Designing the data structure for a modern application requires careful consideration of how information connects, persists, and scales. At the heart of this design process lies the Entity Relationship Diagram (ERD). This visual model serves as the blueprint for understanding data entities and their interactions. As application complexity grows, the choice between a relational approach and a graph-based approach becomes critical. Both methods offer distinct advantages depending on the nature of the data relationships and the performance requirements of the system.
Understanding the nuances of each modeling technique allows architects to build systems that are robust, maintainable, and efficient. This guide explores the foundational principles, structural differences, and practical implications of choosing between relational and graph-based ERDs. By examining these methodologies in depth, teams can make informed decisions that align with their specific business logic and technical constraints.
🏛️ The Relational Approach: Structure and Integrity
The relational model has been the backbone of data management for decades. It relies on a rigid structure where data is organized into tables consisting of rows and columns. In a relational ERD, entities are represented as tables, and relationships are defined through foreign keys that link primary keys across different tables.
Core Principles of Relational Modeling
- Normalization: Relational databases prioritize normalization to reduce redundancy. Data is split into multiple tables to ensure each piece of information is stored in one place. This minimizes data anomalies during updates or deletions.
- Referential Integrity: Constraints ensure that relationships remain valid. If a record in a parent table is deleted, rules determine how child records are handled, such as cascading deletion or preventing the action.
- Schema Definition: The structure is defined before data insertion. Every column must have a specific data type and constraint, ensuring consistency throughout the dataset.
- Query Language: Accessing data typically involves Structured Query Language (SQL). This language allows for complex joins to retrieve data spread across multiple tables.
Strengths of Relational ERDs
Relational diagrams excel in scenarios where data consistency is paramount. They are ideal for systems that handle financial transactions, inventory management, or any application where strict adherence to rules is required.
- Data Integrity: The strict schema enforces rules that prevent invalid data from entering the system. This is crucial for compliance and audit trails.
- Maturity: The technology is well-understood. Tools for visualization, debugging, and maintenance are abundant and standardized.
- ACID Compliance: Relational systems typically support Atomicity, Consistency, Isolation, and Durability. This ensures that transactions are processed reliably, even in the event of system failures.
- Join Efficiency: For deeply normalized data with fewer levels of relationships, joining tables is efficient and predictable.
Limitations to Consider
Despite their strengths, relational models face challenges when dealing with highly interconnected data. As the number of relationships increases, the complexity of joins grows.
- Complex Joins: Querying data that spans many tables can result in performance degradation. Each join adds computational overhead.
- Schema Rigidity: Changing the structure of a relational database often requires migration scripts. This can be risky and time-consuming in production environments.
- Modeling Depth: Representing many-to-many relationships or recursive structures (like organizational hierarchies) requires junction tables or self-referencing keys, which can complicate the diagram and the queries.
🕸️ The Graph-Based Approach: Connections as First Class
Graph-based modeling shifts the focus from the data itself to the connections between data points. In this approach, the relationships are stored as explicitly defined links, rather than inferred through foreign keys. This makes the graph model particularly suited for networks, social structures, and recommendation engines.
Core Principles of Graph Modeling
- Nodes and Edges: Entities are represented as nodes, and relationships are represented as edges. Each node and edge can hold properties, allowing for rich metadata without additional tables.
- Traversal: Queries are designed around traversing paths from one node to another. The database engine optimizes for following links rather than scanning tables.
- Schema Flexibility: While schemas can be enforced, graph models often allow for schema-less or schema-on-read approaches. New relationship types can be added without altering the entire structure.
- Pattern Matching: Queries focus on finding specific patterns of connectivity. This is efficient for finding friends of friends, shortest paths, or shared characteristics.
Strengths of Graph ERDs
Graph diagrams shine when the value of the system lies in the connections between entities. They provide a natural representation for complex networks.
- Navigational Efficiency: Retrieving data through multiple degrees of separation is significantly faster. The database follows the links directly without scanning the entire dataset.
- Dynamic Relationships: Adding new types of connections does not require schema migrations. This supports rapid iteration and evolving business requirements.
- Visual Clarity: Graph ERDs often mirror the mental model of the data. Stakeholders can easily see how entities relate without understanding complex join conditions.
- Handling Deep Hierarchies: Recursive relationships, such as categories within categories, are represented naturally as chains of nodes and edges.
Limitations to Consider
Graph models are not a universal solution. They introduce specific challenges that must be managed.
- Write Performance: While reads are fast, maintaining relationships during high-volume writes can be more complex than simple inserts.
- Transaction Scope: Managing transactions across a distributed graph can be challenging compared to single-table row updates.
- Query Complexity: Writing effective traversal queries requires a different mindset than writing SQL joins. It involves understanding path-finding algorithms.
