











ソフトウェアアーキテクチャの進化において、歴史的なデータモデリングと現代のスケーラビリティ要件の間にある緊張関係ほど、長期間にわたって根強い課題は少ない。多くの組織は、何年も前に設計されたエンティティ関係図(ERD)に基づいて構築されたバックエンドシステムを運用している。その設計は、負荷、並行処理、ハードウェアに関する異なる前提に基づいていることが多い。レガシースキーマが高スループットの要求に直面すると、パフォーマンスの低下は単なる迷惑ではなく、構造的な失敗である。このガイドは、それらの図を最適化する技術的現実を検討し、その中に埋め込まれたビジネスロジックを捨てずに済む方法を提示する。
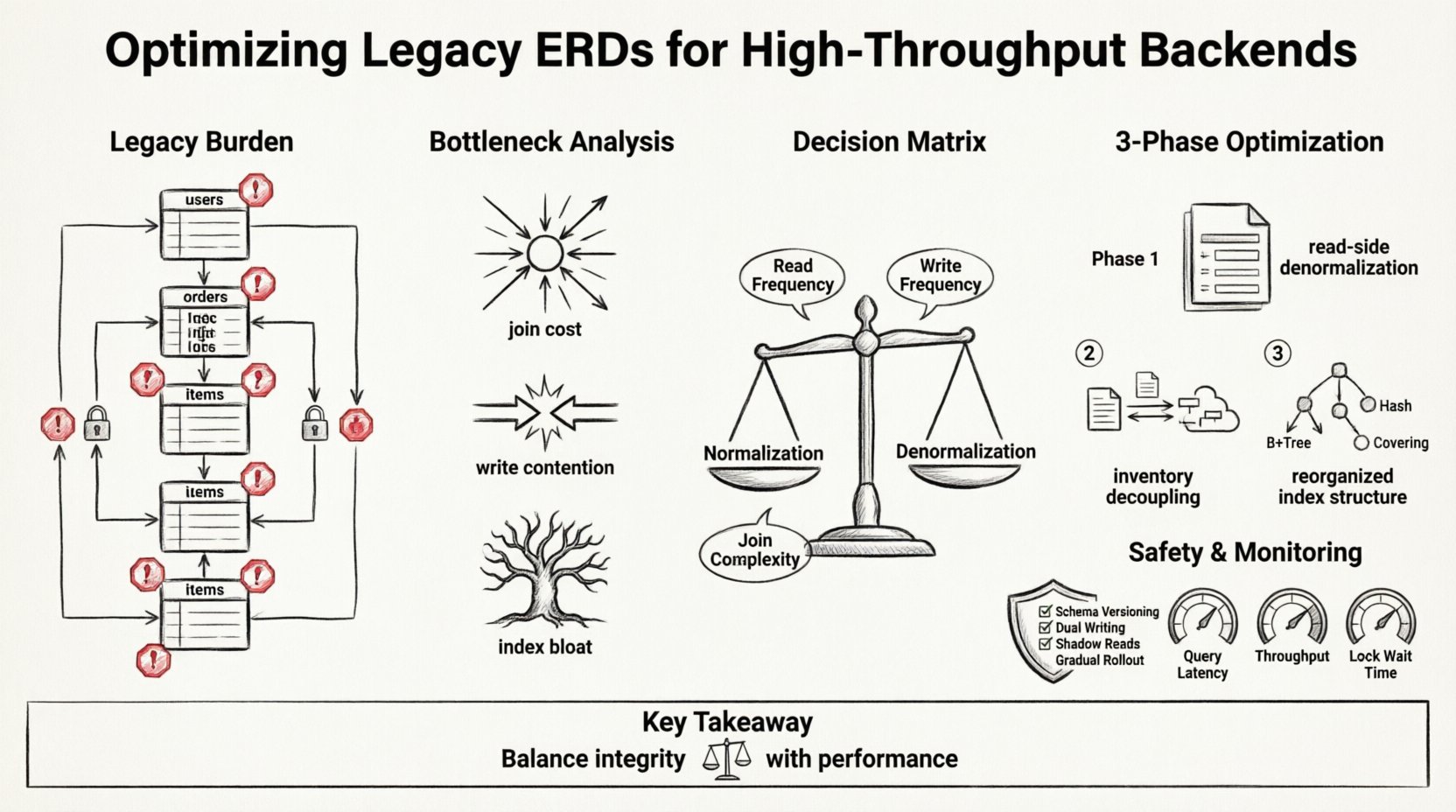
レガシー負荷の理解 💾
レガシーERDはしばしば過去のニーズを反映している。データの整合性と正規化を最優先にしている。中程度のトラフィックを持つ単一ノード環境では、このアプローチはうまく機能する。第三正規形(3NF)への厳格な準拠は、重複を最小限に抑え、一貫性を保証する。しかし、システムが1秒間に数百万件のトランザクションにスケーリングすると、これらの関係性のコストは無視できなくなる。
以下は、古いスキーマに見られる一般的な特徴である。
- 深い結合チェーン:1つのレコードを取得するために5つ以上の結合を必要とするクエリ。
- 重い外部キー制約:並行書き込みをブロックする厳格な整合性チェック。
- 集中型ロック:ピーク負荷時にボトルネックとなる特定のテーブル上のホットスポット。
- 正規化の欠陥:読み込みが重い操作に向けた冗長なデータストアの欠如。
これらのパターンが本質的に「間違っている」わけではない。それらは当時の状況では正しいものだった。課題は、レイテンシが主な通貨となる分散型・高並行環境にそれらを適応させることにある。
ボトルネックの分析 🔍
図を変更する前に、システムがどこでパフォーマンスを失っているかを理解する必要がある。高スループットバックエンドは、通常、I/O操作、サービス間のネットワークレイテンシ、ロック競合によって制限される。ERDはデータのアクセス方法を規定し、それがこれらの指標に直接影響を与える。
1. 結合コスト
すべての結合はディスク読み取りとCPUサイクルを要する。レガシーシステムでは、1つのユーザープロフィール要求が5つのテーブルにわたる連鎖的な検索を引き起こすことがある。トラフィックが増加するにつれて、データベースは関係性のナビゲーションに費やす時間が、ロジックの実行に費やす時間よりも多くなる。インデックスが結合パス全体をカバーできない場合、特にその傾向が強い。
2. 書き込み競合
正規化は整合性を維持するために、データを複数の場所に書き込む必要がある。トランザクションがユーザープロフィールを更新し、アクティビティイベントを記録する場合、2つのテーブルを変更しなければならない。これらのテーブルが同じシャード上にあると、ロック時間は延長される。分散されている場合、トランザクションは2段階コミットとなり、大きなオーバーヘッドが発生する。
3. インデックスの肥大化
