











大規模なバックエンドシステムのデータアーキテクチャを設計することは、アプリケーション全体の持続可能性と安定性を決定する基盤となる作業である。エンティティ関係図(ERD)は、このアーキテクチャの設計図として機能する。ERDはデータ構造を視覚的に明示し、情報の異なる要素がシステム内でどのように接続され、関係し、相互に作用するかを定義する。企業環境では、データの一貫性、整合性、スケーラビリティが極めて重要であるため、既存のERD標準に従うことは単なるベストプラクティスではなく、必須である。
データモデリングに標準化されたアプローチがなければ、バックエンドシステムは脆弱化するリスクがある。一貫性のない命名規則、曖昧な関係、不十分な正規化は、パフォーマンスのボトルネック、保守の困難、データの破損を引き起こす可能性がある。本ガイドでは、複雑な企業環境に適した堅牢なデータベーススキーマを構築するために必要な重要な標準と手法を検討する。専門チームがデータレイヤーの信頼性を長期にわたって維持するために採用する、コアコンポーネント、表記法、正規化ルール、ガバナンス戦略について検証する。
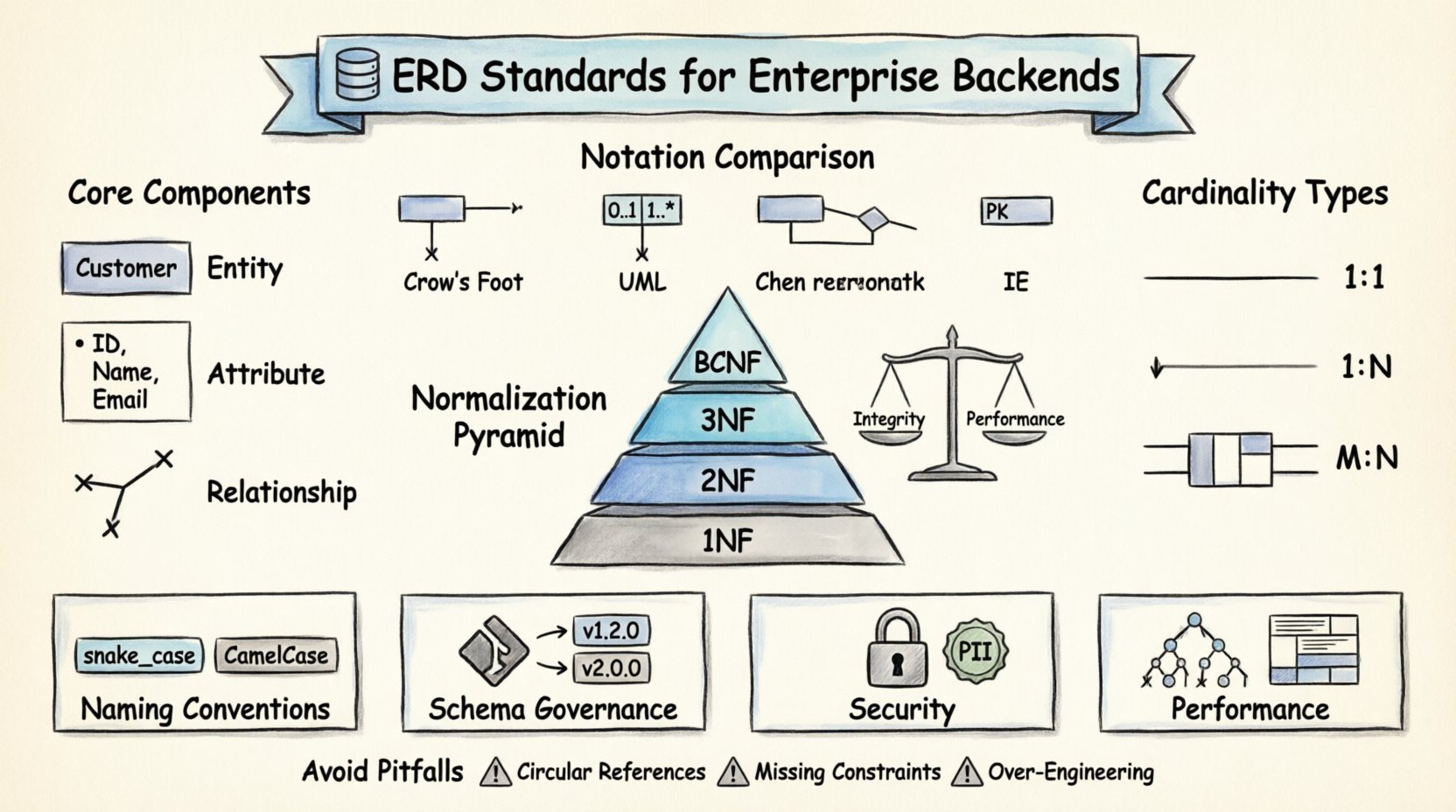
エンタープライズERDのコアコンポーネント 🧩
具体的な標準に深入りする前に、ERDを構成する基本的な構成要素を理解することが不可欠である。プロフェッショナルな文脈におけるすべての図は、3つの主要な要素に依存している。これらの要素が連携することで、データの論理構造を記述する。
- エンティティ: これらは、データが格納される対象となる現実世界のオブジェクトや概念を表す。バックエンドの文脈では、エンティティはしばしばデータベースのテーブルに直接対応する。例として、顧客, 注文、または製品がある。エンティティは、すべてのレコードが一意の識別を持てるように明確に定義されなければならない。
- 属性: 属性は、エンティティの特定の性質や特徴を記述する。これらはテーブル内の列に対応する。顧客 エンティティの場合、属性には顧客ID, 氏名、および電子メールアドレスなどが含まれる。属性のデータ型を適切に定義することは、データの整合性にとって不可欠である。
- 関係: 関係は、エンティティどうしがどのように相互作用するかを定義する。これらはテーブル間の制約や関連を設定する。たとえば、1つの顧客が複数の注文を発注できる。この関係は、バックエンドで必要となる外部キー制約や結合ロジックを規定する。
エンタープライズグレードの開発において、これらのコンポーネントは単なる抽象的概念ではなく、クエリ最適化、アクセス制御、データ移行戦略の基盤となる。適切に文書化されたERDがあれば、開発者はコードの各行を確認せずにデータフローを理解できる。
表記規準と視覚的表記法 📐
ERDを描くための単一の普遍的な構文は存在しないが、異なるチーム間で明確さと一貫性を保つために広く受け入れられている規準がある。表記法を選択し、それを一貫して使用することは、重要なガバナンスの決定事項である。
チェン表記法とクロウズフット表記法
歴史的に、チェン表記法が標準であった。これは、エンティティに長方形、関係にダイヤモンドを使用していた。明確ではあるが、現代のソフトウェア開発ツールではあまり使われていない。クロウズフット表記法が業界の好まれる選択となったのは、いくつかの理由がある。
