











ソフトウェアアーキテクチャの世界では、エンティティ関係図(ERD)ほど重要な概念は少ない。ERDはデータの設計図であり、テーブル、キー、関係性という複雑な構造を開発者が理解するための地図である。アプリケーションが遅延するとき、多くの場合、最初にスケーマのせいだと考えがちだ。その前提は明確だ:図が完璧なら、パフォーマンスも完璧になるはずだ。
これはよくある誤解である。 🧐 よく設計されたERDは基盤にはなるが、スピードの万能薬ではない。完璧な論理モデルが、自動的に高速な物理実行に結びつくわけではない。設計理論と実行時の現実とのギャップを理解することは、圧力がかかる状況でも応答性を保つシステムを構築するために不可欠である。
このガイドでは、なぜ完璧なERDが高速な応答時間を保証しないのか、またデータベースパフォーマンスに影響を与える他の重要な要因について解説する。ストレージエンジンからネットワーク遅延に至るまで、データ処理の各層を分析し、アプリケーション速度の真の要因を明らかにする。
📐 エンティティ関係図の理解
パフォーマンス指標の詳細な分析に入る前に、ERDが実際に何を表しているかを明確にしなければならない。ERDは論理的な構造物である。それは何のデータが存在するか、そしてどのように他のデータと関係しているかを記述する。エンティティ(テーブル)、属性(カラム)、関係性(外部キー)を定義する。
- エンティティ:テーブルとして表現された現実世界のオブジェクト。
- 属性:そのオブジェクトの特徴をカラムに格納したもの。
- 関係性:エンティティ間のリンクで、通常は主キーと外部キーによって強制される。
- 基数:エンティティ間の数的関係(1対1、1対多)。
ERDの主な目的はデータの整合性である。データが時間の経過とともに一貫性を持ち、正確で利用可能であることを保証する。孤立したレコードの発生を防ぎ、参照整合性を維持する。しかし、整合性と速度は同じものではない。ドアを閉じて固定する鍵は中身を守るが、ドアを開ける速度を速くはしない。
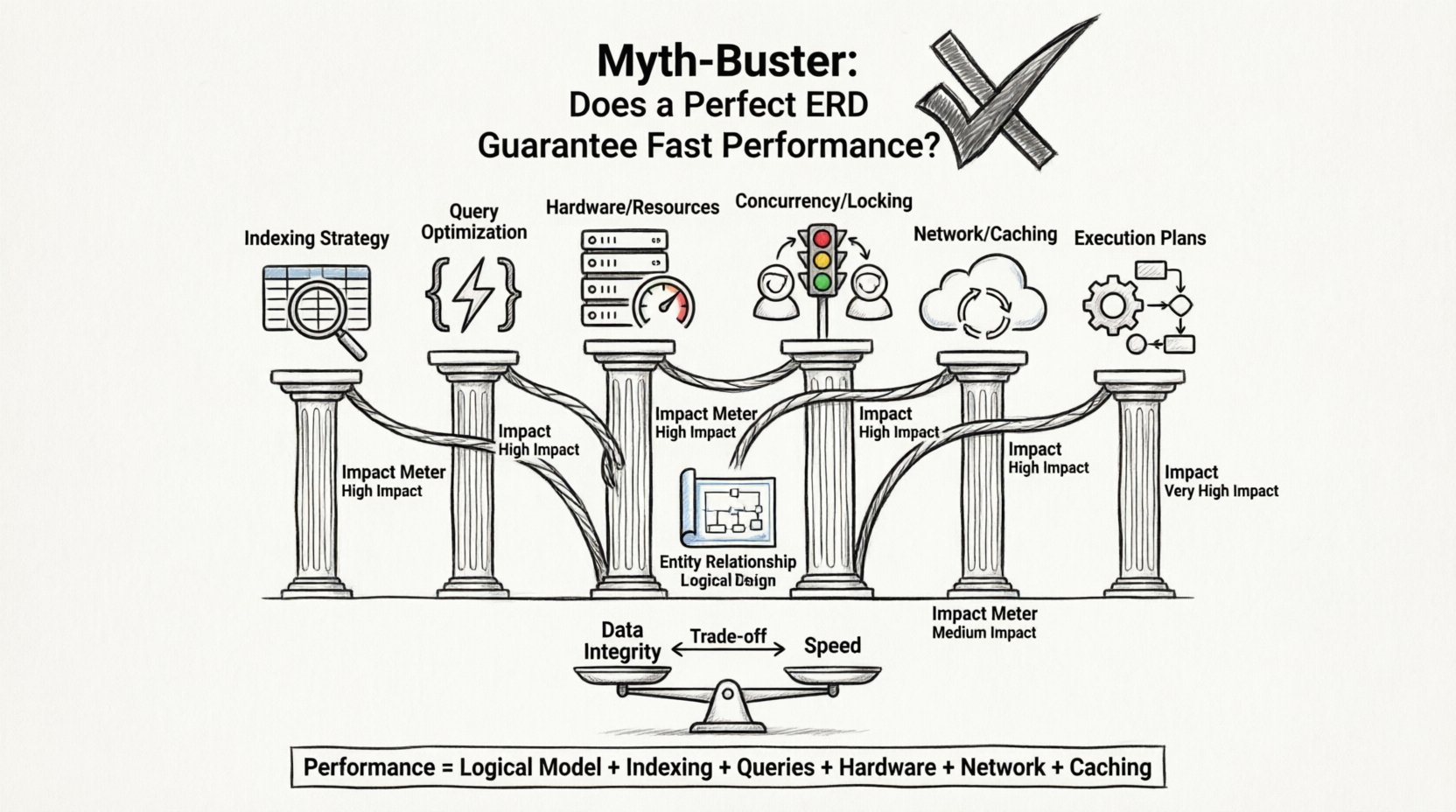
⚡ パフォーマンスの式:スキーマを超えて
アプリケーションの応答時間は、多くの要素の合計である。データベースはその式の一部にすぎない。データベースエンジンがデータを瞬時に取得しても、他の場所にボトルネックがあるため、アプリケーションは依然として遅く感じられることがある。
速度に影響を与える主な要因は以下の通りで、しばしばスキーマ設計を上回る影響を持つ:
1. インデックス戦略
ERDは主キーと外部キーを定義しており、これらはしばしば自動的にインデックスを生成する。しかし、これらのデフォルトインデックスは複雑なクエリに対してほとんど十分ではない。パフォーマンスは、特定のクエリパターンに合わせて調整された補助インデックスに大きく依存する。
- インデックスの欠如:頻繁にフィルタリングされるカラムにインデックスがない場合、データベースはフルテーブルスキャンを実行しなければならない。すべての行を読み取る必要があり、大規模なデータセットでは指数関数的に遅くなる。
- インデックスのオーバーヘッド:インデックスが多すぎると、書き込み操作が遅くなる。すべての挿入や更新は、そのテーブルに関連するすべてのインデックスを更新する必要がある。
