











データモデリングは、ビジネスロジックと技術的実装の間の橋渡しとしばしば説明される。しかし、この橋はしばしば揺らぐ地盤の上に築かれる。ビジネス関係者があいまいな概念、たとえば「顧客の行動を追跡する」や「在庫レベルを管理する」を具体的な制約を定義せずに提示するとき、エンティティ関係図(ERD)は高リスクな賭けとなる。上級のデータベース管理者(DBA)は単に推測しない。彼らは不確実性を構造化されたデータ定義に変換するための体系的なアプローチを採用する。
本ガイドは、曖昧な要件に直面した経験豊富なデータベース専門家が用いる具体的な戦略、質問技術、およびアーキテクチャパターンについて探求する。設計プロセスを安定化させ、データ整合性を確保し、ビジネスニーズが変化しても堅牢なままであるスキーマを構築する方法を検討する。
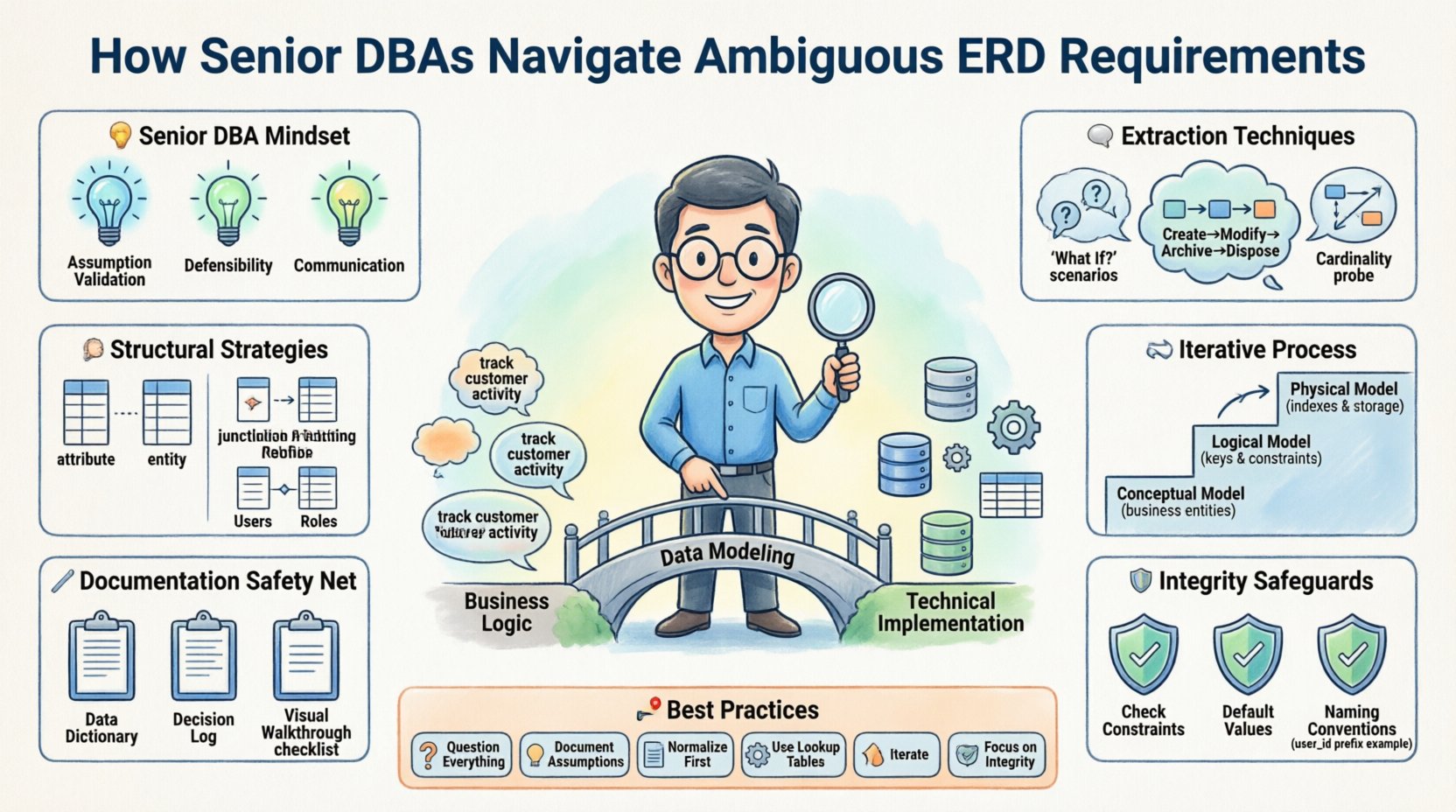
🧠 上級DBAのマインドセット
初心者のモデラーは、ERDを最初の試行で完璧でなければならない静的な図と見なすことが多い。上級の実務者は、データモデリングが反復的な発見プロセスであることを理解している。曖昧さは誤りではなく、ビジネスロジックがまだ完全に明確にされていない兆候である。即座に曖昧さを排除することではなく、それを特定し、文書化し、安全に設計を進めることが目的である。
このアプローチの主な特徴は以下の通りである:
-
仮定の検証:すべての仮定を、現実世界のシナリオに対して検証が必要な仮説として扱う。
-
説明可能性:すべての外部キーとインデックスが、技術的好みではなくビジネスルールによって正当化できることを確実にする。
-
将来対応性:現在のスプリントだけでなく、今後3年のビジネス成長を見据えて設計する。
-
コミュニケーション:技術的制約を、ステークホルダーが理解できるビジネス言語に翻訳する。
🗣️ 隠れたルールを引き出すための技法
要件に「注文を追跡する必要がある」とあるとき、曖昧さは「注文」の定義にある。それは購入なのか?見積もりなのか?カート放棄なのか?上級のDBAは、範囲を絞るために特定の質問パターンを用いる。
