











O desempenho do banco de dados é frequentemente invisível até se tornar um gargalo crítico. Quando os usuários experimentam atrasos, tempos limite ou interfaces não responsivas, a causa raiz frequentemente está abaixo da superfície da camada de aplicativo. Ela reside na arquitetura dos próprios dados. O plano que regula como os dados são estruturados, relacionados e armazenados é o Diagrama de Relacionamento de Entidades (ERD). Um ERD bem elaborado garante a integridade dos dados e a recuperação eficiente. Por outro lado, um diagrama defeituoso introduz latência que nenhum grau de cache em nível de aplicativo pode resolver completamente.
Este guia oferece uma análise aprofundada sobre a solução de problemas com consultas lentas por meio da análise da modelagem subjacente do esquema. Exploraremos como as decisões estruturais dentro do ERD influenciam diretamente os planos de execução de consultas, operações de E/S e a resposta geral do sistema. Ao compreender os mecanismos do design relacional, você poderá diagnosticar problemas de desempenho em sua origem, em vez de tratar apenas os sintomas.
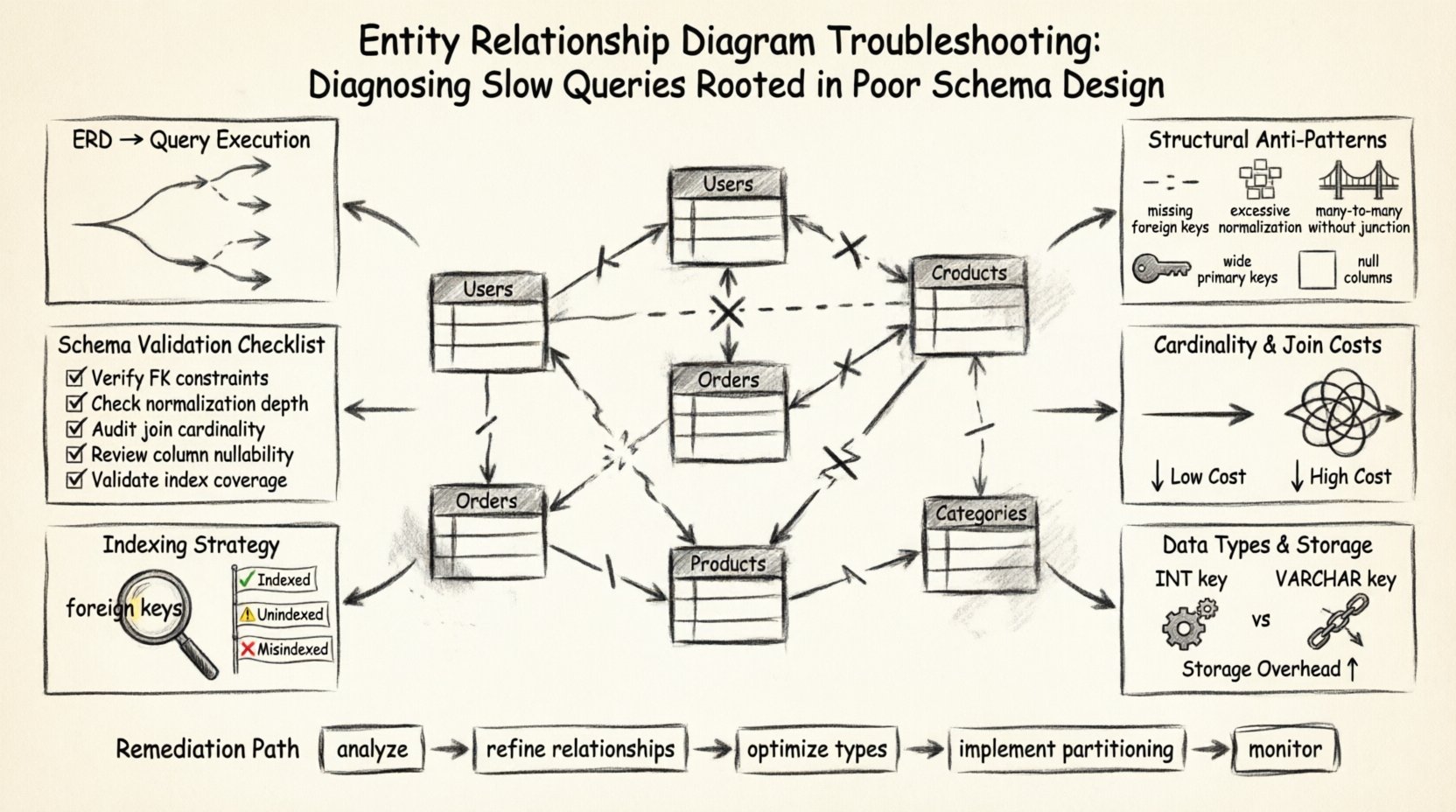
🏗️ A Fundação: Como os ERDs Influenciam a Execução de Consultas
Antes de diagnosticar um problema, é essencial compreender a relação entre a representação visual dos dados e a execução física de comandos. Um ERD não é meramente um diagrama para documentação; é um conjunto de regras que o motor do banco de dados deve aplicar. Cada linha traçada entre tabelas, cada restrição definida e cada tipo de dado especificado determina como o motor de armazenamento lê e escreve informações.
