











Na evolução da arquitetura de software, poucos desafios são tão persistentes quanto a tensão entre o modelamento histórico de dados e os requisitos modernos de escalabilidade. Muitas organizações se veem gerenciando sistemas de backend baseados em Diagramas de Relacionamento de Entidades (ERDs) projetados anos atrás, frequentemente com pressupostos diferentes sobre carga, concorrência e hardware. Quando um esquema legado enfrenta demandas de alto throughput, a degradação de desempenho não é meramente uma inconveniência; é uma falha estrutural. Este guia explora as realidades técnicas de otimizar esses diagramas sem descartar a lógica de negócios embutida neles.
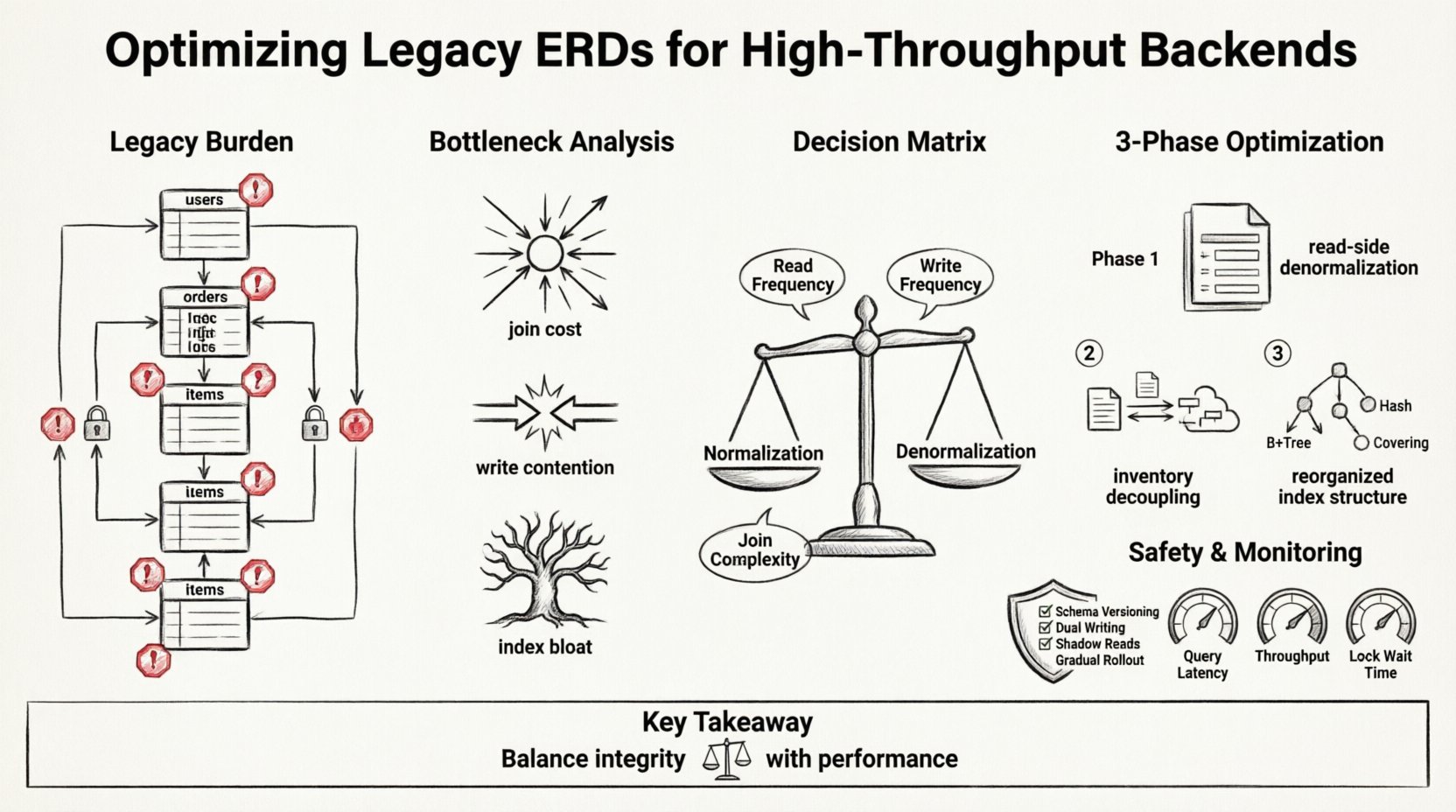
Compreendendo a Carga do Legado 💾
Os ERDs legados frequentemente refletem as necessidades do passado. Eles priorizam a integridade dos dados e a normalização acima de tudo. Em um ambiente de nó único com tráfego moderado, essa abordagem funciona bem. A aderência rigorosa à Terceira Forma Normal (3NF) minimiza a redundância e garante consistência. No entanto, quando o sistema escala para milhões de transações por segundo, o custo dessas relações torna-se proibitivo.