1. 「もし~なら」シナリオ
高レベルな記述を受け入れるのではなく、DBAは境界ケースを追求する。たとえば「注文が部分的に出荷された場合どうなるか?」や「支払い後に注文をキャンセルできるか?」といった質問は、当初は見えなかった制約をステークホルダーに明らかにする。こうした境界ケースは、ステータステーブルやトランザクションログ、または特定の制約ルールの必要性を左右することが多い。
2. データライフサイクルの調査
すべてのデータにはライフサイクルがある。上級のDBAは、状態遷移について尋ねる:
-
作成:誰がレコードを作成するのか?自動化されているのか、手動なのか?
-
変更:履歴は追跡されるのか、それともレコードが上書きされるのか?履歴を追跡する場合、スナップショットかデルタか?
-
アーカイブ:データが「古くなった」と判断されるのはいつか?ソフト削除(フラグ付き)か、ハード削除(削除)か?
-
廃棄:データ保持を規定する法的保持期間はあるか?
3. カーディナリティの調査
カーディナリティはエンティティ間の関係を定義する。ここでの曖昧さはパフォーマンスの問題やデータの重複を引き起こす。DBAは次のように尋ねる:
-
1つのアイテムが同時に複数のカテゴリに属することは可能ですか?
-
関係は必須(存在しなければならない)か、オプション(nullでもよい)ですか?
-
関係が破綻した場合、親レコードにどのような影響がありますか?
📐 不確実性への構造的戦略
相談の後も要件が曖昧なまま残る場合、データベース設計は整合性を損なうことなく不確実性を吸収しなければなりません。これには柔軟性を許す特定のモデリングパターンが必要です。
1. 属性とエンティティの選択
最も一般的な曖昧さの一つは、データの一部が列(属性)として扱われるべきか、別々のテーブル(エンティティ)として扱われるべきかということです。たとえば、「電話番号」は1つの列として扱うべきか、それとも「連絡先」エンティティに関連する別テーブルとして扱うべきでしょうか?