Quando uma consulta é enviada, o otimizador do banco de dados analisa a solicitação com base nos metadados do esquema. Se o esquema for ambíguo ou ineficiente, o otimizador pode escolher um caminho subótimo. Isso frequentemente se manifesta como uma varredura completa da tabela em vez de uma busca em índice, ou uma junção em loop aninhado que multiplica o tempo de processamento exponencialmente.
Áreas-chave onde o ERD impacta o desempenho incluem:
- Complexidade de Junções: O número de relacionamentos definidos determina o número de junções necessárias para recuperar dados relacionados.
- Restrições de Integridade de Dados: Chaves estrangeiras e restrições únicas adicionam sobrecarga às operações de escrita, mas podem otimizar operações de leitura.
- Níveis de Normalização: O grau em que os dados são divididos entre tabelas afeta o volume de dados escaneados durante a recuperação.
- Estratégia de Indexação: A modelagem do esquema determina onde os índices podem ser logicamente posicionados para suportar padrões comuns de consulta.
🔍 Identificando Anti-Padrões Estruturais
Muitos problemas de desempenho surgem de padrões que eram aceitáveis na fase inicial de projeto, mas tornam-se passivos à medida que o volume de dados cresce. Esses anti-padrões frequentemente aparecem sutis no diagrama, mas causam fricção significativa no motor de consultas. Abaixo está uma análise dos defeitos estruturais comuns e seu impacto direto na velocidade.
| Anti-Padrão | Indicador Visual no ERD | Impacto no Desempenho |
|---|---|---|
| Chaves Estrangeiras Ausentes | Linhas que conectam tabelas sem definições de restrição. | Permite registros órfãos, obrigando consultas complexas a filtrar dados inválidos manualmente. |
| Normalização Excessiva | Alto número de tabelas com relacionamentos de uma única coluna. | Exige junções excessivas para reconstruir uma única entidade lógica, aumentando o uso da CPU. |
| Muitos para Muitos Sem Tabela de Junção | Linhas diretas de relacionamento muitos para muitos entre duas entidades. | Motores de banco de dados geralmente exigem uma tabela de ligação; sua ausência leva a soluções ineficientes. |
| Chaves Primárias Amplas | Chaves compostas com múltiplas colunas grandes. | Aumenta o tamanho de todos os índices que referenciam esta chave, tornando as pesquisas mais lentas. |
| Colunas Preenchidas com Nulos | Atributos marcados como nulos sem motivo lógico. | Pode impedir o uso de índices ou reduzir a seletividade do índice, levando a varreduras completas. |
🔗 Cardinalidade de Relacionamento e Custos de Junção
A cardinalidade define quantas instâncias de uma entidade se relacionam com instâncias de outra. Este é o aspecto mais crítico do ERD em relação ao desempenho de consultas. Definições incorretas de cardinalidade obrigam o sistema a processar mais linhas do que o necessário para atender a uma consulta.
Ao diagnosticar consultas lentas, você deve verificar se as relações no diagrama correspondem aos requisitos lógicos da aplicação. Se uma relação for definida como Muitos para Muitos quando deveria ser Um para Muitos, o motor de consulta preparará uma junção através de uma tabela de junção que pode não existir ou pode estar preenchida de forma ineficiente.
Problemas Comuns de Cardinalidade
- Cardinalidade Não Definida:Se o diagrama não especificar se uma relação é obrigatória ou opcional, o otimizador de consultas pode assumir o pior cenário, adicionando verificações extras para valores nulos.
- Relacionamentos Recursivos:Tabelas que se referenciam a si mesmas (por exemplo, uma tabela de Funcionários que se refere a si mesma para um Gerente) podem causar profundas aninhamentos em consultas. Sem indexação adequada na coluna de referência recursiva, essas consultas tornam-se exponencialmente mais lentas.
- Dependências Circulares:Redes complexas de relacionamentos onde a Tabela A se liga à B, a B se liga à C e a C volta para a A. Essa estrutura torna difícil a navegação no grafo de dados para o motor, frequentemente resultando na criação de tabelas temporárias na memória.
