











Le modèle C4 est devenu la norme pour visualiser l’architecture logicielle, offrant une hiérarchie claire du Contexte au Conteneur, au Composant et au Code. Toutefois, l’essor du calcul sans serveur introduit des défis uniques pour ce cadre de modélisation statique. Les fonctions sans serveur sont éphémères, déclenchées par des événements et souvent gérées par des fournisseurs de cloud, ce qui rend leur représentation dans un diagramme structuré non triviale. Ce guide détaille comment modéliser avec précision les architectures sans serveur en utilisant les principes C4 sans dépendre d’outils spécifiques aux fournisseurs. 📚
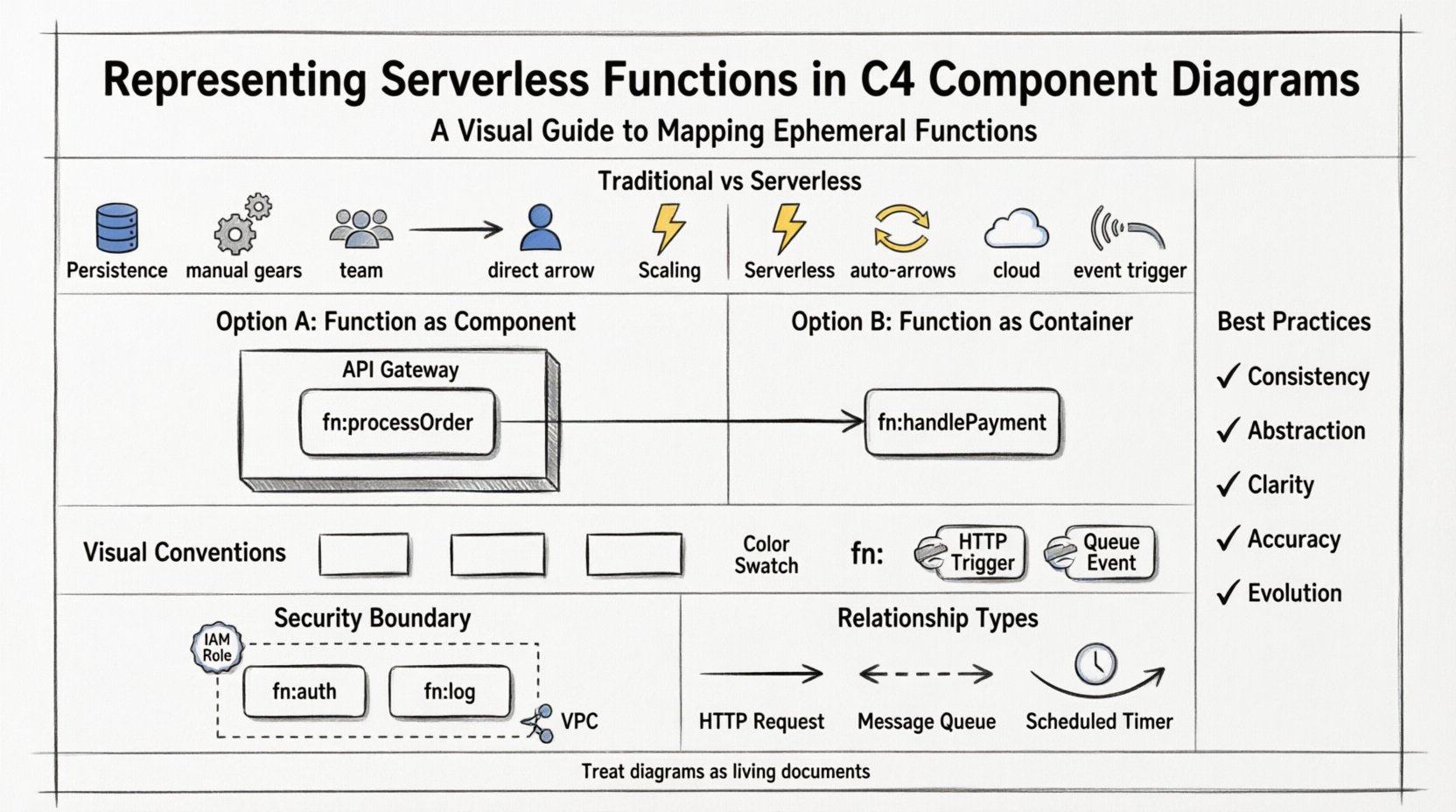
Comprendre les tensions : C4 vs. sans serveur 🤔
Le modèle C4 a été conçu en tenant compte des structures d’applications traditionnelles. Il suppose un certain niveau de persistance et d’état au sein des conteneurs. Les fonctions sans serveur, en revanche, sont conçues pour être sans état et évoluer selon la demande. Lorsque vous tentez de mapper une fonction à un composant C4, des questions surgissent concernant les frontières, le cycle de vie et la propriété. Sans directives claires, les diagrammes peuvent devenir encombrés ou trompeurs, masquant le flux réel des données et du contrôle. Nous devons adapter le modèle pour refléter la nature dynamique des infrastructures cloud modernes. 🌥️
Pour combler cet écart, nous devons comprendre les différences fondamentales :
- Persistance :Les conteneurs traditionnels conservent souvent un état en mémoire. Les fonctions sans serveur, elles, ne le font pas. Elles sont détruites après leur exécution.
- Mise à l’échelle :Les conteneurs évoluent grâce à une orchestration (comme Kubernetes). Le sans serveur évolue automatiquement en fonction du volume d’événements.
- Propriété :Les conteneurs sont souvent gérés par l’équipe de développement. Les environnements d’exécution sans serveur sont gérés par le fournisseur de cloud.
- Points d’entrée :Les API sont souvent le déclencheur des fonctions sans serveur, et non une interaction directe de l’utilisateur avec un processus persistant.
Mapper le sans serveur dans la hiérarchie C4 🗺️
