











Les diagrammes de flux de données (DFD) servent d’outil fondamental dans l’analyse et la conception des systèmes. Ils offrent une représentation visuelle du déplacement des données à travers un système, en mettant en évidence les processus, les entrepôts de données, les entités externes et les flux qui les relient. Toutefois, la création d’un DFD valide n’est pas toujours simple. Des erreurs peuvent s’infiltrer au cours du processus de modélisation, entraînant des incohérences logiques qui compromettent toute l’architecture du système.
Ce guide propose une approche complète pour identifier et résoudre les problèmes courants rencontrés dans les diagrammes de flux de données. En suivant des méthodes de dépannage structurées, les analystes peuvent s’assurer que leurs modèles reflètent fidèlement les exigences du système et les réalités opérationnelles.
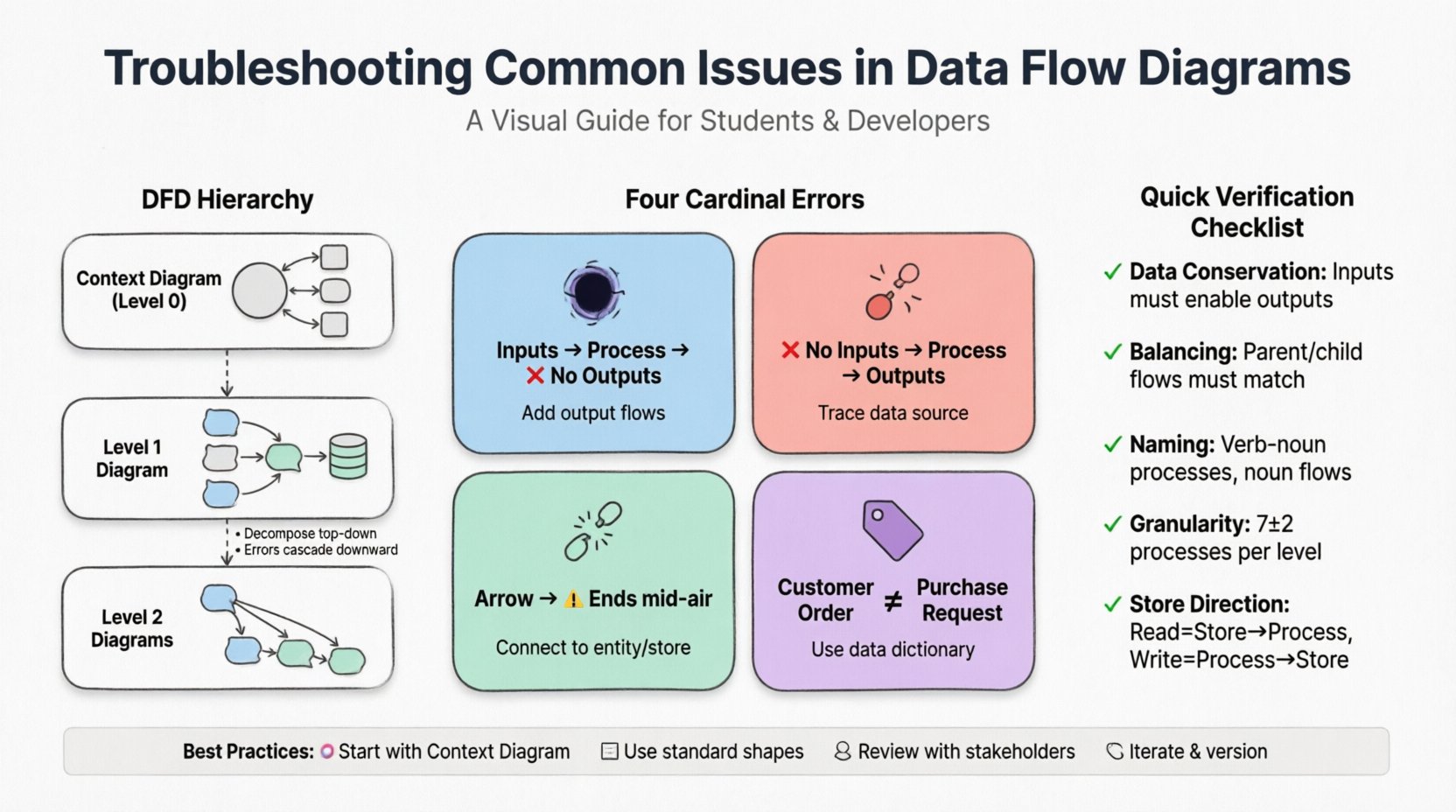
Comprendre la hiérarchie des DFD 🏗️
Avant de procéder au dépannage d’erreurs spécifiques, il est essentiel de comprendre la structure d’un DFD. Un effort de modélisation complet implique généralement une hiérarchie de diagrammes :
- Diagramme de contexte (Niveau 0) : Vue de niveau le plus élevé. Il représente le système comme un seul processus interagissant avec des entités externes. Il définit les limites du système.