- Tooling Ecosystem: While growing, the ecosystem for graph data management is smaller than that of relational systems, potentially affecting hiring and support availability.
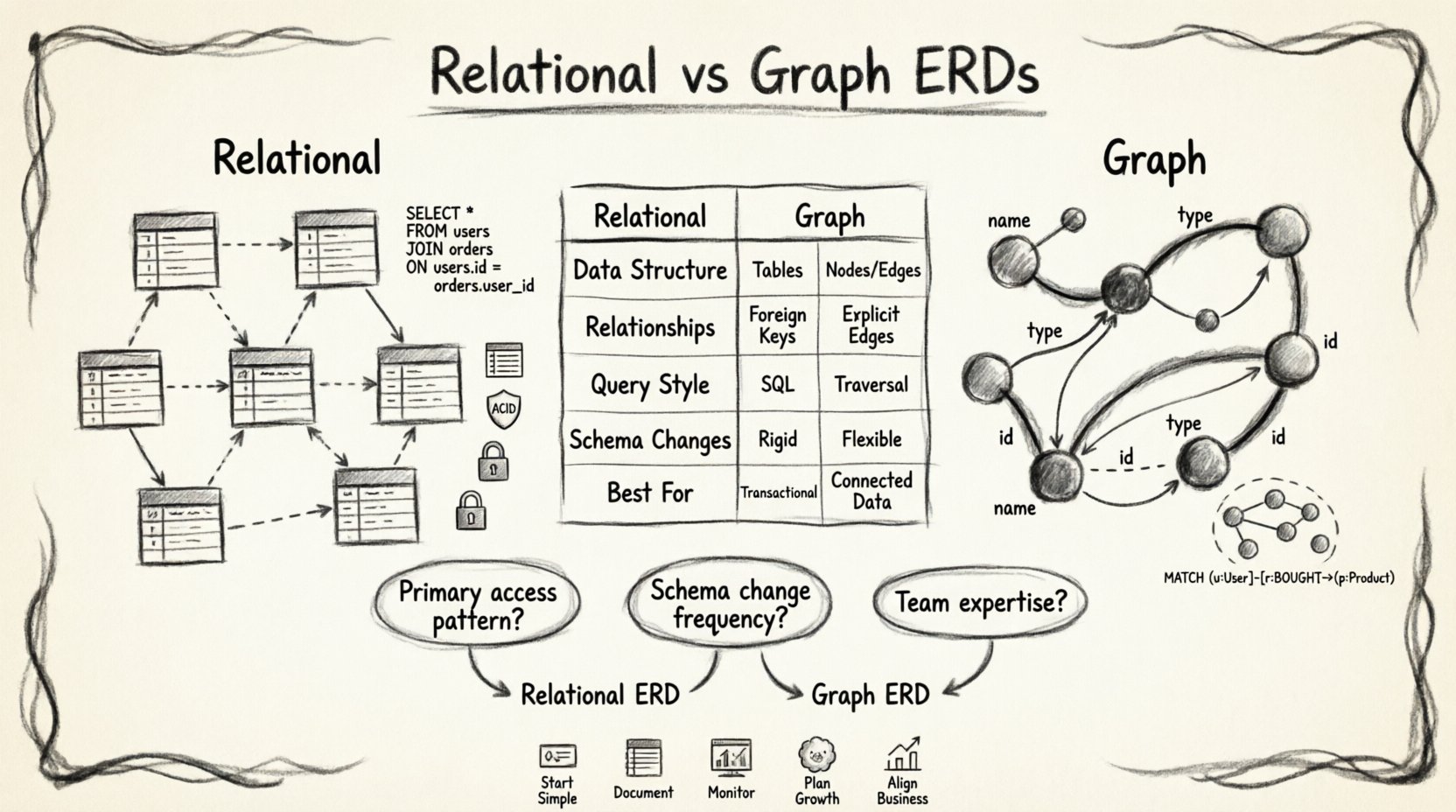
⚖️ Comparative Analysis: Key Differences
To understand the trade-offs clearly, it is helpful to view the two approaches side-by-side. The following table outlines the primary distinctions across common architectural dimensions.
| Dimension | Relational ERD Approach | Graph-Based ERD Approach |
|---|---|---|
| Data Structure | Tables, Rows, Columns | Nodes, Edges, Properties |
| Relationship Storage | Foreign Keys (Implicit) | Explicit Edges (First Class) |
| Query Style | Declarative (SQL) | Traversals / Pattern Matching |
| Schema Changes | Expensive (Migrations) | Flexible (Schema-less options) |
| Best Use Case | Transactional, Structured Data | Networked, Connected Data |
| Integrity Enforcement | Strict Constraints | Application-Level or Configurable |
| Scalability | Vertical Scaling | Horizontal Scaling |
| Query Complexity | High Joins = Slower | High Depth = Efficient |
🛠️ Implementation Considerations
Choosing between these approaches involves more than just technical preferences. It requires an evaluation of the application lifecycle, team expertise, and long-term maintenance goals.
