











In der modernen Softwarearchitektur ist die Verschiebung von monolithischen Strukturen hin zu verteilten Systemen eine häufige Entwicklung. Organisationen beginnen oft mit einer einheitlichen Codebasis und einer zentralen Datenbankstruktur. Im Laufe der Zeit entstehen durch diese Struktur Engpässe. Das Entitäts-Beziehungs-Diagramm (ERD), das einst als klares Bauplan für die Anwendung diente, wird zu einem komplexen Netzwerk von Abhängigkeiten. Die Umwandlung dieses monolithischen ERD in eine Grundlage für ein modulares Service-Mesh erfordert sorgfältige Planung, technische Disziplin und ein klares Verständnis der Daten-Grenzen. Dieser Leitfaden untersucht die praktischen Schritte, Herausforderungen und architektonischen Entscheidungen, die bei dieser Transformation berücksichtigt werden müssen.
Architektur geht nicht nur darum, Code zu verschieben; es geht darum, die Datenverantwortung zu verlegen. Wenn ein ERD monolithisch ist, verweisen Tabellen oft über funktionale Bereiche hinweg aufeinander. Eine einzelne Abfrage könnte fünf verschiedene Tabellen durchlaufen, die unterschiedlichen Geschäftseinheiten entsprechen. Diese enge Kopplung macht eine unabhängige Bereitstellung unmöglich. Durch die Aufteilung dieses Diagramms und die Ausrichtung an einem Service-Mesh können Teams Isolation und Skalierbarkeit erreichen. Die folgenden Abschnitte erläutern die Methode, die zur Durchführung dieser Umstellung ohne Abhängigkeit von spezifischen Anbieterwerkzeugen eingesetzt wird.
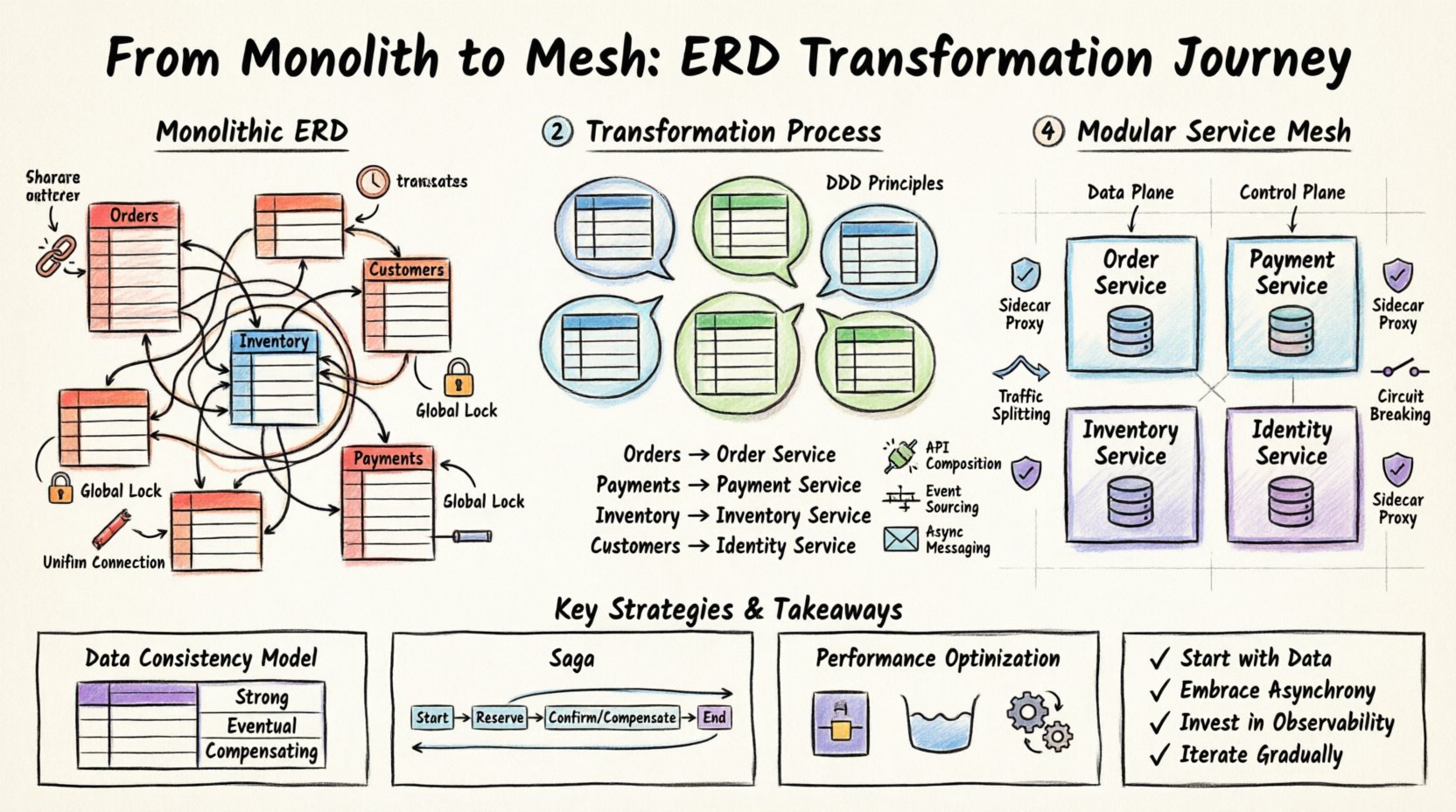
🏗️ Verständnis des Ausgangspunkts: Das monolithische ERD
Bevor Änderungen vorgenommen werden, muss der aktuelle Zustand vollständig verstanden werden. Ein monolithisches ERD zeigt typischerweise Merkmale, die auf eine hohe Kopplung hinweisen. Zu diesen Merkmalen gehören:
- Gemeinsame Fremdschlüssel:Tabellen in verschiedenen Modulen verweisen auf dieselben eindeutigen Kennungen, was direkte Abhängigkeiten erzeugt.
