











В мире архитектуры программного обеспечения немногие концепции имеют такое же значение, как диаграмма отношений сущностей (ERD). Это чертеж ваших данных, карта, которая направляет разработчиков сквозь сложный ландшафт таблиц, ключей и связей. Когда приложение тормозит, первая реакция часто — обвинить схему. Предположение очевидно: если диаграмма идеальна, производительность тоже должна быть идеальной.
Это распространённое заблуждение. 🧐 Хотя хорошо спроектированная ERD является основой, она не является панацеей для скорости. Идеальная логическая модель не автоматически превращается в высокоскоростное физическое выполнение. Понимание разрыва между теорией проектирования и реальностью выполнения в runtime критически важно для создания систем, которые остаются отзывчивыми под нагрузкой.
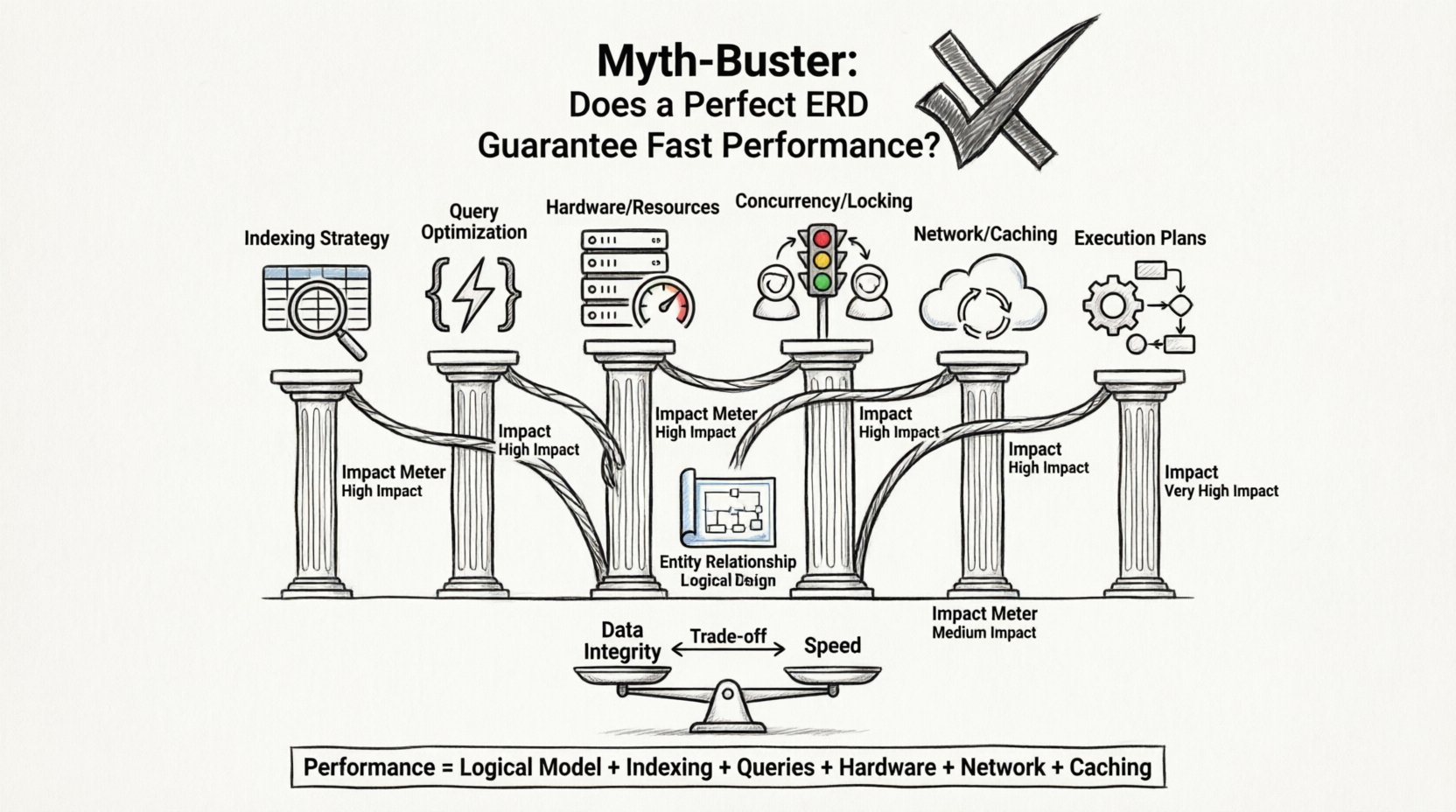
В этом руководстве рассматривается, почему идеальная ERD не гарантирует быстрые времена отклика, и какие другие критически важные факторы влияют на производительность базы данных. Мы разберём слои обработки данных — от движков хранения до задержек сети — чтобы выявить истинные причины скорости приложения.
