











W nowoczesnej architekturze oprogramowania przesunięcie od struktur monolitycznych w kierunku systemów rozproszonych jest powszechnym kierunkiem rozwoju. Organizacje często zaczynają od jednolitego kodu źródłowego i centralnego schematu bazy danych. Z czasem ta struktura powoduje węzły zatyczki. Diagram relacji encji (ERD), który kiedyś był jasnym szkicem aplikacji, staje się skomplikowaną siecią zależności. Przekształcenie tego monolitycznego ERD w podstawę dla modułowej siatki usług wymaga starannego planowania, dyscypliny technicznej oraz jasnego zrozumienia granic danych. Niniejszy przewodnik omawia praktyczne kroki, wyzwania oraz decyzje architektoniczne związane z tą transformacją.
Architektura to nie tylko przenoszenie kodu; to przenoszenie własności danych. Gdy ERD jest monolityczny, tabele często odnoszą się do siebie przez różne domeny funkcjonalne. Jedno zapytanie może przemierzać pięć różnych tabel reprezentujących różne jednostki biznesowe. Ta silna zależność uniemożliwia niezależne wdrażanie. Przez rozkład tego diagramu i dopasowanie go do siatki usług zespoły mogą osiągnąć izolację i skalowalność. Poniższe sekcje szczegółowo opisują metodologię stosowaną do osiągnięcia tej zmiany bez użycia konkretnych narzędzi dostawcy.
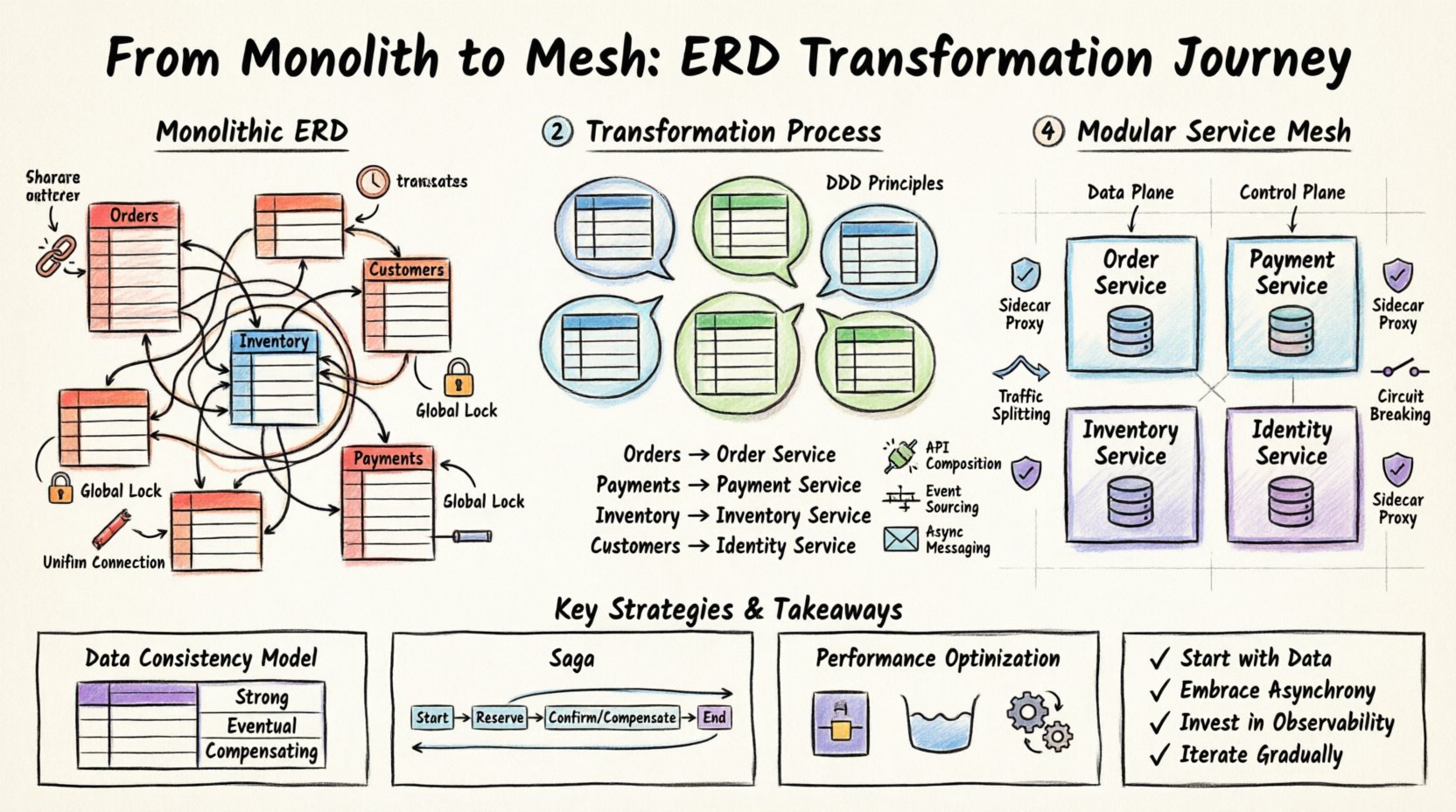
🏗️ Zrozumienie punktu wyjścia: monolityczny ERD
Zanim wprowadzimy jakiekolwiek zmiany, musimy dokładnie zrozumieć obecną sytuację. Monolityczny ERD zwykle wykazuje cechy wskazujące na wysoką zależność. Do takich cech należą:
- Współdzielone klucze obce:Tabele z różnych modułów odnoszą się do tych samych unikalnych identyfikatorów, tworząc bezpośrednie zależności.
- Duże bloki transakcji:Transakcje bazy danych obejmują wiele tabel, które logicznie należą do różnych kontekstów biznesowych.
- Globalne blokady schematu:Zmiany schematu wymagają czasu przestoju lub skomplikowanych skryptów migracji wpływających na całą aplikację.
- Zjednoczone puly połączeń:Aplikacja dzieli się jedną pulą połączeń z bazą danych, co ogranicza współbieżność dla określonych funkcji o wysokim obciążeniu.