- Diagramme de niveau 1 : Décompose le processus principal du diagramme de contexte en sous-processus majeurs. Il révèle les principaux entrepôts de données et les principaux flux.
- Diagrammes de niveau 2 : Décompose davantage des processus spécifiques du niveau 1 en étapes plus précises.
Le dépannage commence souvent au niveau du contexte et se propage vers le bas. Les incohérences au niveau supérieur entraîneront des erreurs dans tous les diagrammes de niveaux inférieurs.
Les quatre erreurs fondamentales 🚫
Il existe quatre types spécifiques d’erreurs logiques qui apparaissent fréquemment dans les DFD. Leur identification exige une revue attentive des entrées et sorties de données pour chaque processus.
1. Le trou noir
Un trou noir se produit lorsqu’un processus possède des entrées mais aucune sortie. Cela implique que les données entrent dans le processus et disparaissent sans qu’aucun résultat ou transformation ne soit enregistré. Dans un système du monde réel, cela est impossible. Chaque entrée doit déclencher une action, qu’il s’agisse de stocker des données, d’envoyer une réponse ou de mettre à jour un enregistrement.
Comment corriger :
- Suivez chaque flux de données entrant dans le processus.
- Vérifiez si le processus doit générer un rapport, mettre à jour une base de données ou déclencher une notification.
- Si aucune sortie n’existe, ajoutez les flux de données nécessaires pour assurer la conservation des données.
2. Le miracle
L’inverse d’un trou noir est un miracle. Cela se produit lorsque un processus produit des sorties sans aucune entrée. Cela suggère que des données sont générées de nulle part. Il s’agit d’une faille logique critique, car chaque donnée doit provenir d’une source à l’intérieur du système ou d’une source externe.
Comment corriger :
- Identifiez l’élément de données produit.
- Déterminez la source de ces données (par exemple, une entrée utilisateur, une lecture de capteur ou un processus antérieur).
- Ajoutez le flux d’entrée manquant à la bulle du processus.
3. Données pendantes
Les données pendantes font référence à un flux qui ne se connecte à rien. Cela pourrait être une ligne qui s’arrête brusquement au milieu du diagramme ou qui se connecte à un espace vide. Cela indique une rupture dans le chemin des données.
Comment corriger :
- Assurez-vous que chaque flèche relie une source à une destination.
- Vérifiez si un magasin de données ou une entité externe est manquant.
- Vérifiez que le processus de destination a réellement besoin de cet élément de données spécifique.
4. Nommage incohérent
Les flux de données doivent être étiquetés de manière cohérente à tous les niveaux. Si un flux est étiqueté « Commande client » dans le diagramme de niveau 1, il ne doit pas être renommé en « Demande d’achat » dans le diagramme de niveau 2, sauf si le sens a fondamentalement changé. Un nommage incohérent confond les parties prenantes et les développeurs.
Comment corriger :
- Créez un dictionnaire de données pour standardiser la terminologie.
- Effectuez une vérification croisée entre les diagrammes parent et enfant.
- Assurez-vous que le nom d’un flux entrant dans un processus correspond au nom du flux sortant du même processus (sauf si transformé).
Granularité des processus et décomposition 🧩
L’un des problèmes les plus courants dans les diagrammes en flux de données est une décomposition incorrecte. Une bulle de processus ne doit pas être trop grande (trop de logique) ni trop petite (étapes triviales).
Trop de processus
Si un diagramme de niveau 1 comporte plus de sept à neuf processus, il devient difficile à lire et à gérer. Cela indique souvent que l’analyste n’a pas regroupé les fonctions connexes.
- Solution :Regroupez les processus par domaine fonctionnel ou capacité métier.
- Solution :Considérez si un processus doit être divisé en deux processus distincts s’il gère deux fonctions logiques différentes.
Trop peu de processus
Inversement, si un processus est chargé de tout, de la connexion utilisateur au sauvegarde de la base de données, il est trop complexe. Cela rend impossible la conception d’algorithmes ou d’interfaces spécifiques pour cette bulle.
