











Dans le paysage complexe de l’analyse système et du développement logiciel, la clarté est primordiale. Lorsque les parties prenantes, les développeurs et les analystes tentent de comprendre comment les informations circulent dans un système, l’ambiguïté peut entraîner des erreurs coûteuses. C’est là que le diagramme de flux de données (DFD) joue un rôle essentiel. Il offre une méthode structurée pour représenter le flux d’information au sein d’un système, en séparant les processus logiques de leur implémentation physique.
Un DFD n’est pas simplement un dessin ; c’est un outil de communication. Il permet aux équipes de visualiser les entrées de données, les transformations et les sorties sans s’attarder sur les détails du code. En cartographiant ces flux, les organisations peuvent identifier les points de congestion, garantir l’intégrité des données et aligner les objectifs métiers avec les capacités techniques. Ce guide explore les mécanismes, les composants et la valeur stratégique des diagrammes de flux de données dans les systèmes d’information modernes.
Comprendre le but fondamental 🎯
La fonction principale d’un diagramme de flux de données est de décrirece queun système fait, plutôt quecommentil le fait. Cette distinction est essentielle lors de la phase de collecte des exigences. Alors qu’un extrait de code ou un schéma de base de données montre l’implémentation, un DFD montre le comportement. Il agit comme un plan directeur pour la logique du système.
Prenons une application bancaire. Un organigramme pourrait montrer la séquence des boutons cliqués par l’utilisateur. Un DFD, en revanche, se concentre sur le transfert d’argent depuis le compte utilisateur jusqu’au registre des transactions. Il met en évidence la transformation des données. Cette abstraction permet aux analystes de discuter de la logique du système avec des parties prenantes non techniques sans engendrer de confusion.
Pourquoi la visualisation compte
- Communication : Elle comble l’écart entre les besoins métiers et l’exécution technique.
- Analyse : Elle révèle les points de données manquants ou les processus redondants.
- Documentation : Elle sert de référence pour les maintenances et mises à jour futures.
- Validation : Elle aide à vérifier que toutes les entrées de données sont prises en compte et traitées correctement.
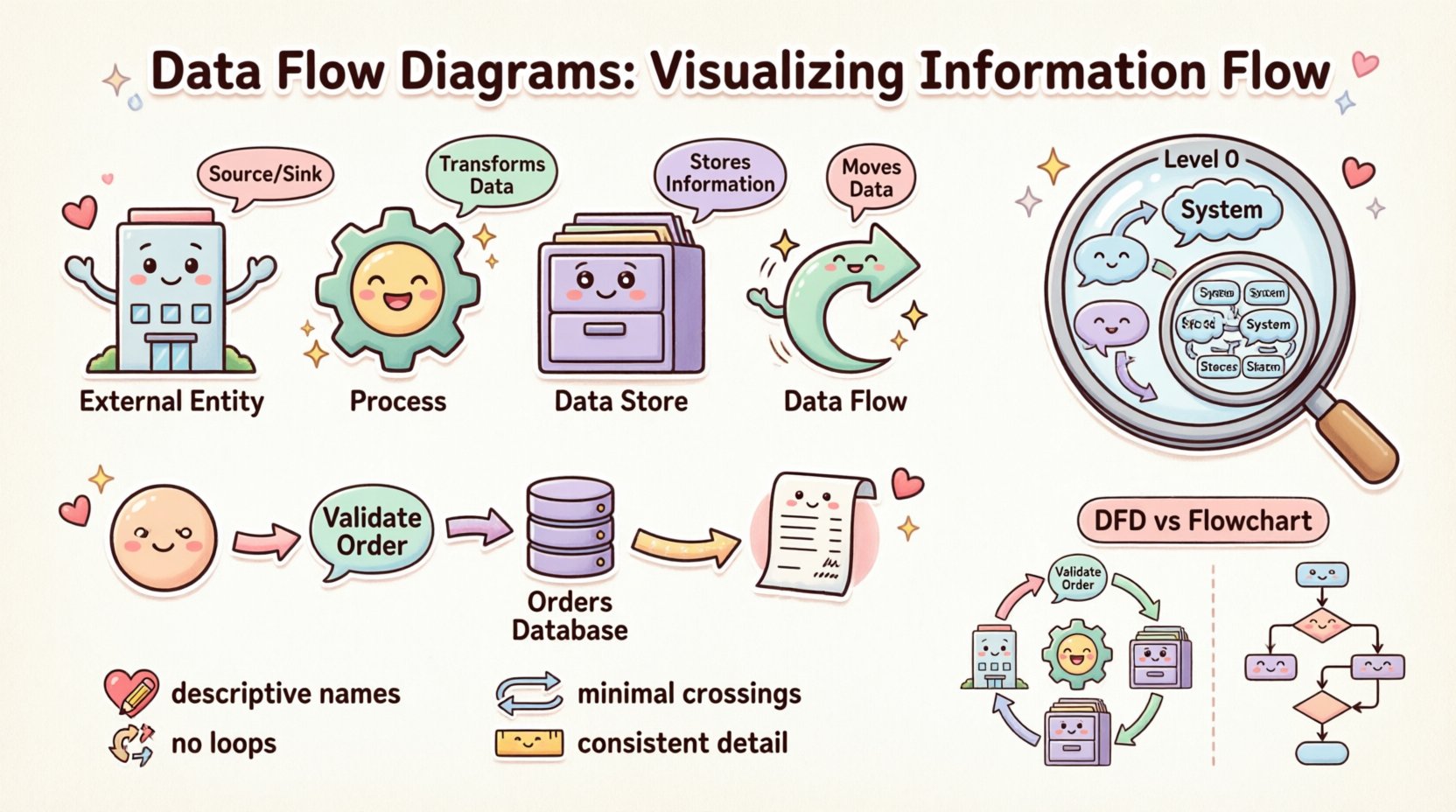
Les quatre composants essentiels 🧱
