











Tworzenie oprogramowania dla chmury wymaga zmiany podejścia. Tradycyjne architektury monolityczne opierały się na silnie powiązanych komponentach współdzielących pamięć i lokalne systemy plików. Aplikacje typu cloud-native działają jednak w rozproszonych środowiskach, często obejmujących wiele sieci i granic zabezpieczeń. Aby poradzić sobie z tą złożonością, inżynierowie potrzebują jasnych wizualnych przedstawień, jak informacje przepływają przez system. To właśnie w tym miejscu diagram przepływu danych (DFD) staje się niezbędnym narzędziem. Przyporządkowując przepływ danych między procesami, magazynami i zewnętrznymi jednostkami, zespoły mogą projektować wytrzymałe, skalowalne i bezpieczne systemy, nie opierając się na domysłach.
Ten przewodnik omawia sposób stosowania zasad DFD specjalnie w kontekście cloud-native. Przeanalizujemy podstawowe elementy, konieczne dostosowania dla systemów rozproszonych oraz praktyczne kroki tworzenia diagramów, które pozostają użyteczne w miarę ewolucji infrastruktury. Niezależnie od tego, czy projektujesz ekosystem mikroserwisów, czy łańcuch funkcji bezserwerowych, zrozumienie przepływu danych jest fundamentem niezawodnej inżynierii.
🌩️ Zrozumienie przesunięcia w kierunku modelowania typu cloud-native
W tradycyjnym środowisku lokalnym system często istnieje w jednym fizycznym obszarze. Dane przepływają lokalnie między procesami. W środowisku typu cloud-native granice są płynne. Jedna logiczna aplikacja może składać się z dziesiątek niezależnych usług działających w kontenerach, zarządzanych na różnych regionach lub strefach dostępności. Opóźnienia sieciowe, spójność ostateczna i zasady zabezpieczeń wprowadzają zmienne, których nie ma w projektach monolitycznych.
Podczas tworzenia diagramu przepływu danych dla tego środowiska należy uwzględnić:
- Granice sieciowe:Dane często przechodzą przez publiczne sieci lub bezpieczne VPC. Każdy skok reprezentuje potencjalny punkt awarii lub opóźnienie.
- Zarządzanie stanem:Usługi chmury są często bezstanowe. Procesy muszą pobierać stan z zewnętrznych magazynów, a nie przechowywać go w pamięci.
- Komunikacja asynchroniczna:Wywołania synchroniczne (zapytanie-odpowiedź) nie zawsze są najlepszym rozwiązaniem. Kolejki komunikatów i strumienie zdarzeń zmieniają sposób przepływu danych między składnikami.
- Strefy zabezpieczeń:Dane wchodzące do strefy muszą zostać uwierzytelnione i zaszyfrowane przed dotarciem do procesów wewnętrznych.
Wizualizacja tych ograniczeń na wczesnym etapie zapobiega zadłużeniu architektonicznemu. Diagram, który pomija segmentację sieciową lub wymagania dotyczące bezstanowości, prowadzi do systemu trudnego w debugowaniu i skalowaniu. Celem nie jest tylko pokazanie, dokąd idzie dane, ale również wyróżnienie, gdzie jest przekształcane, przechowywane i zabezpieczane.