- 選択性:選択性が低いカラム(例:性別やステータス)にインデックスを設置しても、クエリ最適化子が無視する可能性がある。
2. クエリ最適化
データの取得方法は、その保存方法よりも重要です。適切でないクエリは、完璧なスキーマを無力化する可能性があります。一般的な問題には以下が含まれます:
- N+1問題:親レコードを取得した後、ループを使って個別に子レコードを取得する。これにより、1つのJOINで済むところを複数のデータベースへの往復通信が発生する。
- SELECT * の使用:すべてのカラムを取得すると、必要なのが1つでもネットワークトラフィックとメモリ使用量が増加する。
- 暗黙的変換:文字列と数値、または日付とタイムスタンプを比較すると、インデックスの使用が妨げられることがある。
- 複雑なJOIN:適切なフィルタリングなしに複数の大きなテーブルを結合すると、計算負荷が著しく増加する。
3. ハードウェアとインフラ構造
ソフトウェアの効率性は物理的な制限を克服できない。基盤となるハードウェアがパフォーマンスの上限を決定する。
- ストレージタイプ:ランダムI/O操作において、ソリッドステートドライブ(SSD)はハードディスクドライブ(HDD)よりも著しく高速である。
- メモリ(RAM):データの作業セットがRAMに収まる場合、クエリはほぼ瞬時に実行される。データをディスクから読み込む必要がある場合は、遅延が増加する。
- CPUパワー:複雑な計算、並べ替え、集計には処理能力が必要である。
- ネットワーク遅延:アプリケーションサーバーとデータベースサーバーの距離が、すべてのリクエストにミリ秒単位の遅延を加える。
4. 同時実行とロック
複数のユーザーが同時にシステムにアクセスすると、データベースは競合を管理しなければならない。これがパフォーマンスが低下しやすいポイントである。
- ロック競合:1つのトランザクションが行にロックを取得していると、他のトランザクションは待たなければならない。高い競合はタイムアウトや遅い応答時間を引き起こす。
- デッドロック:2つのトランザクションがお互いを待つことで、システム全体の停止を引き起こす可能性がある。
- 分離レベル:高い分離レベル(例:可視化可能)はより強い保証を提供するが、同時実行性と速度を低下させる。
📊 ERDの影響とその他のパフォーマンス要因の比較
ERDの影響を他の変数と比較して可視化するため、以下の分解を検討してください。この表は、ERDが価値を提供する点と、不足している点を強調しています。
| 要因 | 読み取り速度への影響 | 書き込み速度への影響 | ERDの役割 |
|---|---|---|---|
| テーブルスキーマ構造 | 中 | 中 | 関係性と正規化を定義する。 |
| インデックス化 | 高 | 低 | ERDはキーを定義するが、すべてのインデックスを定義するわけではない。 |
| クエリ論理 | 非常に高い | 中 | ERDはクエリ構文を規定しない。 |
| ハードウェアリソース | 高 | 高 | なし。スキーマに依存しない。 |
| ネットワーク遅延 | 高 | 中 | なし。スキーマに依存しない。 |
| 接続プール | 中 | 中 | なし。アプリケーションの設定による。 |
🧱 正規化のトレードオフ
