











Dans l’architecture logicielle moderne, le passage des structures monolithiques vers des systèmes distribués est une évolution courante. Les organisations commencent souvent avec une base de code unique et un schéma de base de données centralisé. Au fil du temps, cette structure engendre des goulets d’étranglement. Le diagramme d’entités relationnel (ERD), qui servait autrefois de plan clair pour l’application, devient un réseau complexe de dépendances. Transformer cet ERD monolithique en fondation pour une architecture de service modulaire exige une planification soigneuse, une discipline technique et une compréhension claire des frontières des données. Ce guide explore les étapes pratiques, les défis et les décisions architecturales impliquées dans cette transformation.
L’architecture ne consiste pas seulement à déplacer du code ; elle consiste à déplacer la propriété des données. Lorsqu’un ERD est monolithique, les tables font souvent référence les unes aux autres à travers des domaines fonctionnels. Une requête unique peut traverser cinq tables différentes représentant des unités commerciales distinctes. Ce couplage étroit rend le déploiement indépendant impossible. En décomposant ce diagramme et en l’alignant sur une architecture de service mesh, les équipes peuvent atteindre une isolation et une évolutivité. Les sections suivantes détaillent la méthodologie utilisée pour effectuer cette transition sans dépendre d’outils spécifiques aux fournisseurs.
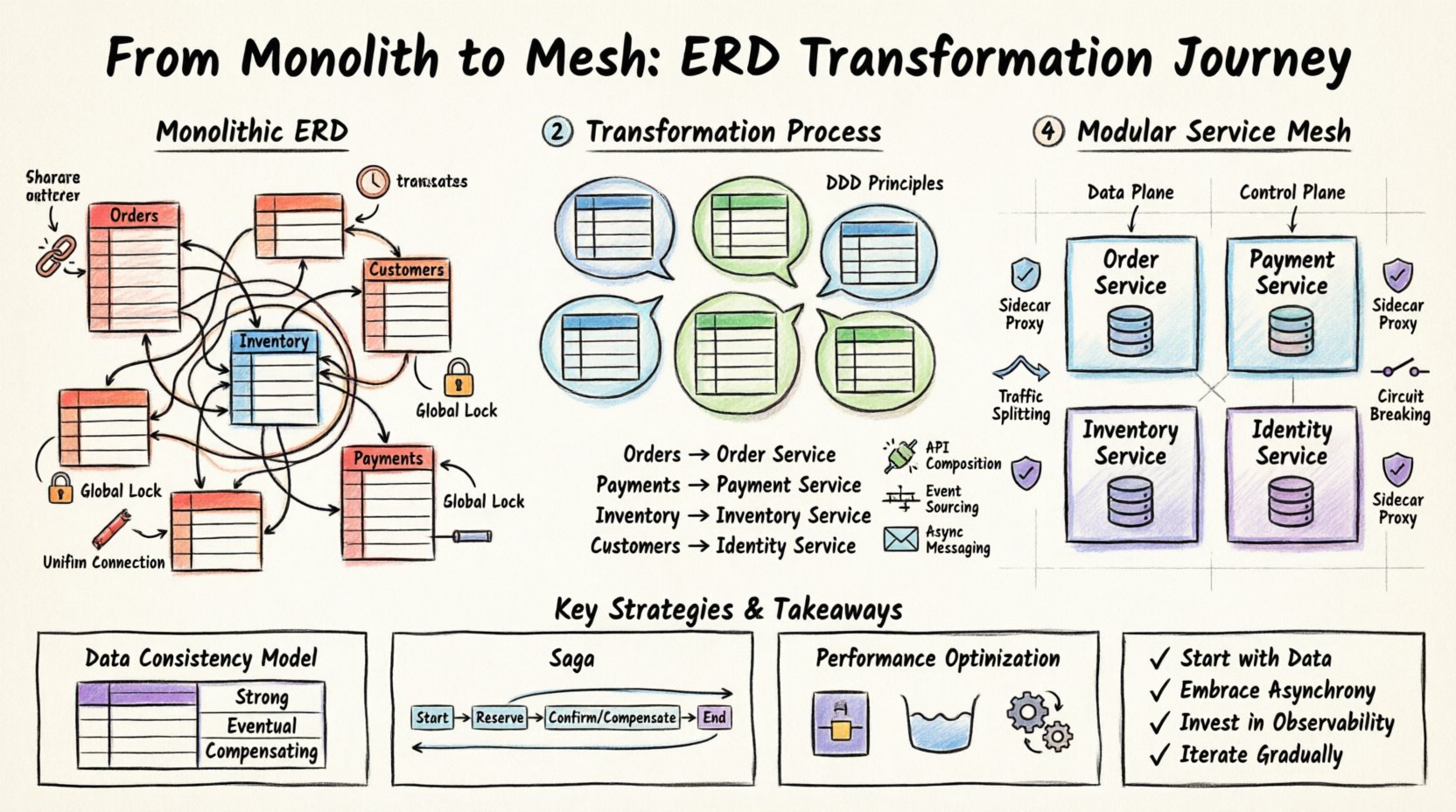
🏗️ Comprendre le point de départ : le diagramme ERD monolithique
Avant toute modification, l’état actuel doit être pleinement compris. Un ERD monolithique présente généralement des caractéristiques signalant un fort couplage. Ces caractéristiques incluent :
- Clés étrangères partagées :Les tables de modules différents font référence aux mêmes identifiants uniques, créant des dépendances directes.
