











Dans l’ingénierie logicielle moderne, comprendre comment les composants interagissent est essentiel pour la stabilité, la scalabilité et la maintenance. À mesure que les systèmes gagnent en complexité, la nécessité d’une documentation architecturale claire devient primordiale. Le modèle C4 fournit une approche structurée pour visualiser l’architecture logicielle, en passant du contexte de haut niveau aux détails au niveau du code. Parmi ces niveaux, le Vue des conteneursoccupe une position unique. Il sert de pont entre les capacités métiers et l’infrastructure sous-jacente.
Ce guide explore comment cartographier efficacement les dépendances d’infrastructure à l’aide de la vue des conteneurs C4. Nous aborderons les principes d’abstraction, les types spécifiques de dépendances à documenter, ainsi que les meilleures pratiques pour maintenir l’exactitude au fil du temps. En suivant ces stratégies, les équipes peuvent s’assurer que leurs diagrammes architecturaux restent pertinents et utiles pour la prise de décision.
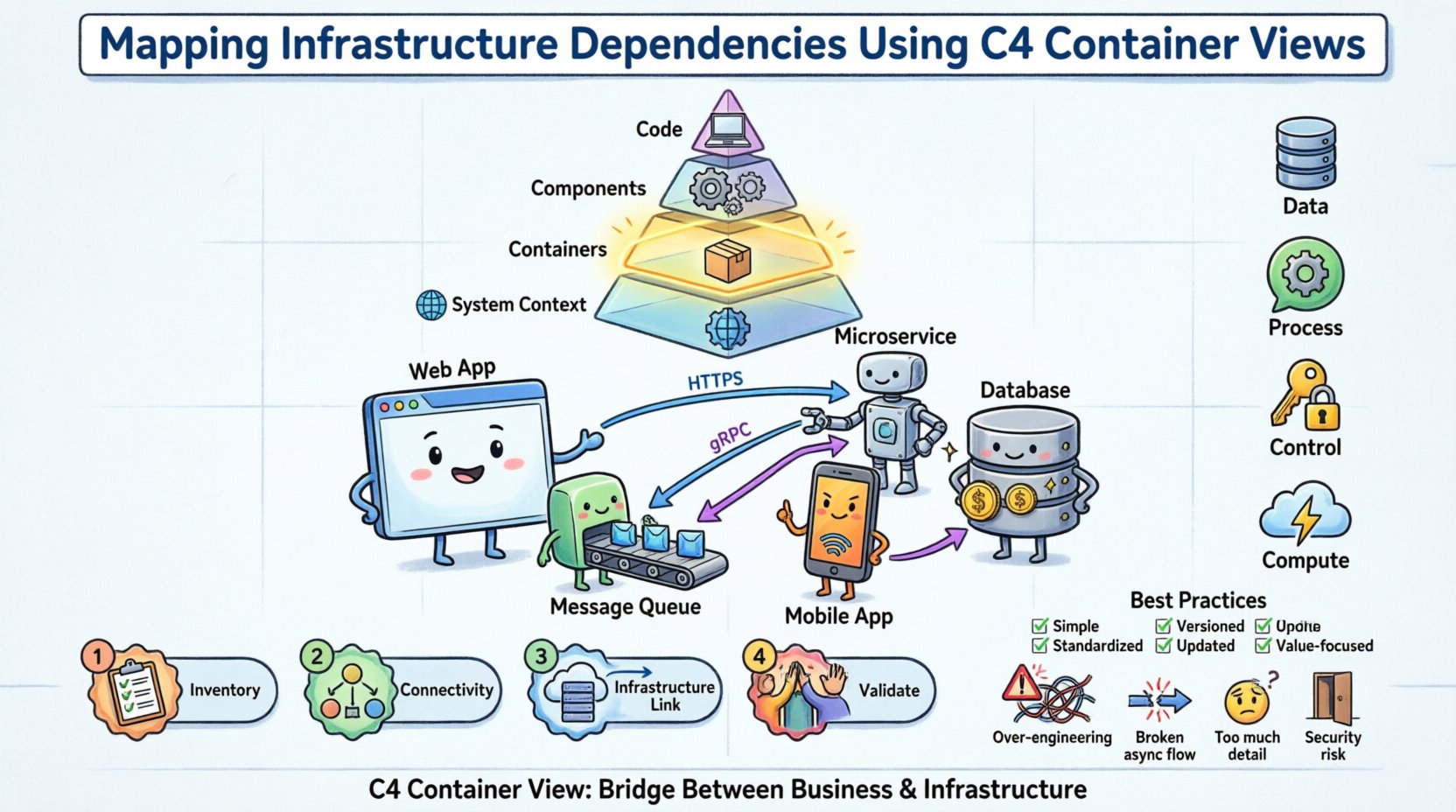
📚 Comprendre la hiérarchie du modèle C4
Le modèle C4 organise la documentation architecturale en quatre niveaux distincts. Chaque niveau s’adresse à un public spécifique et fournit un niveau de détail différent. Comprendre ces niveaux est une condition préalable à une utilisation correcte de la vue des conteneurs pour la cartographie de l’infrastructure.
