











災害復旧は、災害そのものについての話であることがほとんどない。それは、嵐が来る前に私たちが構築した構造の脆さについての話である。最近の事象では、データベーススキーマ設計における見過ごされがちな小さなミスが、全体の復旧プロセスのボトルネックとなった。原因は、本番環境のデータ依存関係を正確に反映できなかったエンティティ関係図(ERD)だった。45分で終わるはずの作業が、3時間にわたる手動による対応とデータの整合化作業にまで膨らんでしまった。 🕰️
この記事では、その失敗の技術的詳細、遅延を引き起こした具体的なスキーマの不整合、そして再発防止のために導入したプロセス上の変更について詳述する。データの整合性がコードそのものだけでなく、設計文書の正確さに大きく依存していることを検証する。
データの回復力におけるERDの重要な役割 🛡️
エンティティ関係図(ERD)は、デジタルインフラの設計図である。テーブル、フィールド、主キー、外部キーを明示し、データがどのように接続され、流れているかを定義する。災害が発生した際、これらの図は状態を復旧しようとするエンジニアにとって最初の参照資料となる。地図が間違っているならば、その旅は遅れる。
災害復旧の文脈において、ERDは主に3つの機能を果たす:
- 検証: 復旧されたスキーマがアプリケーションの期待される状態と一致していることを確認する。
- 依存関係のマッピング: どのテーブルが他のテーブルに依存しているかを特定し、復旧の順序を決定する。
- 制約の検証: インポートプロセス中に参照整合性ルールが正しく適用されていることを保証する。
ERDが実際のデータベース構成と一致しない場合、復旧スクリプトは検証の段階で失敗する。これによりエンジニアは作業を停止し、調査を行い、手動でスキーマを修正しなければならない。この手動作業が時間の損失の原因となる。 ⏳
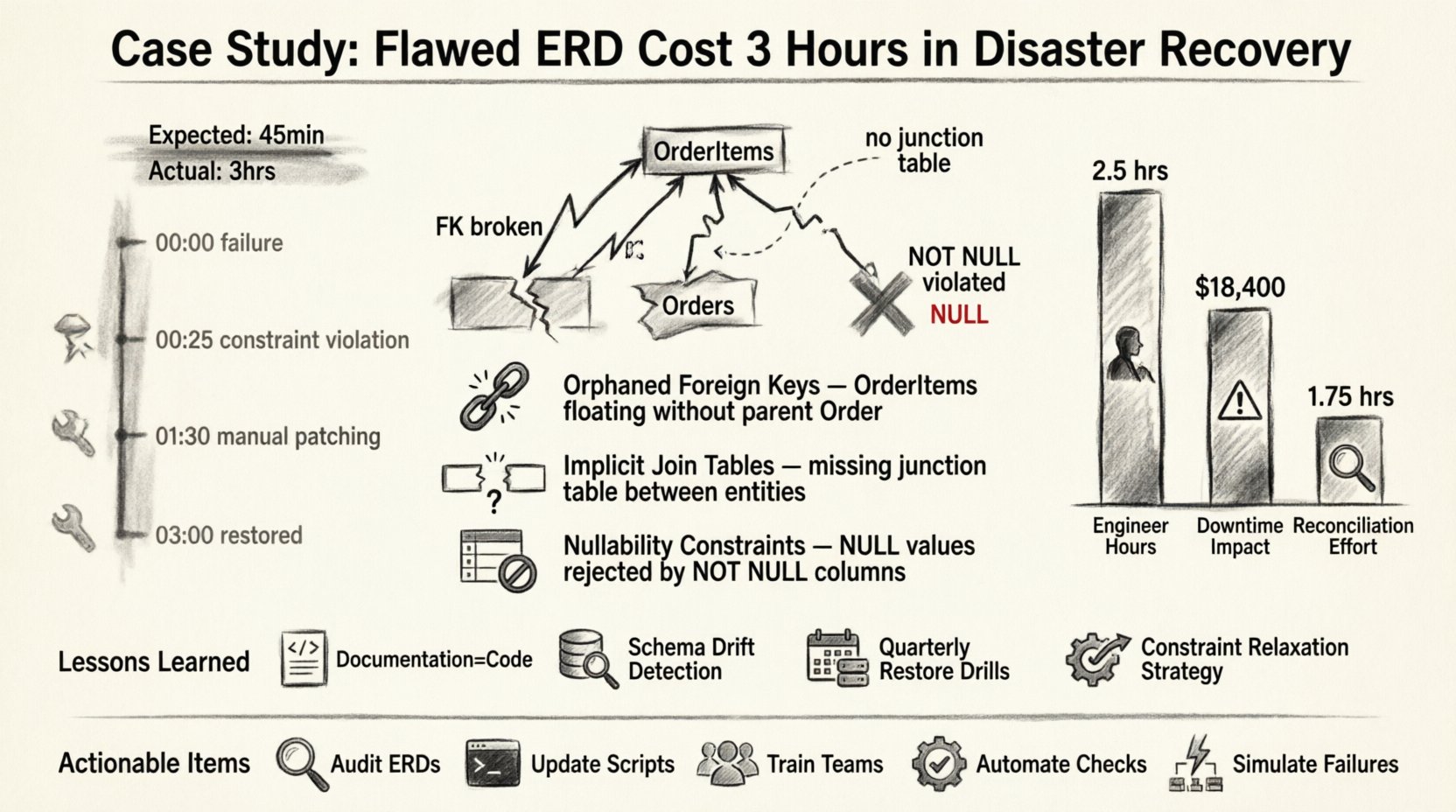
事象の概要:エラーのタイムライン 📉
この事象は、プライマリデータストアの障害から始まった。深刻なハードウェア障害が、セカンダリ環境へのフェイルオーバーを引き起こした。標準運用手順では、ドキュメントリポジトリに保存された静的ERDバージョンに依存する復旧スクリプトを開始するものだった。
以下が障害のタイムラインである:
- 00:00 – プライマリシステムの障害が検出された。アラートが発動し、インシデント対応が開始された。
- 00:05 – エンジニアリングチームが動員された。セカンダリ環境へのアクセスが許可された。
- 00:15 – ドキュメントに記載されたERDに基づいて、復旧スクリプトが開始された。
- 00:25 – スクリプトが停止。外部キー制約違反が検出された。
- 00:30 – 調査が開始された。ERDとライブスキーマの間に不一致が発見された。
- 01:30 – スキーマの修正と手動によるデータ整合化作業が開始された。
- 03:00 – システムが運用可能状態に復旧した。
3時間の遅延は、ネットワークの遅延やハードウェアの遅さによって引き起こされたものではありません。設計書と実際の物理的現実との間の論理的なギャップが原因でした。 🧩
特定されたスキーマの欠陥 🔍
ライブデータベースをERDと照合したところ、3つの重大な不一致を発見しました。これらは構文エラーではなく、システムが関係を強制しようとした際にのみ明らかになった論理的な省略でした。
1. 孤立した外部キー
ERDでは、注文 と 注文項目 の間に厳密な1対多の関係が描かれていました。しかし、実際のデータベースには、以前の移行で制約が強制されなかったため、注文項目 が対応する 注文 レコードが存在しないレガシーデータが含まれていました。ERDはこの孤立状態を考慮していませんでした。復元スクリプトが外部キーを再構築しようとした際、親レコードが欠落しているか、文書通りとは異なる方法で制約が強制されていたため、データベースはデータを拒否しました。
