projektumfangs und strategische Sicherheitsplanung.
Ebene 1: Hauptprozesse
Ebene 1 zerlegt den zentralen Prozess in Hauptunterprozesse. Im Kontext von Cloud-Native-Systemen sind dies typischerweise die wichtigsten funktionalen Bereiche. Ein Beispiel für ein Diagramm der Ebene 1 bei einer E-Commerce-Plattform könnte „Auftragsbearbeitung“, „Bestandsverwaltung“ und „Zahlungsabwicklung“ als getrennte Prozesse zeigen. Diese Ebene zeigt auf, wie Daten zwischen den Hauptdienstgruppen fließen.
- Schwerpunkt: Hauptfunktionsmodule und ihre Wechselwirkungen.
- Detail: Eingaben und Ausgaben für jedes Hauptmodul.
- Anwendungsfall: Architekturreview und Dienstdekomposition.
Ebene 2: Detaillierte Logik
Ebene 2 geht auf spezifische Unterprozesse ein. Hier werden die technischen Implementierungsdetails relevant. Zum Beispiel könnte der Prozess „Zahlungsabwicklung“ erweitert werden, um „Karte überprüfen“, „Konto belasten“ und „Quittung aktualisieren“ anzuzeigen. Diese Ebene wird von Entwicklern genutzt, die bestimmte Dienste implementieren.
- Schwerpunkt: Interne Logik spezifischer Dienste.
- Detail: Spezifische Datenumformungen und lokale Datenbanken.
- Anwendungsfall: Entwicklungsimplementation und Test-Szenarien.
🔒 Sicherheit und Compliance bei der Datenzuordnung
Sicherheit ist bei der Entwicklung von Cloud-nativen Anwendungen kein nachträglicher Gedanke; sie ist eine Designanforderung. Ein Datenflussdiagramm ist ein hervorragendes Werkzeug zur Identifizierung von Sicherheitsrisiken. Indem Sie den Pfad der Daten verfolgen, können Sie erkennen, wo sensible Informationen preisgegeben oder unsachgemäß gespeichert werden könnten.
Identifizierung sensibler Daten
Nicht alle Datenflüsse sind gleich. Persönliche Identifikationsdaten (PII), Finanzdaten und Gesundheitsinformationen erfordern eine strengere Behandlung. Markieren Sie in Ihrem Diagramm die Flüsse, die sensible Daten enthalten. Dadurch wird sichergestellt, dass jeder Prozess, der mit diesen Daten interagiert, auf Compliance überprüft wird.
- Verschlüsselung im Transit: Flüsse, die Netzwerkgrenzen überschreiten, müssen verschlüsselt werden (TLS/SSL). Markieren Sie diese Flüsse deutlich.
- Verschlüsselung im Ruhezustand: Datenbanken, die sensible Informationen enthalten, müssen verschlüsselt werden. Kennzeichnen Sie dies im Datenbanklabel.
- Zugriffssteuerung: Identifizieren Sie, welche Prozesse berechtigt sind, bestimmte Datenbanken zu lesen oder zu schreiben. Dies hilft bei der Einrichtung einer rollenbasierten Zugriffssteuerung (RBAC).
Compliance-Grenzen
Verschiedene Regionen haben unterschiedliche Gesetze zur Datenhoheit. Daten könnten innerhalb einer bestimmten geografischen Grenze verbleiben müssen. Ein DFD hilft dabei, diese Beschränkungen zu visualisieren. Wenn ein Prozess in Region A Daten an Region B sendet, sollte dieser Fluss für eine rechtliche Überprüfung markiert werden. Dadurch werden versehentliche Verstöße gegen Vorschriften wie die DSGVO oder CCPA verhindert.
⚠️ Häufige Fehler und wie man sie vermeidet
Die Erstellung von DFDs für Cloud-Systeme ist herausfordernd. Es gibt häufige Fehler, die Teams machen, oft, weil sie alte Muster in neue Umgebungen übertragen. Das Vermeiden dieser Fehler stellt sicher, dass Ihre Diagramme genau und nützlich bleiben.
1. Vermischung von Steuerungs- und Datenfluss
DFDs sollten keine Steuerungslogik zeigen. Zeichnen Sie keine Pfeile, um „wenn dies, dann jenes“ anzugeben. Verwenden Sie Entscheidungspunkte oder externe Notizen für Logik, halten Sie die Pfeile aber auf die Datenbewegung fokussiert. In Cloud-Systemen, wo die Steuerungslogik oft von Orchestrierungsplattformen behandelt wird, sollte das DFD sich auf den Payload konzentrieren.
2. Ignorieren asynchroner Flüsse
Cloud-Systeme sind selten zu 100 % synchron. Aufträge laufen im Hintergrund. Wenn Sie nur synchrone Anfrage-Antwort-Flüsse zeichnen, wird Ihr Diagramm unvollständig sein. Fügen Sie immer Hintergrundjobs und Ereignisströme als Datenflüsse in oder aus Datenbanken hinzu.
