











Introduction
Dans le génie logiciel moderne, les systèmes n’existent rarement sous forme d’entités monolithiques. Ils sont composés de multiples services, processus et unités de stockage qui interagissent au-delà des frontières réseau. Comprendre comment les informations circulent entre ces unités distinctes est essentiel pour maintenir l’intégrité du système, diagnostiquer les défaillances et prévoir l’évolutivité.
Ce guide complet explore le processus de cartographie et de visualisation du flux de données au sein des architectures distribuées, en utilisant spécifiquement le modèle C4 comme cadre structurel. Sans documentation claire, les systèmes distribués deviennent rapidement des boîtes noires. Les ingénieurs peinent à suivre les requêtes, à identifier les goulets d’étranglement ou à comprendre l’impact des modifications. Visualiser le déplacement des données apporte de la clarté, transformant la logique abstraite en diagrammes concrets que les parties prenantes peuvent interpréter.
Avec l’apparition d’outils alimentés par l’IA tels que C4 Studio de Visual Paradigm, la création et la maintenance de ces diagrammes architecturaux essentiels sont devenues plus accessibles et efficaces que jamais. Ce guide vous accompagnera à travers les fondements théoriques et les stratégies pratiques d’implémentation pour une visualisation efficace des systèmes distribués.
Le paysage architectural 🌍
Les systèmes distribués introduisent une complexité que les applications monolithiques n’ont pas à affronter. Lorsqu’un seul processus gère toute la logique, le flux de données est interne et linéaire. Lorsqu’il est question de plusieurs conteneurs ou services, les données traversent les réseaux, passent par des pare-feu et franchissent des frontières de confiance. Chaque saut introduit une latence et des points potentiels de défaillance.
Le besoin de standardisation
Visualiser ce paysage nécessite une approche standardisée. Les diagrammes improvisés mènent souvent à une incohérence. Un ingénieur pourrait représenter une base de données sous forme de cylindre, tandis qu’un autre utilise une boîte. La standardisation garantit que, lorsqu’un diagramme est consulté, son sens est immédiatement compris. Le modèle C4 assure cette standardisation en définissant des niveaux spécifiques d’abstraction.
Défis clés de la visualisation distribuée
Lors de la cartographie des systèmes distribués, les ingénieurs doivent relever plusieurs défis critiques :
-
Latence réseau : Visualiser où les données attendent dans les files d’attente ou les réseaux
-
Consistance des données : Montrer comment l’état est synchronisé entre les nœuds
-