Considere as seguintes características comuns encontradas em esquemas mais antigos:
- Cadeias de Junções Profundas: Consultas que exigem cinco ou mais junções para recuperar um único registro.
- Restrições de Chave Estrangeira Pesadas:Verificações rígidas de integridade que bloqueiam gravações concorrentes.
- Bloqueio Centralizado:Pontos quentes em tabelas específicas que se tornam gargalos durante picos de carga.
- Falhas na Denormalização:A ausência de armazenamentos redundantes de dados para operações intensivas de leitura.
Esses padrões não são intrinsecamente “errados”. Eram corretos para o seu tempo. O desafio está em adaptá-los a um ambiente distribuído e de alta concorrência, onde a latência é a moeda principal.
Analisando os Gargalos 🔍
Antes de alterar o diagrama, é necessário entender onde o sistema perde desempenho. Backends de alto throughput são frequentemente limitados por operações de I/O, latência de rede entre serviços e contenção de bloqueios. O ERD determina como os dados são acessados, influenciando diretamente essas métricas.
1. Custos de Junção
Cada junção é uma leitura em disco e um ciclo de CPU. Em um sistema legado, uma única solicitação de perfil de usuário pode desencadear uma cascata de consultas em cinco tabelas. À medida que o tráfego aumenta, o banco de dados passa mais tempo navegando pelas relações do que executando lógica. Isso é especialmente verdadeiro quando os índices não conseguem cobrir todo o caminho de junção.
2. Conteúdo de Escrita
A normalização exige escrever dados em múltiplas localizações para manter a integridade. Se uma transação atualiza um perfil de usuário e registra um evento de atividade, duas tabelas precisam ser modificadas. Se essas tabelas residirem no mesmo shard, a duração do bloqueio aumenta. Se estiverem distribuídas, a transação torna-se um compromisso de duas fases, adicionando sobrecarga significativa.
3. Inchaço de Índices
Para suportar junções complexas, os sistemas legados acumulam índices. Com o tempo, esses índices tornam lentas as operações de escrita. O banco de dados deve atualizar cada índice em cada inserção ou atualização. Em cenários de alto throughput, essa amplificação de escrita pode saturar o subsistema de armazenamento.
Estratégia de Refatoração: Normalização versus Denormalização ⚖️
O cerne da otimização reside em repensar o equilíbrio entre integridade de dados e velocidade de consulta. Embora a normalização rígida garanta consistência, sistemas de alto desempenho frequentemente exigem uma denormalização pragmática. Isso não significa abandonar a estrutura; significa aceitar redundância para reduzir a latência.
A tabela a seguir apresenta a matriz de decisão para alterações no esquema:
| Critérios | Manter Normalizado | Aplicar Denormalização |
|---|---|---|
| Frequência de Leitura | Baixa (processamento em lote) | Alto (painéis em tempo real) |
| Frequência de Gravação | Alto (transações principais) | Baixo (registros de auditoria) |
| Requisito de Consistência | ACID Forte | Consistência eventual aceitável |
| Complexidade de Junção | Simples (1-2 junções) | Complexo (3+ junções) |
| Volatilidade dos Dados | Estático (dados de referência) | Dinâmico (estado do usuário) |
Implementar esta estratégia exige planejamento cuidadoso. Você não está apenas mudando tabelas; está mudando a forma como o aplicativo percebe os dados.