Wizualizacja tej struktury często ujawnia wzór „spaghetti” na diagramie. Linie łączą tabele na całym układzie, co sugeruje, że żaden pojedynczy komponent nie jest samodzielny. W podejściu opartym na usługach te połączenia muszą zostać zerwane lub abstrakcyjnie przedstawione. Celem jest zidentyfikowanie, gdzie dane się znajdują i kto powinien je zarządzać.
🧩 Definiowanie kontekstów ograniczonych
Kluczową częścią transformacji jest zasada projektowania opartego na domenie (DDD). Musisz zidentyfikować konteksty ograniczone wewnątrz monolitycznego ERD. Kontekst ograniczony to określona granica, w której stosuje się konkretny model domeny. W kontekście ERD oznacza to grupowanie tabel, które logicznie do siebie należą.
Aby to osiągnąć, wykonaj analizę ścieżki danych. Śledź, jak dane przepływają od tworzenia do użytkowania. Zadaj następujące pytania:
- Które tabele są aktualizowane przez ten sam proces biznesowy?
- Które tabele są często odczytywane przez określone role użytkowników?
- Które relacje reprezentują relację „ma” lub „należy do”, które przekraczają granice funkcjonalne?
Gdy te grupy zostaną zidentyfikowane, przypisz je do konkretnych granic usług. Ten proces nie zawsze jest jednoznaczny. Wiele tabel może należeć do jednej usługi, podczas gdy jedna tabela może zostać podzielona między usługi, jeśli wzorce użytkowania danych znacznie się różnią.
Przykład: Strategia dekompozycji
Rozważ sytuację, w której ERD zawiera ogromnąZamówieniatabelę połączoną zKlientami, Inwentarzem, orazPłatnościami. W monolitach jest to jedna tabela. W systemie modułowym stają się to osobne encje.
| Encja monolityczna | Zaproponowane granice usługi | Uzasadnienie |
|---|---|---|
Zamówienia (Główny) |
Usługa zamówień | Główna logika biznesowa znajduje się tutaj. |
Płatności |
Usługa płatności | Wymaga innych standardów bezpieczeństwa i zgodności. |
Inwentarz |
Usługa inwentarza | Wymaga wysokiej dostępności i innych strategii blokowania. |
Klienci |
Usługa tożsamości | Udostępniana w wielu dziedzinach, wymaga centralizacji. |
🔄 Przebudowa relacji danych
Po zdefiniowaniu usług relacje na diagramie ERD muszą ulec zmianie. W monolitach ograniczenie klucza obcego zapewnia integralność danych. W systemie rozproszonym wymuszanie kluczy obcych przez granice sieci są nieefektywne i podatne na awarie. Zamiast tego relacje są zarządzane za pomocą logiki aplikacji i komunikacji.