2. 暗黙の結合テーブル
多対多の関係はERDでは2つのテーブル間の直接的なリンクとして表現されていました。物理的な実装では、この関係は結合テーブルを介して処理されていました。復元ロジックは直接リンクを想定しており、誤ったカラムにデータを挿入しようとしました。これにより、型の不一致エラーが連鎖的に発生し、手動でのスキーマ変更が必要になりました。
3. NULL許容制約
ERDではいくつかのフィールドがオプション(NULL許容)であると示されていました。しかし、プロダクションスキーマは、データ品質の向上のために時間とともに非NULL値の強制を導入するように更新されていました。ERDはこの変更を反映していませんでした。復元中にスクリプトが非NULLカラムにNULL値を挿入しようとしたため、トランザクションが即座にロールバックされました。
これらの不一致は、技術文書における一般的な問題を浮き彫りにしています:ドキュメントのずれ。システムが進化するにつれて、ドキュメントが古くなり、誤った安心感を生み出します。
コスト分析:時間 vs. 正確性 💰
3時間の停止による財務的影響は大きいですが、評判への影響はそれ以上です。以下は、遅延中に消費されたリソースの内訳です。
| リソース | 消費時間 | 影響 |
|---|---|---|
| シニアエンジニア | 3時間 | 開発から優先度の高い作業がずれ込んだ |
| システム停止時間 | 3時間 | サービスの可用性が15%低下 |
| データの調整 | 1.5時間 | 手動での検証が必要 |
| ドキュメントの更新 | 0.5時間 | インシデント後の確認会議 |
表からわかるのは、コストの大部分は復元そのものではなく、修正復元の。ERDが正確であれば、復元は中断されることなく進行していたであろう。
技術的詳細:スクリプトが失敗した理由 🛠️
エラーの深刻さを理解するためには、復元スクリプトがデータベースエンジンとどのように連携したかを検証する必要がある。スクリプトは標準的な手順に従った:
- ERDの定義に基づいてテーブルを作成する。
- 制約を適用する(主キー、外部キー)。
- 整合性を確認する。
3. データを挿入する。
スクリプトがステップ2に到達した際、テーブルAをテーブルBに外部キー制約を設定しようと試みた。データベースエンジンはテーブルBに既存のデータをスキャンした。親キーが欠落しているため、制約に違反するレコードが見つかった。スクリプトは再実行可能で安全であるように設計されていたため、データを破損するよりも停止した。このセーフティ機能はデータ整合性には良いが、復旧スケジュールのブロッカーとなった。
スクリプトは、テーブルBのデータがクリーンアップされるまで進行できなかった。データのクリーンアップには以下の作業が必要である:
- 孤立したレコードの特定。
- 削除するか、仮想の親レコードを作成するかを決定する。
- 手動でクリーンアップを実行する。
- 制約の再作成。
この連鎖のすべてのステップが時間の遅延をもたらす。ERDは設計段階で孤立データの発生可能性を警告すべきだった。単なるスキーマの複製ではなく、データ移行戦略を講じるべきだったのだ。
教訓:スキーマライフサイクルの強化 🔄
事故の後、我々はスキーマ管理の実践を厳密に見直した。災害復旧のために静的文書に依存することは不十分であることに気づいた。動的でバージョン管理可能なスキーマ設計のアプローチが必要だった。
今回の事故から得た主な教訓は以下の通りである:
- ドキュメントはコードである: ERDは別個の成果物ではない。コードベースの一部である。アプリケーションロジックと同様に、バージョン管理とレビューのプロセスを経なければならない。
