Data modeling is often described as the bridge between business logic and technical implementation. However, this bridge is frequently built on shifting ground. When business stakeholders present vague concepts like “tracking customer activity” or “managing inventory levels” without defining specific constraints, the Entity Relationship Diagram (ERD) becomes a high-stakes gamble. Senior Database Administrators (DBAs) do not simply guess; they employ a structured methodology to convert uncertainty into structured data definitions.
This guide explores the specific strategies, questioning techniques, and architectural patterns used by experienced database professionals when facing ambiguous requirements. We will examine how to stabilize the design process, ensure data integrity, and create a schema that remains robust even as business needs evolve.
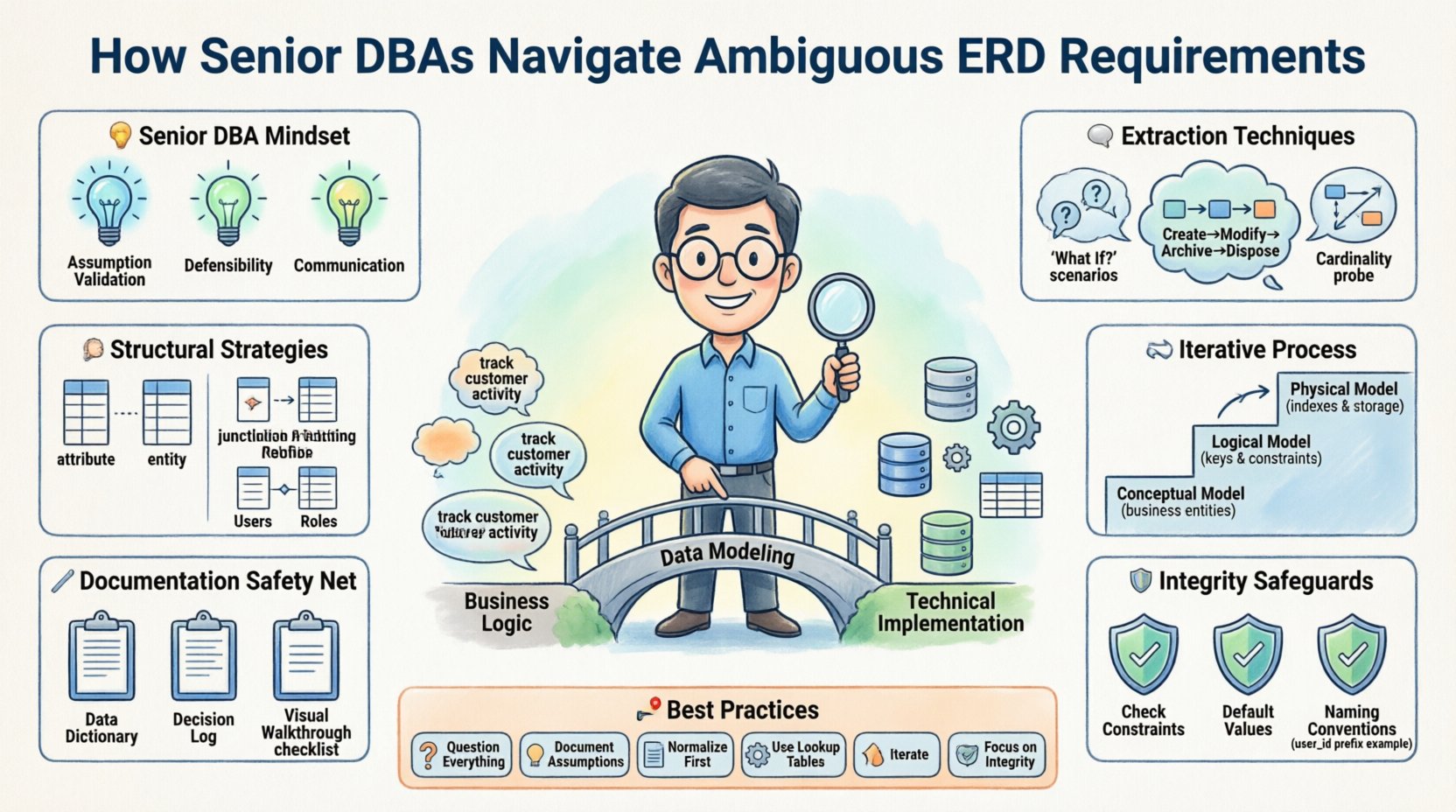
🧠 The Mindset of a Senior DBA
Junior modelers often view an ERD as a static drawing that must be perfect on the first attempt. Senior practitioners understand that data modeling is an iterative discovery process. Ambiguity is not an error; it is a signal that the business logic has not yet been fully articulated. The goal is not to eliminate ambiguity immediately but to isolate it, document it, and design around it safely.
