











Data modeling is often the invisible backbone of any software application. While the code running the business logic gets the spotlight, the schema beneath it dictates performance, scalability, and maintainability. For many junior engineers, the Entity Relationship Diagram (ERD) is a straightforward exercise in drawing boxes and connecting lines. However, this simplicity is deceptive. A poorly constructed ERD creates a debt that compounds over time, leading to complex queries, data integrity issues, and difficult migrations.
This guide explores the hidden complexity gap. It identifies where the disconnect occurs between theoretical knowledge and practical application. By understanding these pitfalls, developers can move beyond basic diagramming to true architectural thinking.
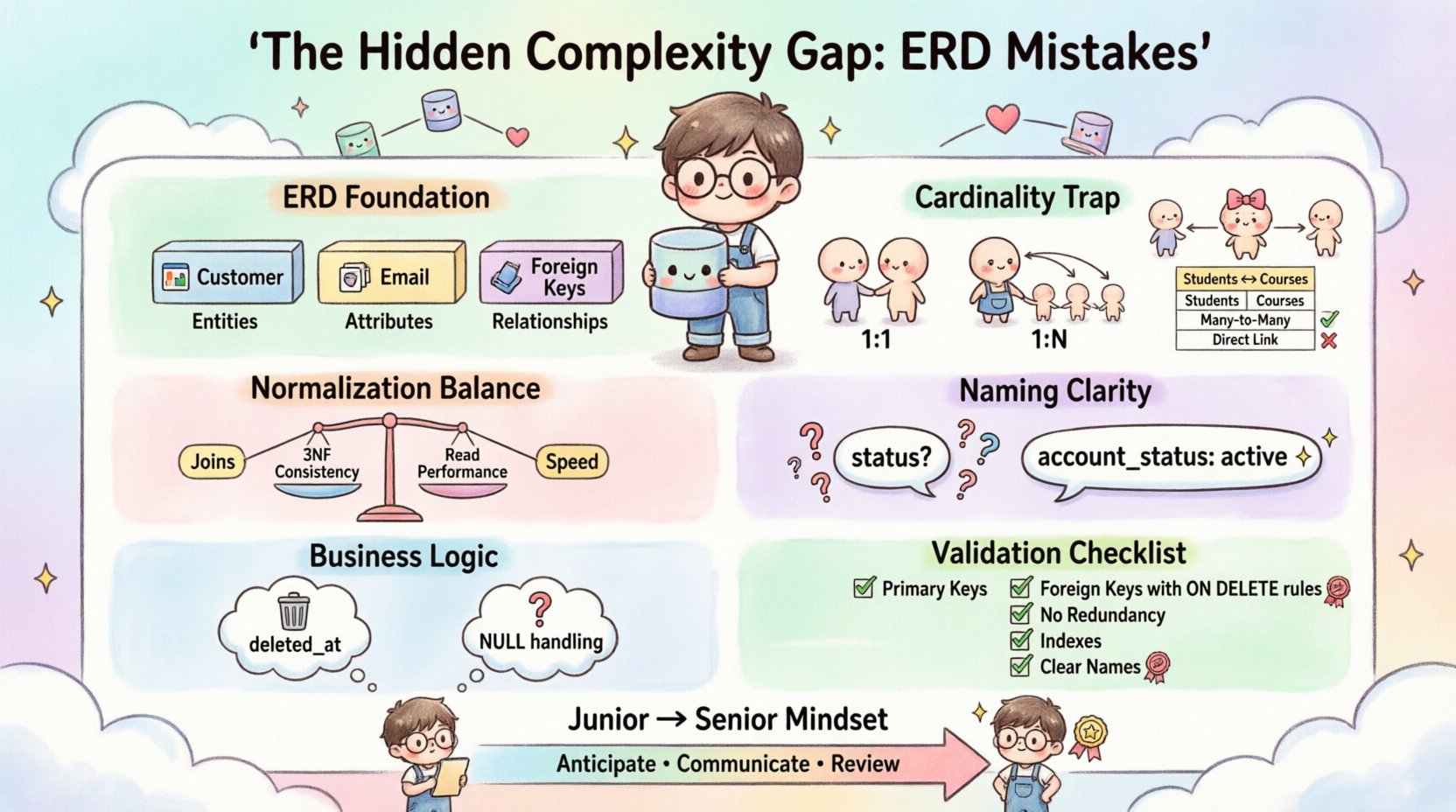
1. Understanding the Foundation of Data Modeling 🏗️
Before diving into errors, it is essential to establish what an ERD actually represents. It is not merely a drawing; it is a contract between the application and the storage layer. An ERD visualizes entities (tables), attributes (columns), and relationships (foreign keys).
When an engineer treats this as a static artifact created once and forgotten, they miss the dynamic nature of data. Data models evolve as business requirements shift. A junior engineer might focus on the immediate feature, such as storing a user’s name, while ignoring how that user interacts with other entities like orders, subscriptions, or logs.