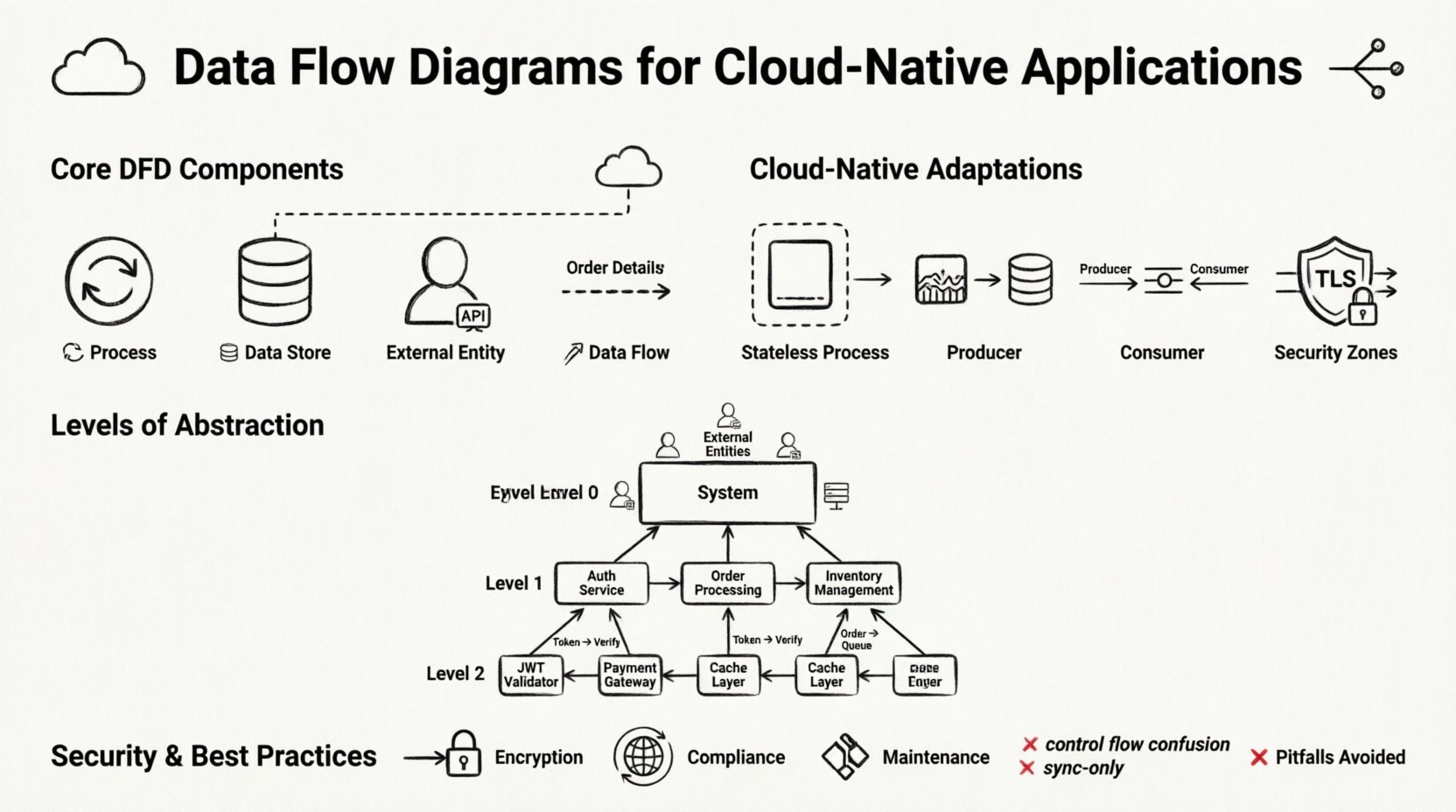
🧩 Podstawowe elementy diagramu przepływu danych
Zanim dostosujemy te diagramy do chmury, musimy ustalić standardowe elementy konstrukcyjne. DFD nie jest schematem blokowym; nie pokazuje logiki sterowania ani czasu. Pokazuje przepływ danych. Cztery podstawowe elementy pozostają stałe, nawet w systemach rozproszonych.
1. Procesy 🔄
Proces reprezentuje działanie, które przekształca dane wejściowe w dane wyjściowe. W kontekście cloud-native proces często jest funkcją, aplikacją kontenerową lub wystąpieniem mikroserwisu. Ważne jest, aby procesy nazywać według tego, co robią, a nie według ich technicznej nazwy. Na przykład zamiast „UserService API” użyj „Weryfikuj dane logowania użytkownika”. To utrzymuje diagram skupiony na logice przekształcania danych.