- 基数の明確さ: 一対一、一対多、多対多の関係を視覚的に示すために、特定の記号(線、円、および「足」)を使用している。
- ツールのサポート: 多くの現代的なデータベース設計ツールやリバースエンジニアリングユーティリティは、クロウズフット表記法またはUML由来の記号をネイティブにサポートしている。
- 可読性: 複雑で相互に接続されたスキーマを扱う際、一般的によりコンパクトで読みやすくなる。
表記システムの比較
| 表記スタイル | エンティティの表現 | 関係の表現 | 最適な使用ケース |
|---|---|---|---|
| クロウズフット | 長方形 | 記号付きの線(クロウズフット、円、線) | 関係データベース設計 |
| UMLクラス図 | 仕切り付きのクラスボックス | 多重度付きの矢印(0..1, 1..*) | オブジェクト指向モデリング |
| チェン | 長方形 | エンティティをつなぐダイヤモンド型 | 学術的/理論的モデル |
| IE(情報工学) | 属性付きの長方形 | 主キーを示す記号付きの線 | レガシーシステムのドキュメント |
企業向けバックエンドでは、クラウズフット記法が一般的に推奨される。これは関係制約への直接的なマッピングが可能だからである。開発者が実装中に図を解釈する際に曖昧さを最小限に抑えることができる。
正規化:データ整合性の確保 🔄
正規化とは、データの重複を減らし、データの整合性を向上させるためにデータベース内のデータを整理するプロセスである。現代のシステムではパフォーマンス向上のため、一部では非正規化を行うことがあるが、健全な初期スキーマを設計するためには正規化のルールを理解することが不可欠である。
正規形
- 第一正規形(1NF):すべての列は原子的な値を含む必要がある。1つのセルに複数の値を含むことは禁止されている。これにより、行と列の交点にあるデータは常に1つの不可分な情報となることが保証される。
- 第二正規形(2NF):テーブルは1NFにあり、すべての非キー属性は主キーに完全に依存しなければならない。これにより、複合キーの一部にのみ依存する部分的依存を防ぐことができる。
- 第三正規形(3NF):テーブルは2NFにあり、推移的依存が存在してはならない。非キー属性は他の非キー属性に依存してはならない。たとえば、都市は郵便番号に依存し、郵便番号はID, 都市都市”は別々のテーブルに移動すべきである。”
- ボーイス・コッド正規形(BCNF):3NFのより厳格なバージョンである。すべての関数的依存 X → Y に対して、X はスーパーキーでなければならない。これは、決定要因が候補キーではあるが主キーではないという3NFの特定の例外ケースを処理する。
正規化のトレードオフ
| レベル | 利点 | コスト |
|---|---|---|
| 高正規化(3NF/BCNF) | 冗長性が最小限、整合性が高い | クエリの実行に追加の結合が必要になる |
| 低度正規化(非正規化) | 読み取り性能が向上 | データ不整合のリスクが高まる |
エンタープライズシステムは通常、トランザクションスキーマにおいて3NFを目指す。読み取り性能がボトルネックになる場合、コアのトランザクションスキーマではなく、特定のビューまたはレポートテーブルに対して選択的に非正規化が適用される。
