











堅牢なデータベーススキーマを設計するには正確さが求められる。エンティティ関係図(ERD)は、この構造の設計図として機能し、複雑なビジネスロジックを開発者やステークホルダーが理解できる視覚的な形式に変換する。しかし、その有用性にもかかわらず、ERDはモデリング段階でしばしば誤解の原因となる。記号の曖昧さ、基数の誤解、属性の種類に関する混乱は、開発ライフサイクルの後半に大きな再作業を引き起こす可能性がある。
このガイドは、データベースアーキテクトやエンジニアの間でよく摩擦を生じるERD内の特定の構成要素について詳細に検討する。強固なエンティティと弱いエンティティの違いを明確にし、関係の表記法を分解し、属性の分類を分析することで、誤りを減らし、結果として得られるデータモデルが運用要件を正確に反映することを確保できる。
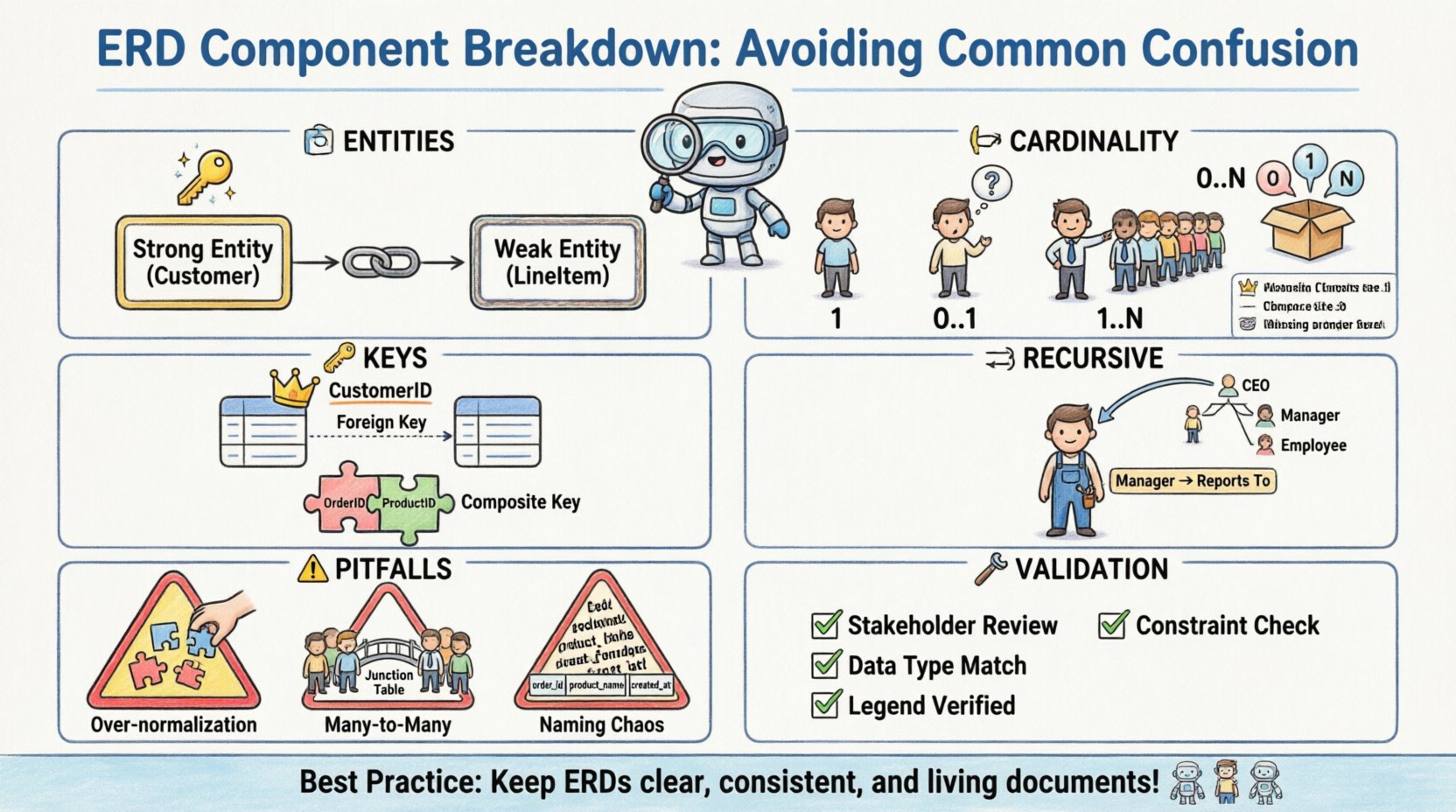
🏗️ エンティティの種類:強固なエンティティと弱いエンティティの違い
任意のERDの中心にはエンティティがある。これらはデータが格納される対象や概念を表す。ほとんどの実務者がテーブルの概念を理解している一方で、強固なエンティティと弱いエンティティの違いは、最初の大きな混乱の原因になりやすい。
- 強固なエンティティ: これらのエンティティは自らの主キーを持つ。独立しており、識別のために他のエンティティに依存しない。たとえば、
顧客エンティティは通常、一意の顧客IDを持ち、強固なエンティティとなる。 - 弱いエンティティ: これらのエンティティは、自らの属性だけでは一意に識別できない。識別親と呼ばれる別のエンティティとの関係に依存して存在する。たとえば、注文システム内の
明細行は、特定の注文.