- Große Transaktionsblöcke:Datenbanktransaktionen erstrecken sich über mehrere Tabellen, die logisch unterschiedlichen Geschäftskontexten zugeordnet sind.
- Globale Schema-Sperren:Schema-Änderungen erfordern Ausfallzeiten oder komplexe Migrations-Skripte, die die gesamte Anwendung betreffen.
- Einheitliche Verbindungspools:Die Anwendung teilt sich einen einzigen Pool von Datenbankverbindungen, was die Konkurrenzfähigkeit für bestimmte hochbelastete Funktionen einschränkt.
Die Visualisierung dieser Struktur offenbart oft ein „Spaghetti“-Muster im Diagramm. Linien verbinden Tabellen über die gesamte Anordnung hinweg, was darauf hindeutet, dass kein einzelner Bestandteil selbstständig ist. Bei einem serviceorientierten Ansatz müssen diese Verbindungen getrennt oder abstrahiert werden. Ziel ist es, festzustellen, wo die Daten liegen und wer sie besitzen sollte.
🧩 Definition von begrenzten Kontexten
Der Kern der Transformation liegt in den Prinzipien des domain-driven Designs (DDD). Sie müssen begrenzte Kontexte innerhalb des monolithischen ERD identifizieren. Ein begrenzter Kontext ist eine spezifische Grenze, innerhalb derer ein bestimmtes Domänenmodell gilt. Im Kontext eines ERD bedeutet dies, Tabellen zu gruppieren, die logisch zusammengehören.
Um dies zu erreichen, führen Sie eine Datenstamm-Analyse durch. Verfolgen Sie, wie Daten von der Erstellung bis zur Nutzung fließen. Stellen Sie die folgenden Fragen:
- Welche Tabellen werden durch denselben Geschäftsprozess aktualisiert?
- Welche Tabellen werden von bestimmten Benutzerrollen häufig gelesen?
- Welche Beziehungen stellen eine „hat-ein“- oder „gehört-zu“-Beziehung dar, die über funktionale Grenzen hinweggeht?
Sobald diese Gruppen identifiziert sind, weisen Sie sie spezifischen Service-Grenzen zu. Dieser Prozess ist nicht immer ein-eins-zu-eins. Mehrere Tabellen können einer einzelnen Dienstleistung zugeordnet sein, während eine einzelne Tabelle auf mehrere Dienste aufgeteilt werden kann, wenn die Daten-Nutzungsmuster sich signifikant unterscheiden.
Beispiel: Aufteilungsstrategie
Betrachten Sie eine Situation, in der das ERD eine riesigeBestellungenTabelle enthält, die mitKunden, Lagerbestand, undZahlungen. In einem Monolithen ist dies eine Tabelle. In einem modularen System werden diese zu eigenständigen Entitäten.
| Monolithische Entität | Vorgeschlagene Dienstgrenze | Begründung |
|---|---|---|
Bestellungen (Haupt) |
Bestellungs-Dienst | Die primäre Geschäftslogik befindet sich hier. |
Zahlungen |
Zahlungs-Dienst | Erfordert unterschiedliche Sicherheits- und Compliance-Standards. |
Lagerbestand |
Lagerbestands-Dienst | Erfordert hohe Verfügbarkeit und unterschiedliche Sperrstrategien. |
Kunden |
Identitäts-Dienst | Wird über mehrere Domänen hinweg gemeinsam genutzt, erfordert Zentralisierung. |
🔄 Umstrukturierung von Datenbeziehungen
Sobald Dienste definiert sind, müssen die Beziehungen im ERD geändert werden. In einem Monolithen sorgt eine Fremdschlüsselbeschränkung für Datenintegrität. In einem verteilten System ist die Durchsetzung von Fremdschlüsseln über Netzwerkgrenzen hinweg ineffizient und anfällig für Fehler. Stattdessen werden Beziehungen über Anwendungslogik und Nachrichtenverkehr verwaltet.