📐 Понимание диаграммы отношений сущностей
Прежде чем погружаться в метрики производительности, мы должны уточнить, что на самом деле представляет собой ERD. ERD — это логический объект. Он описывает что данные существуют и как они связаны с другими данными. Он определяет сущности (таблицы), атрибуты (столбцы) и отношения (внешние ключи).
- Сущности: Объекты реального мира, представленные в виде таблиц.
- Атрибуты: Характеристики этих объектов, хранящиеся в столбцах.
- Связи: Связи между сущностями, часто обеспечиваемые первичными и внешними ключами.
- Мощность: Числовое отношение между сущностями (один к одному, один ко многим).
Основная цель ERD — целостность данных. Она обеспечивает, что данные остаются согласованными, точными и пригодными к использованию в течение времени. Она предотвращает появление «сиротских» записей и поддерживает ссылочную целостность. Однако целостность не равна скорости. Замок, удерживающий дверь закрытой, защищает содержимое внутри, но не делает дверь открываться быстрее.
⚡ Уравнение производительности: за пределами схемы
Время отклика приложения — это сумма многих компонентов. База данных — лишь одна часть этого уравнения. Даже если движок базы данных мгновенно извлекает данные, приложение может по-прежнему казаться медленным из-за узких мест в других местах.
Вот ключевые факторы, влияющие на скорость, часто превосходящие влияние проектирования схемы:
1. Стратегия индексации
ERD определяет первичные и внешние ключи, которые часто автоматически создают индексы. Однако эти индексы по умолчанию редко достаточны для сложных запросов. Производительность в значительной степени зависит от вторичных индексов, настроенных под конкретные шаблоны запросов.
- Отсутствующие индексы:Без индекса на часто фильтруемом столбце база данных должна выполнить полное сканирование таблицы. Это означает чтение каждой строки, что экспоненциально медленнее на больших наборах данных.
- Нагрузка от индексов:Слишком много индексов замедляет операции записи. Каждый вставляемый или обновляемый элемент требует обновления каждого индекса, связанного с этой таблицей.
- Выборочность:Индекс на столбце с низкой выборочностью (например, пол или статус) может быть проигнорирован оптимизатором запросов.
2. Оптимизация запросов
То, как запрашиваются данные, имеет большее значение, чем то, как они хранятся. Плохо написанный запрос может парализовать идеальную схему. Распространенные проблемы включают:
- Проблемы N+1:Получение родительской записи, а затем цикл по ней для получения дочерних записей по отдельности. Это приводит к нескольким往返 к базе данных вместо одного JOIN.
- Использование SELECT *:Получение всех столбцов увеличивает сетевой трафик и использование памяти, даже если нужен только один.
- Неявные преобразования:Сравнение строки с числом или даты с меткой времени может препятствовать использованию индексов.
- Сложные JOIN-операции:Объединение нескольких больших таблиц без надлежащей фильтрации значительно увеличивает вычислительную нагрузку.
3. Аппаратное обеспечение и инфраструктура
Эффективность программного обеспечения не может преодолеть физические ограничения. Аппаратное обеспечение определяет верхний предел производительности.
- Тип хранилища:Твердотельные накопители (SSD) значительно быстрее жестких дисков (HDD) при случайных операциях ввода-вывода.
- Память (ОЗУ):Если рабочий набор данных помещается в ОЗУ, запросы выполняются почти мгновенно. Если данные должны быть загружены с диска, задержка возрастает.
- Мощность процессора:Сложные вычисления, сортировка и агрегация требуют вычислительной мощности.