Domaines de défaillance : Identifier ce qui se produit si un conteneur cesse de répondre
-
Frontières de sécurité : Indiquer où le chiffrement des données ou l’authentification est requis
Ces défis exigent une réflexion attentive pendant le processus de création de diagrammes afin de garantir que la visualisation représente fidèlement le comportement du système dans diverses conditions.
Comprendre le modèle C4 📐
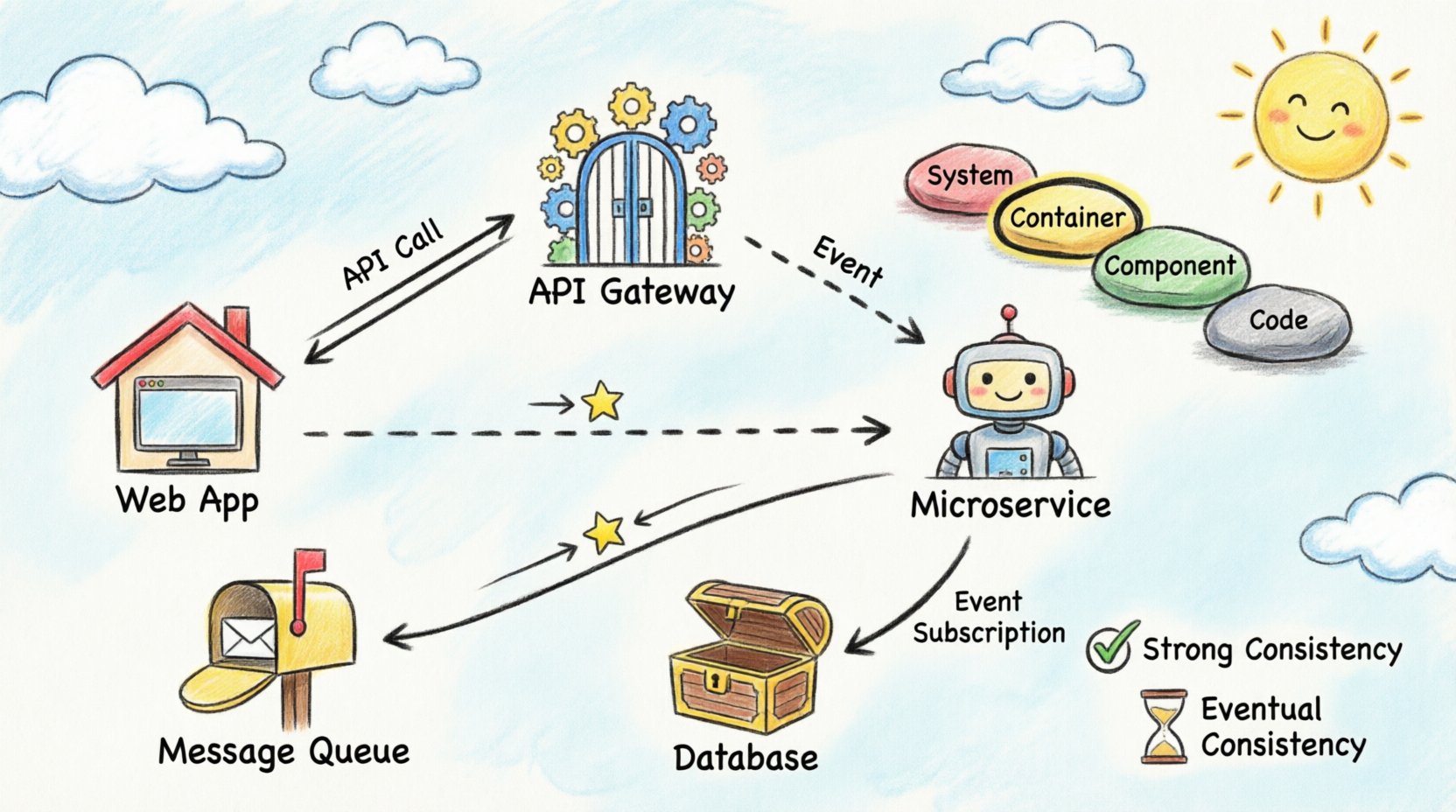
Le modèle C4 est une hiérarchie de diagrammes utilisée pour décrire l’architecture logicielle. Il se compose de quatre niveaux, chacun servant un public et un objectif différents. Pour la visualisation du flux de données entre conteneurs, les niveaux Container et Component sont les plus pertinents.
Niveau 1 : Contexte du système
Cette vue de haut niveau montre le système sous forme d’un bloc unique et ses interactions avec les utilisateurs et systèmes externes. Elle répond à la question :« Qu’est-ce que ce système fait, et qui l’utilise ? »
Bien qu’utile pour fournir un contexte aux parties prenantes non techniques, ce niveau ne montre pas le flux de données interne entre les conteneurs. Il convient idéalement aux synthèses exécutives et aux aperçus de projet.
Niveau 2 : Conteneurs
C’est lecœur de la visualisation distribuée. Un conteneur représente une unité de déploiement distincte. Des exemples incluent :
-
Applications web
-
Applications mobiles
-
Microservices
-
Bases de données
Ce niveau illustre le flux de données entre ces unités. C’est l’endroit idéal pour cartographier :
-
Appels d’API
-
Files de messages
-
Connexions directes à la base de données
-
Communication service à service
Niveau 3 : Composants
Dans un conteneur, les composants représentent des parties distinctes du logiciel. Ce niveau approfondit la logique, en montrant :
-
Interactions internes entre classes
-
Dépendances entre modules
-
Relations entre composants
Bien que cela soit important pour les équipes de développement, ce niveau est souvent trop détaillé pour une analyse de flux de données de haut niveau et des revues architecturales.
Niveau 4 : Code
Ce niveau correspond à des classes et des méthodes spécifiques. Il est généralement inutile pour la documentation du flux architectural et convient mieux aux documents de référence spécifiques aux développeurs et aux outils de navigation de code.
Définition des limites des conteneurs 🚧
Avant de dessiner les lignes de flux de données, vous devez définir ce qui constitue un conteneur. Un conteneur est ununité déployableavec un cycle de vie indépendant des autres conteneurs. Il peut fonctionner sur le même serveur physique ou être réparti sur différentes régions.