Dieser Wandel erfordert die Einführung spezifischer Muster, um Konsistenz zu gewährleisten:
- API-Zusammensetzung:Dienste stellen APIs bereit, die zusammengefasste Daten zurückgeben und interne Datenbankstrukturen verbergen.
- Ereignisquellen:Zustandsänderungen werden als Folge von Ereignissen aufgezeichnet. Dienste abonnieren diese Ereignisse, um ihren lokalen Zustand zu aktualisieren.
- Asynchrone Nachrichtenübertragung: Anstelle direkter Aufrufe kommunizieren Dienste über einen Nachrichtenbroker, um Lastspitzen und Ausfälle zu bewältigen.
Der ERD entwickelt sich von einem einzigen Diagramm zu einer Sammlung von Dienstenschemata. Jeder Dienst verfügt über ein eigenes Datenmodell, das auf seine spezifischen Lese- und Schreibmuster optimiert ist. Dies verringert die Komplexität jeder einzelnen Abfrage.
🛡️ Implementierung der Service-Mesh-Ebene
Sobald Dienste definiert und Daten-Grenzen festgelegt sind, folgt die nächste Ebene: der Service-Mesh. Diese Infrastrukturebene verwaltet die Kommunikation zwischen Diensten. Sie befindet sich zwischen dem Anwendungscode und dem Netzwerk und bietet Sichtbarkeit und Kontrolle.
Wichtige Komponenten des Mesh
Während bestimmte Tools variieren, bleiben die architektonischen Komponenten konsistent. Das Mesh besteht typischerweise aus:
- Datenebene:Leichte Proxys, die den Datenverkehr zwischen Diensten abfangen.
- Steuerungsebene:Eine zentrale Verwaltungskomponente, die die Proxys konfiguriert.
- Sidecar-Muster:Jede Dienstinstanz läuft neben einem Proxy-Container.
Das Service-Mesh ermöglicht Richtlinien, die zuvor in einer Monolith-Architektur schwer umzusetzen waren. Beispielsweise können Sie Rate-Limits für bestimmte Dienste durchsetzen, ohne den Anwendungscode zu ändern. Sie können auch eine gegenseitige TLS-Verschlüsselung zwischen Diensten automatisch implementieren.
Verkehrssteuerung
Ein Hauptvorteil des Meshes ist die Verkehrsverteilung. Während der Bereitstellung können Sie einen Prozentsatz des Verkehrs an eine neue Version eines Dienstes weiterleiten. Dies ermöglicht die Testung in einer Produktionsumgebung, ohne das gesamte System zu gefährden. Das Mesh verwaltet die Routing-Regeln basierend auf Headern, Pfaden oder Gewicht.
Zusätzlich ist das Circuit-Breaking entscheidend. Wenn ein nachgeschalteter Dienst nicht mehr reagiert, kann das Mesh den Datenverkehr an ihn stoppen und so eine Kettenreaktion verhindern. Dies schützt die Integrität des Systems, wenn einzelne Komponenten ausfallen.
📊 Datenkonsistenz und Governance
Das Aufteilen des ERD bringt die Herausforderung verteilter Transaktionen mit sich. In einer Monolith-Architektur werden die ACID-Eigenschaften von der Datenbank verwaltet. In einem verteilten System ist es komplex, diese Eigenschaften über mehrere Datenbanken hinweg aufrechtzuerhalten. Sie müssen eine Strategie wählen, die den Geschäftsanforderungen entspricht.
Konsistenzmodelle
Verschiedene Dienste können unterschiedliche Konsistenzanforderungen haben. Die folgende Tabelle zeigt gängige Strategien:
| Strategie | Anwendungsfall | Kompromiss |
|---|---|---|
| Starke Konsistenz | Finanzbuchhaltungen | Höhere Latenz, geringere Verfügbarkeit. |
| Eventuelle Konsistenz | Bestandszählungen | Niedrigere Latenz, temporäre Dateninkonsistenzen. |
| Kompensierende Transaktionen | Bestellstornierung | Komplexe Logik, erfordert Rückgängigmachungsmechanismen. |
Das Saga-Muster ist ein verbreiteter Ansatz zur Verwaltung langlaufender Transaktionen. Es teilt eine Transaktion in eine Reihe lokaler Transaktionen auf. Wenn eine fehlschlägt, werden kompensierende Aktionen ausgelöst, um die vorherigen Schritte rückgängig zu machen. Dadurch bleibt das System auch dann in einem gültigen Zustand, wenn Teile des Prozesses fehlschlagen.