- Przekształcanie: Każdy proces musi w jakiś sposób zmienić dane. Jeśli dane przechodzą bez zmian, nie powinny być przedstawiane jako proces.
- Ukrywanie szczegółów: W mikroserwisach każdy proces jest ukryty. Wewnętrzna logika jest ukryta; dla diagramu mają znaczenie tylko interfejsy wejściowe i wyjściowe.
- Bezstanowość: Większość procesów chmury jest chwilowa. Nie zachowują pamięci poprzednich interakcji. To musi być odzwierciedlone w wymaganiach przepływu danych.
2. Magazyny danych 🗄️
Magazyn danych reprezentuje miejsce, gdzie dane spoczywają, gdy nie są przetwarzane. W chmurze może to być baza danych relacyjna, magazyn dokumentów NoSQL, pojemnik przechowywania obiektów lub rozproszona pamięć podręczna. W przeciwieństwie do systemu plików, magazyny danych w chmurze są często dostępne przez sieć.
- Trwałość:Dane muszą być zapisane w magazynie, jeśli mają przetrwać awarię procesu lub jego ponowne uruchomienie.
- Wzorce dostępu: Magazyny o wysokim obciążeniu odczytem różnią się od magazynów o wysokim obciążeniu zapisem. Diagram powinien wskazywać rodzaj dostępu, jeśli ma istotny wpływ na architekturę.
- Bezpieczeństwo:Magazyny danych poufnych wymagają różnych kontrolek dostępu. Ta różnica jest kluczowa dla audytów bezpieczeństwa.
3. Zewnętrzne jednostki 👥
Zewnętrzne jednostki to źródła lub miejsca docelowe danych poza granicami systemu. Mogą to być użytkownicy, interfejsy API firm trzecich, systemy dziedziczne lub urządzenia sprzętowe. W diagramie opartym na chmurze zewnętrzne jednostki często reprezentują krawędź internetu lub inne usługi chmurowe.
- Zaufane vs. Niezaufane:Rozróżnij dane pochodzące z znanego wewnętrznego serwisu od ruchu internetowego publicznego.
- Wyzwalanie:Jednostki często inicjują przepływ. Żądanie użytkownika wywołuje proces; zaplanowana zadanie wywołuje synchronizację danych.
4. Przepływy danych 📡
Przepływy danych to strzałki łączące komponenty. Odpowiadają one za przesyłanie danych. W środowiskach chmurowych te przepływy często przechodzą przez sieci. Etykiety na strzałkach są kluczowe. Powinny opisywać pakiet danych, a nie protokół. Na przykład oznacz strzałkę jako „Szczegóły zamówienia”, a nie „HTTP POST”. Dzięki temu diagram pozostaje niezależny od protokołu i przyszłościowy.
- Kierunek:Przepływy są jednokierunkowe. Jeśli dane poruszają się tam i z powrotem, narysuj dwie osobne strzałki.
- Objętość:Przepływy danych o wysokiej objętości mogą wymagać innej infrastruktury (np. dedykowanego przepustowości) niż przepływy sterujące o niskiej objętości.
- Szyfrowanie:Przepływy danych przechodzące przez granice bezpieczeństwa muszą być oznaczone jako zaszyfrowane, aby podkreślić wymagania zgodności.
☁️ Dostosowanie DFD do systemów rozproszonych
Standardowe DFD zakładają spójny system. Systemy oparte na chmurze są rozproszone. Aby DFD był użyteczny w tym kontekście, należy jawnie modelować rozproszony charakter infrastruktury. Oznacza to dodanie warstw abstrakcji reprezentujących topologię sieci i granice usług.
Granice usług
Usługi mikroserwisowe to standardowe elementy budowlane aplikacji opartych na chmurze. Każda usługa powinna idealnie być odrębnym procesem na diagramie. Jednak rysowanie każdej usługi osobno może prowadzić do zamieszania. Powszechną metodą jest grupowanie powiązanych usług w domenie logicznej, takiej jak „Domena rozliczeń” lub „Domena zarządzania użytkownikami”. Pozwala to zobaczyć przepływ na poziomie wysokim, jednocześnie ukrywając wewnętrzną złożoność.
