











Modelowanie danych często stanowi niewidzialną podstawę każdej aplikacji oprogramowania. Choć kod realizujący logikę biznesową znajduje się w centrum uwagi, schemat znajdujący się pod nią decyduje o wydajności, skalowalności i utrzymywalności. Dla wielu młodych inżynierów diagram relacji encji (ERD) to prosta ćwiczenie polegające na rysowaniu prostokątów i łączeniu ich liniami. Jednak ta prostota jest myląca. Źle zbudowany ERD tworzy dług, który się kumuluje z czasem, prowadząc do skomplikowanych zapytań, problemów z integralnością danych oraz trudnych migracji.
Ten przewodnik bada ukrytą lukę złożoności. Wskazuje miejsca, w których występuje rozłączenie między wiedzą teoretyczną a jej zastosowaniem praktycznym. Zrozumienie tych pułapek pozwala programistom przekroczyć poziom podstawowego rysowania schematów i osiągnąć prawdziwe myślenie architektoniczne.
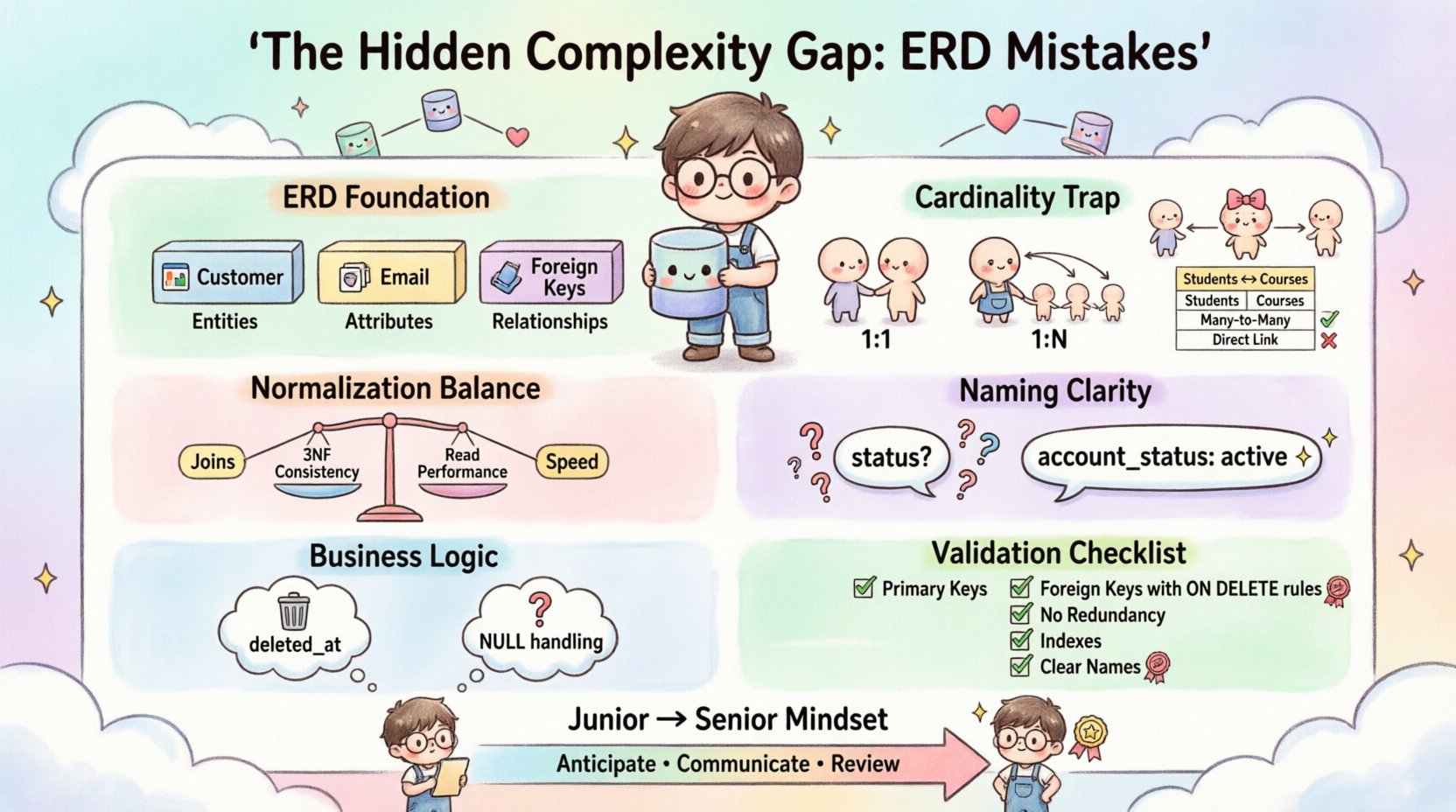
1. Zrozumienie podstaw modelowania danych 🏗️
Zanim przejdziemy do błędów, konieczne jest ustalenie, co dokładnie oznacza diagram ERD. Nie jest to po prostu rysunek; jest to umowa między aplikacją a warstwą przechowywania danych. ERD wizualizuje encje (tabelki), atrybuty (kolumny) oraz relacje (klucze obce).
