











В процессе эволюции архитектуры программного обеспечения немногие проблемы столь же устойчивы, как напряжение между историческим моделированием данных и современными требованиями масштабируемости. Многие организации вынуждены управлять бэкенд-системами, построенными на диаграммах сущностей и отношений (ERD), разработанных несколько лет назад, часто при других предположениях относительно нагрузки, параллелизма и аппаратных средств. Когда устаревшая схема сталкивается с требованиями высокой пропускной способности, снижение производительности — это не просто неудобство, а структурный сбой. В этом руководстве рассматриваются технические реалии оптимизации этих диаграмм без утраты встроенной в них бизнес-логики.
Понимание бремени устаревших систем 💾
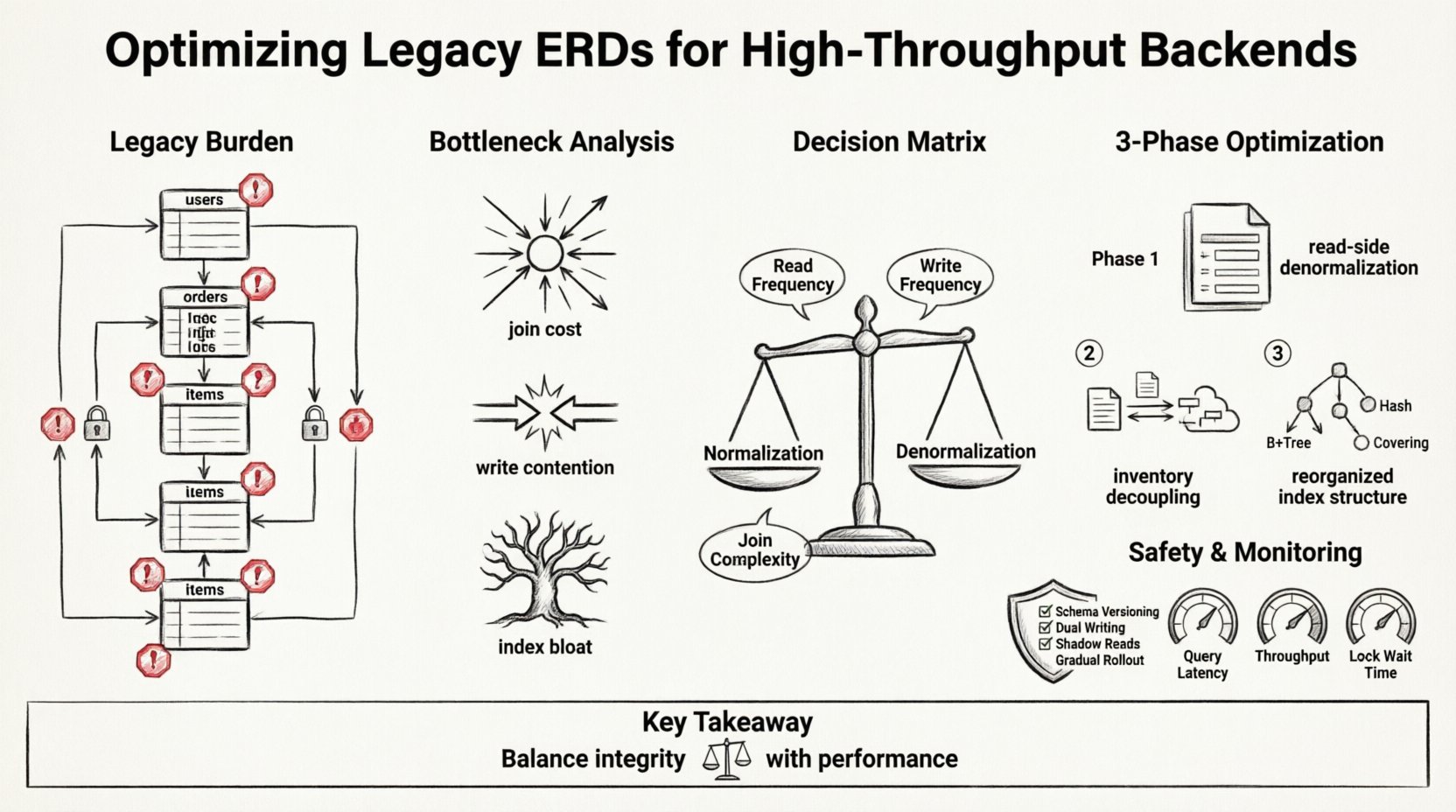
Устаревшие диаграммы сущностей и отношений часто отражают потребности прошлого. Они в первую очередь ориентируются на целостность данных и нормализацию. В среде с одним узлом и умеренной нагрузкой такой подход работает хорошо. Строгое соблюдение третьей нормальной формы (3NF) минимизирует избыточность и обеспечивает согласованность. Однако, когда система масштабируется до миллионов транзакций в секунду, стоимость этих связей становится неприемлемой.