Bramy interfejsów API
Większość aplikacji opartych na chmurze znajduje się za bramą interfejsu API lub balancerem obciążenia. Ten komponent działa jako jedyny punkt wejścia. W DFD brama jest procesem routującym żądania. Obsługuje uwierzytelnianie, ograniczanie szybkości oraz tłumaczenie protokołów. Nie traktuj bramy jako prostego przewodu; aktywnie modyfikuje przepływ danych.
Architektury oparte na zdarzeniach
Wiele nowoczesnych systemów wykorzystuje wzorce oparte na zdarzeniach. Producent generuje zdarzenie, a konsument przetwarza je później. Powoduje to zerwanie synchronicznego związku między procesem a przepływem danych. W DFD przedstawia się to za pomocą kolejki zdarzeń lub strumienia jako magazynu danych. Producent zapisuje zdarzenie; konsument je odczytuje. Ta rozłączność jest kluczowa dla odporności.
| Komponent | Tradycyjna monolityczna | Adaptacja dla systemów opartych na chmurze |
|---|---|---|
| Proces | Funkcja w pamięci | Zapakowany mikroserwis / funkcja bezserwerowa |
| Magazyn danych | Lokalny plik / baza danych SQL | Zarządzana baza danych w chmurze / magazyn obiektów |
| Przepływ | Wywołanie pamięci lokalnej | HTTP / gRPC / kolejka komunikatów |
| Stan | Współdzielona pamięć | Zewnętrzny magazyn stanu |
📉 Poziomy abstrakcji w architekturze chmury
Złożone systemy wymagają wielu poziomów diagramów. Próba uchwycenia każdej szczegółowości w jednym widoku prowadzi do zamieszania. Standardowy sposób DFD poziomów 0, 1 i 2 działa dobrze dla systemów chmury, gdy jest stosowany poprawnie.
Poziom 0: Diagram kontekstowy
Diagram kontekstowy przedstawia cały system jako pojedynczy proces. Wyróżnia zewnętrzne jednostki oddziałujące z systemem. Dla aplikacji w chmurze definiuje on obręb. Odpowiada na pytanie: „Co wchodzi do systemu, a co z niego wychodzi?” Jest to najwyższy poziom widoku, przydatny dla stakeholderów, którzy potrzebują zrozumienia zakresu bez szczegółów technicznych.
- Skupienie:Granice systemu i zewnętrzne interfejsy.
- Szczegóły:Minimalne. Jeden centralny proces.
- Przypadek użycia:Definicja zakresu projektu i planowanie bezpieczeństwa na wysokim poziomie.
Poziom 1: Główne procesy
Poziom 1 dzieli centralny proces na główne podprocesy. W kontekście chmury, są to zwykle główne domeny funkcjonalne. Na przykład, diagram poziomu 1 dla platformy e-commerce może pokazywać „Przetwarzanie zamówień”, „Zarządzanie zapasami” i „Obsługa płatności” jako odrębne procesy. Ten poziom ujawnia, jak dane przepływają między głównymi grupami usług.
- Skupienie:Główne moduły funkcjonalne i ich wzajemne oddziaływania.
- Szczegóły:Wejścia i wyjścia dla każdego głównego modułu.
- Przypadek użycia:Przegląd architektoniczny i dekompozycja usług.
Poziom 2: Szczegółowa logika
Poziom 2 przechodzi do szczegółów konkretnych podprocesów. To tutaj stają się istotne szczegóły implementacji technicznej. Na przykład proces „Obsługa płatności” może zostać rozszerzony, aby pokazać „Weryfikacja karty”, „Zaczerpanie środków z konta” i „Aktualizacja paragonu”. Ten poziom jest używany przez programistów implementujących konkretne usługi.
- Skupienie: Wewnętrzna logika określonych usług.