- スキーマのずれ検出: ライブデータベースのスキーマとバージョン管理されたERDを比較する自動化ツールを導入した。どの差異も即座にアラートを発動する。
- 復旧のテスト: 今後は、サンドボックス環境で四半期ごとに復旧訓練を実施する。これにより、ERDが復旧パスを正確に反映していることを保証する。
- 制約の緩和: 復旧スクリプトを調整し、初期データロード時に外部キー制約を一時的に無効化する。すべてのデータが検証された後、再び制約を適用する。
ERDの維持管理におけるベストプラクティス 📝
将来の遅延を防ぐため、エンティティ関係図(ERD)の維持管理に向けたベストプラクティスを採用した。これらのステップにより、システムのライフサイクルを通じて、設計図が常に有効であることが保証される。
1. 図面のバージョン管理
ERDファイルをソースコードと同じリポジトリに保存する。各リリースには対応する図面バージョンをタグ付けする。これにより、エンジニアはいつでもスキーマの正確な状態を取得できる。
2. 自動生成
可能な限り、手動で描くのではなく、データベーススキーマから直接ERDを生成する。これにより人的ミスの可能性を減らし、図面が常に現実と一致することを保証する。
3. 定期的な監査
四半期ごとにERDの監査をスケジュールする。図面を本番環境と比較し、標準的なデプロイパイプライン外で行われた変更をすべて文書化する。
4. データ移行のメモを含める
ERDはテーブルを表示するだけではなく、データの履歴を示すべきである。孤立データやレガシーなデータについてのメモを図面に追加する。これにより、復旧チームが異常を予期できるようにする。
5. スプリント計画時にレビューを行う
新しい機能にデータベースの変更が必要な場合、ERDは同じチケット内で更新されなければならない。対応する図面の更新が行われないままスキーマ変更をデプロイしてはならない。
技術的エラーにおける人的要因 🧑💻
図面やスクリプトを責めるのは簡単だが、根本的な原因はしばしばコミュニケーションのギャップだった。新しいフィールドを追加した開発者は図面を更新しなかった。コードをレビューしたエンジニアはスキーマドキュメントを確認しなかった。
技術プロセスの強さは、それを実行する人の質に依存する。デプロイ用のチェックリストを導入し、スキーマの検証ステップを含めた。すべてのデプロイには、データベース構造の変更を示すdiffレポートを含める必要がある。これにより、スキーマの変更が可視化される。
レジリエンスについての最終的な考察 🏗️
災害復旧は、私たちの反応の度合いではなく、準備の度合いを測る指標である。3時間の遅延は、より大きな問題の兆候だった。設計と実装の間の断絶である。エンティティ関係図をインフラの生き生きとした一部として扱うことで、復旧時間を大幅に短縮できる。
データの整合性は機能ではない。基盤である。その基盤が亀裂を生じれば、全体の構造が危機にさらされる。私たちの設計図が正確であることを保証することは、レジリエントなアーキテクチャへの第一歩である。ドキュメントに費やす時間は、コードに費やす時間と同等に投資すべきである。
実行可能な項目の概要 ✅
- 現在のERDの監査: すべてのドキュメントをライブスキーマとすぐに比較する。
- スクリプトの更新: ディザスタリカバリスクリプトを変更し、制約違反をスムーズに処理できるようにする。
- チームのトレーニング: すべてのエンジニアがスキーマドキュメントの重要性を理解していることを確認する。
- チェックの自動化: スキーマのずれを検出するツールを導入する。
- 障害のシミュレーション: ドキュメントの正確性を検証するために、定期的にディザスタリカバリ訓練を行う。
これらの実践を守ることで、将来のインシデントが数時間ではなく数分で解決されることを保証できます。正確性のコストは、修正のコストよりもはるかに低いです。