要件が不明な場合、ベテランのアプローチは正規化を優先します。電話番号用に別テーブルを作成することで、連絡先ごとに複数の番号を保持でき、nullableな列を追加せずに済みます。また、ホーム、モバイル、仕事などカテゴリ分けも可能になり、主テーブルが肥大化することもありません。このアプローチは、多くのオプション列を持つ広いテーブルよりも、成長に対応しやすいです。
2. オプション関係の扱い方
特定の関係が必須かどうか不明な場合、DBAはnullableな外部キーを使用してオプション関係としてモデル化します。ただし、警告があります。適切に管理されない場合、nullableな外部キーは孤立データを生じさせる可能性があります。解決策として、データベースがnullを許容しても論理的に参照整合性を維持できるように、トリガーまたはアプリケーションレベルの検証を導入することが一般的です。
3. 結合テーブル戦略
多対多関係は頻繁に混乱の原因になります。要件が「ユーザーは複数のロールを持つことができる」かつ「ロールは複数のユーザーに割り当てられる」という場合、単純な列ではこのデータを保持できません。結合テーブル(関連エンティティ)が標準的な解決策です。これによりDBAは関係自体に属性を付与でき、たとえば「ロールはいつ割り当てられたか?」や「誰が割当を承認したか?」といった情報を保持できます。これは要件が進化した際にしばしば求められる監査可能性を追加します。
🔄 反復プロセス
ベテランのDBAは初稿で最終スキーマを提示することはめったにありません。リスクを軽減するために段階的なアプローチを採用します。
段階1:概念モデル
これはビジネスエンティティとその関係に焦点を当てた高レベルの図です。データ型や技術的制約は無視されます。目的は「何を」実現するかについてステークホルダーの承認を得ることであり、「どのように」実現するかではありません。これにより技術的詳細がビジネス論理の合意を曇らせることを防ぎます。
段階2:論理モデル
ここではデータ型が定義され、正規化ルール(通常は第三正規形まで)が適用されます。曖昧さは、データ辞書に記録された保守的な仮定に基づいて解消されます。ここがDBAが主キー、外部キー、一意制約を定義する場所です。
段階3:物理モデル
論理モデルが具体的な実装詳細に翻訳されます。これにはインデックス戦略、パーティショニング、ストレージエンジンが含まれます。この段階で、以前にした曖昧な決定のパフォーマンスへの影響をDBAは検討します。たとえば「高速レポート」について要件が曖昧だった場合、物理モデルには正規化の解除や物化ビューを含め、そのニーズに対応する一方で、後で再検討するようメモを残すことがあります。
📝 ドキュメント化とコミュニケーション
ドキュメント化は曖昧な要件に対する安全網です。仮定に基づいて決定がなされた場合、それを記録しなければなりません。これによりDBAと組織がスコープクリープやデータ損失から保護されます。
-
データ辞書: 列ごとの定義、目的、制約を記載する動的な文書。フィールドがnullableである場合は、その理由を明記するべきです。
-
意思決定ログ: プロジェクトドキュメント内のセクションで、特定のモデリング選択の理由を記録します。たとえば:「[日付]のステークホルダーインタビューに基づき、注文に対して1対多関係を仮定した。」
-
視覚的ウォークスルー: コード生成の前に、図をビジネスチームとレビューします。これによりモデルがビジネスのメンタルマップを反映していることを確認できます。
⚠️ 避けるべき一般的な落とし穴
経験豊富なプロフェッショナルでも、要件が不明な場合、罠にはまってしまうことがあります。これらの落とし穴への意識は、設計の整合性を保つのに役立ちます。
-
過剰設計:すべての将来のシナリオに対処しようとすると、維持が難しいほど複雑なスキーマになってしまう。現在の明確な要件に基づいて構築し、将来の柔軟性を確保するほうが良い。
-
データ型を無視する:すべてのテキストを「VARCHAR」として扱うことは一般的な誤りである。日付、通貨、IDには特定の制約があり、データベースレベルで強制すべきである。
-
ロジックをハードコードする:ビジネスルールをERDに直接ハードコードする(例:「Status = 1 は Active を意味する」)のはリスクが高い。データの意味が明確になるように、読みやすい列挙型や参照テーブルを使用するほうが良い。
-
監査トレールをスキップする:要件が曖昧な場合、データの出所が重要になる。「created_by」、「created_at」、「updated_at」のようなカラムを追加することで、変更の追跡のための基本を確保できる。
📊 不明確さの種類と解決戦略
迅速な参照を支援するため、以下の表はERD設計で見られる一般的な不明確さの種類と推奨される技術的解決策を概説している。
|
不明確さの種類 |
例のシナリオ |
解決戦略 |
|---|---|---|
|
基数の不確実性 |