- Szczegóły: Określone przekształcenia danych i lokalne magazyny danych.
- Przypadek użycia: Implementacja w procesie rozwoju i scenariusze testowania.
🔒 Bezpieczeństwo i zgodność w mapowaniu danych
Bezpieczeństwo nie jest dodatkowym aspektem w rozwoju aplikacji opartych na chmurze; jest wymaganiem projektowym. Diagram przepływu danych to doskonały narzędzie do identyfikacji ryzyk bezpieczeństwa. Śledząc ścieżkę danych, możesz wykryć miejsca, w których wrażliwe informacje mogą zostać ujawnione lub nieodpowiednio przechowywane.
Identyfikacja danych wrażliwych
Nie wszystkie przepływy danych są jednakowe. Dane osobowe (PII), rekordy finansowe i dane zdrowotne wymagają bardziej ostrożnego traktowania. W swoim diagramie oznacz przepływy zawierające dane wrażliwe. Zapewnia to, że każdy proces dotykający tych danych zostanie przejrzany pod kątem zgodności.
- Szyfrowanie w tranzycji: Przepływy przekraczające granice sieciowe muszą być szyfrowane (TLS/SSL). Jasno oznacz te przepływy.
- Szyfrowanie w spoczynku: Magazyny danych przechowujące wrażliwe informacje muszą być szyfrowane. Wskaż to w etykiecie magazynu danych.
- Kontrola dostępu: Zidentyfikuj, które procesy mogą odczytywać lub zapisywać w określonych magazynach danych. Pomaga to w ustawieniu kontroli dostępu opartej na rolach (RBAC).
Granice zgodności
Różne regiony mają różne przepisy dotyczące suwerenności danych. Dane mogą wymagać pozostania w określonej granicy geograficznej. Diagram przepływu danych pomaga wizualizować te ograniczenia. Jeśli proces w Regionie A wysyła dane do Regionu B, ten przepływ powinien zostać oznaczony do przeglądu prawno-etycznego. Zapobiega to przypadkowym naruszeniom przepisów takich jak GDPR lub CCPA.
⚠️ Powszechne pułapki i jak im zapobiegać
Tworzenie diagramów przepływu danych dla systemów chmurowych jest trudne. Są powszechne błędy, które zespoły popełniają, często wynikające z próby przekształcenia starych wzorców na nowe środowiska. Unikanie tych pułapek zapewnia, że Twoje diagramy pozostaną dokładne i użyteczne.
1. Połączenie logiki sterowania i przepływu danych
Diagramy przepływu danych nie powinny pokazywać logiki sterowania. Nie rysuj strzałek, które oznaczają „jeśli to, to tam”. Używaj punktów decyzyjnych lub notatek zewnętrznych do logiki, ale utrzymaj strzałki skupione na przepływie danych. W systemach chmurowych, gdzie logika sterowania często jest obsługiwana przez platformy koordynacji, diagram przepływu danych powinien skupiać się na ładunku danych.
2. Ignorowanie przepływów asynchronicznych
Systemy chmurowe rzadko są w 100% synchroniczne. Zadania działają w tle. Jeśli rysujesz tylko synchroniczne przepływy żądanie-odpowiedź, Twój diagram będzie niepełny. Zawsze uwzględniaj zadania w tle i strumienie zdarzeń jako przepływy danych do lub z magazynów danych.
3. Nadmierna optymalizacja pod kątem konkretnych narzędzi
Nie projektuj swojego diagramu na podstawie możliwości konkretnego narzędzia lub platformy. Jeśli wybierzesz konkretną bazę danych lub broker komunikatów, diagram może się wygryźć, gdy zmienisz technologie. Skup się na logicznym przepływie danych, a nie na implementacji fizycznej.
4. Ignorowanie przepływów błędów
Ścieżki powodzenia są łatwe do narysowania. Ścieżki błędów są trudniejsze, ale niezbędne. W środowisku chmurowym usługi często zawodzą. Wskaż, gdzie dane błędów są rejestrowane lub gdzie aktywują się mechanizmy ponownych prób. Pomaga to w projektowaniu wytrzymały system monitorowania i ostrzegania.