Types courants de conteneurs
| Type de conteneur | Description | Exemples |
|---|---|---|
| Applications web | Interfaces frontend accessibles via les navigateurs | Applications React, SPAs Angular |
| Microservices | Services backend gérant une logique métier spécifique | Service de commande, service utilisateur |
| Passerelles API | Points d’entrée qui redirigent le trafic vers les services internes | Kong, passerelle API AWS |
| Magasins de données | Bases de données, caches ou systèmes de fichiers | PostgreSQL, Redis, S3 |
| Traitements par lots | Travaux planifiés qui traitent les données de manière asynchrone | Travaux ETL, générateurs de rapports |
Considérations sur la stratégie de déploiement
Lors de la définition des limites, prenez en compte la stratégie de déploiement :
-
Déploiement couplé :Si deux services sont toujours déployés ensemble et partagent la mémoire, ils peuvent faire partie d’un seul conteneur
-
Mise à l’échelle indépendante :Si les services peuvent être mis à l’échelle indépendamment, ils devraient être des conteneurs séparés
Cette décision influence directement la manière dont le flux de données est visualisé et compris. Des limites claires évitent toute confusion concernant les responsabilités des services et leurs caractéristiques de déploiement.
Cartographie des modèles de flux de données 📡
Le flux de données n’est pas simplement une ligne reliant deux boîtes. Il représente un schéma d’interaction spécifique. Comprendre ce schéma est crucial pour une visualisation précise.
Schémas courants de flux de données
| Schéma | Direction | Visibilité | Cas d’utilisation |
|---|---|---|---|
| Demande/réponse synchrone | Bidirectionnel (Client → Serveur → Client) | Immédiate | Appels API, soumissions de formulaires |
| Communication asynchrone type « feu et oublie » | Unidirectionnel (Client → Serveur) | Différé | Journalisation, événements d’analyse |
| Traitement basé sur le pull | Unidirectionnel (Worker ← File d’attente) | Sur demande | Travaux en arrière-plan, ingestion de données |
| Abonnement à un événement | Unidirectionnel (Émetteur → Abonné) | Déclenché par un événement | Notifications, changements d’état |
Communication synchrone
Dans les flux synchrones, l’expéditeur attend une réponse. C’est courant dans les interactions API.
Lignes directrices de visualisation :
-
Utilisez des lignes pleines avec des flèches
-
Indiquez les deux sens, demande et réponse
-
Indiquez le protocole utilisé (HTTP, gRPC, GraphQL)
-
Cela aide les ingénieurs à comprendre la nature bloquante de l’interaction
Exemple : Une application web effectuant un appel API REST à un service utilisateur afficherait une flèche bidirectionnelle pleine étiquetée « HTTPS/JSON ».
Communication asynchrone
Les flux asynchrones déconnectent l’expéditeur du destinataire. L’expéditeur place un message dans une file d’attente et continue. Le destinataire traite le message plus tard.
Lignes directrices de visualisation :
-
Utilisez des lignes pointillées ou des icônes distinctes
-
Représentez explicitement le broker de messages
-
Indiquez le nom de la file d’attente pour distinguer les différents flux de données
-
Montrez clairement la direction à l’aide de flèches unidirectionnelles
Exemple :Un service de commande publiant dans une file d’attente de messages afficherait une flèche pointillée vers une icône de file d’attente étiquetée « orders.events ».
Gestion de la synchronisation et de la cohérence ⚖️
L’un des aspects les plus difficiles du flux de données distribué est la gestion de l’état. Lorsqu’un données sont écrites dans un conteneur, celle-ci se reflètent-elles immédiatement dans un autre ? La visualisation doit capturer ces exigences de cohérence.
Cohérence forte
Certains systèmes exigent que tous les nœuds voient les mêmes données au même moment. Cela implique souvent :
-
Une seule source de vérité
-
Réplication synchrone
-
Coordination des transactions
Notation du diagramme :
-
Marquez les connexions avec des étiquettes indiquant« Cohérence forte »ou« ACID »
-
Cela alerte les parties prenantes que la panne dans une partie du système peut affecter les autres
-
Utilisez des lignes solides et marquées pour indiquer les exigences critiques de cohérence
Cohérence éventuelle
De nombreux systèmes distribués privilégient la disponibilité par rapport à la cohérence immédiate. Les données peuvent prendre des secondes ou des minutes pour se propager.