Обратите внимание на следующие распространённые особенности, присутствующие в старых схемах:
- Глубокие цепочки соединений:Запросы, требующие пяти или более соединений для получения одного записей.
- Тяжёлые ограничения внешних ключей:Жёсткие проверки целостности, блокирующие одновременные записи.
- Централизованная блокировка:Зоны повышенной нагрузки на определённых таблицах, которые становятся узкими местами при пиковой нагрузке.
- Пробелы в денормализации:Отсутствие избыточных хранилищ данных для операций с высокой нагрузкой на чтение.
Эти паттерны не являются по своей сути «неправильными». Они были правильными на своём этапе. Проблема заключается в адаптации их к распределённой среде с высокой конкуренцией, где задержка является основной валютой.
Анализ узких мест 🔍
Прежде чем изменять диаграмму, необходимо понять, где система теряет производительность. Высокопроизводительные бэкенды часто ограничены операциями ввода-вывода, сетевой задержкой между сервисами и конкуренцией за блокировки. Диаграмма сущностей и отношений определяет, как осуществляется доступ к данным, что напрямую влияет на эти метрики.
1. Стоимость соединений
Каждое соединение — это операция чтения с диска и цикл процессора. В устаревшей системе запрос одного профиля пользователя может запустить цепочку поисков по пяти таблицам. По мере роста трафика база данных тратит больше времени на навигацию по связям, чем на выполнение логики. Это особенно актуально, когда индексы не могут покрыть весь путь соединения.
2. Конкуренция при записи
Нормализация требует записи данных в несколько мест для поддержания целостности. Если транзакция обновляет профиль пользователя и записывает событие активности, необходимо изменить две таблицы. Если эти таблицы находятся на одном шарде, время блокировки увеличивается. Если они распределены, транзакция превращается в двухэтапное подтверждение, что добавляет значительную накладную.
3. Избыточность индексов
Для поддержки сложных соединений устаревшие системы накапливают индексы. Со временем эти индексы замедляют операции записи. База данных должна обновлять каждый индекс при каждом вставке или обновлении. В сценариях с высокой пропускной способностью эта амплификация записи может перегрузить подсистему хранения.
Стратегия рефакторинга: нормализация против денормализации ⚖️
Суть оптимизации заключается в переосмыслении компромисса между целостностью данных и скоростью запросов. Хотя строгая нормализация обеспечивает согласованность, высокопроизводительные системы часто требуют прагматичной денормализации. Это не означает отказ от структуры, а означает принятие избыточности для снижения задержки.
В следующей таблице представлен матрица решений для изменений схемы:
| Критерии | Оставить нормализованным | Применить денормализацию |
|---|---|---|
| Частота чтения | Низкая (обработка пакетов) | Высокая (реальные панели мониторинга) |
| Частота записи | Высокая (основные транзакции) | Низкая (журналы аудита) |
| Требования согласованности | Сильная ACID-совместимость | Временная согласованность допустима |
| Сложность соединений | Простая (1-2 соединения) | Сложная (3+ соединения) |
| Неустойчивость данных | Статические (справочные данные) | Динамические (состояние пользователя) |
Реализация этой стратегии требует тщательного планирования. Вы не просто меняете таблицы; вы меняете, как приложение воспринимает данные.