-
Niveau 1 : Contexte du système 🌍
Définit le système dans son ensemble et ses relations avec les utilisateurs et les autres systèmes. Il s’agit du niveau d’abstraction le plus élevé. -
Niveau 2 : Conteneurs 📦
Décris les blocs de construction logiciels de haut niveau au sein du système. Un conteneur est une unité logicielle déployée, telle qu’une application web, une application mobile ou une base de données. -
Niveau 3 : Composants ⚙️
Découpe les conteneurs en groupes fonctionnels internes. Ce niveau se concentre sur la manière dont le code est structuré à l’intérieur. -
Niveau 4 : Code 💻
Détaille des classes, fonctions ou modules spécifiques. Cela est rarement inclus dans les discussions architecturales de haut niveau.
Lors de la cartographie des dépendances d’infrastructure, la vue des conteneurs (niveau 2) est la plus appropriée. Elle équilibre les détails techniques et la pertinence métier. Elle permet aux architectes de montrer comment les composants logiciels dépendent des ressources d’infrastructure sans s’enfoncer dans les configurations des serveurs ou les détails du code.
🔍 Explication de la vue des conteneurs
Un conteneur dans le modèle C4 représente une unité logicielle distincte et déployable. Les exemples courants incluent :
-
Une application web qui traite les requêtes des utilisateurs.
-
Un microservice qui gère une logique métier spécifique.
-
Un système de gestion de bases de données qui stocke des données persistantes.
-
Une application mobile en cours d’exécution sur un appareil utilisateur.
-
Un job de traitement par lots qui s’exécute selon un planning.
Le diagramme de la vue des conteneurs visualise ces conteneurs et les relations entre eux. Il répond à la question :« Comment les différentes pièces de logiciel fonctionnent-elles ensemble pour fournir une fonctionnalité ? »
Caractéristiques clés d’un conteneur
-
Déployable : Il peut être construit, testé et déployé de manière indépendante.
-
Exécutable : Il exécute du code pour effectuer des tâches.
-
Spécifique à la technologie : Il implique une pile technologique (par exemple, Java Spring Boot, Python Django, PostgreSQL).
-
Frontière : Il dispose d’une interface claire que d’autres conteneurs peuvent consommer.
Lors de la création de ces diagrammes, il est essentiel d’éviter de lister chaque instance de serveur individuelle. Au lieu de cela, regroupez les infrastructures similaires dans des conteneurs logiques. Par exemple, un conteneur « Serveur Web » peut représenter un cluster de serveurs derrière un équilibreur de charge, plutôt que de dessiner dix boîtes distinctes pour dix machines individuelles.
🌐 Cartographie des dépendances d’infrastructure
Le défi central de cette tâche consiste à relier l’architecture logicielle à l’infrastructure sur laquelle elle s’exécute. Bien que le modèle C4 soit principalement centré sur le logiciel, les dépendances d’infrastructure constituent la base sur laquelle reposent ces conteneurs logiciels. Une cartographie appropriée de ces dépendances garantit que les modifications de l’infrastructure n’entraînent pas la rupture de la fonctionnalité logicielle.