混乱の原因は、これらの表現が視覚的にどのように描かれるかにある。強固なエンティティは通常、標準の長方形で描かれる。弱いエンティティはしばしば二重の長方形で表現される。これらを視覚的に区別しないと、弱いエンティティのテーブルが、その依存関係を強制するための必要な外部キー制約なしに作成されるデータベース実装の誤りにつながる。
誤分類の影響
弱いエンティティを強固なエンティティとしてモデル化すると、データベースが親を持たないレコードの存在を許可する可能性がある。これにより、孤立データが発生する。逆に、強固なエンティティを弱いエンティティとしてモデル化すると、不要な依存関係が強制され、エンティティの主な文脈外での利用可能性が制限される可能性がある。オブジェクトが独立して存在できるかどうかを判断した上で、強固なエンティティとしてのステータスを割り当てることが不可欠である。
- 独立性の確認:このレコードは他のレコードへのリンクなしで存在できるか?
- 識別子の源泉:一意のIDはエンティティ自体から来るのか、それとも関係から来るのか?
- 存在依存性:親を削除すると、子も自動的に削除されるか?
🔗 関係の基数とオプショナリティ
関係はエンティティどうしがどのように相互作用するかを定義する。基数は、あるエンティティのインスタンスが、別のエンティティの各インスタンスと関連できる数(または必須の数)を指定する。この点は、記法のスタイルの違いにより、最も混乱しやすい領域である。
基数の表記法
図上で基数を表す方法は複数存在する。一部は「1」や「N」などのテキストラベルを使用するが、他はクロウズフット記法を用いる。これらのスタイルを混在させたり、記号を誤解したりすると、物理スキーマに論理的な穴が生じる。
| 記号/ラベル | 意味 | 例のシナリオ |
|---|---|---|
| 1 | ちょうど一つ | 個人はちょうど一つの社会保障番号を持つ。 |
| 0..1 | ゼロまたは一つ | 個人は中間名を持たないか、一つだけ持つことができる。 |
| 1..1 | 一つであり、唯一のもの | プロジェクトには、必ず一つのプロジェクトマネージャーが割り当てられている必要がある。 |
| 0..N | ゼロから多数 | 注文にはゼロ個または多数の行項目を持つことができる。 |
| 1..N | 一つから多数 | 部門には、一つまたは多数の従業員がいなければならない。 |
選択的およびnull許容性
選択的とは、関係が必須か任意かを指す。これはデータベーステーブル内の外部キー定義に直接影響する。関係が必須の場合、外部キー列はnullにできない。任意の場合、nullにできる。
図面で実線と破線を示す場合、混乱が生じることが多い。明確な凡例がないと、開発者は存在しない必須関係を仮定し、データ入力時に制約違反を引き起こす。モデルドキュメント内に線のスタイルの意味を明示的に記録することが不可欠である。
- 必須関係: 親レコードが有効であるためには、子レコードが存在しなければならない。
- 任意関係: 子レコードは親なしで作成可能であり、親は子なしで存在してもよい。
- 外部キー制約: 必ず
NOT NULL必須の場合に、NULL任意の場合に許容される。
🔑 属性とキーの識別
属性はエンティティのプロパティです。見た目は単純に思えるかもしれませんが、属性をキー、外部キー、および単純な属性に分類する際に、正規化やクエリパフォーマンスにおいて頻繁に誤りが生じます。
プライマリキー対外部キー
プライマリキー(PK)は行を一意に識別します。外部キー(FK)は行を親テーブルにリンクします。自然キーがサロゲートキーの代わりに使われる場合、またはPKが図の全体で一貫して定義されていない場合、混乱が生じます。
- 自然キー:データに自然に存在するキーで、社会保障番号やメールアドレスなどが該当します。これらは変更される可能性があり、整合性の問題を引き起こすことがあります。
- サロゲートキー:システムによって生成される人工的なキーで、自動増分の整数などが該当します。これらは安定性の観点から一般的に好まれます。
複合キー
複合キーは、組み合わせて1つのレコードを一意に識別する2つ以上の列から構成されます。これは、多対多関係を解決するために使用される結合テーブルでよく見られます。ここでの混乱は、列の順序と、どのテーブルがキーを保持しているかにあります。
