











ソフトウェアアーキテクチャの本質は、複雑さを管理することにある。システムが大きくなるにつれて、明確なメンタルモデルを持つことがエンジニアリングチームにとって不可欠になる。C4モデルは、抽象化の階層を通じてソフトウェアアーキテクチャを可視化する構造的なアプローチを提供する。この階層の中で、しばしば混乱を招く2つの特定のレベルが存在する:コンテナとコンポーネント。これら2つの違いを理解することは、効果的なコミュニケーション、スケーラブルな設計、保守可能なドキュメント作成にとって不可欠である。
このガイドでは、C4モデルの文脈の中でコンテナとコンポーネントの微細な違いを検討する。それぞれの定義、責任、境界、および広範なシステム設計における相互作用について検討する。これらの概念を明確にすることで、チームは本当に目的を果たす図を構築できるようになる:コミュニケーション。
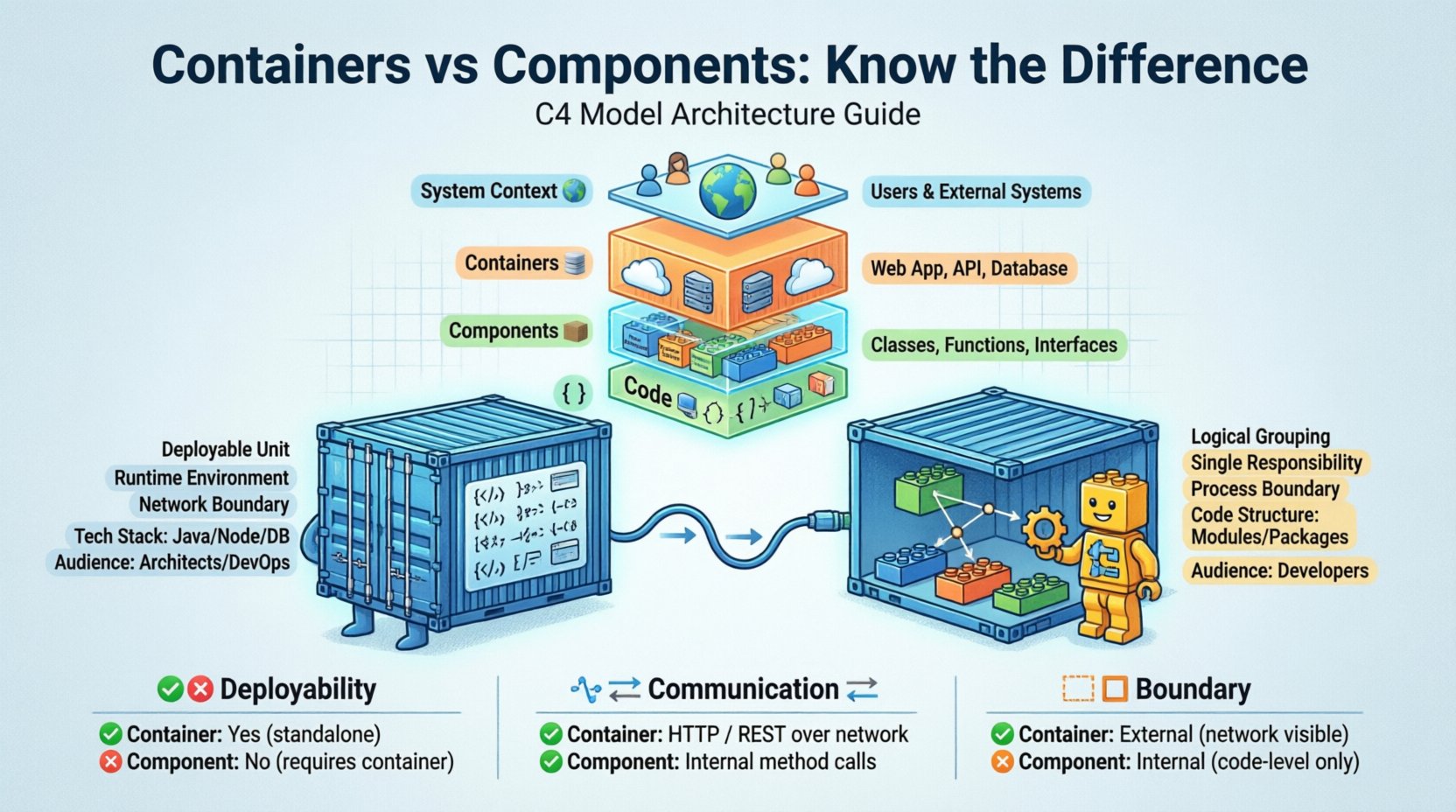
C4モデルの階層構造を理解する 📊
コンテナとコンポーネントの具体的な違いを検討する前に、それらがC4モデルの中でどのように位置づけられているかを理解することが必要である。このモデルは、アーキテクトや開発者がシステムの詳細を必要に応じて拡大・縮小できるように、階層的なアプローチを設計している。
- レベル1:システムコンテキスト 🌍 – システム全体を示し、ユーザーおよび他のシステムとの関係を表す。
- レベル2:コンテナ 📦 – システムの高レベルな構成要素を示す。Webアプリケーション、モバイルアプリ、データベースなど。
- レベル3:コンポーネント 🧱 – コンテナをより小さな、機能的に一貫した単位に分解する。
- レベル4:コード 💻 – コンポーネントの内部構造、クラスやインターフェースを含む詳細を示す。
レベル2からレベル3への移行が、コンテナとコンポーネントの違いが最も顕著になるポイントである。両者とも構造的要素を表すが、異なる対象者を対象とし、システムの構成に関する異なる問いに答える。
コンテナレベルの定義 📦
コンテナとは、デプロイ可能なソフトウェア単位である。コードが実行される明確なランタイム環境を表す。コンテナは、システムが実際に存在する物理的または論理的な境界である。サーバー、クラウドプラットフォーム、デバイスにデプロイするものである。
コンテナの特徴
- デプロイ可能: コンテナは、独立してインストールおよび実行可能な離散的な単位である。
- ランタイム環境: コードを実行するために必要なインフラストラクチャ(JVM、ブラウザ、OSなど)を提供する。
- テクノロジー・スタック: コンテナは、Javaアプリケーション、Node.jsサーバー、PostgreSQLデータベースなど、特定の技術選択を示すことが多い。
- 境界: コンテナ間の通信はネットワークを介して、または定義されたプロトコルを通じて行われる。
代表的な例
コンテナレベルでのモデル化では、以下の要素を特定する可能性がある:
- Webサーバーアプリケーション(例:ブラウザ上で動作するReactアプリ)。
- バックエンドマイクロサービス(例:Dockerコンテナ上で動作するAPI)。
- ユーザーの携帯電話にインストールされたモバイルアプリケーション。
- 永続データを格納するデータベースサーバー。
- 非同期通信を処理するメッセージキュー・ブローカー。