- Blocs de transactions volumineux :Les transactions de base de données englobent plusieurs tables qui appartiennent logiquement à des contextes commerciaux différents.
- Verrous de schéma globaux :Les modifications de schéma nécessitent une interruption ou des scripts de migration complexes affectant l’ensemble de l’application.
- Pools de connexions unifiés :L’application partage un seul pool de connexions à la base de données, limitant la concurrence pour des fonctionnalités spécifiques à fort trafic.
Visualiser cette structure révèle souvent un motif « spaghetti » dans le diagramme. Des lignes relient des tables à travers l’ensemble du schéma, ce qui suggère qu’aucun composant n’est autonome. Dans une approche orientée services, ces connexions doivent être rompues ou abstraites. L’objectif est d’identifier où se trouvent les données et qui doit en être propriétaire.
🧩 Définition des contextes bornés
Le cœur de la transformation repose sur les principes du Design orienté domaine (DDD). Vous devez identifier des contextes bornés au sein de l’ERD monolithique. Un contexte borné est une frontière spécifique dans laquelle un modèle de domaine particulier s’applique. Dans le contexte d’un ERD, cela signifie regrouper les tables qui appartiennent logiquement ensemble.
Pour y parvenir, effectuez une analyse de la traçabilité des données. Suivez le parcours des données depuis leur création jusqu’à leur consommation. Posez les questions suivantes :
- Quelles tables sont mises à jour par le même processus métier ?
- Quelles tables sont fréquemment lues par des rôles d’utilisateurs spécifiques ?
- Quelles relations représentent une relation « possède » ou « appartient à » qui traverse les frontières fonctionnelles ?
Une fois ces groupes identifiés, attribuez-les à des frontières de service spécifiques. Ce processus n’est pas toujours un à un. Plusieurs tables peuvent appartenir à un seul service, tandis qu’une seule table pourrait être divisée entre plusieurs services si les modèles d’utilisation des données diffèrent sensiblement.