Kiedy inżynier traktuje to jako statyczny artefakt stworzony raz i zapomniany, nie zauważa dynamicznego charakteru danych. Modele danych ewoluują wraz z zmianami wymagań biznesowych. Młody inżynier może skupić się na natychmiastowej funkcji, takiej jak przechowywanie imienia użytkownika, pomijając sposób, w jaki ten użytkownik oddziałuje z innymi encjami, takimi jak zamówienia, subskrypcje lub dzienniki.
- Encje: Odnoszą się do rzeczywistych obiektów lub pojęć (np. Klient, Produkt, Faktura).
- Atrybuty: Są to właściwości definiujące encję (np. Email, Cena, Data).
- Relacje: Określają sposób oddziaływania encji (np. Jedna do wielu, wiele do wielu).
Solidny model uwzględnia przyszły rozwój. Przewiduje, jak „Klient” może stać się „Użytkownikiem” lub jak „Produkt” może wymagać wariantów. Początkowy schemat powinien być wystarczająco elastyczny, aby dopasować się do tych zmian bez konieczności całkowitego ponownego budowania.
2. Pułapka kardynalności: nieprawidłowe rozumienie relacji 🔄
Kardynalność jest najczęściej występującym źródłem błędów strukturalnych w projektowaniu baz danych. Określa relację liczbową między wystąpieniami encji. Nieprawidłowe rozumienie tego prowadzi do nieefektywnego przechowywania danych i skomplikowanej logiki łączenia.
Typowe scenariusze kardynalności
Inżynierowie często wybierają najbardziej oczywistą relację, nie rozważając przypadków granicznych. Rozważ następujące sytuacje, w których założenia prowadzą do błędów:
- Jeden do jednego (1:1):Często nadużywane. Jeśli dwie encje mają relację 1:1, powinny często zostać połączone w jedną tabelę, aby zmniejszyć koszt łączenia, chyba że wymagana jest ścisła separacja bezpieczeństwa.
- Jeden do wielu (1:N): Najczęstsza relacja. Jedno rekord z rodzica łączy się z wieloma rekordami potomka. Klucz obcy musi znajdować się po stronie potomka.
- Wiele do wielu (M:N): To właśnie tutaj rośnie luka złożoności. Bez pośredniej tabeli relacja M:N nie jest fizycznie możliwa w modelu relacyjnym.
Tabela: Błędy implementacji kardynalności
| Scenariusz | Niepoprawna metoda | Poprawna metoda |
|---|---|---|
| Studenci i kursy | Dodawanie kolumny „CourseID” do tabeli „Student” | Tworzenie tabeli pośredniej „Student_Course” |
| Zamówienia i produkty | Wstawianie szczegółów produktu bezpośrednio do tabeli Zamówienie | Łączenie za pomocą tabeli OrderItems |
| Pracownicy i departamenty | Zezwolenie pracownikowi na przynależność do wielu departamentów bez tabeli pośredniczącej | Oddzielenie relacji mapowania |
Gdy inżynierowie próbują narzucić relację wiele do wielu w jedną tabelę poprzez powtarzanie danych, wprowadzają nadmiarowość. Jeśli cena produktu się zmienia, musi zostać zaktualizowana we wszystkich rekordach zamówienia, w których ten produkt występuje. Nadużywa to zasad normalizacji i tworzy koszmary utrzymaniowe.