データベース設計における最も議論されているトピックの一つが正規化である。ERDは通常、冗長性を減らすために第三正規形(3NF)を目指す。これによりスペースを節約し、一貫性を確保できるが、パフォーマンスに悪影響を及ぼすことがある。
データが高度に正規化されている場合、1つの情報は1か所に格納されます。それを取得するには、システムが複数のJOINを経由しなければなりません。各JOINは計算上のオーバーヘッドを追加します。
ユーザーのプロフィールと最新の注文、および製品の詳細を表示する状況を考えてみましょう。正規化されたERDでは、この処理に4つのテーブルを結合する必要があるかもしれません。これらのテーブルが大きくなると、CPUは行の並べ替えや照合に多くの時間を費やすことになります。
デノーマライゼーションは、この問題に対処するために用いられる技術です。データの重複を許容することでJOINの必要性を減らします。これにより読み取り速度が向上しますが、書き込み処理が複雑化し、データの不整合のリスクが生じます。完璧なERDが自動的にこの線を引くわけではなく、読み込み/書き込みの比率に基づく戦略的な判断が必要です。
🔍 深掘り:クエリ実行計画
データベースエンジンは、クエリを書かれた通りに正確に実行するわけではありません。リクエストを分析し、次のものを生成します。実行計画。この計画は、処理の順序、どのインデックスを使用するか、スキャンを行うかシークを行うかを決定します。
ERDはデータ型や制約に関するメタデータを提供します。しかし、最適化エンジンはデータの分布に関する統計情報を用いて決定を行います。統計情報が古くなっていると、最適なインデックスを無視して、劣った計画を選択してしまう可能性があります。
例えば、テーブルに1000万行あるのに統計情報が100行だと誤認している場合、最適化エンジンはインデックスシークよりもフルスキャンの方が安価だと判断するかもしれません。これにより、良好なERD構造にもかかわらず、性能が低下します。
🛡️ データ整合性 vs. 速度
データ整合性を確保することと速度を最大化することの間には、本質的な緊張関係があります。ERDは制約やトリガーなどの整合性ルールを強制します。
- 外部キー制約:参照整合性を保証します。削除や更新の際、関連するテーブルをチェックする必要があります。これにより、書き込み処理に遅延が生じます。
- トリガー:データ変更時に自動実行されるスクリプトです。ロジックの実行には有用ですが、すべてのトランザクションに処理時間を追加します。
- 一意制約:新しい値を挿入する前に、既存の値をチェックする必要があります。
高スループットシステムでは、これらのチェックを無効化したり、遅らせて速度を向上させることがあります。完璧なERDはすべてのルールを含みますが、高性能システムでは修正されたアプローチが必要になる場合があります。
🚦 最適化の実践的ステップ
アプリケーションが遅い場合、すぐにERDを再設計しないでください。ボトルネックを特定するための体系的なアプローチを取ってください。
1. 遅延クエリの分析
長時間実行されるステートメントをキャプチャするため、クエリログを有効化してください。プロファイリングツールを使って、時間がどこに使われているかを確認してください。ロック待ちですか?行のスキャンですか?ロジックの処理ですか?