Notation du diagramme :
-
Ajoutez unindicateur de tempsouétiquette « Sync »avec une notation de délai
-
Exemple : « Sync < 5min » ou « Éventuelle (Δt ≈ 30s) »
-
Cela gère les attentes concernant le moment où les utilisateurs verront les informations mises à jour
Conteneurs sans état vs. conteneurs avec état
Comprendre les caractéristiques d’état des conteneurs est essentiel pour une cartographie précise du flux de données :
Conteneurs sans état :
-
Ne pas stocker de données localement
-
Compter sur des bases de données externes ou des mémoires tampon
-
Peuvent être mis à l’échelle horizontalement sans migration de données
-
Les lignes de flux doivent pointer vers un stockage externe
Conteneurs avec état :
-
Stockent les données dans leur propre stockage
-
Exigent une réflexion soigneuse en matière de mise à l’échelle et de basculement
-
Les lignes de flux doivent pointer vers des icônes de stockage à l’intérieur ou attachées au conteneur
Lors de la cartographie du flux, assurez-vous que le stockage externe est clairement séparé du conteneur. Si un conteneur stocke des données, la ligne de flux doit pointer vers une icône de stockage à l’intérieur ou attachée à ce conteneur.
Stratégies de maintenance de la documentation 📝
Un schéma n’est utile que s’il estprécis. Au fil du temps, le code évolue, de nouveaux services sont ajoutés et les services obsolètes sont supprimés. Les schémas statiques deviennent rapidement obsolètes. Une stratégie de maintenance est nécessaire.
Meilleures pratiques pour maintenir la documentation à jour
1. Génération automatisée
Lorsque c’est possible, générez les schémas à partir de :
-
Annotations de code
-
Fichiers de configuration
-
Définitions d’infrastructure en tant que code
Avantages :
-
Réduit les efforts manuels
-
Empêche le décalage entre le code et la documentation
-
Assure la cohérence dans l’ensemble du système
Outils à considérer :
-
Structurizr
-
PlantUML
-
Mermaid.js avec intégration CI/CD
2. Cycles de revue
Inclure les mises à jour des schémas dans lesdéfinition de fait pour les demandes de fusion :
-
Si une interface de service change, le schéma doit changer
-
Exiger une revue du schéma en parallèle avec la revue du code
-
Attribuer la responsabilité de la documentation à des membres spécifiques de l’équipe
3. Gestion des versions
Traiter les schémas d’architecture comme du code :
-
Les stocker dans des systèmes de gestion de versions (Git)
-
Suivre l’historique et permettre le retour arrière si un changement est incorrect
-
Utiliser des messages de validation significatifs pour les modifications de schéma
-
Marquer les versions de libération avec les versions correspondantes du schéma
4. Normes d’outils
Utiliser une pile d’outils cohérente à travers les équipes :
-
Éviter de passer d’une plateforme de création de schémas à une autre
-
Établir des normes à l’échelle de l’organisation
-
Fournir de la formation et des modèles
-
Créer un référentiel central pour tous les schémas d’architecture
Péchés courants et comment les éviter 🛑
Même avec une approche structurée, des erreurs peuvent survenir au cours du processus de visualisation. Être conscient des erreurs courantes aide à maintenir une documentation de haute qualité.
Piège 1 : Sur-abstraction
Le problème :
Il est tentant de simplifier les schémas trop. Si vous regroupez dix services dans une seule boîte intitulée « Backend », vous perdez la capacité de suivre des chemins de données spécifiques.
La solution :
-
Maintenir le niveau de granularité du conteneur
-
Ne pas fusionner des unités de déploiement distinctes sauf si elles partagent exactement le même cycle de vie
-
Demandez : « Peut-on le déployer de manière indépendante ? » Si oui, il mérite sa propre boîte
Piège 2 : Ignorer les chemins d’échec
Le problème :
La plupart des schémas montrent le chemin idéal où tout fonctionne.
La solution :
Une visualisation robuste indique également les modes de défaillance :
-
Où va le flux si un service expiré ?
-
Y a-t-il un service de secours ?
-
Y a-t-il une file d’attente de lettres mortes ?
-
Ajoutez ces chemins pour transformer le diagramme en outil de planification de résilience
Suggestions de notation :
-
Utilisez des couleurs différentes pour les chemins de défaillance (rouge ou orange)
-
Étiquetez les mécanismes de réessai et les disjoncteurs
-
Montrez clairement les destinations de secours
Piège 3 : Nommage incohérent
Le problème :
Utiliser des terminologies différentes pour les services dans le diagramme par rapport au code source crée de la confusion pendant les sessions de débogage.