3. Überoptimierung für spezifische Werkzeuge
Entwerfen Sie Ihr Diagramm nicht auf Basis der Fähigkeiten eines bestimmten Werkzeugs oder Plattform. Wenn Sie eine bestimmte Datenbank oder einen bestimmten Nachrichtenbroker wählen, könnte das Diagramm obsolet werden, wenn Sie die Technologien wechseln. Konzentrieren Sie sich auf den logischen Datenfluss, nicht auf die physische Implementierung.
4. Vernachlässigung von Fehlerflüssen
Erfolgreiche Pfade sind leicht zu zeichnen. Fehlerpfade sind schwieriger, aber notwendig. In einer Cloud-Umgebung fallen Dienste häufig aus. Kennzeichnen Sie, wo Fehlerdaten protokolliert werden oder wo Wiederholungsmechanismen ausgelöst werden. Dies hilft bei der Gestaltung robuster Überwachungs- und Alarmierungssysteme.
🔄 Pflege von Diagrammen im Laufe der Zeit
Ein Diagramm ist nur dann nützlich, wenn es genau ist. Cloud-native Anwendungen ändern sich schnell. Neue Dienste werden hinzugefügt, alte werden abgeschaltet, und Datenmodelle entwickeln sich weiter. Wenn das Diagramm nicht mit dem laufenden System übereinstimmt, wird es irreführende Dokumentation. Hier ist, wie Sie sie pflegen.
- Versionskontrolle:Behandle Diagramme wie Code. Speichere sie zusammen mit deinem Anwendungscode in deinem Versionskontrollsystem. Dadurch wird die Historie und Nachvollziehbarkeit gewährleistet.
- Überprüfungszyklen:Integriere Diagramm-Updates in deinen Code-Review-Prozess. Wenn ein Entwickler einen Datenfluss ändert, sollte das Diagramm in derselben Commit- oder Pull-Request-Aktion aktualisiert werden.
- Automatisierte Generierung:Generiere Diagramme, wo immer möglich, direkt aus dem Code oder den Infrastructure-as-Code-Definitionen. Dadurch wird die Lücke zwischen Dokumentation und Realität verkleinert.
- Abstimmung mit Stakeholdern:Bespreche die Diagramme regelmäßig mit nicht-technischen Stakeholdern. Dadurch wird sichergestellt, dass das Abstraktionsniveau für die Zielgruppe angemessen bleibt.
📋 Vergleich von DFDs mit anderen architektonischen Ansichten
Es ist üblich, DFDs mit anderen Diagrammen wie Ablaufdiagrammen oder Systemarchitekturdiagrammen zu verwechseln. Das Verständnis der Unterschiede hilft dir, das richtige Werkzeug für die Aufgabe zu wählen.
| Diagrammtyp | Hauptfokus | Am besten geeignet für |
|---|---|---|
| Datenflussdiagramm | Datenbewegung und -transformation | Systemdesign, Sicherheitsüberprüfungen, Datenzuordnung |
| Ablaufdiagramm | Zeitbasierte Interaktion zwischen Objekten | API-Integration, Debugging von Aufrufketten |
| Systemarchitektur | Infrastruktur und Bereitstellung | DevOps, Skalierung, Hardwareanforderungen |
| Entität-Beziehung | Datenstruktur und Beziehungen | Datenbankdesign, Schema-Planung |
Ein DFD ergänzt diese Ansichten. Während ein Architekturdiagramm zeigt, wo Server lokalisiert sind, zeigt ein DFD, wie Informationen zwischen ihnen fließen. Während ein Ablaufdiagramm die Reihenfolge der Aufrufe zeigt, zeigt ein DFD den Payload. Die Kombination dieser Ansichten liefert ein vollständiges Bild des Systems.
🚀 Zukünftige Trends im Cloud-Modellieren
Mit der Entwicklung von Cloud-Technologien ändern sich auch die Anforderungen an das Modellieren. Der Aufstieg von serverlosen Computing- und Edge-Computing-Lösungen bringt neue Herausforderungen mit sich. Datenflüsse werden zunehmend dezentraler. Prozesse laufen näher am Benutzer. Dieser Wandel erfordert, dass DFDs Edge-Knoten und temporäre Rechenressourcen berücksichtigen.
Zusätzlich bringt die Integration von künstlicher Intelligenz in Workflows zusätzliche Komplexität mit sich. KI-Modelle verarbeiten Daten und erzeugen Erkenntnisse. Diese Prozesse erfordern oft große Datensätze und spezialisierte Hardware. Zukünftige DFDs müssen diese rechenintensiven Prozesse und die Datenpfade, die sie versorgen, darstellen. Die Grundprinzipien bleiben gleich, aber die Granularität und der Umfang werden sich erweitern.
Indem man sich an die Grundlagen von Datenflussdiagrammen hält und sich den Realitäten der Cloud anpasst, können Ingenieurteams Systeme entwickeln, die transparent, sicher und skalierbar sind. Die Visualisierung von Daten ist nicht nur eine Dokumentationsaufgabe; sie ist ein entscheidender Schritt im Gestaltungsprozess, der Fehler verhindert, bevor sie in die Produktion gelangen.