このレベルでの重要な問いは:システムは物理的または論理的にどのように分離されていますか?コンテナはデプロイの境界とテクノロジー・スタックの境界を定義する。
コンポーネントレベルの定義 🧱
コンテナに入ると、アーキテクチャがより細かくなる。コンポーネントはコンテナを構成する内部の構成要素である。コンポーネント単体ではデプロイ可能な単位ではない。むしろ、1つのデプロイ単位内での機能の論理的なグループ化である。
コンポーネントの特徴
- 論理的グループ化: コンポーネントは関連する機能をまとめる。これは物理的な境界ではなく、概念的な境界である。
- 単一の責任: 理想的には、コンポーネントは1つの特定のタスク、または密接に関連したタスクの集合を実行する。
- 内部構造: コンポーネントは内部の実装詳細を隠す。他のコンポーネントとは定義されたインターフェースを通じて通信する。
- デプロイ不可能: コンポーネントを独立してデプロイすることはできない。コンポーネントを保持するコンテナをデプロイする。
一般的な例
バックエンドコンテナ内には、次のようなコンポーネントが存在する可能性がある:
- ユーザーのログインを担当する認証モジュール。
- PDFドキュメントを生成するレポートエンジン。
- データインデックスを処理する検索インデックスマネージャー。
- パフォーマンス向上のための一時データを格納するキャッシュレイヤー。
このレベルでの重要な問いは:機能はデプロイ単位内でどのように整理されていますか? コンポーネントは内部構造と関心の分離を定義する。
コンテナとコンポーネントの主な違い 📋
両方の用語が構造を説明するため、混乱が生じることが多い。しかし、違いはデプロイ、技術、範囲にあります。以下の表は主な違いを示している。
| 特徴 | コンテナ(レベル2) | コンポーネント(レベル3) |
|---|---|---|
| デプロイ性 | はい、デプロイ可能なユニットです。 | いいえ、デプロイ可能なユニットの一部です。 |
| 通信 | ネットワーク経由(HTTP、TCPなど)。 | 同じプロセス内(メソッド呼び出し、内部API)。 |
| 技術 | 実行環境を定義する(例:JVM、ブラウザ)。 | コード構造を定義する(例:モジュール、パッケージ)。 |
| 境界 | システム境界(外部)。 | 内部境界(コンテナ内)。 |
| 対象者 | ステークホルダー、アーキテクト、DevOps。 | 開発者、エンジニア。 |
粒度と境界 🔍
粒度の違いがこの区別における最も実用的な側面です。コンテナは越えるコストが高い境界を表します。コンテナ間でデータを移動するにはネットワーク呼び出し、シリアライズ、潜在的な遅延や障害の処理が必要です。一方、コンポーネントは越えるコストが低い境界を表します。コンポーネント間を渡るデータは、同じプロセスのメモリ内で処理されます。
ネットワーク境界
コンテナを設計するとき、ネットワークトポロジーに関する意思決定を行っています。ネットワーク呼び出しが発生する場所を決めているのです。たとえばモノリスの場合、1つのコンテナになるかもしれません。それがマイクロサービスに分割されれば、複数のコンテナが存在することになります。これは重要なアーキテクチャ上の意思決定です。
プロセス境界
コンポーネントを設計するとき、コードの構成に関する意思決定を行っています。保守性を保つためにコードベースをどのように構造化するかを決めているのです。コンポーネントを使うことでロジックを分離できます。あるコンポーネントのロジックを変更しても、インターフェースが安定していれば、他のコンポーネントのロジックは壊れないはずです。