- Entities: These represent real-world objects or concepts (e.g., Customer, Product, Invoice).
- Attributes: These are the properties that define the entity (e.g., Email, Price, Date).
- Relationships: These define how entities interact (e.g., One-to-Many, Many-to-Many).
A robust model accounts for future growth. It anticipates how a “Customer” might become a “User” or how a “Product” might need variations. The initial diagram should be flexible enough to accommodate these changes without requiring a complete rebuild.
2. The Cardinality Trap: Misinterpreting Relationships 🔄
Cardinality is the most common source of structural failure in database design. It defines the numerical relationship between instances of entities. Misunderstanding this leads to inefficient storage and complex join logic.
Common Cardinality Scenarios
Engineers often default to the most obvious relationship without considering edge cases. Consider the following scenarios where assumptions lead to errors:
- One-to-One (1:1): Often overused. If two entities have a 1:1 relationship, they should often be merged into a single table to reduce join overhead, unless strict security separation is required.
- One-to-Many (1:N): The most frequent relationship. A single Parent record relates to multiple Child records. The Foreign Key must reside on the Child side.
- Many-to-Many (M:N): This is where the complexity gap widens. A direct M:N relationship is not physically possible in a relational model without an intermediate table.
Table: Cardinality Implementation Errors
| Scenario | Incorrect Approach | Correct Approach |
|---|---|---|
| Students and Courses | Adding a “CourseID” column to the “Student” table | Creating a “Student_Course” junction table |
| Orders and Products | Embedding product details directly into the Order table | Linking via an OrderItems table |
| Employees and Departments | Allowing an employee to belong to multiple departments without a junction table | Separating the mapping relationship |
When engineers attempt to force a Many-to-Many relationship into a single table by repeating data, they introduce redundancy. If a product price changes, it must be updated in every order record where that product appears. This violates normalization principles and creates maintenance nightmares.
3. Normalization Myths and Reality Checks 📉
Normalization is a standard concept taught in academic settings. The goal is to reduce data redundancy and improve integrity. However, junior engineers often normalize to an extreme degree (up to 5NF) without considering performance trade-offs.
The Over-Normalization Trap
An over-normalized schema splits data into too many tables. While this ensures consistency, it forces the application to perform excessive joins. Every join adds computational cost. In high-traffic systems, this can become a bottleneck.
- 1NF (First Normal Form): Atomic values. No lists in a single cell.
- 2NF (Second Normal Form): No partial dependencies. All non-key attributes must depend on the whole primary key.
- 3NF (Third Normal Form): No transitive dependencies. Attributes should not depend on other non-key attributes.
A common mistake is assuming that 3NF is always the goal. In some cases, denormalization is a deliberate design choice. For example, storing a “Total Order Amount” directly on the Order table avoids calculating the sum of items every time the order is displayed. This trades write performance for read performance.
Table: Normalization vs. Denormalization
| Factor | Normalized (3NF) | Denormalized |
|---|---|---|
| Data Redundancy | Low | High |
| Write Speed | Fast | Slower |
| Read Speed | Slower (More Joins) | Fast |
| Data Integrity | High | Lower (Requires Logic) |
The decision to denormalize must be data-driven. It should not happen arbitrarily. Engineers need to profile query performance before merging tables. Blindly following normalization rules without context leads to systems that are consistent but sluggish.
4. Naming Conventions and Semantic Clarity 🏷️
Schema names are the vocabulary of the database. If the vocabulary is ambiguous, the system becomes unintelligible to future developers. This is a frequent issue where technical precision is sacrificed for brevity.
A field named status is dangerous. What does it mean? Is it an active account? A pending payment? A deleted record? Without context, the meaning is lost. Similarly, using plural names for tables (e.g., Users) versus singular (e.g., User) creates inconsistency.
- Consistency: If one table uses
snake_case, all must usesnake_case. - Descriptiveness: Use names that describe the data, not just the format. Avoid generic terms like
table1ordata. - Context: Include the entity name in the relationship key if ambiguity exists. Use
user_idinstead of justidwhen possible.
Consider the scenario of a system with multiple types of users: Admins, Customers, and Vendors. A single table named Users might contain a role column. This is a “God Table”. A better approach is separate tables or a clear inheritance strategy. This distinction becomes critical when permissions and data access rules diverge significantly between roles.
5. Ignoring Business Logic in Technical Design 🧠
The biggest gap between junior and senior engineers is the understanding of business logic. A junior engineer might build a schema that fits the current code requirements perfectly but fails when the business rules change.
The “Soft Delete” Misconception
Many developers simply add a deleted_at column to a table. This works for simple cases. However, if a user is deleted, should their associated logs be deleted? Should their financial records remain for audit compliance? The ERD should reflect these constraints through constraints and triggers, not just application code.