複雑な結合をサポートするために、レガシーシステムはインデックスを蓄積する。時間とともに、これらのインデックスは書き込み操作を遅くする。データベースは、すべての挿入や更新ごとにすべてのインデックスを更新しなければならない。高スループットの状況では、この書き込み増幅がストレージサブシステムを飽和させる可能性がある。
リファクタリング戦略:正規化 vs. 非正規化 ⚖️
最適化の核心は、データ整合性とクエリ速度のトレードオフを再考することにある。厳格な正規化は一貫性を保証するが、高性能システムでは実用的な非正規化がしばしば必要となる。これは構造を放棄するという意味ではない。レイテンシを低減するために冗長性を受け入れることを意味する。
以下の表は、スキーマ変更の意思決定マトリクスを示している:
| 基準 | 正規化を維持する | 非正規化を適用する |
|---|---|---|
| 読み込み頻度 | 低(バッチ処理) | 高 (リアルタイムダッシュボード) |
| 書き込み頻度 | 高 (コアトランザクション) | 低 (監査ログ) |
| 整合性要件 | 強力なACID | 最終的整合性が許容可能 |
| 結合の複雑さ | 簡単 (1〜2つの結合) | 複雑 (3つ以上の結合) |
| データの変動性 | 静的 (参照データ) | 動的 (ユーザー状態) |
この戦略を実装するには慎重な計画が必要です。単にテーブルを変更するのではなく、アプリケーションがデータをどのように認識するかを変えるのです。
事例研究のステップバイステップ説明:ECトランザクションエンジン 🛒
このプロセスを説明するために、架空のECプラットフォームを考えてみましょう。レガシーシステムは注文処理、在庫管理、顧客プロフィールを担当しています。ERDは在庫の過剰販売を防ぐことに焦点を当て、単一のデータベースインスタンスを想定して設計されています。
レガシー状態
元の設計では、ordersテーブルはorder_itemsを参照しており、それはproductsを参照しています。productsテーブルはinventory注文詳細ページを表示するには、バックエンドがすべての4つのテーブルを結合するクエリを実行していました。さらに、すべての注文更新には正確性を確保するために在庫テーブルへのロックが必要でした。
特定された主な問題:
- 遅延: セールイベント中、ページ読み込み時間が800msまで急上昇した。
- デッドロック:在庫更新の高同時アクセスがトランザクションのロールバックを引き起こした。
- スケーラビリティ: データベースは、
在庫テーブルをシャーディングできなかった。これは頻繁なクロスシャード結合が原因だった。
最適化プロセス
チームはERDを3段階に分けて再設計することを決定した。目的は読み取りパスと書き込みパスを分離することだった。
フェーズ1:読み取り側の非正規化
最初のステップでは、注文記録内に製品データのスナップショットを作成した。クエリ時にproductsテーブルに結合するのではなく、システムは購入時刻に製品名、価格、SKUをorder_itemsテーブルにコピーした。
- 利点:製品データが後で変更されても、注文履歴の正確性が保たれる。