Où se situent les fonctions sans serveur dans la hiérarchie C4 ? La réponse dépend du niveau de détail requis par le public cible. Il n’existe pas de réponse unique correcte, mais il existe des bonnes pratiques pour maintenir la clarté. 🛠️
Option 1 : Sans serveur en tant que composant ⚙️
C’est l’approche la plus courante. Vous traitez la fonction sans serveur comme un Composant à l’intérieur d’un Conteneur. Le Conteneur représente le service logique ou la passerelle API qui redirige le trafic vers la fonction. Cette séparation est cruciale car elle distingue le point d’entrée (la passerelle) de l’exécution de la logique (la fonction).
- Conteneur : La passerelle API ou le chargeur répartiteur qui accepte les requêtes HTTP.
- Composant : La fonction sans serveur spécifique qui traite la requête.
- Avantage : Sépare clairement les préoccupations de routage de la logique métier.
Option 2 : Sans serveur en tant que conteneur 📦
Dans certains cas, une seule fonction agit comme le point d’entrée complet d’un microservice. Si la fonction gère directement la logique API et l’accès aux données, elle peut être modélisée comme un Conteneur. Cela est souvent utilisé pour des services plus petits et autonomes, où le surcoût de définir un conteneur de passerelle distinct est inutile.
- Conteneur : La fonction sans serveur elle-même.
- Frontière : La fonction gère elle-même la validation d’entrée et le formatage de sortie.
- Avantage : Simplifie les diagrammes pour les applications sans serveur à petite échelle.
Tableau de comparaison : Stratégies de placement 📊
| Stratégie | Meilleur cas d’utilisation | Complexité | Clarté |
|---|---|---|---|
| Fonction en tant que composant | Microservices matures avec des passerelles distinctes | Moyen | Élevé |
| Fonction en tant que conteneur | Fonctions simples, à une seule finalité | Faible | Moyen |
| Plusieurs fonctions en tant que composants | Flux de travail complexes avec orchestration | Élevé | Élevé |
Conventions visuelles pour les applications sans serveur 🎨
La cohérence dans la représentation visuelle aide les parties prenantes à identifier rapidement les éléments sans serveur. Bien que le modèle C4 n’impose pas d’icônes spécifiques, l’adoption de conventions améliore la lisibilité. Utilisez des formes standard de composants, mais ajoutez des indices visuels pour indiquer les caractéristiques sans serveur.