La solution :
-
Utilisez le même terminologie exacte pour les services dans le diagramme que dans le code source
-
Si un service est appelé « Order-Service » dans le code, ne l’étiquetez pas « Orders API » dans le diagramme
-
Créez un document de convention de nommage et appliquez-le
Piège 4 : Types de données manquants
Le problème :
Une ligne entre deux conteneurs vous indique queles données circulent,mais pasquelles données circulent.
La solution :
Annotez les lignes avec le type de charge utile des données :
-
« Charge utile JSON »
-
« Image binaire »
-
« Lot CSV »
-
« Messages Protobuf »
Cela informe les ingénieurs sur la complexité du traitement requis au niveau du récepteur et aide à identifier les surcharges liées à la sérialisation/désérialisation.
Meilleures pratiques pour une documentation évolutif 📈
Au fur et à mesure que le système grandit, le diagramme peut devenir encombré. Gérer la complexité est une tâche continue.
Stratégie 1 : Stratification
Utilisez des couches différentes pour des préoccupations différentes :
-
Couche 1 : Frontières de sécurité et flux d’authentification
-
Couche 2 : Flux de données et interactions entre services
-
Couche 3 : Topologie de déploiement et infrastructure
Évitez de dessiner tout cela sur une seule page. Proposez des vues distinctes pour différents publics et objectifs.
Stratégie 2 : Liens vers les détails
Si un conteneur est complexe :
-
Créez un sous-diagramme distinct pour celui-ci
-
Liez le diagramme principal à la vue détaillée
-
Évitez de dessiner chaque composant sur la page de vue d’ensemble
-
Utilisez une approche par descente : Contexte → Conteneurs → Composants → Code
Stratégie 3 : Codage par couleur
Utilisez la couleur pour indiquer l’état ou la criticité :
| Couleur | Signification |
|---|---|
| Rouge | Chemins critiques, flux à haute priorité |
| Bleu | Flux standards, opérations normales |
| Gris | Connexions obsolètes, systèmes hérités |
| Vert | Nouveaux ou flux récemment mis à jour |
| Orange | Zones d’alerte, points de congestion potentiels |
Cela permet un balayage visuel rapide de l’état du système et des priorités.
Stratégie 4 : Métadonnées
Inclure les métadonnées essentielles dans chaque diagramme :
-
Numéro de versiondu diagramme
-
Date de dernière révision
-
Propriétaire/entreteneurnom ou équipe
-
Statut (Brouillon, En revision, Approuvé, Obsolète)
Placez ces informations dans le pied de page du document pour fournir un contexte sur la mise à jour de l’information.
Intégration avec les plateformes d’observabilité 🔍
Les diagrammes statiques sont statiques. Les systèmes réels sont dynamiques. Les architectures modernes intègrent les diagrammes avec des plateformes d’observabilité. Cela signifie que le diagramme n’est pas seulement une image, mais uninterface en temps réel.
Connexion des diagrammes aux données de surveillance
Lors de la visualisation du flux de données, prenez en compte la relation entre le diagramme et les données de surveillance :
Le défi :
Si vous observez une latence élevée sur une connexion spécifique dans l’outil de surveillance, le diagramme doit clairement afficher cette connexion.
La solution :
-
Assurez-vous que le lien aide à l’analyse des causes racines
-
Les ingénieurs doivent pouvoir cliquer sur une ligne du diagramme et voir les métriques actuelles pour ce lien
-
Intégrez des outils tels que Prometheus, Grafana, Datadog ou New Relic
Approches de mise en œuvre
-
Diagrammes interactifs :
-
Utilisez des outils qui prennent en charge les éléments cliquables
-
Intégrez directement des widgets de surveillance dans les diagrammes
-
Lier les éléments du diagramme aux tableaux de bord
-
-
Mises à jour pilotées par API :
-
Récupérer des métriques en temps réel depuis les plateformes d’observabilité
-
Mettre à jour automatiquement les annotations du diagramme
-
Mettre en évidence les chemins problématiques en fonction des seuils d’alerte
-
-
Approche hybride :
-
Maintenir une structure statique pour assurer la stabilité
-
Superposer des métriques dynamiques pour l’état actuel
-
Utiliser le codage par couleur pour indiquer l’état de santé
-
Exigences d’intégration
Cette intégration nécessite que :
-
Le format du diagramme prend en charge l’intégration ou le lien avec des sources de données externes
-
La méthode de diagrammation choisie permet une flexibilité sans nécessiter de mises à jour manuelles à chaque changement de métrique
-
L’authentification et les contrôles d’accès sont correctement configurés
-
L’impact sur les performances est minimisé
Mise à profit des outils C4 à intelligence artificielle de Visual Paradigm 🤖
Visual Paradigm a révolutionné la manière dont les équipes abordent la documentation de l’architecture logicielle grâce à sa suite complète d’outils de modélisation C4 à intelligence artificielle. Ces outils résolvent de nombreux défis traditionnels liés à la création et à la maintenance des diagrammes d’architecture.