- Solution :Décomposez les processus complexes en sous-processus pour les diagrammes de niveau 2.
- Solution :Assurez-vous qu’un processus ait un seul nom verbe-nom (par exemple, « Valider la connexion » au lieu de « Se connecter, valider et enregistrer »).
Intégrité du magasin de données 🗄️
Les magasins de données représentent les référentiels où les données sont sauvegardées pour une utilisation future. Les erreurs ici peuvent entraîner une perte ou une corruption des données.
Magasins de données manquants
Il est fréquent d’oublier d’ajouter un magasin de données lorsqu’un processus doit sauvegarder des informations pour une récupération ultérieure. Par exemple, une fonction « Traiter la commande » doit sauvegarder les détails de la commande quelque part avant que la transaction ne soit terminée.
- Vérifiez :Recherchez les processus qui modifient l’état sans connexion correspondante à un magasin de données.
Direction incorrecte du flux de données
Les flèches reliant les magasins de données doivent indiquer la bonne direction du déplacement des données. Un flux d’un magasin de données vers un processus signifie la lecture des données. Un flux d’un processus vers un magasin de données signifie l’écriture des données. Confondre ces deux sens peut entraîner des erreurs logiques dans la conception de la base de données.
- Vérifier :Vérifiez que les opérations de lecture vont du Stockage au Processus.
- Vérifier :Vérifiez que les opérations d’écriture vont du Processus au Stockage.
Techniques de vérification et de validation 🧐
Une fois le diagramme dessiné, il doit être validé par rapport aux exigences métier réelles. Plusieurs techniques aident à garantir l’exactitude.
1. La règle de conservation des données
Cette règle stipule que les entrées et sorties d’un processus doivent être suffisantes pour effectuer la fonction décrite. Si un processus est étiqueté « Calculer la taxe », les entrées doivent inclure le montant imposable et le taux de taxe, et la sortie doit être la valeur de taxe calculée.
2. La règle de décomposition des processus
Les entrées et sorties au niveau 1 doivent correspondre aux entrées et sorties agrégées des processus enfants au niveau 2. Si le diagramme au niveau 1 montre une entrée « ID client » entrant dans l’élément « Traiter la commande », le diagramme enfant au niveau 2 doit montrer que « ID client » entre dans au moins un des processus enfants.
3. Vérification d’équilibre
Assurez-vous que les flux de données entrant dans un processus parent sont les mêmes que les flux de données entrant dans l’ensemble des processus enfants. Cela maintient l’intégrité de la hiérarchie.
Liste de contrôle courante pour le dépannage 📋
Utilisez le tableau suivant pour passer en revue systématiquement vos diagrammes.
| Type de problème | Description | Impact | Étape de correction |
|---|---|---|---|
| Trou noir | Le processus a des entrées mais aucune sortie | Perte de données ; flux de travail interrompu | Ajouter des flux de sortie ou redéfinir la fonction du processus |
| Miracle | Le processus a des sorties mais aucune entrée | Génération de données non valides | Identifier la source des données et ajouter des flux d’entrée |
| Flux pendu | La flèche ne se connecte à rien | Chemin de données rompu | Connecter à l’entité, le processus ou le stockage approprié |
| Incohérence dans la nomenclature | Même donnée nommée différemment | Confusion pour les développeurs | Standardiser la terminologie dans le dictionnaire des données |
| Décomposition déséquilibrée | Les entrées/sorties enfants diffèrent du parent | Fentes logiques dans la hiérarchie | Ajuster les flux pour correspondre au processus parent |
Conventions de nommage et clarté 🏷️
Un nommage clair est essentiel pour la communication avec les parties prenantes. Les noms de processus doivent être des verbes suivis de noms (par exemple, « Mettre à jour l’inventaire »). Les noms de flux de données doivent être des noms (par exemple, « Rapport d’inventaire »).
Lors du dépannage des problèmes de nommage :
- Éviter les acronymes :Utilisez des mots complets sauf si l’acronyme est universellement compris au sein de l’organisation.
- Soyez précis :« Données » est trop vague. Utilisez « Adresse du client » ou « Enregistrement de paiement ».
- Tense cohérent :Gardez les noms de processus au présent (“Générer un rapport” et non “Généré un rapport”).
Intégration avec d’autres modèles 🔄
Les diagrammes de flux de données n’existent pas en isolation. Ils doivent souvent s’aligner avec d’autres techniques de modélisation.