Para mitigar esses problemas, certifique-se de que o ERD distinga claramente entre links opcionais e obrigatórios. Links obrigatórios permitem que o otimizador pule verificações de nulos, o que melhora a velocidade de execução. Links opcionais exigem lógica adicional para lidar com casos em que a relação não existe.
📏 Tipos de Dados e Eficiência de Armazenamento
A escolha de tipos de dados na definição do esquema tem um impacto profundo no tamanho do armazenamento e na velocidade de comparação. Uma consulta que compara duas colunas de tipos diferentes frequentemente dispara conversões implícitas. Essas conversões impedem o uso de índices e obrigam o motor a processar cada linha.
Implicações de Armazenamento
Quando o esquema usa um tipo de dado genérico para todas as colunas, como um campo de texto grande para códigos curtos, ele consome mais espaço em disco e memória. Isso reduz o tamanho efetivo do pool de buffer, significando que menos páginas de dados quentes podem ser mantidas na memória. Consequentemente, o sistema precisa ler mais dados do subsistema de disco mais lento.
Desempenho de Comparação
As comparações de inteiros são significativamente mais rápidas que as comparações de strings. Se o ERD definir uma chave estrangeira como uma string (por exemplo, VARCHAR) em vez de um inteiro (por exemplo, INT), a operação de junção precisará comparar caractere por caractere, em vez de usar comparação numérica binária. Isso adiciona ciclos de CPU a cada linha processada.
- Use Tipos de Comprimento Fixo:Para campos como códigos de país ou bandeiras de status, use strings de comprimento fixo. Strings de comprimento variável introduzem sobrecarga para calcular o comprimento em cada leitura.
- Evite Texto Grande em Chaves:Nunca use uma coluna com grande volume de texto como chave primária ou estrangeira. Isso aumenta todos os índices que a referenciam.
- Mantenha os Tipos de Pai e Filho Alinhados:Certifique-se de que o tipo de dado na tabela filha corresponda exatamente ao da tabela pai. Mesmo uma pequena diferença (por exemplo, INT vs BIGINT) pode forçar uma conversão durante as junções.
🔑 Visibilidade e Estratégia de Indexação
Um ERD é a representação visual da estrutura lógica, mas também deve informar a estratégia física de indexação. Embora índices sejam frequentemente adicionados após a construção do esquema, a fase de design deve antecipar onde eles são necessários. Uma consulta que filtra por uma coluna não indexada é um indicador principal de uma lacuna no design.
Oportunidades de Indexação no ERD
Ao revisar o diagrama em busca de gargalos de desempenho, procure colunas que sejam frequentemente usadas em condições de pesquisa ou junções.
- Chaves Estrangeiras: Elas quase sempre devem ser indexadas. Se uma consulta junta a Tabela A com a Tabela B por meio de uma chave estrangeira e a chave na Tabela B não estiver indexada, o motor precisará varrer toda a Tabela B para cada linha na Tabela A.
- Bandeiras de Status: Colunas que definem o estado de um registro (por exemplo, Is_Active, Order_Status) são frequentemente usadas em cláusulas WHERE. Se essas colunas não estiverem indexadas, a filtragem se torna uma varredura completa da tabela.
- Faixas de Data: Tabelas com rastreamentos de auditoria ou registros de transações frequentemente consultam por data. A coluna de data deve ser indexada para permitir varreduras eficientes por faixa.
É crucial equilibrar o número de índices em relação ao desempenho de gravação. Cada índice adiciona sobrecarga às operações INSERT, UPDATE e DELETE. No entanto, um esquema mal indexado com alta carga de leitura causará latência no sistema que supera o custo de gravação. O ERD ajuda a visualizar quais tabelas são de leitura intensiva (por exemplo, tabelas de consulta) em comparação com as de gravação intensiva (por exemplo, registros de transações), orientando a decisão de indexação.
🚫 A Patologia da Junção
Uma das fontes mais comuns de consultas lentas é o caminho de junção. Isso se refere à sequência na qual o motor do banco de dados conecta tabelas para atender a uma solicitação. Um esquema mal projetado pode forçar o motor a seguir um caminho logicamente correto, mas computacionalmente custoso.
Produtos Cartesianos
Se o esquema não tiver restrições adequadas ou se a lógica da consulta não especificar corretamente as condições de junção, o motor pode gerar um produto cartesiano. Isso ocorre quando cada linha da Tabela A é combinada com cada linha da Tabela B. O conjunto de resultados cresce exponencialmente, e a consulta pode expirar ou consumir toda a memória disponível.