Обзор кейса: движок транзакций электронной коммерции 🛒
Чтобы проиллюстрировать этот процесс, рассмотрим вымышленную платформу электронной коммерции. Устаревшая система обрабатывает заказы, управляет запасами и профилями клиентов. ERD был разработан для одного экземпляра базы данных с акцентом на предотвращение перепродажи товаров.
Состояние устаревшей системы
В первоначальном проекте таблица orders ссылалась на order_items, которая ссылалась на products. Таблица products ссылалась на inventory. Чтобы отобразить страницу деталей заказа, серверная часть выполняла запрос, объединяющий все четыре таблицы. Кроме того, каждое обновление заказа требовало блокировки таблицы запасов для обеспечения точности.
Выявленные ключевые проблемы:
- Задержка: Время загрузки страницы выросло до 800 мс во время распродаж.
- Взаимоблокировки:Высокая конкуренция при обновлении инвентаря привела к откату транзакций.
- Масштабируемость: База данных не могла шардировать
инвентарьтаблицу из-за частых соединений между шардами.
Процесс оптимизации
Команда решила реорганизовать ERD в три этапа. Целью было отделить пути чтения от путей записи.
Этап 1: денормализация сторон чтения
Первый шаг заключался в создании снимка данных о продуктах в записях заказов. Вместо соединения с таблицей productsтаблицы во время выполнения запроса, система скопировала название продукта, цену и артикул в таблицу order_itemsтаблицы в момент покупки.
- Выгода:История заказов остается точной, даже если данные о продукте изменятся позже.
- Выгода:Запрос больше не требует соединения с таблицей продуктов.
- Риск:Различия в ценах, если продукт будет обновлен после оформления заказа.
- Смягчение:Интерфейс отображает цену на момент покупки как «Историческая цена».
Этап 2: отделение инвентаря
Таблица инвентаря была источником конфликтов. Команда перенесла отслеживание инвентаря в отдельное хранилище с высокой частотой записи. Система заказов отправляет асинхронное сообщение для резервирования товара, вместо выполнения синхронной блокировки SQL.
- Выгода:Пропускная способность записи увеличилась на 400%.
- Выгода:Больше не будет блокировок основной транзакции заказа.
- Компромисс: Заказы можно размещать, даже если запасы временно не синхронизированы.
- Смягчение:Фоновый процесс устраняет расхождения между системой заказов и запасами.
Этап 3: Перестройка индексов
При денормализованных данных старые индексы по внешним ключам стали избыточными. Команда удалила их и добавила составные индексы, оптимизированные под новые шаблоны запросов. Например, индекс на(customer_id, created_at) устранил необходимость сканирования всей таблицы заказов.
Этапы реализации и безопасность 🛡️
Изменение активной схемы — это операция с высоким риском. Следующие этапы обеспечивают стабильность во время перехода.
1. Версионирование схемы
Не удаляйте старые столбцы сразу. Оставьте их на месте, но пометьте как устаревшие. Это позволит приложению откатиться, если новая логика не сработает. Используйте скрипты миграции, которые добавляют столбцы до их удаления.
2. Двойная запись
Во время перехода данные записываются как в старую структуру, так и в новую. Логика приложения направляет чтение в новую структуру, но запись идет в обе. Это обеспечивает резервный вариант, если новая схема не завершена.
3. Теневое чтение
Перед перенаправлением производственного трафика запустите новые запросы на копии производственных данных. Сравните результаты устаревших запросов с результатами оптимизированных запросов, чтобы убедиться в точности данных.
