











堅牢なデータアーキテクチャを設計するには、情報がどのように接続され、関連し、永続化されるかを深く理解する必要があります。この設計の核となるのがエンティティ関係図(ERD)です。従来、リレーショナルデータベースに関連付けられてきたERDの意味論は、現代のNoSQL環境の多様なニーズに対応するように進化しました。本ガイドでは、異なるストレージパラダイム間でデータ関係をモデル化する際の微細な点を検討し、パフォーマンスを犠牲にすることなく構造的整合性を保証します。
データモデリングの基盤となる概念 🏗️
特定のデータベースタイプに深入りする前に、共通の語彙を確立することが不可欠です。エンティティ関係図は視覚的な設計図として機能します。エンティティ(テーブル、コレクション、またはドキュメント)、それらの属性(列、フィールド、またはプロパティ)、およびそれらを結ぶ関係を定義します。
- エンティティ:ビジネスドメイン内の明確に区別されたオブジェクトまたは概念。データベースの文脈では、ユーザー、製品、注文などになります。
- 属性:エンティティを説明する性質。例として、id, name, created_at、またはstatus.
- 関係:2つのエンティティ間の関連。これは、1つのエンティティのデータが別のエンティティのデータとどのように接続されるかを定義します。
- 基数:関係の数的側面。関係が1対1、1対多、または多対多であるかどうかを指定します。
ERDを作成する際の目的は、アプリケーションの現実世界の論理を表現することです。適切に構築された図は、開発者の曖昧さを軽減し、開発ライフサイクルの後段階で効率的なクエリを書けることを保証します。
リレーショナル環境における意味論 🗃️
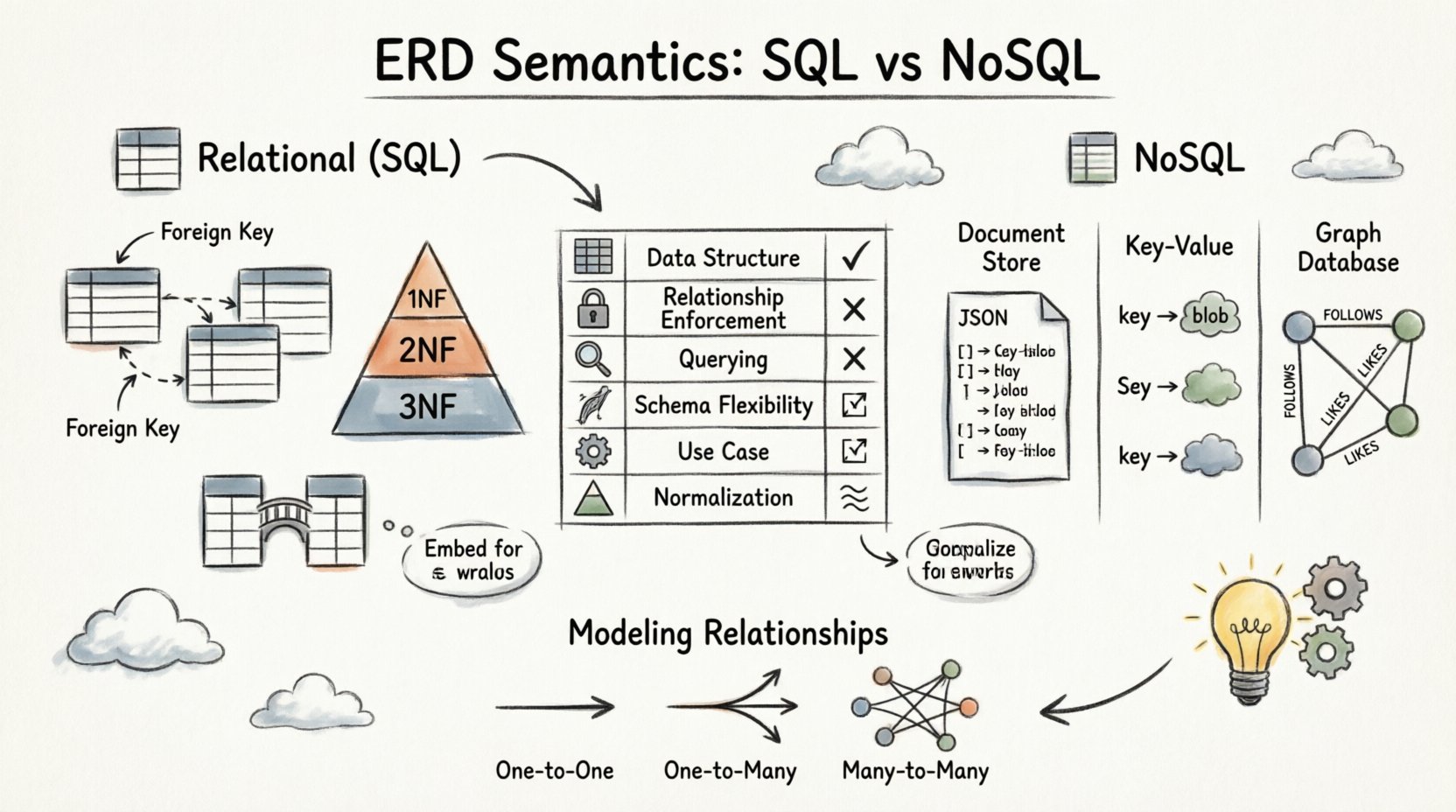
リレーショナルモデルでは、データは厳格なスキーマを持つテーブルに格納されます。ここでのERDの意味論は厳格で、集合論および第1正規形の原則によって支配されます。すべての関係は、参照整合性を維持するためにデータベースエンジンによって強制されます。
1. 外部キーの役割
外部キーはリレーショナルERDの骨格です。物理的にテーブルを結びつけます。ERDで2つのテーブルをつなぐ線が表示される場合、実装は子テーブルの外部キー列が親テーブルの主キーを参照することに依存しています。
- 実装:列に格納される数値またはアルファベット・数値の値。
- 制約:データベースエンジンが孤立レコードの発生を防止します。参照される主キーに存在しない値は、外部キー列に挿入できません。
- カスケード: 親レコード(削除または更新)に対する操作は、定義されたルールに基づいて自動的に子レコードに伝播することができる。
2. 正規化と整合性
関係型ERDは正規化を優先する。このプロセスは、属性を論理的なグループに整理することでデータの重複を削減する。適切に正規化されたERDは、関与するテーブルの数のため、通常はより複雑な構造を持つ。
- 1NF: 原子性を保証する;各セルには単一の値が含まれる。
- 2NF: 部分的依存関係を除去する;属性は主キー全体に依存する。
- 3NF: 推移的依存関係を除去する;非キー属性は主キーにのみ依存する。
この構造により、データの一貫性が保証される。ユーザーが名前を変更すると、1か所で更新され、そのユーザーを参照するすべてのレコードが即座に変更を反映する。
3. 多対多関係の扱い
多対多関係は関係型システムにおいて意味的に明確に異なる。この場合、2つのテーブルを直接リンクすることはできない。代わりに、中間の結合テーブルが必要となる。
- 構造: 両方の関連エンティティの主キーを含むテーブル。
- 機能: このテーブルはブリッジとして機能し、エンティティAの複数のレコードがエンティティBの複数のレコードにリンクできるようにする。
- クエリ: このデータを取得するには、