Outil de diagramme C4 de Visual Paradigm
L’outil dédié de diagramme C4 de Visual Paradigm offre un environnement spécialisé pour créer des diagrammes de systèmes clairs, évolutifs et maintenables. L’outil prend en charge nativement les quatre niveaux du modèle C4, permettant aux équipes de passer sans heurt entre différents niveaux d’abstraction.
Fonctionnalités principales :
-
Prise en charge native du C4 :Formes et notations intégrées spécifiquement conçues pour la modélisation C4
-
Navigation multi-niveaux :Navigation facile du niveau Contexte au niveau Code
-
Application de la cohérence :Validation automatique des règles de modélisation C4
-
Flexibilité d’exportation :Plusieurs formats de sortie, notamment PDF, PNG et HTML interactif
Studio C4 PlantUML à intelligence artificielle
L’un des offres les plus puissantes de Visual Paradigm est le Studio C4 PlantUML à intelligence artificielle, qui combine la flexibilité du diagrammation basée sur du texte de PlantUML avec des capacités d’intelligence artificielle.
Comment ça marche :
-
Entrée en langage naturel : Décrivez votre architecture en anglais courant
-
Traitement par IA : L’IA interprète votre description et comprend les relations
-
Génération automatique : Les diagrammes C4 sont générés automatiquement au format PlantUML
-
Affinement itératif : Utilisez une IA conversationnelle pour modifier et affiner les diagrammes
Avantages :
-
Rapidité : Générez des diagrammes complexes en quelques minutes au lieu de plusieurs heures
-
Accessibilité : Pas besoin d’apprendre une syntaxe de diagrammation complexe
-
Consistance : L’IA garantit une application cohérente des principes de modélisation C4
-
Convivial avec le contrôle de version : Les fichiers PlantUML basés sur du texte fonctionnent sans problème avec Git
Chatbot IA pour la génération et la modification de diagrammes
Le chatbot IA de Visual Paradigm pousse la documentation d’architecture à un niveau supérieur en offrant une interface interactive et conversationnelle pour créer et modifier des diagrammes C4.
Cas d’utilisation :
-
Création initiale du diagramme : « Créez un diagramme de conteneurs C4 pour un système de commerce électronique avec des microservices »
-
Mises à jour incrémentales : « Ajoutez un conteneur de service de paiement qui communique avec le service de commande »
-
Support du restructurage : « Divisez le service utilisateur monolithique en services d’authentification et de profil »
-
Amélioration de la documentation : « Ajoutez des étiquettes de flux de données montrant les charges utiles JSON entre les services »
Application dans le monde réel :
Les équipes peuvent intégrer le chatbot d’IA dans leur flux de développement, permettant aux architectes et aux développeurs de maintenir la documentation aussi naturellement qu’ils écrivent du code. Le chatbot comprend le contexte et peut proposer des suggestions intelligentes concernant les limites des conteneurs, les modèles de flux de données et les modèles de cohérence.