Key characteristics of this approach include:
Assumption Validation: Treating every assumption as a hypothesis that requires testing against real-world scenarios.
Defensibility: Ensuring that every foreign key and index can be justified by a business rule, not just a technical preference.
Future-Proofing: Designing for the next three years of business growth, not just the current sprint.
Communication: Translating technical constraints into business language that stakeholders can understand.
🗣️ Techniques for Extracting Hidden Rules
When a requirement states “we need to track orders,” the ambiguity lies in the definition of an order. Is it a purchase? A quote? A cart abandonment? Senior DBAs use specific questioning patterns to narrow the scope.
1. The “What If” Scenario
Instead of accepting a high-level statement, the DBA pushes for edge cases. Questions like “What happens if an order is partially shipped?” or “Can an order be cancelled after payment?” force the stakeholder to reveal constraints that were not initially visible. These edge cases often dictate the need for status tables, transaction logs, or specific constraint rules.
2. The Data Lifecycle Inquiry
Every piece of data has a lifecycle. Senior DBAs ask about the state transitions:
Creation: Who creates the record? Is it automated or manual?
Modification: Is history tracked, or is the record overwritten? If history is tracked, is it a snapshot or a delta?
Archival: When does data become “old”? Is it soft-deleted (flagged) or hard-deleted (removed)?
Disposal: Are there legal retention periods that dictate data retention?
3. The Cardinality Probe
Cardinality defines the relationship between entities. Ambiguity here leads to performance issues and data duplication. The DBA asks:
Can one item belong to multiple categories simultaneously?
Is a relationship mandatory (must exist) or optional (can be null)?
If a relationship breaks, what is the impact on the parent record?
📐 Structural Strategies for Uncertainty
When requirements remain vague after consultation, the database design must absorb the uncertainty without compromising integrity. This involves specific modeling patterns that allow for flexibility.
1. The Attribute vs. Entity Decision
One of the most common ambiguities is whether a piece of data should be a column (attribute) or a separate table (entity). For example, should “phone numbers” be a single column or a separate table linked to a “Contacts” entity?
When the requirement is unclear, the senior approach favors normalization. Creating a separate table for phone numbers allows for multiple numbers per contact without adding nullable columns. It also allows for categorization (e.g., Home, Mobile, Work) without bloating the primary table. This approach handles growth better than wide tables with many optional columns.
2. Handling Optional Relationships
If it is unclear whether a specific relationship must exist, the DBA models it as optional using nullable foreign keys. However, this comes with a warning. Nullable foreign keys can lead to orphaned data if not managed correctly. The solution is often to implement triggers or application-level validation to ensure referential integrity is maintained logically, even if the database allows the null.
3. The Junction Table Strategy
Many-to-many relationships are a frequent source of confusion. If the requirement says “Users can have multiple Roles” and “Roles can be assigned to multiple Users,” a simple column cannot hold this data. A junction table (associative entity) is the standard solution. It allows the DBA to attach attributes to the relationship itself, such as “When was the role assigned?” or “Who approved the assignment?”. This adds a layer of auditability that is often requested later when requirements evolve.
🔄 The Iterative Process
Senior DBAs rarely deliver a final schema on the first draft. They utilize a phased approach to mitigate risk.
Phase 1: Conceptual Model
This is a high-level diagram focusing on business entities and their relationships. It ignores data types and technical constraints. The goal is to get stakeholder sign-off on the *what*, not the *how*. This prevents technical details from clouding the business logic agreement.
Phase 2: Logical Model
Here, data types are defined, and normalization rules (typically up to Third Normal Form) are applied. Ambiguities are resolved by making conservative assumptions documented in a data dictionary. This is where the DBA defines primary keys, foreign keys, and unique constraints.
Phase 3: Physical Model
The logical model is translated into specific implementation details. This includes indexing strategies, partitioning, and storage engines. At this stage, the DBA considers performance implications of the ambiguous decisions made earlier. If a requirement was vague about “fast reporting,” the physical model might include denormalization or materialized views to accommodate that need, with a note to revisit it later.
📝 Documentation & Communication
Documentation is the safety net for ambiguous requirements. If a decision was made based on an assumption, it must be recorded. This protects the DBA and the organization from scope creep or data loss.
Data Dictionary: A living document that defines every column, its purpose, and its constraints. If a field is nullable, the reason should be noted.
Decision Log: A section in the project documentation that records why specific modeling choices were made. For example: “Assumed one-to-many relationship for Orders based on stakeholder interview on [Date].”
Visual Walkthroughs: Before code generation, the diagram is reviewed with the business team. This ensures the model reflects their mental map of the business.