JOIN操作が必要となるが、正しくインデックスが設定されていない場合、大規模なデータセットでは計算コストが高くなる可能性がある。
NoSQL環境における意味論 📦
NoSQLデータベースは柔軟性を提供する。ERDの意味論は構造的制約から論理的表現へとシフトする。図は厳密なスキーマ定義よりも、設計パターンのガイドとしての役割が強くなる。異なるNoSQLモデルは関係を異なる方法で扱う。
1. ドキュメントストアと埋め込み
ドキュメント指向のデータベースでは、データはJSONに似たドキュメントとして格納される。ERDは、読み取りパフォーマンスを最適化するために、関連データを単一のドキュメント内に直接埋め込むことをしばしば提案する。
- 1対多: 親ドキュメントは子オブジェクトの配列を含むことができる。これにより、取得時に結合(JOIN)が必要なくなる。
- 影響: 子データの更新には、親ドキュメント全体を再書き込みする必要がある。親ドキュメントが非常に大きくなると、競合が発生する可能性がある。
- 読み取り vs. 書き込み: このアプローチは読み取りを最適化する。速度を求める代わりに、書き込みパフォーマンスとデータの重複を犠牲にする。
2. キーバリューストア
キーバリューストアはデータを不透明なブロブとして扱います。ここでのERDの意味は最小限です。関係性はデータベースエンジンではなく、アプリケーション層によってしばしば推論されます。
- 参照:ドキュメントはしばしば別のドキュメントへの参照IDを含み、外部キーに似ていますが、制約は適用されません。
- 責任:アプリケーションロジックが参照されたIDが存在し、有効であることを保証しなければなりません。データベースレベルでの制約は存在しません。
- 使用例:キャッシュ、セッション管理、または関係性が主な関心ではない非常に柔軟なデータ構造に最適です。
3. グラフデータベース
グラフデータベースは関係性に特化して設計されています。この文脈におけるERDは、ノードとエッジに直接対応します。これはおそらくエンティティ関係図の最も直訳的な解釈です。
- ノード:エンティティ(例:Person、Location)を表します。
- エッジ:関係性(例:LIVES_IN、KNOWS)を表します。
- プロパティ:ノードとエッジの両方に属性を付けることができます。
- トラバーサル:クエリはエッジに従います。関係性は検索ではなく、パスの移動です。
モデル化アプローチの比較分析 📊
これらの環境間の違いを理解することは、適切なツールを選択するのに役立ちます。以下の表は、ERDの意味がこれらのシステム間でどのように変換されるかを概説しています。
| 機能 | リレーショナル(SQL) | ドキュメントストア | グラフデータベース |
|---|---|---|---|
| データ構造 | 行と列を持つテーブル | JSONドキュメント | ノードとエッジ |
| 関係性の強制 | 外部キー(厳格) | 手動 / アプリケーションレベル | ネイティブなエッジ参照 |
| 関係のクエリ | JOIN 操作 | 検索または埋め込み | パスのたどり |
| スキーマの柔軟性 | 固定スキーマ | 動的スキーマ | 準構造化 |
| 主な使用ケース | トランザクションの整合性 | コンテンツ管理 / 権限階層 | ネットワーク / ソーシャルグラフ |
| 正規化 | 高い(3NF / BCNF) | 低い(非正規化) | 該当しない |
関係のモデリング:詳細な考察 🔗
ERDに描かれる関係の表現方法が、アプリケーションのクエリパターンとパフォーマンス特性を決定する。特定の基数について詳しく検討しよう。
1対1の関係
これは最も単純な関係である。Table Aの1つのレコードは、Table Bの正確に1つのレコードに対応する。
- SQLでの実装:いずれかのテーブルに外部キーを設け、一意制約を付ける。
- NoSQLでの実装:検索を避けるために、しばしば1つのドキュメントに統合されるか、一意の参照を持つ別々の場所に保存される。