🔄 Utrzymywanie diagramów w czasie
Diagram jest użyteczny tylko wtedy, gdy jest dokładny. Aplikacje oparte na chmurze zmieniają się szybko. Dodawane są nowe usługi, stare są wycofywane, a modele danych ewoluują. Jeśli diagram nie odpowiada działającemu systemowi, staje się mylącą dokumentacją. Oto jak je utrzymywać.
- Kontrola wersji:Traktuj diagramy jak kod. Przechowuj je w systemie kontroli wersji razem z kodem aplikacji. Zapewnia to historię i śledzenie zmian.
- Cykle przeglądu:Uwzględnij aktualizacje diagramów w procesie przeglądu kodu. Jeśli deweloper zmienia przepływ danych, diagram powinien zostać zaktualizowany w tym samym commicie lub żądaniu pobrania.
- Automatyczne generowanie: Tam gdzie to możliwe, generuj diagramy z kodu lub definicji infrastruktury jako kodu. Pomaga to zmniejszyć różnicę między dokumentacją a rzeczywistością.
- Wyrównanie z zaangażowanymi stronami: Regularnie przeglądaj diagramy z nietechnicznymi zaangażowanymi stronami. Zapewnia to, że poziom abstrakcji pozostaje odpowiedni dla odbiorców.
📋 Porównanie DFD z innymi widokami architektonicznymi
Często myli się DFD z innymi diagramami, takimi jak diagramy sekwencji lub diagramy architektury systemu. Zrozumienie różnicy pomaga wybrać odpowiedni narzędzie do zadania.
| Typ diagramu | Główny zakres | Najlepiej używane do |
|---|---|---|
| Diagram przepływu danych | Przemieszczanie i przekształcanie danych | Projektowanie systemu, audyt bezpieczeństwa, mapowanie danych |
| Diagram sekwencji | Interakcja oparta na czasie między obiektami | Integracja z API, debugowanie łańcuchów wywołań |
| Architektura systemu | Infrastruktura i wdrażanie | DevOps, skalowanie, wymagania sprzętowe |
| Relacja encji | Struktura danych i relacje | Projektowanie bazy danych, planowanie schematu |
DFD uzupełnia te widoki. Podczas gdy diagram architektury pokazuje, gdzie znajdują się serwery, DFD pokazuje, jak informacje przemieszczają się między nimi. Podczas gdy diagram sekwencji pokazuje kolejność wywołań, DFD pokazuje ładunek. Ich wspólne użycie zapewnia kompletny obraz systemu.
🚀 Przyszłe trendy w modelowaniu chmury
Wraz z rozwojem technologii chmury zmieniają się również wymagania dotyczące modelowania. Wzrost obliczeń bezserwerowych i krawędziowych wprowadza nowe wyzwania. Przepływy danych stają się bardziej rozproszone. Procesy działają bliżej użytkownika. Ten przesunięcie wymaga, by DFD uwzględniały węzły krawędziowe i tymczasowe zasoby obliczeniowe.
Dodatkowo, integracja sztucznej inteligencji do przepływów pracy zwiększa złożoność. Modele AI zużywają dane i generują wgląd. Te procesy często wymagają dużych zbiorów danych i specjalistycznego sprzętu. Przyszłe DFD muszą przedstawiać te intensywne obliczeniowo procesy oraz potoki danych je zasilające. Zasady podstawowe pozostają te same, ale szczegółowość i zakres będą się rozszerzać.
Przestrzegając podstaw DFD, jednocześnie dostosowując się do rzeczywistości chmury, zespoły inżynieryjne mogą budować systemy przejrzyste, bezpieczne i skalowalne. Wizualizacja danych to nie tylko ćwiczenie dokumentacyjne; jest to kluczowy krok w procesie projektowania, który zapobiega błędom przed ich dotarciem do produkcji.