Chaque diagramme de flux de données est construit à partir de quatre blocs de base fondamentaux. Comprendre ces éléments est une condition préalable à la création de diagrammes précis. Chaque composant joue un rôle spécifique dans l’écosystème du flux d’information.
1. Entités externes (la source et le puits) 🏢
Les entités externes représentent des personnes, des organisations ou d’autres systèmes situés à l’extérieur de la frontière du système analysé. Elles agissent comme source de données entrant dans le système ou comme destination où les données sortent.
- Terminologie : Souvent appelées sources, puits ou acteurs.
- Fonction : Elles initient un processus ou reçoivent la sortie finale.
- Exemple : Un client, une banque, un fournisseur ou une passerelle de paiement externe.
2. Processus (la transformation) ⚙️
Les processus représentent des activités qui transforment les données d’entrée en données de sortie. Ce sont les éléments actifs du schéma. Un processus modifie l’état ou la forme des données.
- Terminologie : Aussi appelés Fonctions ou Transformations.
- Fonction : Il reçoit des données, les modifie et les envoie ensuite.
- Exemple : « Calculer la taxe », « Valider la connexion utilisateur » ou « Générer une facture ».
3. Magasins de données (La mémoire) 🗄️
Les magasins de données représentent des endroits où les informations sont conservées pour une utilisation ultérieure. Ils ne déclenchent pas d’action, mais conservent les données à l’intérieur de la frontière du système. Cela peut être une base de données physique, un fichier, ou même un classeur physique dans des contextes hérités.
- Terminologie : Bases de données, Fichiers, Référentiels ou Files d’attente.
- Fonction : Stockage et récupération des données.
- Exemple : « Base de données clients », « Journal de l’historique des commandes » ou « Fichier d’inventaire ».
4. Flux de données (Le mouvement) 🔄
Les flux de données indiquent le déplacement des informations entre les entités, les processus et les magasins. Ce sont les connecteurs qui relient le schéma. Un flux doit avoir un nom qui décrit les informations en cours de déplacement.
- Terminologie : Flèches, Flux ou Lignes.
- Fonction : Transport des données du point A au point B.
- Direction : Le flux est directionnel. Une flèche pointant d’un processus vers un magasin indique l’écriture des données ; une flèche pointant d’un magasin vers un processus indique la lecture des données.