3. Mitologia normalizacji i sprawdzanie rzeczywistości 📉
Normalizacja to standardowy pojęcie nauczane w środowiskach akademickich. Celem jest zmniejszenie nadmiarowości danych i poprawa integralności. Jednak młodzi inżynierowie często normalizują do ekstremalnej miary (do 5NF), nie rozważając kompromisów pod względem wydajności.
Pułapka nadmiernego normalizowania
Zbyt normalizowana schemat dzieli dane na zbyt wiele tabel. Choć zapewnia spójność, zmusza aplikację do wykonywania nadmiernych połączeń. Każde połączenie dodaje koszt obliczeniowy. W systemach o wysokim ruchu może to stać się węzłem szybkości.
- 1NF (Pierwsza forma normalna):Wartości atomowe. Brak list w jednym polu.
- 2NF (Druga forma normalna):Brak częściowych zależności. Wszystkie atrybuty niekluczowe muszą zależeć od całego klucza głównego.
- 3NF (Trzecia forma normalna):Brak zależności przechodnich. Atrybuty nie powinny zależeć od innych atrybutów niekluczowych.
Powszechnym błędem jest zakładanie, że 3NF to zawsze cel. W niektórych przypadkach denormalizacja to celowe podejście projektowe. Na przykład przechowywanie „Całkowitej kwoty zamówienia” bezpośrednio w tabeli Zamówienie unika obliczania sumy elementów za każdym razem, gdy zamówienie jest wyświetlone. To wymienia wydajność zapisu na wydajność odczytu.
Tabela: Normalizacja wobec denormalizacji
| Czynnik | Normalizowane (3NF) | Denormalizowane |
|---|---|---|
| Nadmiarowość danych | Niska | Wysoka |
| Prędkość zapisu | Szybko | Wolniej |
| Prędkość odczytu | Wolniej (więcej połączeń) | Szybki |
| Integralność danych | Wysoki | Niższy (wymaga logiki) |
Decyzja o zdenormalizowaniu musi być oparta na danych. Nie powinna być podejmowana dowolnie. Inżynierowie muszą profilować wydajność zapytań przed łączeniem tabel. Ślepe przestrzeganie reguł normalizacji bez kontekstu prowadzi do systemów spójnych, ale wolnych.
4. Zasady nazewnictwa i jasność semantyczna 🏷️
Nazwy schematów to słownictwo bazy danych. Jeśli słownictwo jest niejasne, system staje się niezrozumiały dla przyszłych programistów. Jest to częsty problem, w którym precyzja techniczna jest ofiarowana krótkości.
Pole o nazwie status jest niebezpieczne. Co to oznacza? Czy to aktywne konto? Oczekująca płatność? Usunięty rekord? Bez kontekstu znaczenie ginie. Podobnie, używanie nazw liczby mnogiej dla tabel (np. Użytkownicy) w porównaniu do liczby pojedynczej (np. Użytkownik) prowadzi do niezgodności.
- Spójność:Jeśli jedna tabela używa
snake_case, wszystkie muszą używaćsnake_case. - Opisowość:Używaj nazw opisujących dane, a nie tylko format. Unikaj ogólnych słów takich jak
tabela1lubdane. - Kontekst:Włącz nazwę encji w kluczu relacji, jeśli występuje niejasność. Użyj
user_idzamiast tylkoidgdy to możliwe.
Rozważ sytuację systemu z wieloma typami użytkowników: Administratorzy, Klienci i Dostawcy. Jedna tabela o nazwie Użytkownicy może zawierać kolumnę rola kolumnę. Jest to tzw. „Bóg tabeli”. Lepszym rozwiązaniem jest oddzielne tabele lub jasna strategia dziedziczenia. Ta różnica staje się kluczowa, gdy uprawnienia i zasady dostępu do danych znacznie się różnią między rolami.
5. Ignorowanie logiki biznesowej w projektowaniu technicznym 🧠
Największa różnica między inżynierami początkującymi a doświadczonymi polega na zrozumieniu logiki biznesowej. Inżynier początkujący może stworzyć schemat, który idealnie odpowiada obecnym wymaganiom kodu, ale zawiedzie, gdy zmienią się zasady biznesowe.