Iconographie et style
- Forme : Utilisez le rectangle standard de composant (arrondi ou carré).
- Codage par couleur : Attribuez une couleur spécifique (par exemple, gris clair ou un accent particulier) à tous les composants sans serveur afin de les distinguer des conteneurs persistants.
- Étiquettes : Précisez les noms des fonctions avec
fn:oufunc:pour indiquer leur nature éphémère. - Annotations : Ajoutez du texte indiquant l’environnement d’exécution ou le type de déclencheur (par exemple, « Déclencheur HTTP », « Événement de file d’attente »).
Indiquer la nature éphémère
Étant donné que les fonctions serverless sont détruites après exécution, vous pouvez utiliser des traits pointillés ou des styles de bord spécifiques pour suggérer cela. Toutefois, les traits pleins standards sont souvent préférés pour une clarté concernant les dépendances logiques. L’essentiel est de documenter le cycle de vie dans les notes du diagramme plutôt que de s’appuyer uniquement sur les styles de traits.
Modélisation des relations et des dépendances 🔗
Comprendre comment les fonctions serverless interagissent avec les autres composants du système est essentiel. Les relations dans les diagrammes C4 représentent le flux de données et les dépendances, et non seulement la connectivité réseau.
Relations de déclenchement
Les fonctions serverless sont généralement pilotées par des événements. Vous devez représenter clairement la source de ces événements.
- Demandes HTTP :Connectez un conteneur API Gateway au composant de fonction en utilisant une relation « Demande ».
- Files de messages : Si une fonction consomme des messages depuis une file d’attente, dessinez une relation du conteneur de file d’attente vers le composant de fonction.
- Horloges : Pour les tâches planifiées, indiquez une relation « Planification » à partir d’un conteneur de planificateur.
Considérations sur le flux de données
Les fonctions serverless traitent souvent des données sans les stocker à long terme. Assurez-vous que votre diagramme reflète cette nature sans état.
- État temporaire : Si les données sont conservées en mémoire pendant l’exécution, ne les modélisez pas comme un composant de base de données.
- Stockage persistant : Connectez la fonction aux services de stockage externes (comme le stockage d’objets ou les bases de données) de manière explicite. Ne supposez pas que la fonction possède les données.
- Sortie : Montrez clairement où va le résultat de la fonction (par exemple, une réponse au client ou un message vers une autre file d’attente).
Sécurité et limites 🔒
La sécurité est souvent négligée dans les diagrammes d’architecture de haut niveau, mais elle est cruciale pour les architectures serverless. La gestion des identités et des accès (IAM) joue un rôle plus important ici que dans les applications traditionnelles conteneurisées.
Définition des limites de sécurité
Chaque fonction sans serveur doit avoir une frontière de sécurité définie. Dans votre schéma, regroupez les fonctions qui partagent les mêmes rôles IAM ou politiques réseau. Cela facilite la vérification et la compréhension de la propagation des autorisations.
- Regroupement :Utilisez une frontière « Contexte système » ou « Conteneur » pour regrouper les fonctions par domaine de sécurité.
- Autorisations :Annotez les composants avec le niveau d’accès requis (par exemple, « Lecture seule », « Accès administrateur »).
- Réseau :Indiquez si une fonction s’exécute dans un Cloud privé virtuel (VPC) ou est accessible publiquement.
Authentification et autorisation
Schématisez le flux des jetons d’authentification. La fonction valide-t-elle elle-même le jeton, ou dépend-elle de la passerelle API ? Cette distinction influence l’emplacement de la logique de sécurité dans votre architecture.
Péchés courants et défis ⚠️
La modélisation des architectures sans serveur comporte des défis spécifiques qui peuvent entraîner des schémas inexactes si elles ne sont pas traités.