Taka zmiana wymaga wprowadzenia określonych wzorców w celu zachowania spójności:
- Kompozycja interfejsów API: Usługi udostępniają interfejsy API zwracające podsumowane dane, ukrywając wewnętrzne struktury baz danych.
- Zasoby zdarzeń: Zmiany stanu są zapisywane jako sekwencja zdarzeń. Usługi subskrybują te zdarzenia, aby zaktualizować swój lokalny stan.
- Komunikacja asynchroniczna: Zamiast bezpośrednich wywołań usługi komunikują się przez broker komunikatów, aby obsłużyć szczyty obciążenia i awarie.
Diagram ERD ewoluuje z pojedynczego rysunku do zbioru schematów usług. Każda usługa ma własny model danych zoptymalizowany pod kątem jej specyficznych wzorców odczytu i zapisu. To zmniejsza złożoność każdej pojedynczej zapytania.
🛡️ Wdrażanie warstwy mesh usługi
Po zdefiniowaniu usług i ustaleniu granic danych następna warstwa to mesh usługi. Ta warstwa infrastruktury obsługuje komunikację między usługami. Znajduje się między kodem aplikacji a siecią, zapewniając widoczność i kontrolę.
Kluczowe składniki mesh
Choć konkretne narzędzia się różnią, składniki architektoniczne pozostają spójne. Sieć usług zwykle składa się z:
- Płaszczyzna danych:Lekkie proxy, które przechwytują ruch między usługami.
- Płaszczyzna sterowania:Centralny składnik zarządzania, który konfiguruje proxy.
- Wzorzec sidecar:Każda instancja usługi działa razem z kontenerem proxy.
Sieć usług umożliwia zastosowanie zasad, które wcześniej były trudne do zaimplementowania w monolitach. Na przykład możesz wymusić limity szybkości na określonych usługach bez zmiany kodu aplikacji. Możesz również automatycznie zaimplementować szyfrowanie TLS wzajemne między usługami.
Zarządzanie ruchem
Jedną z głównych zalet sieci jest podział ruchu. Podczas wdrażania możesz kierować procentem ruchu do nowej wersji usługi. Pozwala to na testowanie w środowisku produkcyjnym bez ryzyka całkowitego awarii systemu. Sieć zarządza regułami routingu na podstawie nagłówków, ścieżek lub wag.
Dodatkowo, przerwanie obwodu (circuit breaking) jest kluczowe. Jeśli usługa dolnego poziomu stanie się nieodpowiedzialna, sieć może zatrzymać wysyłanie ruchu do niej, zapobiegając tym samym awarii kaskadowej. Chroni to integralność systemu w przypadku awarii poszczególnych składników.
📊 Spójność danych i zarządzanie danymi
Podział ERD wprowadza wyzwanie związane z transakcjami rozproszonymi. W monolitach właściwości ACID są zarządzane przez bazę danych. W systemie rozproszonym utrzymanie tych właściwości na wielu bazach danych jest skomplikowane. Musisz wybrać strategię dopasowaną do wymagań biznesowych.
Modele spójności
Różne usługi mogą mieć różne potrzeby spójności. Poniższa tabela przedstawia typowe strategie:
| Strategia | Przypadek użycia | Zalety i wady |
|---|---|---|
| Silna spójność | Dzienniki finansowe | Wyższa opóźnienie, niższa dostępność. |
| Końcowa spójność | Stan magazynowy | Niższe opóźnienie, tymczasowa niezgodność danych. |
| Transakcje kompensacyjne | Anulowanie zamówienia | Złożona logika, wymaga mechanizmów cofnięcia. |
Wzorzec Saga to powszechna metoda zarządzania długotrwałymi transakcjami. Dzieli transakcję na serię lokalnych transakcji. Jeśli jedna z nich nie powiedzie się, uruchamiane są działania kompensacyjne w celu cofnięcia poprzednich kroków. Zapewnia to, że system pozostaje w poprawnym stanie nawet jeśli część procesu się nie powiedzie.