「1つの製品は複数の注文に含まれる。」(これは1製品あたり複数の注文を意味するのか?それとも1つだけなのか?) |
将来の拡張を可能にするために、中間テーブルを用いた多対多としてモデル化する。 |
|
データの変動性 |
「顧客の住所を保存する必要がある。」(住所は変更されるのか?履歴は保持するのか?) |
メインの住所を上書きするのではなく、有効日を含む別々の「住所履歴」テーブルを使用する。 |
|
属性の粒度 |
「ユーザーの位置を保存する。」(都市?GPS座標?IPアドレス?) |
将来の精度を確保するために、特定のフィールド(緯度、経度、都市)を持つ専用の「位置」エンティティを作成する。 |
|
状態管理 |
「注文の状態を追跡する。」(有効な状態は何か?) |
無効な状態遷移を防ぐために、制約付きのステータス参照テーブルを実装する。 |
|
一意性制約 |
「メールアドレスが一意であることを保証する。」(大文字小文字を区別するか?誤字についてはどうするか?) |
フィールドの小文字版に一意性制約を適用するか、別途検証レイヤーを使用する。 |
🛡️ 不明確な環境でのデータ整合性の確保
要件が不明瞭な場合、データ破損のリスクが高まる。シニアDBAは、悪意のあるデータがシステムに流入するのを防ぐための保護策を実装する。
1. 制約の確認
ビジネスルールが曖昧であっても、データベースは厳格な境界を強制すべきである。たとえば、「価格」フィールドが必須の場合、ビジネスロジックによって明示的に許可されない限り、データベースは負の数やnull値の入力を防止すべきである。
2. デフォルト値
要件が欠落している場合、nullを許容するよりも安全なデフォルト値を使用するほうが良い。たとえば、「ステータス」フィールドが曖昧な場合、デフォルトを「保留中」または「下書き」に設定することで、レコードが孤立したり無視されたりすることを防げる。
3. 名前付け規則
一貫した名前付けは曖昧さを軽減するのに役立つ。外部キーには接頭辞を使用する(たとえば、user_id ではなく、単にid)とすることで、テーブル構造が後で変更された場合でも関係が明確になる。これにより、スキーマを読む開発者の認知負荷が軽減される。
🚀 不明な状況へのスケーラビリティ
最後に、シニアDBAはスキーマが負荷に耐えうるかを検討する。曖昧な要件は、後に poorly optimizedなクエリを引き起こすことが多い。成長を見越して設計することで、モデルは使い続けられる状態を保てる。
-
インデックス戦略:検索やフィルタリングに使用される可能性が高いフィールドを特定する。要件が曖昧であっても、潜在的な検索カラムにインデックスを追加することで、後でのパフォーマンス低下を防げる。
-
パーティショニングの検討事項: 大きなテーブルの場合、データがどのようにパーティショニングされるかを検討する。時間範囲について要件が曖昧な場合、日付範囲でパーティショニングすることで、後でのメンテナンスやアーカイブが容易になる。
-
読み込みと書き込みのバランス: システムが読み込み中心か、書き込み中心かを理解する。これにより、重度の正規化を行うか、パフォーマンス向上のための制御された非正規化を導入するかが決まる。
🤝 コラボラティブデザイン
最も効果的なERD設計は、協働によって作成される。シニアDBAは、孤立して作業するわけではない。技術チームとビジネス関係者との間の翻訳者として機能する。
この協働により、以下が保証される:
-
ビジネス関係者は、複雑さのコストを理解する。
-
開発者はデータの制約を理解する。
-
DBAは運用要件を理解する。
定期的なレビュー会議は不可欠である。これらの会議では、図面を一行ずつ丁寧に確認する。質問が投げかけられ、仮定が検証される。この反復的なフィードバックループが、曖昧な要件に対する主な防御手段となる。
🎯 最良の実践の要約
ERD設計における曖昧な要件への対処方法を要約すると:
-
すべてに疑問を投げかける:詳細を追求せずに高レベルな記述を受け入れてはならない。
-
仮定を文書化する:推測に基づいて選択がなされた場合は、それを記録する。
-
まず正規化する:クリーンで正規化された構造から始め、必要最小限のときにのみ非正規化する。
-
参照テーブルを使用する:スキーマ内に値をハードコードしない。
-
反復する:最初の設計を最終製品ではなく、ドラフトとして扱う。
-
整合性に注力する:データの品質は実装のスピードよりも重要である。
これらの原則に従うことで、データベース専門家は曖昧な要件の迷宮を乗り越え、堅牢でスケーラブルかつ保守可能なデータアーキテクチャを提供できる。目標は未来を予測することではなく、未来が到来したときに適応できるだけの柔軟性を持つシステムを構築することである。
良好に設計されたスキーマはコミュニケーションツールであることを忘れないでください。開発者、アナリスト、ビジネス担当者にメッセージを伝えるのです。要件が不明瞭なとき、スキーマはチームを前進させるために十分に明確でなければならない。