2. インデックス使用状況の確認
実際に使用されているインデックスを確認してください。使用されていないインデックスはストレージを消費し、書き込みを遅くします。頻繁に実行されるクエリのWHERE句やJOIN句に合ったインデックスを作成してください。
3. ハードウェアの割当最適化
データベースサーバーが作業セットをキャッシュできるだけのRAMを持っていることを確認してください。データベースがメモリ制限の場合、RAMを追加すれば即効性のある改善が得られます。CPU制限の場合、プロセッサのアップグレードやコードの最適化が必要になるかもしれません。
4. キャッシュの導入
すべてのリクエストがデータベースにアクセスする必要はありません。頻繁にアクセスされるデータにはメモリ内キャッシュ(RedisやMemcachedなど)を使用してください。これにより、読み取り操作はデータベースを完全に迂回できます。
5. 同時実行の監視
ロック待ちを監視してください。ユーザーがタイムアウトを経験している場合は、トランザクションの長さを確認してください。トランザクションを短くすることで、ロックを素早く解放できます。
🔄 スキーマ進化の役割
アプリケーションは変化します。要件も変化します。ERDはビジネスの変化に合わせて進化しなければなりません。6か月前には完璧だったスキーマでも、新しい機能やデータ量の増加により、今日では陳腐化している可能性があります。
移行戦略は重要です。小さなテーブルから大きなパーティショニングされたテーブルへデータを移動すると、パフォーマンスが向上する可能性があります。データ型をVARCHARからINTに変更することで、ストレージを削減し、スキャン速度を向上させることができます。これらの決定は、初期のERD作成後に行われます。
静的なERDはデータの増加を考慮していません。データがスケーリングするにつれて、パフォーマンス特性も変化します。1万件のレコードで動作していた設計が、1000万件では失敗する可能性があります。そのため、パフォーマンスチューニングは一度きりの作業ではなく、継続的なプロセスです。
🧩 NoSQLの考慮事項
ERDの概念は、リレーショナルデータベースに最も厳密に適用されます。NoSQL環境では、データモデルが異なります。ドキュメントストア、キー値ストア、グラフデータベースは、関係の扱い方が異なります。
ドキュメントストアでは、結合を避けるためにデータを埋め込むことがあります。これは意図的に正規化を回避するものです。グラフデータベースでは、関係が第一級の存在として扱われ、移動を最適化するために明示的に格納されます。
ここでは、ERDの保証という神話がさらに強調されます。NoSQLでは、スキーマはしばしば柔軟または動的です。パフォーマンスは、厳格な図面よりもアプリケーションコードで定義されたアクセスパターンに大きく依存します。
🏁 データアーキテクチャに関する最終的な考察
高速なアプリケーションを構築するには包括的な視点が必要です。ERDは、データが論理的に整理されていることを保証する重要な出発点です。混乱を防ぎ、整合性を維持します。しかし、それはスピードを生み出すエンジンではありません。
パフォーマンスは以下の要素の連携の結果です:
- 堅実な論理モデル。
- 戦略的なインデックス作成。
- 効率的なクエリの記述。
- 適切なハードウェアリソース。
- 適切なネットワーク構成。
- 効果的なキャッシュ戦略。
遅延応答の原因をスキーマに帰するというのは、誤った修正につながる単なる手抜きです。紙上の完璧な図面は、遅いディスク、ネットワークタイムアウト、または poorly written query を補うことはできません。真のパフォーマンス工学とは、ブループリントを超えて、実際のデータフローを観察することにあります。
システムを監査する際は、まずERDから始めて正しさを確認してください。次に実行計画に移り、効率性を確認します。最後にインフラを評価して、容量を確保します。すべてのレイヤーに取り組むことで、ユーザーが期待する応答性を達成できます。