Automatisation du cycle de vie du modèle C4
Les outils d’IA de Visual Paradigm permettent l’automatisation sur l’ensemble du cycle de vie du modèle C4 :
1. Phase de découverte :
-
L’IA analyse les bases de code existantes et les configurations d’infrastructure
-
Propose des limites initiales de conteneurs basées sur les modèles de déploiement
-
Identifie les microservices potentiels à partir d’applications monolithiques
2. Phase de conception :
-
Génère des diagrammes à partir des registres des décisions architecturales
-
Valide les modèles de conception par rapport aux meilleures pratiques
-
Propose des améliorations en matière de scalabilité et de résilience
3. Phase d’implémentation :
-
Synchronise les diagrammes avec les fichiers Infrastructure-as-Code
-
Met à jour automatiquement les diagrammes lorsque des services sont ajoutés ou supprimés
-
Maintient la cohérence entre le code et la documentation
4. Phase de maintenance :
-
Détecte les écarts entre les diagrammes et l’architecture réelle du système
-
Propose des mises à jour lorsque de nouvelles dépendances sont introduites
-
Fournit une analyse d’impact pour les modifications architecturales proposées
Intégration avec les équipes DevOps et cloud
Pour les équipes DevOps et natives du cloud, les outils C4 alimentés par l’IA de Visual Paradigm offrent des avantages spécifiques :
Visualisation de l’architecture cloud :
-
Génération automatique de diagrammes à partir des configurations des fournisseurs cloud (AWS, Azure, GCP)
-
Visualisation des architectures sans serveur et de l’orchestration de conteneurs
-
Mappage des services cloud aux conteneurs C4
Intégration avec les pipelines CI/CD :
-
Génération automatique de diagrammes dans le cadre des pipelines de construction
-
Portes de validation de la documentation dans les flux de déploiement
-
Mises à jour automatiques lorsque des modifications de l’infrastructure sont déployées
Collaboration d’équipe :
-
Collaboration en temps réel sur les diagrammes d’architecture
-
Commentaires et workflows de revue intégrés aux éléments du diagramme
-
Contrôle d’accès basé sur les rôles pour différents groupes de parties prenantes
Mise en route avec les outils C4 d’IA de Visual Paradigm
Étape 1 : Évaluation
-
Évaluez vos pratiques actuelles de documentation
-
Identifiez les points douloureux liés à la maintenance des diagrammes d’architecture
-
Déterminez quels niveaux C4 sont les plus critiques pour votre organisation
Étape 2 : Sélection des outils
-
Choisissez entre l’ensemble complet de Visual Paradigm ou des outils C4 spécifiques
-
Décidez de l’intégration PlantUML en fonction des préférences de l’équipe
-
Pensez à l’accès à un chatbot d’IA pour un prototypage rapide
Étape 3 : Projet pilote
-
Sélectionnez un système représentatif pour le modélisation initiale
-
Créez des diagrammes de base aux niveaux Contexte et Conteneur
-
Formez les membres de l’équipe à la création de diagrammes assistée par l’IA
Étape 4 : Intégration
-
Connectez les diagrammes aux systèmes de gestion de version
-
Mettez en place des processus de revue pour les modifications des diagrammes
-
Intégrez avec les plateformes de documentation existantes
Étape 5 : Montée en charge
-
Étendez à d’autres systèmes et services
-
Développez des modèles et des normes à l’échelle de l’organisation
-
Mesurez les améliorations de la qualité de la documentation et de l’effort de maintenance
Points clés ✅
Visualiser le flux de données dans les systèmes distribués est une discipline qui équilibrel’exactitude techniqueavecla lisibilité. En s’alignant sur le modèle C4 et en utilisant des outils modernes alimentés par l’IA comme C4 Studio de Visual Paradigm, les équipes peuvent créer un langage cohérent pour l’architecture qui évolue avec leurs systèmes.
Principes essentiels
-
Définir clairement les limites
-
Assurer que les conteneurs s’alignent avec les unités de déploiement
-
Chaque service déployable de manière indépendante obtient son propre conteneur
-
Utiliser des outils d’IA pour valider les décisions concernant les limites
-
-
Mettre en évidence les modèles explicitement
-
Différencier les flux synchrones et asynchrones
-
Utiliser des styles de lignes et des annotations appropriés
-
Montrer clairement la direction et le protocole
-
Utiliser l’IA pour suggérer des modèles optimaux
-
-
Documenter les modèles de cohérence
-
Indiquer comment l’état est géré à travers les limites
-
Préciser la cohérence forte contre la cohérence éventuelle
-
Noter les délais de synchronisation lorsque cela est pertinent
-
-
Maintenir rigoureusement avec l’aide de l’IA
-
Traiter les diagrammes comme des documents vivants qui évoluent avec le code
-
Automatiser autant que possible à l’aide des outils d’IA de Visual Paradigm
-
Inclure dans les processus de revue de code
-
Utiliser l’IA conversationnelle pour des mises à jour rapides
-
-