4. Постепенный выпуск
Используйте флаги функций для включения новой схемы для небольшого процента пользователей (например, 1%). Мониторьте уровни ошибок и задержки. Если метрики остаются стабильными, постепенно увеличивайте процент.
Мониторинг и валидация 📊
Оптимизация — это не одноразовое событие. Требуется непрерывный мониторинг, чтобы убедиться, что изменения выдерживают нагрузку. Ключевые показатели эффективности (KPI) должны быть установлены до начала рефакторинга.
Основные метрики для отслеживания:
- Задержка запросов:Время отклика на 95-м и 99-м перцентилях.
- Пропускная способность:Транзакции в секунду (TPS) без ошибок.
- Время ожидания блокировки:Среднее время, в течение которого транзакция ожидает блокировки.
- Задержка репликации:Задержка между основным и реплицированным узлами (при наличии).
- Коэффициент попадания в кэш:Эффективность стратегий кэширования чтения.
Пороги оповещения должны устанавливаться на основе базовых метрик, собранных до изменений. Если наблюдается резкий рост задержки, система должна автоматически вернуться к устаревшей схеме или перенаправить трафик на резервный сервис.
Распространённые ошибки, которые следует избегать ⚠️
Даже при наличии надёжного плана технический долг часто возвращается неожиданным образом. Будьте внимательны к этим распространённым ошибкам.
- Пренебрежение затратами на миграцию данных:Перенос терабайтов данных в новые структуры занимает время. Планируйте окна обслуживания или инструменты фоновой миграции.
- Чрезмерная оптимизация чтения: Если вы слишком сильно денормализуете, производительность записи пострадает. Сбалансируйте соотношение чтения и записи для вашей конкретной рабочей нагрузки.
- Забывание логики приложения: Изменение схемы — это лишь половина битвы. Код приложения должен быть обновлён для обработки новой структуры данных.
- Пренебрежение тестированием: Тесты юнитов часто охватывают только штатные сценарии. Для выявления гонок в новой схеме необходимы нагрузочные тесты.
Стратегии долгосрочного сопровождения 🔧
Как только оптимизация будет завершена, команда должна поддерживать новую архитектуру. Документация имеет критическое значение. Каждая таблица, столбец и связь должны быть помечены с указанием их цели и ответственного лица.
Регулярные аудиты:
Планируйте ежеквартальные обзоры ERD. Выявляйте таблицы, которые растут непропорционально, или запросы, которые становятся медленнее. Рост базы данных часто выявляет новые узкие места, которых не было на этапе первоначальной рефакторинга.
Автоматическая проверка схемы:
Интегрируйте проверку схемы в цикл CI/CD. Запрещайте разработчикам добавлять новые соединения или удалять критические ограничения без одобрения. Это обеспечит сохранение оптимальной производительности системы в долгосрочной перспективе.
Обучение команды:
Убедитесь, что все инженеры по бэкенду понимают новую модель данных. Общее понимание схемы снижает вероятность появления нового технического долга из-за нестандартных запросов.
Заключительные мысли о моделировании данных 🔗
Оптимизация устаревшей диаграммы сущность-связь — это баланс между исторической точностью и будущей масштабируемостью. Не существует единственно «правильной» схемы. Правильная модель — та, которая поддерживает ваши текущие бизнес-цели, оставляя место для роста.
Фокусируясь на конкретных узких местах вашей системы — будь то стоимость соединений, конкуренция за блокировки или переполнение индексов — вы можете вносить целенаправленные улучшения. Кейс-стади показывает, что даже глубоко укоренившиеся структуры можно модернизировать без полной переписи. Ключевым является последовательный подход, строгая валидация и чёткое понимание всех компромиссов.
Моделирование данных не является статичным. Оно развивается вместе с трафиком, который обслуживает. Относитесь к своей ERD как к живому документу, которому требуется такая же забота и внимание, как и коду, который к ней обращается. При правильном подходе вы можете превратить устаревшую систему в высокопроизводительный двигатель, способный справляться с требованиями современного веба.