Sur-modélisation des détails
Il est facile de se perdre dans les détails de chaque fonction. Si vous avez des centaines de petites fonctions, ne modélisez pas chacune individuellement dans un schéma de composants. Regroupez-les en groupes logiques ou en composants de niveau supérieur.
- Règle de base :Si un composant est trop petit pour avoir un comportement distinct, fusionnez-le avec son parent.
- Abstraction :Utilisez un composant « Service » pour représenter un groupe de fonctions liées.
Ignorer les démarrages froids
Bien que ce ne soit pas strictement un élément visuel, le concept de « démarrages froids » (latence lors de l’initialisation d’une fonction) affecte l’architecture. Vous pourriez souhaiter annoter les composants où la latence est critique. Cela influence les décisions concernant la concurrence préallouée ou les couches de mise en mémoire tampon.
Supposer une exécution synchrone
De nombreuses fonctions sans serveur sont asynchrones. Ne les modélisez pas comme si elles renvoyaient toujours une réponse HTTP directe. Utilisez des types de relation différents (par exemple, « Déclencher et oublier » ou « Événement ») pour indiquer les flux asynchrones.
Documentation et maintenance 📝
Un schéma C4 n’est bon que par sa précision au fil du temps. Les architectures sans serveur évoluent fréquemment. Pour maintenir les schémas :
- Contrôle de version :Stockez vos schémas aux côtés de votre code d’infrastructure.
- Automatisation :Utilisez des outils capables de générer des schémas à partir de définitions de code, lorsque cela est possible.
- Cycles de revue :Mettez à jour les schémas lors des rétrospectives de sprint ou des revues architecturales.
- Balises : Utilisez des balises dans le diagramme pour indiquer la date de la dernière revue.
Scénarios avancés : Orchestration et état 🔄
Les applications serverless complexes impliquent souvent une orchestration. Vous pourriez utiliser un moteur de workflow pour gérer une série de fonctions. Comment cela s’intègre-t-il dans C4 ?
Moteurs de workflow
Modélisez le moteur de workflow comme un Conteneur. Les étapes individuelles du workflow sont des Composants. Cela sépare la logique de contrôle (le workflow) de la logique d’exécution (les fonctions).
- Conteneur : Orchestrateur de workflow.
- Composant : Fonction étape A, fonction étape B.
- Relation : « Déclencheurs » ou « Coordonne ».
Gestion d’état
Si votre application serverless nécessite un état, celui-ci doit être externe. N’impliquez pas qu’un état existe à l’intérieur de la fonction. Connectez explicitement la fonction à un composant de base de données ou de cache. Cela renforce le modèle sans état dans le modèle visuel.
Résumé des bonnes pratiques ✅
Pour garantir que vos diagrammes C4 restent efficaces pour les architectures serverless, respectez ces principes fondamentaux :
- Consistance : Utilisez le même style visuel pour tous les composants serverless.
- Abstraction : N’implémentez pas chaque fonction individuelle si cela ajoute du bruit.
- Clarté : Distinctement différenciez les déclencheurs, la logique et le stockage.
- Précision : Représentez les limites de déploiement et les autorisations réelles.
- Évolution : Traitez les diagrammes comme des documents vivants qui évoluent avec le code.
Pensées finales sur la visualisation de l’architecture 🌟
Représenter les fonctions serverless dans le modèle C4 exige un changement de mentalité. Vous ne dessinez pas simplement des boîtes ; vous cartographiez des comportements dynamiques vers des représentations statiques. En suivant ces directives, vous créez des diagrammes qui servent d’outils de communication efficaces pour les développeurs, les architectes et les parties prenantes. L’objectif n’est pas seulement de documenter ce qui existe, mais de clarifier le comportement du système sous charge, en cas de panne et dans différents environnements. Un diagramme C4 bien conçu pour une architecture serverless réduit l’ambiguïté et accélère la prise de décision. 🚀
Souvenez-vous, la valeur du diagramme réside dans la compréhension qu’il apporte, et non dans la complexité du dessin. Gardez-le simple, gardez-le précis et gardez-le à jour. Cette approche garantit que votre architecture reste compréhensible au fur et à mesure de l’évolution du paysage technologique. 🛠️