Pomyłka dotycząca „miękkiego usuwania”
Wielu programistów po prostu dodaje kolumnę deleted_at do tabeli. To działa w prostych przypadkach. Jednak jeśli użytkownik zostanie usunięty, czy powinny zostać usunięte jego powiązane dzienniki? Czy jego rekordy finansowe powinny zostać zachowane w celu zgodności z audytami? Schemat ERD powinien odzwierciedlać te ograniczenia za pomocą ograniczeń i wyzwalaczy, a nie tylko kodu aplikacji.
Problem z wartością NULL
Zezwolenie na wartości NULL często jest źródłem ukrytej złożoności. W niektórych przypadkach NULL ma inne znaczenie niż pusty ciąg znaków lub zero. Jeśli pole jest opcjonalne, schemat ERD powinien jasno to wyrazić. Jednak zależność od wartości NULL do kontroli logiki jest niepożądana.
- Integralność referencyjna: Klucze obce powinny idealnie nie być NULL, chyba że relacja jest naprawdę opcjonalna.
- Obliczenia: Wartości NULL rozprzestrzeniają się w obliczeniach, co prowadzi do wyników NULL. Może to spowodować awarię zapytań agregujących.
- Indeksy: Obsługa NULL w indeksach różni się w zależności od silnika bazy danych, co może wpływać na wydajność zapytań.
6. Obciążenie utrzymania złego projektu 🔧
Dług techniczny nie dotyczy tylko wolnego kodu; dotyczy sztywności strukturalnej. Zły projekt ERD sprawia, że zmiany są bolesne. Gdy pojawia się nowe wymaganie, takie jak dodanie „adresu rozliczeniowego” oddzielonego od „adresu wysyłki”, inżynier musi ocenić, czy obecny schemat to wspiera.
Noce migracji
Zmiana schematu bazy danych produkcyjnej z milionami rekordów wymaga starannego planowania. Jeśli schemat ERD nie został zaprojektowany z myślą o migracjach, zmiana typu kolumny lub podział tabeli może zablokować system na godziny. Ten czas przestoju wpływa na przychód i zaufanie użytkowników.
Strategie zmniejszające to ryzyko obejmują:
- Kontrola wersji schematu: Traktuj strukturę bazy danych jak kod aplikacji.
- Zgodność wsteczna: Dodawaj kolumny przed ich usunięciem. Zachowuj stare kolumny, aż migracja zostanie zakończona.
- Dokumentacja: ERD powinien być źródłem prawdy. Jeśli nie zgadza się z bazą danych, to baza danych jest błędna.
7. Praktyczna lista kontrolna weryfikacji ERD ✅
Aby zapewnić solidny projekt, inżynierowie powinni przejść przez listę weryfikacji przed ostatecznym zakończeniem diagramu. Ten proces pomaga wykryć błędy logiczne przed rozpoczęciem implementacji.
Weryfikacja przed wdrożeniem
| Sprawdzenie | Pytanie | Kryteria zaliczenia |
|---|---|---|
| Klucze główne | Czy każda tabela ma unikalny identyfikator? | Tak, z autoinkrementacją lub UUID |
| Klucze obce | Czy relacje są jawnie zdefiniowane? | Tak, z regułami ON DELETE/UPDATE |
| Zbyt duża redundancja | Czy jakakolwiek dane są przechowywane w więcej niż jednym miejscu? | Nie, chyba że znormalizowanie jest celowe |
| Skalowalność | Czy może obsłużyć 10-krotnie większy obciążenie danych niż obecnie? | Indeksy istnieją na kluczach obcych |
| Czytelność | Czy nowy pracownik może zrozumieć przepływ w ciągu 5 minut? | Jasne zasady nazewnictwa |
8. Narzędzia wobec koncepcji 🛠️
Łatwo polegać na funkcjach konkretnego narzędzia do rozwiązywania problemów projektowych. Jednak narzędzie jest wtórne wobec koncepcji. Niezależnie od tego, czy używamy narzędzia do modelowania wizualnego, czy piszemy skrypty SQL bezpośrednio, logika podstawowa pozostaje ta sama.