Demonstração do Estudo de Caso: Motor de Transações de Comércio Eletrônico 🛒
Para ilustrar este processo, considere uma plataforma de comércio eletrônico fictícia. O sistema legado gerencia o processamento de pedidos, o gerenciamento de estoque e os perfis de clientes. O diagrama ER foi projetado para uma única instância de banco de dados, com foco na prevenção da venda excessiva de estoque.
O Estado Legado
No projeto original, a pedidos tabela referenciava itens_do_pedido, que referenciava produtos. A produtos tabela referenciava estoque. Para exibir uma página de detalhes do pedido, o backend executava uma consulta que unia todas as quatro tabelas. Além disso, cada atualização de pedido exigia um bloqueio na tabela de estoque para garantir precisão.
Problemas Principais Identificados:
- Latência: Os tempos de carregamento da página aumentaram para 800ms durante os eventos de venda.
- Bloqueios:Alta concorrência nas atualizações do estoque causou rollback de transações.
- Escalabilidade: O banco de dados não pôde particionar a
estoquetabela devido às frequentes junções entre partições.
O Processo de Otimização
A equipe decidiu refatorar o ERD em três fases. O objetivo era desacoplar os caminhos de leitura dos caminhos de escrita.
Fase 1: Denormalização do Lado de Leitura
O primeiro passo envolveu criar uma cópia de segurança dos dados do produto dentro dos registros de pedidos. Em vez de fazer junção com a produtostabela no momento da consulta, o sistema copiou o nome do produto, o preço e o SKU para a order_itemstabela no momento da compra.
- Benefício: O histórico de pedidos permanece preciso mesmo que os dados do produto mudem posteriormente.
- Benefício: A consulta já não exige uma junção com a tabela de produtos.
- Risco: Discrepâncias de preço se um produto for atualizado após o pedido ter sido feito.
- Mitigação: A interface exibe o preço no momento da compra como “Preço Histórico”.
Fase 2: Desacoplamento do Estoque
A tabela de estoque era a fonte de conflito. A equipe transferiu o rastreamento de estoque para uma loja separada de gravação de alta frequência. O sistema de pedidos envia uma mensagem assíncrona para reservar estoque em vez de executar um bloqueio SQL síncrono.
- Benefício: A taxa de transferência de escrita aumentou em 400%.
- Benefício: Não há mais bloqueio na transação principal de pedidos.
- Compromisso: Pedidos podem ser feitos mesmo que o estoque esteja temporariamente fora de sincronia.
- Mitigação: Um processo em segundo plano reconcilia as discrepâncias entre o sistema de pedidos e o estoque.
Fase 3: Reestruturação de Índices
Com dados denormalizados, os índices antigos nas chaves estrangeiras tornaram-se redundantes. A equipe removeu-os e adicionou índices compostos otimizados para os novos padrões de consulta. Por exemplo, um índice em (customer_id, criado_em) substituiu a necessidade de escanear toda a tabela de pedidos.
Fases de Implementação e Segurança 🛡️
Alterar um esquema em produção é uma operação de alto risco. As seguintes fases garantem estabilidade durante a transição.
1. Versionamento de Esquema
Não remova imediatamente as colunas antigas. Mantenha-as no lugar, mas marque-as como obsoletas. Isso permite que o aplicativo volte atrás se a nova lógica falhar. Use scripts de migração que adicionem colunas antes de removê-las.
2. Escrita Dupla
Durante a transição, escreva dados na estrutura antiga e na nova. A lógica da aplicação direciona leituras para a nova estrutura, mas as gravações vão para ambas. Isso fornece um ponto de fallback se o novo esquema estiver incompleto.
3. Leituras em Sombra
Antes de redirecionar o tráfego em produção, execute as novas consultas em uma cópia dos dados de produção. Compare os resultados das consultas legadas com as consultas otimizadas para garantir a precisão dos dados.