No ERD, isso geralmente acontece quando uma relação muitos para muitos não é adequadamente mediada por uma tabela de junção, ou quando a tabela de junção está faltando restrições de chave estrangeira necessárias.
Subconsulta vs. Junção
O design do esquema influencia se uma consulta pode ser executada como uma junção simples ou exige uma subconsulta. Subconsultas frequentemente executam a consulta interna uma vez para cada linha da consulta externa, levando a uma complexidade de tempo quadrática. Um esquema normalizado que permite junções diretas é geralmente preferido em relação a estruturas denormalizadas que forçam o uso de subconsultas.
✅ Lista de Verificação de Validação de Esquema
Para diagnosticar sistematicamente consultas lentas com base no ERD, realize uma revisão estruturada. Essa lista de verificação garante que você examine cada componente crítico do design.
1. Revise as Restrições de Chave Estrangeira
- Todas as chaves estrangeiras estão explicitamente definidas no diagrama?
- Elas incluem regras de propagação que poderiam causar movimentação de dados indesejada?
- O tipo de dado em ambos os lados da relação é idêntico?
2. Analise a Frequência de Junção
- Identifique as tabelas que são unidas com mais frequência na lógica da aplicação.
- Essas tabelas são adjacentes no diagrama, ou o caminho exige percorrer várias tabelas intermediárias?
- Alguma dessas tabelas intermediárias pode ser consolidada para reduzir a profundidade da junção?
3. Verifique a Nulidade
- As colunas que nunca são nulas estão explicitamente marcadas como NOT NULL?
- O esquema permite valores NULL em colunas que fazem parte de um índice?
4. Verifique os Tipos de Dados
- Campos numéricos estão usando o tamanho apropriado mais pequeno (por exemplo, TINYINT em vez de BIGINT)?
- Campos de texto estão usando o comprimento correto para evitar truncagem ou armazenamento excessivo?
5. Avaliar a Cobertura de Índices
- Os chaves primárias e estrangeiras têm índices?
- Colunas frequentemente filtradas estão indexadas?
- Há um índice composto para consultas comuns de múltiplas colunas?
🛠️ Passos Práticos para a Correção
Uma vez que o ERD tenha sido analisado e os problemas identificados, a próxima fase é a correção. Isso envolve modificar o esquema para alinhar com os requisitos de desempenho sem comprometer a integridade dos dados.
Aprimorar Relacionamentos:Se o ERD mostrar relacionamentos excessivamente complexos, considere simplificá-los. Isso pode significar introduzir desnormalização em áreas específicas, com alta carga de leitura, para reduzir a necessidade de junções. Por exemplo, armazenar uma contagem em cache de itens relacionados na tabela pai pode eliminar a necessidade de juntar e contar sempre.
Otimizar Tipos de Dados:Mude os tipos de dados para alternativas mais eficientes. Se uma data for armazenada apenas para o dia, use um tipo somente de data em vez de um datetime com hora. Se um ID for numérico, certifique-se de que não esteja armazenado como uma string.
Implementar Particionamento:Para tabelas muito grandes, o ERD pode precisar refletir uma estratégia de particionamento. Embora o particionamento seja frequentemente um detalhe de implementação física, o design lógico deve levar em conta como os dados são agrupados. O particionamento por data ou região pode permitir que o motor varra apenas os segmentos relevantes dos dados.
🔎 Considerações Finais
A solução de problemas de desempenho é um processo iterativo. O ERD serve como o artefato central nesse processo. Tratando o diagrama como um documento vivo que reflete tanto a estrutura lógica quanto as restrições de desempenho física, você pode manter um sistema de banco de dados que permaneça responsivo à medida que os dados crescem.
Lembre-se de que nenhuma única arquitetura serve para todos os cenários. Um esquema otimizado para gravações de alta frequência pode se comportar de forma diferente de um otimizado para consultas analíticas complexas. O objetivo é alinhar o design do esquema com os padrões específicos de acesso da sua aplicação. Revise regularmente o ERD com base em métricas reais de desempenho de consultas para detectar desvios precocemente.
Ao focar na integridade estrutural do modelo de dados, você elimina as causas raiz da latência. Essa abordagem é mais sustentável do que aplicar correções na camada de aplicação. Uma base de esquema sólida garante que o sistema possa escalar, adaptar-se e funcionar de forma confiável ao longo do tempo.
Continue monitorando os planos de execução de consultas após fazer alterações. Visualizar o plano de execução pode confirmar que o otimizador está utilizando corretamente os novos índices e restrições. Esse ciclo de feedback completa o processo de solução de problemas, garantindo que as melhorias teóricas no ERD se traduzam em ganhos de desempenho tangíveis no ambiente de produção.