Niektórzy inżynierowie tworzą diagramy, które wyglądają idealnie wizualnie, ale są syntaktycznie niemożliwe do zrealizowania w docelowej bazie danych. Na przykład, niektóre narzędzia pozwalają na cykliczne zależności na poziomie wizualnym, podczas gdy silnik bazy danych je odrzuci. Należy skupić się na zasadach integralności relacyjnej, a nie na interfejsie rysowania.
- Spójność wizualna: Używaj standardowych symboli dla relacji (notacja kłykciowa).
- Weryfikacja: Uruchom schemat na bazie testowej, aby zweryfikować ograniczenia.
- Współpraca:Przejrzyj diagram z zaangażowanymi stronami, które rozumieją dziedzinę biznesową, a nie tylko kolegami technicznymi.
9. Przykłady z rzeczywistego świata niepowodzeń ⚠️
Zrozumienie abstrakcyjnych koncepcji to jedno; widzenie ich niepowodzenia w praktyce to zupełnie inna sprawa. Poniżej znajdują się typowe sytuacje, w których złe projektowanie ERD prowadzi do konkretnych problemów.
Scenariusz A: Nieskończona pętla
Programista tworzy relację międzyUżytkownicy i Zespołygdzie użytkownik należy do zespołu, a zespół jest prowadzony przez użytkownika. Jeśli klucz obcy wskazuje na tę samą tabelę bez jasnego korzenia, podczas wstawiania występują błędy cyklicznych odwołań. ERD musi jasno rozróżniać relacje „Członek” i „Kierownik”.
Scenariusz B: Cichy utrata danych
Tabela Zamówienieodwołuje się do tabeli ProduktTabela. Ograniczenie ON DELETEjest ustawione na CASCADE. Gdy produkt jest usuwany z katalogu, wszystkie powiązane zamówienia są usuwane. To niszczy dane historyczne sprzedaży. ERD powinien jasno określić działanie referencyjne jako RESTRICTlubSET NULLw zależności od potrzeb biznesowych.
Scenariusz C: Powolne wyszukiwanie
Tabela jest tworzona z kolumną namekolumną. Inżynierowie często wykonywają zapytania do tej tabeli w celu znalezienia użytkowników po imieniu. Bez zdefiniowania indeksu w fazie projektowania baza danych wykonuje pełne skanowanie tabeli. ERD powinien wskazywać, które kolumny są intensywnie wyszukiwane i wymagają indeksowania.
10. Rozwój od myślenia początkującego do myślenia zaawansowanego 🚀
Przejście polega na zmianie skupienia z „Czy to działa?” na „Czy się skaluje?” i „Czy jest utrzymywalne?”.
- Przewidywanie: Przewidywanie przyszłych wymagań na podstawie trendów branżowych.
- Komunikacja: Przekładanie ograniczeń technicznych na ryzyka biznesowe.
- Przegląd: Nigdy nie zakładaj, że schemat jest poprawny bez przeglądu przez kolegów.
Młodzi inżynierowie często pracują sami. Starsi inżynierowie współpracują. ERD to narzędzie komunikacji. Łączy luki między programistami, menedżerami produktów i stakeholderami. Jeśli schemat jest mylący, oczekiwania będą niezgodne.
Ostateczne rozważania na temat integralności danych 🎯
Tworzenie schematu bazy danych to nie jednorazowa praca; to ciągła dyscyplina. Przepaść złożoności istnieje, ponieważ ryzyko jest duże. Błąd w kodzie aplikacji można szybko naprawić. Błąd w modelu danych często wymaga migracji, oczyszczania danych i przestoju.
Przestrzegając surowych zasad modelowania, głęboko rozumiejąc liczność oraz priorytetując logikę biznesową przed wygodą, inżynierowie mogą zniwelować tę przepaść. Celem nie jest stworzenie idealnego schematu, ale stworzenie fundamentu wspierającego ewolucję oprogramowania. Dane to najcenniejszy zasób aplikacji. Ochrona ich struktury to odpowiedzialność każdego inżyniera uczestniczącego w procesie budowy.
Poświęć czas na przeglądanie swoich schematów. Zastanów się nad każdą relacją. Zweryfikuj każde ograniczenie. Czas poświęcony na etapie projektowania zaoszczędzi miesiące pracy w fazie utrzymania.