Se concentrer sur la clarté
-
Privilégier l’exactitude plutôt que l’esthétique
-
Éviter le sensationnalisme et le langage marketing
-
Servir en priorité l’équipe d’ingénierie
-
Utiliser l’IA pour générer une documentation claire et cohérente
-
La puissance de la documentation améliorée par l’IA
L’intégration d’outils d’IA tels que C4 PlantUML Studio et l’IA Chatbot de Visual Paradigm transforme la documentation d’architecture d’une tâche pénible en une partie fluide du processus de développement. Les équipes peuvent :
-
Réduire le délai de documentation : Générer des diagrammes complets en quelques minutes
-
Améliorer la précision : L’IA valide la cohérence et la complétude
-
Améliorer la collaboration :Les interfaces en langage naturel rendent la documentation accessible à tous les parties prenantes
-
Assurer la mise à jour :Les mises à jour automatisées maintiennent les diagrammes synchronisés avec le code
Le but ultime
L’objectif n’est pas seulement de tracer des lignes, mais deconstruire une compréhension partagéede la manière dont le système fonctionne. Une visualisation efficace du flux de données, améliorée par des outils alimentés par l’IA :
-
Réduit la charge cognitive des ingénieurs
-
Accélère l’intégration des nouveaux membres de l’équipe
-
Améliore la fiabilité globale de l’infrastructure distribuée
-
Permet une meilleure prise de décision pendant les incidents
-
Facilite les discussions et la planification architecturales
-
Assure que la documentation suit le rythme des cycles de développement rapides
En suivant ces principes et en tirant parti des capacités d’analyse C4 alimentées par l’IA de Visual Paradigm, les équipes d’ingénierie peuvent transformer des systèmes distribués complexes en architectures compréhensibles, maintenables et évolutives qui résisteront à l’épreuve du temps.
Références
- Visualisation du flux de données à travers les conteneurs de systèmes distribués avec le modèle C4: Infographie éducative illustrant les modèles de flux de données, les styles de communication et les modèles de cohérence dans les architectures distribuées en utilisant le cadre du modèle C4 avec une visualisation au style de dessin d’enfant.
- Outil de diagrammes C4 par Visual Paradigm – Visualisez l’architecture logicielle facilement: Cette ressource met en évidence un outil qui permet aux architectes logiciels de créer des diagrammes de systèmes clairs, évolutifs et maintenables en utilisant la technique de modélisation C4.
- Guide ultime pour la visualisation du modèle C4 à l’aide des outils d’IA de Visual Paradigm: Ce guide explique comment tirer parti de l’intelligence artificielle pour automatiser et améliorer la visualisation du modèle C4 afin de concevoir des architectures plus intelligentes.
- Mise à profit de l’AI C4 Studio de Visual Paradigm pour une documentation d’architecture simplifiée: Une exploration de l’AI C4 Studio amélioré, qui permet aux équipes de créer des documents de documentation d’architecture logicielle propres, évolutifs et hautement maintenables.
- Guide pour débutants sur les diagrammes du modèle C4: Un tutoriel pas à pas conçu pour aider les débutants à créer des diagrammes du modèle C4 à travers les quatre niveaux d’abstraction : Contexte, Conteneurs, Composants et Code.
- Le guide ultime pour C4-PlantUML Studio : Révolutionner la conception d’architecture logicielle: Cet article traite de l’intégration de l’automatisation pilotée par l’IA avec la flexibilité de PlantUML afin de simplifier le processus de conception d’architecture logicielle.
- Un guide complet sur le studio C4 PlantUML alimenté par l’IA de Visual Paradigm: Un guide détaillé expliquant comment ce studio spécialisé transforme le langage naturel en diagrammes C4 précis et multicouches.
- C4-PlantUML Studio : générateur de diagrammes C4 alimenté par l’IA: Cette vue d’ensemble des fonctionnalités décrit un outil d’IA qui génère automatiquement des diagrammes d’architecture logicielle C4 directement à partir de descriptions textuelles simples.
- Tutoriel complet : génération et modification de diagrammes de composants C4 avec un chatbot alimenté par l’IA: Un tutoriel pratique qui montre comment utiliser un chatbot alimenté par l’IA pour générer et affiner des diagrammes de composants C4 à travers une étude de cas réelle.
- Sortie de la prise en charge complète du modèle C4 par Visual Paradigm: Un communiqué officiel concernant l’inclusion d’une prise en charge complète du modèle C4 pour gérer des diagrammes d’architecture à plusieurs niveaux d’abstraction au sein de la plateforme.
- Générateur d’IA du modèle C4 : automatisation des diagrammes pour les équipes DevOps et cloud: Cet article explique comment les invites conversationnelles d’IA automatisent l’intégralité du cycle de vie du modèle C4, assurant ainsi une cohérence et une rapidité pour les équipes techniques.