- 使用するタイミング:認証情報から分離されたユーザー設定、または特定の環境にリンクされた設定。
1対多の関係
これは最も一般的な関係タイプである。Table Aの1つのレコードは、Table Bの複数のレコードに関連する。
- SQLの実装: テーブルBの外部キーで、テーブルAを参照する。
- ドキュメントストア: 「Many」側を「One」側のドキュメント内に配列として埋め込む。これにより、階層全体を一度に読み取る際に効率的である。
- グラフデータベース: 「One」ノードから複数の「Many」ノードへエッジを作成する。
- 考慮事項: 「Many」側が大幅に増加した場合、ドキュメントストアに埋め込むとストレージ制限に達する可能性がある。ハイブリッドアプローチ(埋め込みではなく参照)が必要になる場合がある。
多対多関係
この関係はSQLではブリッジが必要だが、他のシステムでは異なる動作を示す。
- SQLの実装: 両方の親テーブルのIDを含む結合テーブル。
- ドキュメントストア: 通常、正規化されていない。各ドキュメントには関連エンティティのIDリストまたは完全なオブジェクトが含まれる。データの重複は生じるが、取得が高速化される。
- グラフデータベース: これはモデルのネイティブな強みである。ノードは中間テーブルを介さずに直接接続される。
- 整合性の課題: ドキュメントストアでは、複数のドキュメント間でリストを同期させるのは難しい。共有エンティティの更新は、参照するすべてのドキュメントに手動で伝播しなければならない。
スキーマの進化と柔軟性 🔄
ソフトウェア要件は変化する。既存のアプリケーションを破壊せずにデータモデルが進化しなければならない。ERDの意味論が、この進化がどれほど容易かを決定する。
1. SQLにおけるスキーマ移行
リレーショナルスキーマを変更することは重大な操作である。通常、テーブルのロックやダウンタイム中にマイグレーションを実行する必要がある。
- カラムの追加: 一般的に安全で高速である。
- カラム名の変更: テーブル構造の再書き込みと、すべての依存クエリの更新が必要である。
- データ型の変更: データ変換に失敗した場合や、アプリケーションロジックが古い型に依存している場合は、リスクが伴う。
2. NoSQLにおけるスキーマの柔軟性
NoSQLシステムは一般的にスキーマレスまたはスキーマオンリードのアプローチを許可する。ERDは法則ではなく、ガイドラインに過ぎない。
- フィールドの追加:特定のドキュメントに新しいフィールドを追加できますが、他のドキュメントには影響しません。
- バージョン管理:ドキュメントにバージョン番号を付けるのは一般的で、時間の経過とともに異なる構造を管理するためです。
- トレードオフ:強制力の欠如により、データ品質の問題が発生する可能性があります。アプリケーションはデータを書き込む前に検証する必要があります。
モデル選択のパフォーマンスへの影響 ⚡
ERDの構造はクエリ速度に直接影響します。万能の解決策は存在せず、設計はアプリケーションのアクセスパターンと一致させる必要があります。
1. 読み込み中心のワークロード
アプリケーションがデータを頻繁に読み込むが、更新は稀な場合、非正規化は有益です。
- 戦略:関連データを埋め込むことで、必要なクエリの数を減らす。
- 利点:I/O操作の回数が減り、レイテンシが低下する。
- コスト:ストレージ使用量の増加と、更新ロジックの複雑化。
2. 書き込み中心のワークロード
アプリケーションがデータを頻繁に更新する場合は、正規化または別々のストレージを推奨します。
- 戦略:データを最も原子的な形で保存し、クエリ時に結合または参照する。
- 利点:単一の真実のソース;更新は1か所で行われる。
- コスト:結合や複数の参照による読み込みレイテンシの増加。
3. インデックス戦略
データベースの種類に関係なく、ERDはインデックスが必要な場所を示します。