⚠️ Common Pitfalls to Avoid
Even experienced professionals can fall into traps when requirements are unclear. Awareness of these pitfalls helps maintain design integrity.
Over-Engineering: Trying to solve for every possible future scenario leads to a schema that is too complex to maintain. It is better to build for the current known requirements and add flexibility for the future.
Ignoring Data Types: Treating all text as “VARCHAR” is a common mistake. Dates, currencies, and IDs have specific constraints that should be enforced at the database level.
Hardcoding Logic: Putting business rules directly into the ERD (like “Status = 1 means Active”) is risky. It is better to use readable enums or lookup tables so that the meaning of the data is clear.
Skipping the Audit Trail: If requirements are vague, data provenance becomes critical. Adding columns like “created_by,” “created_at,” and “updated_at” provides a baseline for tracking changes.
📊 Types of Ambiguity and Resolution Strategies
To aid in quick reference, the following table outlines common types of ambiguity found in ERD design and the recommended technical resolution.
Type of Ambiguity | Example Scenario | Resolution Strategy |
|---|---|---|
Cardinality Uncertainty | “One product can be in many orders.” (Does it imply many orders per product? Or just one?) | Model as Many-to-Many with a junction table to allow future expansion. |
Data Volatility | “We need to store customer addresses.” (Do they change? Do we keep history?) | Use a separate “Address History” table with effective dates rather than overwriting the main address. |
Attribute Granularity | “Store user location.” (City? GPS coordinates? IP?) | Create a dedicated “Location” entity with specific fields (Latitude, Longitude, City) to allow future precision. |
State Management | “Track order status.” (What are the valid states?) | Implement a status lookup table with constraints to prevent invalid state transitions. |
Uniqueness Constraints | “Ensure emails are unique.” (Case sensitive? What about typos?) | Apply unique constraints on lowercased versions of the field or use a separate validation layer. |
🛡️ Ensuring Data Integrity in Vague Environments
When requirements are unclear, the risk of data corruption increases. Senior DBAs implement safeguards to protect the database from bad data entering the system.
1. Check Constraints
Even if the business rules are fuzzy, the database should enforce strict boundaries. For example, if a “Price” field is required, the database should prevent negative numbers or null values unless explicitly allowed by the business logic.
2. Default Values
When a requirement is missing, using a safe default is better than allowing a null. For instance, if a “Status” field is ambiguous, setting a default to “Pending” or “Draft” ensures the record is not orphaned or ignored.
3. Naming Conventions
Consistent naming helps mitigate ambiguity. Using prefixes for foreign keys (e.g., user_id instead of just id) makes the relationship clear even if the table structure changes later. This reduces the cognitive load for developers reading the schema.
🚀 Scaling for the Unknown
Finally, senior DBAs consider how the schema will hold up under load. Ambiguous requirements often lead to poorly optimized queries later. By anticipating growth, the model remains usable.
Indexing Strategy: Identify fields that will likely be used for searching or filtering. Even if the requirement is vague, adding indexes to potential search columns prevents performance degradation later.
Partitioning Considerations: For large tables, consider how data will be partitioned. If the requirement is vague about time ranges, partitioning by date ranges allows for easier maintenance and archival later.
Read vs. Write Balance: Understand if the system is read-heavy or write-heavy. This influences whether to normalize heavily or introduce controlled denormalization for performance.
🤝 Collaborative Design
The most effective ERD designs are created in collaboration. A senior DBA does not work in a silo. They act as a translator between the technical team and the business stakeholders.
This collaboration ensures that:
Business stakeholders understand the cost of complexity.
Developers understand the constraints of the data.
DBAs understand the operational requirements.
Regular review meetings are essential. During these sessions, the diagram is walked through line by line. Questions are asked, and assumptions are challenged. This iterative feedback loop is the primary defense against ambiguous requirements.
🎯 Summary of Best Practices
To summarize the approach to ambiguous requirements in ERD design:
Question everything: Do not accept high-level statements without probing for details.
Document assumptions: If a choice is made based on a guess, record it.
Normalize first: Start with a clean, normalized structure and denormalize only when necessary.
Use lookup tables: Avoid hardcoding values within the schema.
Iterate: Treat the first design as a draft, not a final product.
Focus on integrity: Data quality is more important than speed of implementation.
By following these principles, database professionals can navigate the fog of ambiguous requirements and deliver robust, scalable, and maintainable data architectures. The goal is not to predict the future but to build a system flexible enough to adapt when the future arrives.
Remember that a well-designed schema is a communication tool. It speaks to the developers, the analysts, and the business owners. When the requirements are unclear, the schema must be clear enough to guide the team forward.