ドキュメント作成への影響 📝
正確な図を描くには、どのレベルで図を描いているかを把握することが必要です。コンテナとコンポーネントを同じ図に混在させると、曖昧さが生じます。デプロイトポロジーが不明瞭になり、内部ロジックが混乱する原因になります。
図の作成におけるベストプラクティス
- レベルを分けること:階層を明示的に示している場合を除き、1つのビューにコンテナとコンポーネントを混在させないでください。異なるレベルには別々の図を使用してください。
- 対象者に焦点を当てる:技術リーダーシップやインフラ構成計画にはコンテナ図を使用してください。開発チームやコードレビューにはコンポーネント図を使用してください。
- 明確にラベルを付ける:すべてのボックスがコンテナまたはコンポーネントであることを明確にラベル付けして、混乱を避けてください。
- インターフェースの定義: コンポーネントレベルではインターフェースに注目する。コンテナレベルではプロトコル(HTTP、gRPCなど)に注目する。
一般的な誤りと落とし穴 🚫
経験豊富なエンジニアですらこの違いを理解するのに苦労することがある。アーキテクチャをモデル化する際には、避けたい一般的な落とし穴を以下に示す。
1. すべてのモジュールをコンポーネントとして扱う
小さなモジュールをすべてコンポーネントとして分割したくなるが、コンポーネントは重要な機能単位を表すべきである。コンポーネントにクラスが1つしかなければ、おそらくコンポーネントとして小さすぎる。他のコンポーネントとまとめるべきである。
2. すべてのサービスをコンテナとして扱う
すべてのサービスが独自のコンテナを持つ必要があるわけではない。一部のアーキテクチャでは、複数のサービスを同じコンテナ内で実行することでオーバーヘッドを削減する。新しいコンテナを作成するかどうかは、論理的なグループ化だけでなく、デプロイのニーズによって決めるべきである。
3. ネットワークを無視する
コンテナを描く際、ネットワークトラフィックを表す線を忘れがちである。コンテナ間の通信はアーキテクチャにおいて最も重要な部分である。データがどのように流れているかを明確に示すようにしよう。
4. コンポーネント図を複雑にしすぎること
コンポーネント図はすぐにごちゃごちゃになってしまう。コンポーネントが多すぎると、おそらくモデル化のレベルが間違っている。図が読みにくくなった場合は、コンポーネントをより大きな論理単位にグループ化することを検討しよう。
進化するアーキテクチャ 🔄
アーキテクチャは静的ではない。時間とともに進化する。コンポーネントがコンテナに成長する場合もあれば、コンテナが複数のコンポーネントに縮小する場合もある。
モノリスからマイクロサービスへ
モノリスアーキテクチャでは、1つのコンテナと多数のコンポーネントを持つことがある。システムが成長すると、コンテナを分割する決定を下すこともある。かつて内部にあったコンポーネントが、外部のコンテナになることもある。この移行には、データ整合性やサービス契約が安定したまま保たれるように、慎重な計画が必要である。
マイクロサービスからサーバーレスへ
サーバーレスアーキテクチャでは、コンテナの概念が変わる。多数の小さな関数がコンテナとして機能するかもしれない。これらの関数内のコードを整理するには、コンポーネントレベルが依然として重要である。インフラ構造が変化しても、この区別は依然として有効である。