1. Distinction entre dépendances logiques et physiques
Une erreur courante consiste à confondre le conteneur logiciel avec le matériel physique. Un conteneur d’application web s’exécute sur un serveur, mais le diagramme doit principalement se concentrer sur la frontière logicielle.
|
Aspect |
Vue logique |
Vue physique |
|---|---|---|
|
Focus |
Fonctionnalités et interfaces |
Matériel et topologie du réseau |
|
Exemple |
Passerelle d’API |
Cluster Kubernetes / Instance EC2 |
|
Stabilité |
Élevée (changements rares) |
Faible (changements fréquents) |
|
Utilisation du diagramme |
Conception du système |
Planification du déploiement |
Dans le contexte de la vue Conteneur du modèle C4, nous cartographions le conteneur logiciel sur les ressources d’infrastructure nécessaires à son support. Nous ne remplaçons pas le conteneur par le serveur ; nous montrons la relation.
2. Types de dépendances d’infrastructure
Dans ce contexte, les dépendances se divisent en catégories spécifiques. Les identifier correctement aide à planifier la redondance, la sécurité et les performances.
-
Dépendances des données : Où les données sont-elles stockées ? Cela inclut les bases de données, le stockage d’objets et les systèmes de fichiers. Le conteneur doit avoir accès à la lecture et à l’écriture des données.
-
Dépendances des processus : Le conteneur doit-il communiquer avec un autre processus ? Cela inclut les files de messages, les couches de mise en cache et les travailleurs en arrière-plan.
-
Dépendances de contrôle : Le conteneur dépend-il de services d’authentification ou d’autorisation externes ? Cela inclut les fournisseurs d’identité et les clés d’API.
-
Dépendances de calcul : Le conteneur dépend-il de ressources de calcul externes ? Cela inclut les fonctions sans serveur ou les instances GPU.
3. Visualisation de la cartographie
Pour cartographier efficacement ces dépendances, le diagramme doit utiliser des conventions claires. Les flèches indiquent le sens de la communication. Les étiquettes décrivent le protocole ou le type de données. Les éléments d’infrastructure peuvent être représentés par des boîtes avec un style spécifique pour les distinguer des conteneurs d’applications.
Par exemple, un conteneur « Interface utilisateur » pourrait se connecter à un conteneur « API Backend ». Le conteneur « API Backend » se connecte ensuite à un conteneur « Base de données relationnelle » et à un conteneur « Cache ». En dessous de ceux-ci, vous pouvez indiquer que le conteneur de base de données est hébergé sur un niveau spécifique de l’infrastructure, tel qu’un service géré ou un cluster dédié.
🛠️ Méthodologie étape par étape pour la cartographie
Créer une carte précise des dépendances d’infrastructure nécessite une approche systématique. Respecter un processus garantit une cohérence entre différentes équipes et projets.
Étape 1 : Inventaire des conteneurs existants
Commencez par énumérer tous les conteneurs logiciels à l’intérieur de la frontière du système. Cette liste doit inclure :
-
Applications web
-
Services API
-
Instances de base de données
-
Files de messages
-
Intégrations avec des systèmes externes
Ne pas inclure chaque microservice si le système est vaste. Concentrez-vous sur les flux de valeur principaux. Regroupez les services connexes lorsque cela est pertinent pour maintenir la clarté.
Étape 2 : Identifier les points de connectivité
Pour chaque conteneur, identifiez la manière dont il se connecte aux autres. Posez les questions suivantes :
-
Quels protocoles sont utilisés (HTTP, gRPC, TCP) ?
-
Quelles données sont échangées ?
-
La connexion est-elle synchrone ou asynchrone ?
-
Y a-t-il des exigences de sécurité (TLS, authentification) ?
Cette étape permet de définir clairement les dépendances. Elle va au-delà de « il se connecte à » pour préciser « il se connecte via HTTPS avec une authentification JWT ».