命名規則とスキーマの整備 🏷️
一貫した命名規則は保守性にとって不可欠である。複数のチームが同じバックエンドを扱う場合、命名の曖昧さはエラーを招く。標準は文書化され、lintツールやスキーマ検証スクリプトによって強制されるべきである。
テーブル名のルール
- 複数形 vs. 単数形:議論はあるが、一貫性が重要である。複数形の名前(例:Users, Orders)は英語の文脈で読みやすく、単数形の名前(例:User, Order)はオブジェクト指向の文脈で好まれることが多い。どちらか一つを選択し、グローバルに適用する。
- アンダースコア vs. キャメルケース: アンダースコア(snake_case)はSQL識別子の標準である。キャメルケース(camelCase)はアプリケーションコードで一般的である。データベース層とアプリケーション層が翻訳戦略について合意していることを確認する。
- 予約語を避ける: 予約語を使用してテーブルやカラムの名前を付けない(例:Group, Select, Order). これにより、クエリ生成中に構文エラーが発生するのを防ぎます。
- メタデータの接頭辞: 以下の接頭辞を使用してください:_audit, _log、または_temp補助テーブルとコアビジネスエンティティを区別するために使用します。
カラム名のルール
- 外部キー: 関係を明確に示してください。カラムがUsers テーブルを参照する場合、user_id という名前にするのではなくuid またはfk_user.
- ブールフラグ: 以下の接頭辞を使用してください:is_ またはhas_。たとえば、is_active またはhas_subscription.
- 日時フィールド: スコープを指定してください。次のように使用してください。created_at または updated_at 一般的な date または time.
関係性と基数 🔄
基数を理解することは、正常に動作するデータベースと壊れたデータベースの違いです。基数は、あるエンティティのインスタンスが、別のエンティティの各インスタンスと関連付けられる可能性があるか、または関連付けられなければならない正確な数を定義します。
関係の種類
- 1対1 (1:1): エンティティAの1つのインスタンスが、エンティティBの正確に1つのインスタンスに関連付けられます。これはコアビジネスロジックでは珍しいですが、セキュリティや設定データでは一般的です。例:A User は1つの Profile.
- 1対多 (1:N): エンティティAの1つのインスタンスが、エンティティBの複数のインスタンスに関連付けられます。これは最も一般的な関係です。例:1つの Department は複数の Employees.
- 多対多 (M:N): エンティティAの複数のインスタンスが、エンティティBの複数のインスタンスに関連付けられます。これには結合テーブル(関連エンティティ)が必要です。例:Students と Courses.
オプショナリティと制約
基数は物語の全体を語っていない。オプショナリティがその役割を果たす。これは、関係が必須か任意かを指す。
- 必須(必須参加): エンティティインスタンス は他のものと関連付けられなければならない。たとえば、注文 はを所有しなければならない。顧客.