複合キー内の列の順序が関連するテーブル間で一貫して維持されていない場合、結合が失敗するか、複雑なキャストが必要になります。プライマリキー定義における正確な列の順序を文書化することは非常に重要です。
🔁 再帰的関係
エンティティが自分自身と関係を持つ場合、再帰的関係が発生します。これは、組織図や部品表のような階層構造で頻繁に使用されます。混乱の原因は視覚的な表現にあり、線がエンティティ自身に接続されているためです。
明確なラベルがないと、関係のどちら側が親でどちらが子かがわかりにくくなります。たとえば、従業員テーブルでは、1人の従業員が他の従業員を管理しています。関係は、従業員が他の従業員のマネージャーになり得ることを明確に示す必要があります。
- 自己参照: テーブル内の外部キーが、同じテーブルのプライマリキーを指し示す。
- NULLの扱い: 階層の根には、通常、マネージャーID列にNULL値が入ります。
- 深さの制限: 階層が非常に深い場合、再帰クエリはパフォーマンスのボトルネックになることがあります。
⚠️ 一般的なモデル化の落とし穴
特定の要素を超えて、ある種の構造的パターンが実装中に混乱を引き起こすことがあります。これらの落とし穴を早期に認識することで、高コストなスキーマ移行を防ぐことができます。
1. 過剰な正規化
正規化は冗長性を減らしますが、過剰な正規化はクエリの読みやすさや実行を難しくする可能性があります。すべての属性に対して別々のテーブルを作成すると、データが不必要に断片化されます。第三正規形(3NF)と実用的なクエリパフォーマンスのバランスを取ることが重要です。
2. 結合テーブルなしの多対多
物理的なデータベースでは、多対多関係は直接存在できません。結合テーブル(関連エンティティ)を使用して、2つの1対多関係に分解する必要があります。このステップを忘れると、標準SQLで実装できないモデルになります。
- 論理モデル対物理モデル: 論理モデルでは、2つのエンティティ間にN:Nの基数を持つ直接の線が表示されることがあります。
- 物理的実装: この線は、両側の外部キーを含む新しいテーブルによって分割される必要があります。
3. 名前付け規則の不整合
混在した命名規則(例:customer_id と CustomerID と customerId)は、クエリを書く開発者にとって混乱を招きます。プロジェクトの初期段階で標準化された命名規則を定めるべきです。
- 小文字+アンダースコア:
order_line_items - PascalCase:
OrderLineItems - CamelCase:
orderLineItems
🛠️ 検証戦略
ERDが正確かつ使いやすい状態を保つため、レビュー過程で特定の検証ステップを実施すべきです。これらのステップにより、スキーマが固定される前に混乱の原因を発見できます。
- ステークホルダーとのウォークスルー:ビジネスユーザーと図面を確認し、関係性が彼らのワークフローに対するメンタルモデルと一致しているかを確認する。
- 制約の検証:すべての外部キーが対応する主キー参照を持っているかを確認する。
- データ型の一貫性:1つのテーブルで整数として定義された属性が、別のテーブルで文字列として定義されていないことを確認する。
- 凡例の準拠:図面で使用されたすべての記号が、提供された凡例または標準と一致しているかを確認する。
📝 最良の実践の要約
エンティティ関係図の明確さを維持するには、規律が必要です。標準的な表記に従い、カーディナリティを明確に定義し、エンティティの種類を区別することで、誤解のリスクは大幅に低下します。目標は単に絵を描くことではなく、安定的で信頼性の高いデータベースシステムに直接変換できる仕様を作成することです。
図は動的な文書であることを思い出してください。要件が変化するたびに、ERDもその変化を反映するように更新すべきです。これにより、データモデルが時間の経過とともにビジネスを正確にサポートし続けることが保証されます。この記事で提示された構造的ガイドラインに従い、定期的なレビューを行うことで、データベースプロジェクトを妨げる一般的な落とし穴を回避できます。