Étape 3 : Lier aux ressources d’infrastructure
Maintenant, mappez les conteneurs à l’infrastructure. Cela ne signifie pas dessiner les serveurs physiques. En revanche, annoter le schéma pour montrer le contexte de l’infrastructure.
-
Environnement d’hébergement :Le conteneur fonctionne-t-il sur site, dans le cloud ou en mode hybride ?
-
Segmentation du réseau :Le conteneur se trouve-t-il dans un sous-réseau public ou dans un VLAN privé ?
-
Mise à l’échelle :Le conteneur nécessite-t-il une mise à l’échelle automatique ?
-
Persistance :Les données sont-elles stockées en mémoire, sur disque ou dans un magasin d’objets cloud ?
Utilisez des notes ou des annotations latérales pour transmettre ces informations sans encombrer le schéma principal. Cela maintient une hiérarchie visuelle claire.
Étape 4 : Valider avec les parties prenantes
Une fois le schéma esquissé, faites-le passer en revue avec les équipes concernées. Cela inclut les équipes DevOps, Sécurité et les chefs de développement.
-
DevOps :Confirmez que les hypothèses sur l’infrastructure sont exactes.
-
Sécurité :Vérifiez que les flux de données sensibles sont correctement identifiés et protégés.
-
Développement :Assurez-vous que le flux logique correspond à l’implémentation réelle.
Cette étape de validation est cruciale. Elle permet de détecter les écarts entre l’architecture documentée et le déploiement réel.
✅ Meilleures pratiques pour la documentation
La maintenance des schémas architecturaux est souvent plus difficile que leur création. Pour assurer une valeur à long terme, suivez ces meilleures pratiques.
|
Pratique |
Pourquoi cela importe |
Comment l’implémenter |
|---|---|---|
|
Gardez-le simple |
Les schémas complexes sont ignorés. |
Limitez les conteneurs à 10 à 15 par schéma. Utilisez des niveaux de zoom. |
|
Standardisez la notation |
Assure que tout le monde comprend les symboles. |
Utilisez des formes cohérentes pour les bases de données, les API et les utilisateurs. |
|
Contrôle de version |
Suivi des modifications au fil du temps. |
Stockez les fichiers sources du diagramme dans un dépôt de code. |
|
Mise à jour automatique lors des modifications |
Évite les informations obsolètes. |
Liez les mises à jour du diagramme aux demandes de tirage de code. |
|
Concentrez-vous sur la valeur |
Évite de documenter l’évidence. |
Documentez uniquement les dépendances qui ont un impact sur le risque ou le coût. |
⚠️ Pièges courants à éviter
Même les architectes expérimentés peuvent tomber dans des pièges lors de la cartographie des dépendances. Être conscient de ces problèmes courants aide à produire une documentation de meilleure qualité.
1. Surconcevoir le diagramme
Essayer de montrer chaque dépendance individuelle peut rendre le diagramme illisible. Si un conteneur se connecte à un service de journalisation, cela peut être considéré comme une infrastructure supposée et ne pas justifier une boîte dédiée, sauf si la stratégie de journalisation est complexe. Concentrez-vous sur les chemins critiques qui affectent la stabilité du système.
2. Ignorer les flux asynchrones
De nombreux systèmes modernes reposent sur des architectures pilotées par des événements. Si vous ne dessinez que des flèches de requête-réponse, vous manquez le flux des événements. Utilisez des styles de lignes ou des icônes différents pour représenter les messages asynchrones, les files d’attente et les flux.
3. Confondre les utilisateurs avec des détails d’infrastructure
La vue des conteneurs concerne le logiciel. Si vous dessinez des commutateurs réseau physiques, des routeurs ou des pare-feu, vous passez à la vue de déploiement. Gardez la cartographie de l’infrastructure au niveau élevé. Mentionnez le type d’infrastructure, pas les adresses IP spécifiques ou les modèles matériels.
4. Négliger les frontières de sécurité
Les dépendances croisent souvent des zones de sécurité. Omettre de préciser où l’authentification ou le chiffrement est requis peut entraîner des vulnérabilités de sécurité. Marquez clairement les connexions qui traversent des réseaux publics ou nécessitent des contrôles d’accès stricts.