- Задержка сети:Расстояние между сервером приложений и сервером базы данных добавляет миллисекунды к каждому запросу.
4. Параллелизм и блокировки
Когда несколько пользователей одновременно обращаются к системе, база данных должна управлять конфликтами. Именно здесь производительность часто снижается.
- Конкуренция за блокировки:Если одна транзакция удерживает блокировку на строке, другие должны ждать. Высокая конкуренция приводит к тайм-аутам и медленным ответам.
- Взаимоблокировки:Две транзакции, ожидающие друг друга, могут привести к полной остановке системы.
- Уровни изоляции:Более высокие уровни изоляции (например, Serializable) обеспечивают более сильные гарантии, но снижают параллелизм и скорость.
📊 Влияние ERD по сравнению с другими факторами производительности
Чтобы визуализировать влияние ERD по сравнению с другими переменными, рассмотрим следующий анализ. Эта таблица показывает, где ERD приносит пользу, и где она оказывается недостаточной.
| Фактор | Влияние на скорость чтения | Влияние на скорость записи | Роль ERD |
|---|---|---|---|
| Структура схемы таблицы | Средний | Средний | Определяет отношения и нормализацию. |
| Индексация | Высокий | Низкий | ERD определяет ключи, но не все индексы. |
| Логика запросов | Очень высокий | Средний | ERD не определяет синтаксис запросов. |
| Аппаратные ресурсы | Высокий | Высокий | Нет. Независимо от схемы. |
| Задержка сети | Высокий | Средний | Нет. Независимо от схемы. |
| Пул соединений | Средний | Средний | Нет. Конфигурация приложения. |
🧱 Компромисс нормализации
Одной из наиболее дискутируемых тем в проектировании баз данных является нормализация. ERD обычно стремится к третьей нормальной форме (3НФ), чтобы сократить избыточность. Хотя это экономит место и обеспечивает согласованность, это может негативно сказаться на производительности.
Когда данные сильно нормализованы, одна часть информации хранится в одном месте. Чтобы получить ее, системе необходимо пройти через несколько JOIN. Каждый JOIN добавляет вычислительную нагрузку.
Рассмотрим ситуацию, когда необходимо отобразить профиль пользователя вместе с его последним заказом и деталями продукта. В нормализованной ERD для этого может потребоваться объединение четырех таблиц. Если эти таблицы большие, ЦП тратит значительное время на сортировку и сопоставление строк.
Денормализация — это техника, используемая для противодействия этому. Она предполагает дублирование данных для уменьшения необходимости использования JOIN. Это улучшает скорость чтения, но усложняет операции записи и повышает риск несогласованности данных. Идеальная ERD не определяет автоматически, где проводить эту границу. Это стратегическое решение, основанное на соотношении чтения и записи.
🔍 Глубокое погружение: планы выполнения запросов
Движок базы данных не выполняет запросы точно так, как они написаны. Он анализирует запрос и генерирует План выполнения. Этот план определяет порядок операций, какие индексы использовать, и следует ли выполнять сканирование или поиск.
ERD предоставляет метаданные о типах данных и ограничениях. Однако оптимизатор использует статистику о распределении данных для принятия решений. Если статистика устарела, оптимизатор может выбрать неоптимальный план, игнорируя лучшие доступные индексы.
Например, если таблица содержит 10 миллионов строк, но статистика считает, что их 100, оптимизатор может решить, что полное сканирование дешевле, чем поиск по индексу. Это приводит к медленной производительности, несмотря на хорошо структурированную ERD.
🛡️ Целостность данных против скорости
Существует внутреннее противоречие между обеспечением целостности данных и максимизацией скорости. ERD обеспечивает правила целостности, такие как ограничения и триггеры.
- Ограничения внешних ключей:Обеспечивают целостность ссылок. При удалении или обновлении система должна проверять связанные таблицы. Это добавляет задержку при операциях записи.
- Триггеры:Автоматизированные скрипты, выполняемые при изменениях данных. Хотя они полезны для логики, они добавляют время обработки к каждой транзакции.
- Ограничения уникальности:Требуют от системы проверки существующих значений перед вставкой новых.