4. Implantação Gradual
Use bandeiras de recurso para habilitar o novo esquema para uma pequena porcentagem de usuários (por exemplo, 1%). Monitore as taxas de erro e a latência. Se as métricas permanecerem estáveis, aumente a porcentagem de forma incremental.
Monitoramento e Validação 📊
A otimização não é um evento único. Exige monitoramento contínuo para garantir que as mudanças sejam sustentáveis sob carga. Indicadores-chave de desempenho (KPIs) devem ser estabelecidos antes de iniciar a refatoração.
Métricas Principais a Serem Monitoradas:
- Latência de Consulta: Tempos de resposta nos percentis 95º e 99º.
- Throughput: Transações por segundo (TPS) sem erros.
- Tempo de Espera por Bloqueio: Tempo médio que uma transação espera por um bloqueio.
- Atraso de Replicação: Atraso entre os nós primários e de réplica (se aplicável).
- Taxa de Acerto no Cache: Eficácia das estratégias de cache de leitura.
Os limites de alerta devem ser definidos com base nas métricas de baseline coletadas antes das alterações. Se houver picos de latência, o sistema deve reverter automaticamente para o esquema legado ou redirecionar o tráfego para um serviço de fallback.
Armadilhas Comuns para Evitar ⚠️
Mesmo com um plano sólido, a dívida técnica frequentemente ressurge de maneiras inesperadas. Esteja atento a esses erros comuns.
- Ignorar os Custos de Migração de Dados:Mover terabytes de dados para novas estruturas leva tempo. Planeje janelas de manutenção ou ferramentas de migração em segundo plano.
- Sobreo otimizar leituras:Se você desnormalizar demais, o desempenho das escritas sofrerá. Equilibre a proporção de leitura/escrita da sua carga de trabalho específica.
- Esquecer a Lógica do Aplicativo:A mudança no esquema é apenas metade da batalha. O código do aplicativo deve ser atualizado para lidar com a nova estrutura de dados.
- Descuidar da Testagem:Testes unitários geralmente cobrem os caminhos felizes. Testes de estresse são necessários para encontrar condições de corrida no novo esquema.
Estratégias de Manutenção de Longo Prazo 🔧
Uma vez que a otimização esteja concluída, a equipe deve manter a nova arquitetura. A documentação é crítica. Cada tabela, coluna e relacionamento deve ser rotulado com sua finalidade e responsabilidade.
Auditorias Regulares:
Agende revisões trimestrais do ERD. Identifique tabelas que estão crescendo de forma desproporcional ou consultas que estão ficando mais lentas. O crescimento do banco de dados frequentemente revela novos gargalos que não estavam presentes durante a refatoração inicial.
Verificações Automatizadas de Esquema:
Integre a validação de esquema na pipeline CI/CD. Impedir que desenvolvedores adicionem novos joins ou removam restrições críticas sem aprovação. Isso garante que o sistema permaneça otimizado ao longo do tempo.
Treinamento da Equipe:
Garanta que todos os engenheiros de back-end compreendam o novo modelo de dados. Uma compreensão compartilhada do esquema reduz a probabilidade de introduzir nova dívida técnica por meio de consultas ad hoc.
Pensamentos Finais sobre Modelagem de Dados 🔗
Otimizar um Diagrama de Relacionamento de Entidades legado é um equilíbrio entre precisão histórica e escalabilidade futura. Não existe um único esquema “correto”. O modelo certo é aquele que apoia seus objetivos de negócios atuais, permitindo espaço para crescimento.
Ao focar nos gargalos específicos do seu sistema—sejam custos de junção, contenção de bloqueios ou inflação de índices—você pode fazer melhorias direcionadas. O estudo de caso demonstra que estruturas profundamente enraizadas podem ser modernizadas sem uma reescrita completa. A chave é proceder de forma metódica, validar rigorosamente e manter uma visão clara das trade-offs envolvidas.
A modelagem de dados não é estática. Ela evolui com o tráfego que atende. Trate seu ERD como um documento vivo que exige o mesmo cuidado e atenção que o código que o consulta. Com a abordagem correta, você pode transformar um sistema legado em um motor de alto desempenho capaz de lidar com as demandas da web moderna.