Exemple : Stratégie de décomposition
Considérez un scénario où l’ERD contient une table massiveCommandes liée à Clients, Inventaire, et Paiements. Dans un monolithe, il s’agit d’une seule table. Dans un système modulaire, ces éléments deviennent des entités distinctes.
| Entité monolithique | Frontière de service proposée | Raisonnement |
|---|---|---|
Commandes (Principal) |
Service de commande | La logique métier principale réside ici. |
Paiements |
Service de paiement | Exige des normes de sécurité et de conformité différentes. |
Inventaire |
Service d’inventaire | Exige une haute disponibilité et des stratégies de verrouillage différentes. |
Clients |
Service d’identité | Partagé entre plusieurs domaines, nécessite une centralisation. |
🔄 Restructuration des relations de données
Une fois les services définis, les relations dans le schéma ERD doivent évoluer. Dans un monolithe, une contrainte de clé étrangère garantit l’intégrité des données. Dans un système distribué, imposer des clés étrangères à travers les frontières réseau est inefficace et sujet aux échecs. À la place, les relations sont gérées par la logique d’application et la messagerie.
Ce changement nécessite l’adoption de modèles spécifiques pour maintenir la cohérence :
- Composition d’API :Les services exposent des API qui renvoient des données résumées, masquant les structures internes de la base de données.
- Sourcing d’événements :Les changements d’état sont enregistrés sous forme d’une séquence d’événements. Les services s’abonnent à ces événements pour mettre à jour leur état local.
- Messagerie asynchrone : Au lieu d’appels directs, les services communiquent via un broker de messages pour gérer les pics de charge et les défaillances.
Le schéma ERD évolue d’un seul diagramme vers une collection de schémas de service. Chaque service possède son propre modèle de données, optimisé pour ses motifs de lecture et d’écriture spécifiques. Cela réduit la complexité de toute requête individuelle.
🛡️ Mise en œuvre de la couche de service mesh
Une fois les services définis et les frontières des données établies, la prochaine couche est le service mesh. Cette couche d’infrastructure gère la communication entre services. Elle se situe entre le code de l’application et le réseau, offrant visibilité et contrôle.
Composants clés du mesh
Bien que les outils spécifiques varient, les composants architecturaux restent constants. Le maillage comprend généralement :
- Plan de données :Des proxies légers qui interceptent le trafic entre les services.
- Plan de contrôle :Un composant central de gestion qui configure les proxies.
- Modèle de sidecar :Chaque instance de service s’exécute aux côtés d’un conteneur proxy.
Le maillage de services permet de mettre en œuvre des politiques qui étaient auparavant difficiles à implémenter dans un monolithe. Par exemple, vous pouvez appliquer des limites de débit sur des services spécifiques sans modifier le code de l’application. Vous pouvez également mettre en œuvre automatiquement le chiffrement TLS mutuel entre les services.
Gestion du trafic
L’un des principaux avantages du maillage est le fractionnement du trafic. Pendant le déploiement, vous pouvez acheminer un pourcentage du trafic vers une nouvelle version d’un service. Cela permet de tester dans un environnement de production sans risquer l’ensemble du système. Le maillage gère les règles de routage en fonction des en-têtes, des chemins ou des poids.
En outre, la rupture de circuit est essentielle. Si un service en aval devient inactif, le maillage peut cesser d’envoyer du trafic vers celui-ci, empêchant ainsi une défaillance en chaîne. Cela protège l’intégrité du système lorsque des composants individuels échouent.
📊 Cohérence des données et gouvernance
La séparation du schéma ERD introduit le défi des transactions distribuées. Dans un monolithe, les propriétés ACID sont gérées par la base de données. Dans un système distribué, maintenir ces propriétés sur plusieurs bases de données est complexe. Vous devez choisir une stratégie adaptée aux exigences métiers.
Modèles de cohérence
Différents services peuvent avoir des besoins de cohérence différents. Le tableau suivant décrit des stratégies courantes :
| Stratégie | Cas d’utilisation | Compromis |
|---|---|---|
| Cohérence forte | Livres comptables financiers | Latence plus élevée, disponibilité réduite. |
| Cohérence éventuelle | Inventaires | Latence plus faible, incohérence temporaire des données. |
| Transactions compensatoires | Annulation de commande | Logique complexe, nécessite des mécanismes d’annulation. |
Le modèle Saga est une approche courante pour gérer les transactions longues. Il divise une transaction en une série de transactions locales. Si l’une échoue, des actions compensatoires sont déclenchées pour annuler les étapes précédentes. Cela garantit que le système reste dans un état valide même si certaines parties du processus échouent.