- リレーショナル:インデックスは外部キーおよび
WHERE句で使用されるカラムに配置される。 - ドキュメント: インデックスは頻繁にクエリされるフィールドに配置されます。ネストされたフィールドは特定のインデックス構文を必要とする場合があります。
- グラフ: インデックスはノードラベルとエッジプロパティに配置され、移動の開始点を高速化します。
ハイブリッド環境とポリグロット永続性 🧩
現代のアーキテクチャは、複数のデータベース技術を同時に使用することが多いです。これをポリグロット永続性と呼びます。ERDの意味論は、これらのギャップを埋める必要があります。
1. データ一貫性パターン
データが複数のシステムにまたがる場合、一貫性は複雑になります。
- ACID: 関係データベースは強力な一貫性を提供します。トランザクションは同じデータベース内の複数のテーブルにまたがります。
- BASE: NoSQLデータベースは、可用性と最終的一貫性を好むことが多いです。トランザクションは単一のドキュメントに限定される場合があります。
- サーガパターン: システム間の分散トランザクションの場合、サーガパターンはローカルトランザクションを調整することで、長時間実行される操作を管理します。
2. ハイブリッドシステムにおけるERDの役割
ERDは概念的な地図として機能します。物理的なストレージが異なっていても、論理的な関係を定義します。
- マッピング: 開発者はERDを使って、どのデータをどのストアに配置するかを決定します。
- 統合: 図は、システム間でデータ同期が必要な場所を可視化するのに役立ちます。
- ドキュメント: ストレージエンジン間の技術的違いを理解できないステークホルダーに対して、統一された視点を提供します。
信頼性の高いデータモデリングのベストプラクティス 🛡️
長期的な保守性とパフォーマンスを確保するため、ERDを設計する際はこれらの原則に従ってください。
- ドメインを理解する: ビジネス要件から始めましょう。特定のユースケースをサポートしないデータはモデル化しないでください。
- 適切なツールを選ぶ: データの関係性に基づいてデータベースの種類を選択してください。トレンドではなく、複雑なネットワークにはグラフ、コンテンツにはドキュメント、トランザクションにはSQLを使用します。
- 関係を明確にドキュメント化する: 図に明確に基数をラベル付けしてください。曖昧さは実装エラーを引き起こします。
- 成長を見据えた計画:データ量のスケーリングを検討してください。埋め込み配列が大きくなりすぎないか?ジョインテーブルがボトルネックにならないか?
- 設計を繰り返す:ERDは静的ではありません。アプリケーションの進化や新たな制約の発見に応じて、それを改善し直してください。
- アプリケーション層で検証する:特にNoSQLでは、データベースがそれを強制しない可能性があるため、データの整合性を確保するために検証ロジックを実装してください。
モデル化の意味論に関する結論 📝
エンティティ関係図の意味論は普遍的ではない。それは基盤となるストレージ技術に応じて適応する。リレーショナルシステムでは、ERDはデータベースエンジンによって強制される契約である。NoSQLシステムでは、アプリケーション層のパターンガイドとなる。これらの違いを理解することで、アーキテクトはスケーラブルかつ一貫性のあるシステムを設計できる。
基数を慎重に分析し、適切なストレージモデルを選択し、将来の変化を予測することで、パフォーマンスを損なうことなく複雑なビジネスロジックをサポートするデータレイヤーを構築できる。鍵は、論理モデルを選択した環境の物理的機能と一致させることにある。
テーブル、ドキュメント、グラフのいずれを扱っても、エンティティを特定し、それらの関係を定義するという基本原則は変わらない。明確なERDは信頼性の高いソフトウェアアーキテクチャの基盤となり、ビジネス要件と技術的実装の間のギャップを埋める。