- 利点:クエリはもはや製品テーブルへの結合を必要としなくなった。
- リスク:注文後に製品が更新された場合、価格の不一致が生じる可能性がある。
- 対策:UIは購入時の価格を「履歴価格」として表示する。
フェーズ2:在庫の分離
在庫テーブルが競合の原因となっていた。チームは在庫追跡を別々の高頻度書き込みストアに移行した。注文システムは同期的なSQLロックを実行するのではなく、在庫を予約する非同期メッセージを送信する。
- 利点:書き込みスループットが400%向上した。
- 利点:メイン注文トランザクションでのブロッキングがなくなった。
- トレードオフ: 在在庫が一時的に同期されない場合でも注文を出すことができます。
- 緩和策: バックグラウンドプロセスが注文システムと在庫の不一致を調整します。
フェーズ3:インデックスの再構築
正規化されていないデータでは、外部キーに対する古いインデックスが不要になりました。チームはそれらを削除し、新しいクエリパターンに最適化された複合インデックスを追加しました。たとえば、(customer_id, created_at) すべての注文テーブルをスキャンする必要をなくしました。
実装フェーズと安全性 🛡️
ライブスキーマを変更することは高リスクの操作です。以下のフェーズにより、移行中の安定性が確保されます。
1. スキーマバージョン管理
古いカラムをすぐに削除しないでください。保持したまま非推奨としてマークしてください。これにより、新しいロジックが失敗した場合にアプリケーションがロールバックできるようになります。カラムを削除する前に追加するマイグレーションスクリプトを使用してください。
2. ダブル書き込み
移行中は、古い構造と新しい構造の両方にデータを書き込みます。アプリケーションロジックは読み取りを新しい構造にルーティングしますが、書き込みは両方に送られます。これにより、新しいスキーマが不完全な場合のフォールバックが可能になります。
3. シャドウ読み取り
ライブトラフィックをリダイレクトする前に、本番データのコピー上で新しいクエリを実行します。レガシークエリの結果と最適化されたクエリの結果を比較し、データの正確性を確認します。
4. 漸進的展開
機能フラグを使用して、新しいスキーマを少数のユーザー(例:1%)に有効化します。エラーレートと遅延をモニタリングします。メトリクスが安定している場合は、段階的に割合を増やします。
モニタリングと検証 📊
最適化は一度きりの出来事ではありません。変更が負荷下でも維持されることを確認するために継続的なモニタリングが必要です。リファクタリングを開始する前に、重要なパフォーマンス指標(KPI)を設定する必要があります。
追跡すべき主要指標:
- クエリ遅延: 95パーセンタイルおよび99パーセンタイルの応答時間。
- スループット: エラーなしの1秒あたりのトランザクション数(TPS)。
- ロック待機時間: トランザクションがロックを待つ平均時間。
- レプリケーション遅延: プライマリノードとレプリカノード間の遅延(該当する場合)。
- キャッシュヒット率: 読み取りキャッシュ戦略の効果。