Schema Evolution and Migration
In a relational environment, evolving the schema is a deliberate process. Adding a column or changing a data type often requires locking tables or running migration scripts. This can impact availability. In contrast, graph models allow new relationship types to be introduced without affecting existing nodes. This flexibility supports agile development cycles where requirements shift frequently.
However, this flexibility comes with a cost. Without strict schema enforcement, data quality can degrade over time. Teams must implement governance strategies to ensure that the graph remains usable and queryable.
Query Performance and Indexing
Performance optimization differs significantly between the two models. Relational systems rely on indexes on columns to speed up lookups. When joining multiple tables, the optimizer determines the most efficient execution plan.
Graph systems rely on indexes on nodes and edges. The traversal engine follows the pointers directly. For queries that require deep nesting, such as “find all suppliers who supply parts to products that are shipped to customers in region X,” a graph model avoids the exponential cost of multiple joins.
Data Consistency Requirements
Applications dealing with money, medical records, or legal contracts require strong consistency. Relational models provide built-in mechanisms to ensure that every transaction is valid before committing. Graph models can support consistency, but often require more configuration to achieve the same level of guarantee across distributed nodes.
Integration with Existing Systems
Most organizations already have a relational infrastructure. Introducing a graph model often requires polyglot persistence. This means maintaining two different data stores and ensuring they stay in sync. The integration layer adds complexity to the architecture.
🌐 Hybrid Strategies for Modern Applications
Many modern applications do not fit neatly into one category. A hybrid approach often provides the best balance. This strategy involves using a relational database for core transactional data and a graph store for relationship-heavy queries.
Microservices and Data Ownership
In a microservices architecture, different services can own different data models. The user service might use a relational model to manage accounts securely. The recommendation service might use a graph model to analyze user preferences and connections. This separation allows each service to optimize for its specific workload.
Synchronization Patterns
Keeping the two stores in sync requires careful design. Event-driven architectures can be used to propagate changes. When a record is updated in the relational store, an event is triggered to update the corresponding nodes in the graph store.
- Change Data Capture: Monitoring the transaction log of the relational database to detect changes.
- Event Sourcing: Storing state changes as a sequence of events that can be replayed to build the graph state.
- Batch Processing: Periodic jobs that rebuild the graph index from the relational source.
📊 Decision Framework
When faced with the decision of which ERD approach to adopt, consider the following questions.
- What is the primary access pattern? If the application needs to aggregate data across many tables, relational is often better. If the application needs to traverse relationships, graph is superior.
- How often does the schema change? Frequent changes suggest a graph or document-based approach. Stable schemas suit relational models well.
- What is the tolerance for data redundancy? Relational models minimize redundancy. Graph models often accept redundancy to speed up reads.
- What is the team’s expertise? Relational SQL is widely taught. Graph query languages require specific training for the team to be effective.
- What are the compliance requirements? Highly regulated industries often prefer the auditability of relational systems.
🔮 Future Trends in Data Modeling
The landscape of data modeling continues to evolve. As applications become more complex, the lines between relational and graph approaches may blur further.
Graph-Relational Hybrids
Some emerging database platforms attempt to combine the strengths of both. They offer relational tables with native graph traversal capabilities. This allows developers to use a single engine for both transactional integrity and network analysis.
AI-Driven Schema Design
Artificial intelligence is beginning to assist in data modeling. Tools can analyze usage patterns and suggest optimal schema designs. They can recommend when to denormalize data or when to introduce relationship indexes.
Cloud-Native Scaling
Cloud infrastructure is pushing both models toward horizontal scaling. Distributed relational databases and distributed graph clusters are becoming standard. This reduces the friction of scaling up and allows for global distribution of data.
📝 Summary of Best Practices
Regardless of the approach chosen, certain principles apply to all successful data modeling efforts.
- Start Simple: Do not over-engineer the initial model. Begin with the core entities and add complexity as requirements evolve.
- Document Relationships: Clearly document the cardinality and direction of relationships. This is vital for team alignment.
- Monitor Performance: Continuously monitor query performance. A model that looks good on paper may perform poorly in production.
- Plan for Growth: Design with scaling in mind. Consider how the model will handle 10x or 100x the current data volume.
- Align with Business: Ensure the data model reflects the business domain. The diagram should tell the story of the business logic.
Choosing between relational and graph-based ERDs is not about finding the perfect solution. It is about selecting the right tool for the specific problem at hand. By understanding the strengths and limitations of each approach, architects can build systems that are resilient, performant, and adaptable to future needs. The decision ultimately depends on the data’s nature and the application’s operational requirements.