Diagrammes d’entité-association (ERD)
Les magasins de données du DFD doivent s’aligner avec les tables définies dans un ERD. Si un DFD affiche un magasin de données « Informations client » mais que l’ERD contient « Utilisateurs » et « Détails de contact », le DFD doit être ajusté pour refléter la structure physique de la base de données.
Diagrammes de transition d’état
Les DFD se concentrent sur le mouvement des données, tandis que les diagrammes d’état se concentrent sur les états du système. Assurez-vous que les processus du DFD déclenchent correctement les changements d’état identifiés dans le diagramme d’état.
Maintenance du diagramme au fil du temps 📅
Les systèmes évoluent. Un DFD créé pendant la phase de spécifications peut devenir obsolète après la phase de mise en œuvre. La maintenance nécessite une stratégie de gestion de versions.
- Gestion des versions :Marquez chaque diagramme avec un numéro de version et une date.
- Journaux des modifications :Documentez pourquoi un changement a été effectué (par exemple, « Mis à jour pour refléter la nouvelle passerelle de paiement »).
- Cycles de revue : Planifiez des revues périodiques avec les parties prenantes métier pour vous assurer que le diagramme correspond toujours à la réalité métier.
Outils vs. Revue manuelle 🖥️
Bien que des outils de modélisation existent pour aider à la création des diagrammes de flux de données, ils ne sont pas infaillibles. Les outils automatisés peuvent détecter des erreurs de syntaxe (comme les lignes pendantes), mais ils ne peuvent pas vérifier la logique métier. Un analyste humain doit examiner le diagramme pour s’assurer qu’il a du sens dans le contexte des opérations métiers.
Lorsque vous utilisez un logiciel de modélisation générique :
- Utilisez les fonctions de validation intégrées pour vérifier la connectivité de base.
- Ne comptez pas sur le logiciel pour nommer vos processus ; utilisez votre jugement humain.
- Exportez les diagrammes au format PDF pour les revues des parties prenantes, avec l’édition désactivée afin d’éviter les modifications accidentelles.
Étude de cas : Dépannage d’un système de vente au détail 🛒
Imaginez une situation où un diagramme de flux de données d’un système de vente au détail échouait lors des tests d’acceptation utilisateur.
Le problème
Les utilisateurs ont signalé que les niveaux de stock ne se mettaient pas à jour lors des ventes. Le diagramme de niveau 1 montrait un processus « Traiter la vente » prenant « Détails de la vente » en entrée.
Le diagnostic
Après une inspection plus approfondie de la décomposition au niveau 2, la bulle « Traiter la vente » avait été divisée en « Calculer le total » et « Enregistrer la transaction ». Toutefois, le flux de données reliant « Enregistrer la transaction » au « Magasin de stock » était absent. Il s’agissait d’un classique trou noir du côté du stock, même si le processus avait lui-même une sortie.
La résolution
Les analystes ont ajouté le flux de données « Mise à jour du stock » du processus « Enregistrer la transaction » vers le « Magasin de stock ». Le système a été retesté, et les niveaux de stock se sont mis à jour correctement.
Meilleures pratiques pour les analystes 👨💻
Pour minimiser les efforts de dépannage à l’avenir, adoptez ces pratiques dès le départ :
- Commencez petit :Commencez par un diagramme de contexte clair avant de procéder à la décomposition.
- Utilisez des modèles :Adoptez des formes standard pour les processus (rectangles arrondis) et les magasins de données (rectangles ouverts) afin d’éviter toute confusion.
- Impliquez les parties prenantes :Parcourez le diagramme avec les utilisateurs métiers. Si ils comprennent le flux, il est probablement correct.
- Itérez :Prévoyez de redessiner les diagrammes à plusieurs reprises. Le premier brouillon est rarement la version définitive.
Conclusion sur l’intégrité du système ✅
Le dépannage des diagrammes de flux de données est une compétence essentielle pour garantir la fiabilité du système. En comprenant les quatre erreurs fondamentales, en maintenant une cohérence dans la nomenclature et en validant par rapport aux règles métier, les analystes peuvent créer des modèles solides. Ces modèles servent de plan aux développeurs, garantissant que le logiciel final fonctionne comme prévu.
Une revue régulière et le respect des règles de conservation des données permettront d’éviter les lacunes logiques. Souvenez-vous qu’un DFD est un outil de communication tout autant qu’un document technique. La clarté pour le lecteur est tout aussi importante que l’exactitude pour la machine.