Ewolucja schematu
Przy oddzielnych bazach danych zmiany schematu są łatwiejsze do zarządzania. Zespół może modyfikować schemat dla swojej usługi bez koordynacji z innymi zespołami. Jednak kompatybilność wsteczna nadal jest niezbędna. Interfejsy API muszą obsłużyć wersjonowanie zgodnie z zasadami. Stare klienty powinny nadal działać, podczas gdy nowe klienty przyjmują nowy schemat.
🚀 Rozważania dotyczące wydajności i skalowalności
Zmiana architektury wpływa na wydajność. Pojawia się opóźnienie sieciowe, gdy usługi wywołują się wzajemnie. Aby to ograniczyć, zaleca się następujące optymalizacje:
- Buforowanie:Dane często wykorzystywane powinny być buforowane na krawędzi lub w obrębie usługi. Zmniejsza to obciążenie bazy danych i liczbę przejść sieciowych.
- Pooling połączeń: Każda usługa powinna utrzymywać własny pulę połączeń z bazą danych. Zapobiega to zawieszeniom.
- Przetwarzanie asynchroniczne:Zadania niekrytyczne, takie jak wysyłanie e-maili lub generowanie raportów, powinny być przetwarzane asynchronicznie.
Monitorowanie jest niezbędne. Potrzebujesz widoczności opóźnień między usługami. Rozproszone śledzenie pozwala śledzić żądanie w miarę przepływu przez sieć. Pomaga to wykryć węzły zatrzasku, które wcześniej były ukryte w jednym logu monolitycznym.
🔍 Wyzwania i metody ich ograniczania
Choć korzyści są oczywiste, przejście nie jest bez ryzyka. Zespoły często napotykają konkretne trudności podczas migracji.
1. Zwiększenie złożoności
Debugowanie systemu rozproszonego jest trudniejsze niż debugowanie monolitu. Musisz zrozumieć topologię sieci, zależności między usługami oraz przepływ danych. Ograniczenie ryzyka wymaga inwestycji w zaawansowane narzędzia obserwacji oraz szkolenia.
2. Duplikacja danych
Aby uniknąć wywołań sieciowych przy każdym odczycie, usługi mogą duplikować dane. Powoduje to nadmiarowe zużycie pamięci i konieczność synchronizacji. Ograniczenie ryzyka wymaga starannego projektowania modeli odczytu oraz stosowania widoków materializowanych tam, gdzie to odpowiednie.
3. Obciążenie operacyjne
Zarządzanie wieloma usługami wymaga większej infrastruktury. Musisz zarządzać wdrażaniem, skalowaniem i sprawdzaniem stanu zdrowia każdej komponenty. Kluczem jest automatyzacja. Infrastruktura jako kod zapewnia, że środowisko można ponownie wytworzyć.
🛠️ Podsumowanie operacyjne
Droga od monolitycznego ERD do modułowej sieci usług to istotny przeskok architektoniczny. Wymaga więcej niż tylko przekształcenia kodu; wymaga zmiany sposobu zarządzania danymi i komunikacją. Definiując jasne granice, przyjmując wzorce oparte na zdarzeniach oraz wykorzystując sieć usług do kontroli ruchu, organizacje mogą osiągnąć większą elastyczność i odporność.
Kluczowe wnioski z tej transformacji to:
- Zacznij od danych:Zrozumienie ERD przed napisaniem kodu. Prawo do danych determinuje granice usług.
- Przyjmij asynchroniczność:Używaj komunikacji między usługami, aby rozdzielić ich zależności i poprawić odporność.
- Inwestuj w obserwację:Nie możesz zarządzać tym, czego nie widzisz. Wprowadź śledzenie i rejestrowanie jak najszybciej.
- Postępuj stopniowo:Nie próbuj migracji typu „big bang”. Przenoszenie funkcjonalności stopniowo.
Ten podejście zapewnia, że system pozostaje łatwy do utrzymania w miarę jego rozwoju. Ostateczna architektura wspiera niezależne skalowanie i szybsze cykle wdrażania. Choć początkowe wysiłki są znaczne, długoterminowa wartość modułowości i izolacji uzasadnia inwestycję. ERD już nie jest ograniczeniem; staje się mapą skalowalnego, odpornego systemu rozproszonego.