Évolution du schéma
Avec des bases de données séparées, les modifications de schéma sont plus faciles à gérer. Une équipe peut modifier le schéma de son service sans coordination avec d’autres équipes. Toutefois, la compatibilité descendante reste nécessaire. Les API doivent gérer la versionning de manière fluide. Les anciens clients doivent continuer à fonctionner tandis que les nouveaux adoptent le nouveau schéma.
🚀 Considérations sur les performances et la scalabilité
Transformer l’architecture affecte les performances. Une latence réseau est introduite lorsque les services s’appellent mutuellement. Pour atténuer cela, les optimisations suivantes sont recommandées :
- Mise en cache :Les données fréquemment consultées doivent être mises en cache au niveau de la périphérie ou à l’intérieur du service. Cela réduit la charge sur la base de données et le nombre de sauts réseau.
- Pool de connexions :Chaque service doit maintenir son propre pool de connexions vers la base de données. Cela évite les conflits.
- Traitement asynchrone :Les tâches non critiques, telles que l’envoi d’e-mails ou la génération de rapports, doivent être traitées de manière asynchrone.
Le monitoring est essentiel. Vous devez avoir une visibilité sur la latence entre les services. Le traçage distribué vous permet de suivre une requête au fur et à mesure qu’elle circule dans le maillage. Cela aide à identifier les goulets d’étranglement qui étaient auparavant cachés dans un journal monolithique.
🔍 Défis et atténuation
Bien que les avantages soient clairs, la transition n’est pas sans risques. Les équipes rencontrent souvent des obstacles spécifiques pendant la migration.
1. Complexité accrue
Déboguer un système distribué est plus difficile que de déboguer un monolithe. Vous devez comprendre la topologie du réseau, les dépendances entre services et le flux de données. L’atténuation passe par un investissement dans des outils robustes d’observabilité et une formation.
2. Duplication des données
Pour éviter les appels réseau à chaque lecture, les services peuvent dupliquer des données. Cela entraîne une surcharge de stockage et la nécessité de synchronisation. L’atténuation passe par une conception soigneuse des modèles de lecture et l’utilisation de vues matérialisées lorsque cela est pertinent.
3. Surcharge opérationnelle
La gestion de nombreux services nécessite une infrastructure plus importante. Vous devez gérer le déploiement, le dimensionnement et les vérifications d’état pour chaque composant. L’automatisation est essentielle ici. Le concept d’infrastructure comme code garantit que l’environnement est reproductible.
🛠️ Résumé opérationnel
Le passage d’un ERD monolithique à un maillage de services modulaires représente un changement architectural important. Cela exige plus que simplement une refonte du code ; cela demande un changement dans la manière dont les données et la communication sont gérées. En définissant des frontières claires, en adoptant des modèles basés sur les événements et en tirant parti d’un maillage de services pour le contrôle du trafic, les organisations peuvent atteindre une agilité et une résilience accrues.
Les points clés de cette transformation incluent :
- Commencez par les données :Comprenez l’ERD avant d’écrire du code. La propriété des données détermine les frontières des services.
- Adoptez l’asynchronie :Utilisez la messagerie pour découpler les services et améliorer la résilience.
- Investissez dans l’observabilité :Vous ne pouvez pas gérer ce que vous ne voyez pas. Mettez en œuvre le traçage et la journalisation dès le début.
- Itérez progressivement :N’essayez pas une migration « big bang ». Déplacez les fonctionnalités progressivement.
Cette approche garantit que le système reste maintenable au fur et à mesure de sa croissance. L’architecture résultante permet un dimensionnement indépendant et des cycles de déploiement plus rapides. Bien que l’effort initial soit important, la valeur à long terme de la modularité et de l’isolement justifie l’investissement. L’ERD n’est plus une contrainte ; il devient une carte pour un système distribué évolutif et résilient.