コミュニケーションと協働 🤝
C4モデルの主な価値は、コミュニケーションである。異なるステークホルダーはシステムに対して異なる視点を必要とする。コンテナとコンポーネントの違いは、この多様な視点を実現する助けとなる。
ビジネス関係者向け
ビジネス関係者は通常、システムの文脈に注目する。システムがビジネスエコシステムの中でどのように位置づけられているかを知りたい。コンテナを確認する必要はほとんどないが、確認する場合は、概要構造を理解するのに役立つ。
DevOpsおよびインフラチーム向け
これらのチームはコンテナに強く注目する。何をデプロイするか、どこにデプロイするか、どのように通信するかを把握する必要がある。コンテナ図は彼らの設計図である。
開発者向け
開発者はコンポーネントレベルで活動する。コードをどのように整理するか、テストをどう書くか、機能をどう実装するかを把握する必要がある。コンポーネント図は日々の作業をガイドする。
技術的実装上の考慮事項 🛠️
この違いを理解することは、コードの書き方にも影響する。リポジトリの構造や依存関係の管理にも影響を与える。
リポジトリ構造
各コンテナは通常、別々のリポジトリまたは明確に区別されたデプロイパイプラインに対応する。コンテナ内のコンポーネントは同じリポジトリとデプロイパイプラインを共有する。この分離により、コンテナごとに独立したバージョン管理とデプロイが可能になる。
依存関係の管理
コンテナ内のコンポーネント同士は、強い依存関係を持つことがあります。ライブラリやメモリを共有できます。一方、コンテナ同士は緩い依存関係を持つべきです。APIを介して通信します。この分離により、コンテナ間の緩い結合と、コンポーネント内の強い一貫性が促進されます。
価値の要約 💡
アーキテクチャの明確さは、より良いソフトウェアを生み出します。コンテナとコンポーネントを明確に区別することで、チームはドキュメントや設計における曖昧さを避けられます。C4モデルはフレームワークを提供しますが、重要なのは適切な抽象化レベルを適用するという Discipline です。
- コンテナ デプロイ境界と実行環境を定義する。
- コンポーネント その境界内の論理的構成と機能を定義する。
次に図を描く際には、一時停止して次のように尋ねてください:私はコードがどこで実行されるか、それともコードがどのように構成されているかを示しているだろうか? もし質問に答えられるなら、おそらくあなたはC4モデルの適切なレベルを使っているでしょう。
この区別はスケーラブルな成長をサポートします。システムが拡大するにつれて、図も進化します。サービスを分割する際にはより多くのコンテナを追加します。ロジックをリファクタリングする際にはより多くのコンポーネントを追加します。これらの概念を明確に区別することで、プロジェクトのライフサイクルを通じてドキュメントの正確性が保たれます。
最終的に求められているのは完璧さではなく、理解です。新しい開発者をオンボーディングする際や、大規模なリファクタリングを計画する際でも、コンテナとコンポーネントの明確な区別は時間を節約し、エラーを減らします。抽象的なアーキテクチャを、実行可能な計画に変換します。
これらの原則に従うことで、理解しやすく、保守しやすく、スケーラブルなシステムを構築できます。正確なモデル化に費やした努力は、長期的な生産性向上という恩恵をもたらします。