- 任意(任意参加): エンティティインスタンス は関係を持たずに存在できる。たとえば、製品は注文レコードが存在しなくてもよい。
制約(NOT NULL、外部キー)をデータベースレベルで使用してこれらのルールを強制することは、アプリケーションコードで強制するよりもはるかに信頼性が高い。データのずれを防ぎ、スキーマが真実の源泉であることを保証する。
スキーマのガバナンスとバージョン管理 📜
企業環境では、データベーススキーマはコードである。アプリケーションのソースコードと同様の厳格さでバージョン管理され、レビューされ、管理されなければならない。ERDは静的な文書ではない。ビジネス要件が変化するにつれて進化する。
マイグレーション戦略
- 前方互換性: 変更は古いデータに対応できるように設計すべきである。すぐにカラムを削除するのを避け、代わりに非推奨としてマークする。
- 後方互換性: 新しいスキーマバージョンは既存のクエリを破壊してはならない。ビューを使用して、変更をアプリケーション層から抽象化する。
- 原子的な変更: 各マイグレーションスクリプトは、単一の論理的変更を表すべきである。エラーが発生した場合、ロールバックが容易になる。
ドキュメントのメンテナンス
更新されていないERDは負債である。図の生成プロセスが自動化されていることを確認する。理想的には、ERDはスキーマ定義ファイル(DML)から直接生成されるべきであり、ドキュメントと実際のデータベース状態との間にずれが生じないようにする。
- すべてのコミット時にERDの生成を自動化する。
- プルリクエストプロセスにおいてスキーマのレビューを必須とする。
- 主要なスキーマバージョンにはタグを付けて、アプリケーションリリースと関連付ける。
セキュリティおよびプライバシーに関する考慮事項 🔒
エンタープライズバックエンドは機密情報を扱う。ERDの設計段階では、特に個人識別情報(PII)に関して、セキュリティおよびプライバシー要件を考慮しなければならない。
データ分類
- 公開データ:公開してよい情報。特別な取り扱いは不要。
- 社内データ:社員のみが閲覧可能な情報。アクセス制御リスト(ACL)を検討すべきである。
- 制限データ:パスワード、健康記録、財務情報など、機密性の高いデータ。これらのフィールドは、静的および送信中での暗号化が必要である。
マスキングおよび匿名化
ERDにおいて、非本番環境でマスキングが必要なフィールドを明示する。これにより開発者がテスト中にどの列を特別な扱いが必要か理解しやすくなる。図自体がセキュリティを強制するわけではないが、セキュリティポリシーの実装をガイドする。
- PIIを含む列を明確に特定する。
- 監査用フィールドを定義する(例:last_modified_by)を定義して、誰がデータにアクセスまたは変更したかを追跡する。
- 外部キーが、列挙可能な内部IDを露呈しないようにする。
パフォーマンスおよびスケーラビリティの計画 🚀
ERDは構造に注目するが、パフォーマンスも考慮しなければならない。論理的には正しいが物理的に遅いスキーマは、負荷がかかると失敗する。
インデックス戦略
ERDで定義された関係性が、インデックスが必要な場所を決定する。外部キーは結合や制約チェックを高速化するためにインデックスを張るべきである。ただし、過剰なインデックス化は書き込み操作を遅くする可能性がある。
- 主キー:常にインデックス化される。
- 外部キー:結合のパフォーマンス向上のため、常にインデックス化される。
- 検索用カラム: WHERE句で頻繁に使用される列にはインデックスを設定すべきである。
パーティショニングとシャーディング
大規模なデータセットの場合、ERDがパーティショニング戦略の手がかりを示すことがある。データが自然にグループ化されている場合(例:地域または日付)、これはスキーマ設計に反映されるべきである。これにより、データベースは複数の物理ノードに負荷を分散できる。
避けるべき一般的な落とし穴 ⚠️
経験豊富なチームですらミスを犯す。失敗の一般的なパターンを認識することは、耐障害性の高いシステムを構築するのに役立つ。
- 循環参照: Entity AがBに依存し、BがAに依存する関係を避け、データの削除や更新を複雑にするループを生じさせない。
- 制約の欠如:アプリケーションコードにルールの強制を依存する(例:価格が正であることを保証するなど)はリスクが高い。データベースでCHECK制約を使用する。
- 過剰設計:すべての将来のシナリオをモデル化するべきではない。現在の要件に応じて設計し、適応できる十分な柔軟性を持つが、仮想的な使用ケース用にテーブルを作成するのは避ける。
- ハードコードされた値:照合テーブルなしでステータスコードを整数として保存するのは避ける。注文ステータスのようなステータスには参照テーブルを使用して、明確さを保つ。
ワークフローに標準を適用する 🛠️
これらの標準を採用するには文化の変化が必要である。単に図を描くだけでは不十分である。図が開発プロセスを牽引しなければならない。
- 設計を最優先する:マイグレーションスクリプトを書く前に、ERDの承認を必須とする。
- コードレビュー:標準のコードレビュー確認リストにスキーマの変更を含める。
- トレーニング:すべてのバックエンドエンジニアが正規化と基数の概念を理解していることを確認する。
- ツールの活用:共同作業とバージョン管理をサポートするスキーマ設計ツールに投資してください。
エンティティ関係図をシステムアーキテクチャの生き生きとした構成要素として扱うことで、企業チームはデータレイヤーが堅牢な状態を保つことを確保できます。設計フェーズの標準化に投資した努力は、技術的負債の削減とシステム信頼性の向上という成果をもたらします。適切に構造化されたデータベースは、スケーラブルなアプリケーションを構築する基盤となるのです。
データモデリングにおいて明確性、一貫性、整合性を最優先すると、成長を支える基盤が築かれます。ここに提示された基準は、その基盤のためのフレームワークを提供します。これらの基準に従うことで、組織が拡大してもバックエンドが保守可能で、安全かつ効率的であることが保証されます。