Schema-Evolution
Bei getrennten Datenbanken sind Schema-Änderungen leichter zu verwalten. Ein Team kann das Schema für seinen Dienst ändern, ohne mit anderen Teams abzustimmen. Dennoch ist eine rückwärtskompatible Versionierung weiterhin erforderlich. APIs müssen die Versionsverwaltung reibungslos handhaben. Alte Clients sollten weiterhin funktionieren, während neue Clients das neue Schema übernehmen.
🚀 Leistungs- und Skalierbarkeitsüberlegungen
Die Umgestaltung der Architektur beeinflusst die Leistung. Bei Aufrufen zwischen Diensten entsteht Netzwerklatenz. Um dies zu mindern, werden folgende Optimierungen empfohlen:
- Caching:Häufig aufgerufene Daten sollten am Edge oder innerhalb des Dienstes zwischengespeichert werden. Dadurch verringert sich die Last der Datenbank und die Anzahl der Netzwerk-Hops.
- Verbindungs-Pooling:Jeder Dienst sollte seinen eigenen Verbindungs-Pool zur Datenbank pflegen. Dadurch wird Konkurrenzverhalten vermieden.
- Asynchrone Verarbeitung:Nicht-kritische Aufgaben wie das Versenden von E-Mails oder das Generieren von Berichten sollten asynchron verarbeitet werden.
Monitoring ist essenziell. Sie benötigen Sichtbarkeit bezüglich der Latenz zwischen Diensten. Verteiltes Tracing ermöglicht es Ihnen, eine Anfrage zu verfolgen, während sie durch das Netzwerk fließt. Dadurch können Engpässe identifiziert werden, die zuvor in einem monolithischen Log versteckt waren.
🔍 Herausforderungen und Gegenmaßnahmen
Obwohl die Vorteile klar sind, birgt der Übergang keine Risikofreiheit. Teams stoßen während der Migration oft auf spezifische Hürden.
1. Erhöhte Komplexität
Das Debuggen eines verteilten Systems ist schwieriger als das Debuggen eines Monoliths. Sie müssen die Netzwerktopologie, die Dienstabhängigkeiten und den Datenfluss verstehen. Die Minderung erfordert Investitionen in robuste Observabilitätstools und Schulungen.
2. Daten-Duplizierung
Um Netzwerkaufrufe bei jedem Lesevorgang zu vermeiden, können Dienste Daten duplizieren. Dies führt zu Speicherüberhead und dem Bedarf an Synchronisierung. Die Minderung erfordert eine sorgfältige Gestaltung der Lese-Modelle und die Verwendung von materialisierten Ansichten, wo angebracht.
3. Betriebliche Belastung
Die Verwaltung vieler Dienste erfordert mehr Infrastruktur. Sie müssen für jedes Komponenten Deployment, Skalierung und Gesundheitsprüfungen handhaben. Automatisierung ist hier entscheidend. Infrastructure as Code stellt sicher, dass die Umgebung reproduzierbar ist.
🛠️ Betriebliche Zusammenfassung
Die Reise von einem monolithischen ERD zu einem modularen Dienstnetz ist eine bedeutende architektonische Veränderung. Es erfordert mehr als nur Code-Refactoring; es verlangt eine Änderung der Art und Weise, wie Daten und Kommunikation verwaltet werden. Durch die Festlegung klarer Grenzen, die Einführung ereignisgesteuerter Muster und die Nutzung eines Dienstnetzes zur Verkehrssteuerung können Organisationen größere Agilität und Resilienz erreichen.
Wichtige Erkenntnisse für diese Transformation sind:
- Beginnen Sie mit den Daten:Verstehen Sie das ERD, bevor Sie Code schreiben. Die Datenverantwortung bestimmt die Dienstgrenzen.
- Akzeptieren Sie die Asynchronität:Verwenden Sie Nachrichtenverkehr, um Dienste zu entkoppeln und die Resilienz zu verbessern.
- Investieren Sie in Observabilität:Sie können nicht managen, was Sie nicht sehen können. Implementieren Sie Tracing und Logging frühzeitig.
- Gehen Sie schrittweise vor:Versuchen Sie keine „Big-Bang“-Migration. Übertragen Sie Funktionalität schrittweise.
Dieser Ansatz stellt sicher, dass das System auch bei Wachstum wartbar bleibt. Die resultierende Architektur unterstützt unabhängiges Skalieren und schnellere Bereitstellungzyklen. Obwohl der anfängliche Aufwand erheblich ist, rechtfertigt der langfristige Nutzen von Modularität und Isolation die Investition. Das ERD ist nun kein Hindernis mehr; es wird zu einer Karte für ein skalierbares, resistentes verteiltes System.