The “Null” Problem
Allowing NULL values is often a source of hidden complexity. In some cases, NULL is semantically different from an empty string or zero. If a field is optional, the ERD should clearly indicate this. However, relying on NULLs for logic control is discouraged.
- Referential Integrity: Foreign keys should ideally not be NULL unless the relationship is truly optional.
- Calculations: NULLs propagate through calculations, resulting in NULL results. This can break aggregation queries.
- Indexes: NULL handling in indexes varies by database engine, potentially impacting query performance.
6. The Maintenance Burden of Poor Design 🔧
Technical debt is not just about slow code; it is about structural rigidity. A poorly designed ERD makes changes painful. When a new requirement arrives, such as adding a “Billing Address” separate from a “Shipping Address,” the engineer must assess if the current schema supports this.
Migration Nightmares
Changing the schema of a production database with millions of records requires careful planning. If the ERD was not designed with migrations in mind, altering a column type or splitting a table can lock the system for hours. This downtime impacts revenue and user trust.
Strategies to mitigate this include:
- Version Control for Schema: Treat the database structure like application code.
- Backwards Compatibility: Add columns before removing them. Keep old columns until the migration is complete.
- Documentation: The ERD should be the source of truth. If it does not match the database, the database is wrong.
7. Practical Checklist for ERD Validation ✅
To ensure a robust design, engineers should run through a validation checklist before finalizing the diagram. This process helps catch logical errors before implementation begins.
Pre-Implementation Validation
| Check | Question | Pass Criteria |
|---|---|---|
| Primary Keys | Does every table have a unique identifier? | Yes, auto-increment or UUID |
| Foreign Keys | Are relationships explicitly defined? | Yes, with ON DELETE/UPDATE rules |
| Redundancy | Is any data stored in more than one place? | No, unless denormalization is intentional |
| Scalability | Can this handle 10x the current data volume? | Indexes exist on foreign keys |
| Readability | Can a new hire understand the flow in 5 minutes? | Clear naming conventions |
8. Tools vs. Concepts 🛠️
It is easy to rely on the features of a specific tool to solve design problems. However, the tool is secondary to the concept. Whether using a visual modeling tool or writing SQL scripts directly, the underlying logic remains the same.
Some engineers create diagrams that look perfect visually but are syntactically impossible in the target database. For instance, some tools allow circular dependencies in the visual layer, while the database engine will reject them. The focus must remain on the relational integrity rules rather than the drawing interface.
- Visual Consistency: Use standard symbols for relationships (Crow’s foot notation).
- Validation: Run the schema against a test database to verify constraints.
- Collaboration: Review the diagram with stakeholders who understand the business domain, not just technical peers.
9. Real-World Scenarios of Failure ⚠️
Understanding abstract concepts is one thing; seeing them fail in practice is another. Below are common scenarios where poor ERD design leads to tangible issues.
Scenario A: The Infinite Loop
A developer creates a relationship between Users and Teams where a user belongs to a team, and a team is led by a user. If the foreign key points to the same table without a clear root, circular reference errors occur during insertion. The ERD must clearly distinguish between “Member” and “Leader” relationships.
Scenario B: The Silent Data Loss
An Order table references a Product table. The ON DELETE constraint is set to CASCADE. When a product is removed from the catalog, all associated orders are deleted. This destroys historical sales data. The ERD should explicitly define the referential action as RESTRICT or SET NULL depending on the business need.
Scenario C: The Slow Search
A table is created with a name column. Engineers query this table frequently to find users by name. Without an index defined in the design phase, the database performs a full table scan. The ERD should indicate which columns are search-heavy and require indexing.
10. Evolving from Junior to Senior Mindset 🚀
The transition involves shifting focus from “Does it work?” to “Does it scale?” and “Is it maintainable?”.
- Anticipation: Predict future requirements based on industry trends.
- Communication: Translate technical constraints into business risks.
- Review: Never assume a diagram is correct without peer review.
Junior engineers often work in isolation. Senior engineers collaborate. The ERD is a communication tool. It bridges the gap between developers, product managers, and stakeholders. If the diagram is confusing, the expectations will be misaligned.
Final Thoughts on Data Integrity 🎯
Building a database schema is not a one-time task; it is an ongoing discipline. The complexity gap exists because the stakes are high. A mistake in the application code can be hot-fixed. A mistake in the data model often requires a migration, data cleanup, and downtime.
By adhering to strict modeling principles, understanding cardinality deeply, and prioritizing business logic over convenience, engineers can close the gap. The goal is not to create a perfect diagram, but to create a foundation that supports the evolution of the software. Data is the most valuable asset an application possesses. Protecting its structure is the responsibility of every engineer involved in the build process.
Take the time to review your diagrams. Question every relationship. Verify every constraint. The time invested in the design phase saves months of effort in the maintenance phase.