🔄 Maintenance et évolution
L’architecture n’est pas statique. Les systèmes évoluent, les dépendances changent, et l’infrastructure évolue. Un diagramme exact il y a six mois peut être obsolète aujourd’hui. Pour maintenir l’intégrité de la vue C4 des conteneurs, adoptez une stratégie de documentation vivante.
Automatisez autant que possible
Utilisez des outils capables de générer des diagrammes à partir du code ou des fichiers de configuration. Cela réduit l’effort manuel nécessaire pour mettre à jour la documentation. Si le code d’infrastructure change, le diagramme peut potentiellement se mettre à jour automatiquement.
Revue régulière
Programmez des revues périodiques des diagrammes d’architecture. Pendant ces revues, vérifiez que le diagramme correspond à l’état actuel du système. Posez-vous les questions suivantes :
-
De nouveaux conteneurs ont-ils été ajoutés ?
-
Certains conteneurs ont-ils été dépréciés ou supprimés ?
-
Les protocoles de communication ont-ils changé ?
-
La cartographie de l’infrastructure est-elle toujours exacte ?
Intégrez avec CI/CD
Pensez à intégrer la validation des diagrammes dans le pipeline d’intégration continue. Si une demande de fusion modifie de manière significative l’architecture, déclenchez un contrôle pour vous assurer que la documentation est mise à jour. Cela crée une culture où la documentation est traitée comme du code.
📝 Liste de contrôle pour le mapping des dépendances
Avant de finaliser votre diagramme de vue Container C4, passez en revue cette liste de contrôle pour vous assurer de sa complétude.
-
☐ Tous les principaux conteneurs logiciels sont-ils inclus ?
-
☐ La direction du flux de données est-elle clairement indiquée ?
-
☐ Les protocoles de communication sont-ils étiquetés ?
-
☐ Le contexte d’infrastructure est-il annoté (par exemple, Cloud, On-Prem) ?
-
☐ Les frontières de sécurité et les méthodes d’authentification sont-elles notées ?
-
☐ Le diagramme est-il dépourvu de brouillage technique inutile ?
-
☐ Les diagrammes ont-ils été revus par l’équipe opérationnelle ?
-
☐ Le diagramme est-il stocké dans un emplacement central et accessible ?
🔗 Intégration avec d’autres vues
La vue Container n’existe pas en isolation. Elle est connectée à la vue Contexte Système et à la vue Composants. Lors du mapping des dépendances d’infrastructure, assurez-vous de la cohérence entre ces vues.
-
Contexte Système : Assurez-vous que les systèmes externes affichés ici correspondent aux dépendances de la vue Container.
-
Vue Composants : Assurez-vous que les composants internes sont logiquement associés aux conteneurs dans lesquels ils résident.
Cette alignement évite les contradictions. Par exemple, si un conteneur est marqué comme « Cloud uniquement » dans la vue Container, le contexte système ne devrait pas le montrer en cours d’exécution sur un serveur local. La cohérence renforce la confiance dans la documentation.
💡 Réflexions finales
Cartographier les dépendances d’infrastructure à l’aide de la vue Container C4 est une compétence essentielle pour les dirigeants techniques et les architectes. Elle apporte une clarté sur la manière dont le logiciel interagit avec l’environnement qui le soutient. En suivant une approche structurée, en évitant les pièges courants et en maintenant les diagrammes au fil du temps, les équipes peuvent créer une carte vivante de leur architecture.
Cette clarté soutient une meilleure prise de décision concernant la scalabilité, la sécurité et les coûts. Elle réduit le risque de pannes causées par des dépendances non documentées. En fin de compte, l’objectif n’est pas de créer des diagrammes parfaits, mais des diagrammes utiles qui aident l’équipe à comprendre le système qu’elle construit et entretient.
Commencez par les bases. Identifiez vos conteneurs. Cartographiez leurs connexions. Annotez le contexte d’infrastructure. Revoyez et affinez. Ce processus itératif mènera à une documentation architecturale solide qui résistera à l’épreuve du temps.