В системах с высокой пропускной способностью эти проверки иногда отключаются или откладываются для повышения скорости. Идеальная ERD включает все эти правила, но система с высокой производительностью может потребовать модифицированного подхода.
🚦 Практические шаги по оптимизации
Если ваше приложение медленно работает, не перерисовывайте ERD сразу. Следуйте системному подходу для выявления узкого места.
1. Анализ медленных запросов
Включите ведение журнала запросов для фиксации длительных операций. Используйте инструменты профилирования, чтобы увидеть, где тратится время. Ожидает ли он блокировок? Сканирует ли строки? Обрабатывает ли логику?
2. Проверка использования индексов
Проверьте, какие индексы действительно используются. Неиспользуемые индексы занимают место и замедляют операции записи. Создавайте индексы, соответствующие условиям WHERE и JOIN ваших частых запросов.
3. Оптимизация распределения ресурсов оборудования
Убедитесь, что сервер базы данных имеет достаточно оперативной памяти для кэширования рабочего набора. Если база данных ограничена памятью, добавление больше RAM даст немедленные результаты. Если она ограничена ЦП, возможно, потребуется обновить процессор или оптимизировать код.
4. Реализация кэширования
Не каждый запрос должен обращаться к базе данных. Используйте кэш в оперативной памяти (например, Redis или Memcached) для часто запрашиваемых данных. Это полностью обходит базу данных при операциях чтения.
5. Мониторинг параллелизма
Следите за ожиданием блокировок. Если пользователи испытывают тайм-ауты, проверьте длительность транзакций. Держите транзакции короткими, чтобы быстро освобождать блокировки.
🔄 Роль эволюции схемы
Приложения меняются. Требования смещаются. Схема должна эволюционировать вместе с бизнесом. Схема, которая была идеальной шесть месяцев назад, сегодня может быть устаревшей из-за новых функций или увеличения объема данных.
Стратегии миграции имеют значение. Перемещение данных с небольшой таблицы на большую партиционированную таблицу может улучшить производительность. Изменение типов данных с VARCHAR на INT может сократить объем хранилища и ускорить сканирование. Эти решения принимаются после создания первоначальной ERD.
Статические ERD не учитывают рост данных. По мере масштабирования данных характеристики производительности меняются. Проектирование, которое работало с 10 000 записей, может не справиться с 10 миллионами. Именно поэтому настройка производительности — это непрерывный процесс, а не одноразовая задача.
🧩 Соображения по NoSQL
Понятие ERD применяется наиболее строго к реляционным базам данных. В средах NoSQL модель данных отличается. Хранение документов, хранилища ключ-значение и графовые базы данных по-разному обрабатывают отношения.
В хранилище документов данные могут быть встроены, чтобы избежать соединений. Это имитирует денормализацию по дизайну. В графовой базе данных отношения являются первоклассными сущностями, хранятся явно для оптимизации обхода.
Миф о гарантии ERD здесь ещё более очевиден. В NoSQL схема часто гибкая или динамическая. Производительность во многом зависит от шаблонов доступа, определённых в коде приложения, а не от жёсткой схемы.
🏁 Заключительные мысли о архитектуре данных
Создание быстрого приложения требует комплексного подхода. ERD — это критически важная отправная точка, обеспечивающая логическую организацию данных. Она предотвращает хаос и поддерживает целостность. Однако это не двигатель, который обеспечивает скорость.
Производительность — результат синергии между:
- Надежной логической моделью.
- Стратегическим индексированием.
- Эффективным написанием запросов.
- Достаточными аппаратными ресурсами.
- Правильной настройкой сети.
- Эффективными стратегиями кэширования.
Винить схему в медленных ответах — это упрощённый путь, ведущий к неправильным решениям. Идеальная схема на бумаге не компенсирует медленный диск, тайм-аут сети или плохо написанный запрос. Настоящее инженерное обеспечение производительности предполагает выход за рамки чертежа к реальному потоку данных.
Когда вы аудитируете свою систему, начните с ERD, чтобы убедиться в корректности. Затем перейдите к плану выполнения, чтобы обеспечить эффективность. Наконец, оцените инфраструктуру, чтобы обеспечить ёмкость. Только решив все уровни, вы сможете достичь той отзывчивости, которую ожидают пользователи.