アラートしきい値は、変更前のベースラインメトリクスに基づいて設定する必要があります。遅延が急上昇した場合、システムは自動的にレガシースキーマに戻すか、トラフィックをフォールバックサービスにルーティングするべきです。
避けるべき一般的な落とし穴 ⚠️
しっかりとした計画があっても、技術的負債は予期せぬ形で再び顔を出すことが多いです。これらの一般的な誤りに注意してください。
- データ移行コストを無視する:テラバイト単位のデータを新しい構造に移行するには時間がかかります。メンテナンスウィンドウを計画するか、バックグラウンドでの移行ツールを用意してください。
- 読み取りの過剰最適化:正規化をしすぎると、書き込みパフォーマンスが低下します。特定のワークロードの読み取り/書き込み比率を適切に調整してください。
- アプリケーションロジックを忘れる:スキーマの変更は戦いの半分にすぎません。アプリケーションコードは新しいデータ構造に対応できるように更新される必要があります。
- テストを軽視する:ユニットテストはしばしばハッピーパスをカバーするだけです。新しいスキーマにおける競合状態を見つけるにはストレステストが必要です。
長期的なメンテナンス戦略 🔧
最適化が完了したら、チームは新しいアーキテクチャを維持し続けなければなりません。ドキュメント化は極めて重要です。すべてのテーブル、カラム、関係性には、その目的と所有者を明記する必要があります。
定期的な監査:
ERDの四半期ごとのレビューをスケジュールしてください。過度に成長しているテーブルや、遅くなっているクエリを特定してください。データベースの成長は、初期のリファクタリング時には存在しなかった新たなボトルネックを明らかにすることがよくあります。
自動スキーマチェック:
CI/CDパイプラインにスキーマ検証を統合してください。承認なしに新しい結合を追加したり、重要な制約を削除したりすることを防ぎます。これにより、システムが長期間にわたり最適化された状態を保つことができます。
チーム研修:
すべてのバックエンドエンジニアが新しいデータモデルを理解していることを確認してください。スキーマについて共有された理解があることで、アドホックなクエリによって新たな技術的負債が生じる可能性が低くなります。
データモデリングに関する最終的な考察 🔗
レガシーなエンティティ関係図を最適化することは、歴史的正確性と将来のスケーラビリティの間でバランスを取ることです。唯一の「正しい」スキーマは存在しません。適切なモデルとは、現在のビジネス目標を支えつつ、成長の余地を残すものであるということです。
システムの特定のボトルネック(結合コスト、ロック競合、インデックスの肥大化など)に注目することで、的確な改善が可能です。事例研究は、完全な再構築なしに、深く根付いた構造さえも近代化できる可能性を示しています。鍵となるのは、順序立てて進み、厳密に検証し、関係するトレードオフを明確に理解し続けることです。
データモデリングは静的ではありません。提供するトラフィックとともに進化します。ERDを、コードと同様に注意深く管理すべき動的な文書として扱いましょう。適切なアプローチを取ることで、レガシーなシステムを現代のウェブが求める要求を処理できる高性能なエンジンに変革できます。