Comparaison des composants
Pour assurer la clarté, il est utile de comparer ces composants côte à côte. Ce tableau décrit les rôles distincts que chaque élément joue dans la structure du schéma.
| Composant | Rôle | Forme de notation | Question répondue |
|---|---|---|---|
| Entité externe | Source/Puisard | Rectangle | Qui ou quoi interagit avec le système ? |
| Processus | Transformateur | Cercle ou rectangle arrondi | Quel travail est effectué sur les données ? |
| Magasin de données | Référentiel | Rectangle ouvert | Où sont stockées les données ? |
| Flux de données | Transporteur | Flèche | Comment les données se déplacent-elles ? |
Niveaux d’abstraction 📉
Un seul diagramme capte rarement la complexité d’un système entier. Pour gérer cette complexité, les diagrammes de flux de données (DFD) sont créés à différents niveaux de détail. Cette technique est connue sous le nom de décomposition. Elle permet aux analystes d’agrandir ou de réduire l’architecture du système.
Diagramme de contexte (Niveau 0) 🌍
Le diagramme de contexte est la vue de niveau le plus élevé. Il représente l’ensemble du système comme un seul processus. Il définit les limites du système et identifie toutes les entités externes interagissant avec lui. Ce diagramme répond à la question : « Quel est le but global du système ? »
- Portée : Un processus central.
- Détail : Minimal. Seuls les entrées et sorties majeures sont affichées.
- Objectif : Définir les limites du système pour les parties prenantes.
Diagramme de niveau 1 (processus majeurs) 🔍
Une fois le contexte établi, le processus central est décomposé en sous-processus majeurs. Ce diagramme de niveau 1 décompose le système en ses principales zones fonctionnelles. Il montre comment les données circulent entre ces composants majeurs et les entités externes.
- Portée : 3 à 7 processus majeurs.
- Détail : Interactions internes de haut niveau.
- Objectif : Comprendre les principaux modules fonctionnels.
Diagramme de niveau 2 (processus détaillés) 🔬
Une décomposition supplémentaire a lieu au niveau 2. Les processus spécifiques du niveau 1 sont divisés en étapes plus granulaires. C’est ici que la logique devient précise. Cela est souvent utilisé par les équipes de développement pour comprendre les exigences exactes nécessaires au codage.
- Portée : Sous-processus détaillés.
- Détail : Transformations spécifiques des données.
- Objectif : Guider la mise en œuvre et la conception logique.
Le concept d’équilibre ⚖️
Une règle fondamentale dans la création des diagrammes de flux de données est l’équilibre. Les entrées et sorties d’un processus parent doivent correspondre aux entrées et sorties de son diagramme enfant (le niveau suivant). Si un processus de niveau 1 reçoit « Données de commande », la décomposition au niveau 2 de ce processus ne peut pas simplement faire disparaître ces données ; il doit toujours accepter les « Données de commande » comme entrée.
Le non-respect des règles d’équilibre crée des incohérences dans le modèle du système. Cela suggère que des données sont créées de nulle part ou disparaissent sans laisser de trace. Le maintien de l’équilibre garantit que l’intégrité logique du système est préservée à tous les niveaux d’abstraction.
Diagrammes de flux de données vs. organigrammes 🆚
Il est fréquent de confondre les diagrammes de flux de données avec les organigrammes. Bien qu’ils partagent une ressemblance visuelle, leur objectif et leur structure diffèrent considérablement.
- Organigrammes : Se concentrer sur le flux de contrôle. Ils montrent la séquence des étapes, des décisions et des boucles. Ils répondent à la question « Qu’est-ce qui se passe ensuite ? » Ils sont souvent utilisés pour décrire la logique d’un algorithme spécifique ou d’une interaction avec une interface utilisateur.
- Diagrammes de flux de données : Se concentrer sur le flux de données. Ils montrent le déplacement de l’information. Ils répondent à la question « Où vont les données ? » Ils ne montrent généralement pas explicitement les boucles ou les points de décision ; ils montrent les transformations.
Utiliser le mauvais type de diagramme peut induire en erreur l’équipe de développement. Si vous devez documenter une séquence de connexion utilisateur avec gestion des erreurs, un organigramme est préférable. Si vous devez documenter le déplacement des données utilisateur depuis le formulaire jusqu’à la base de données, un diagramme de flux de données est plus approprié.
Meilleures pratiques pour la clarté ✨
La création d’un DFD est un exercice de rigueur. Suivre les conventions établies garantit que le diagramme reste lisible et utile au fil du temps.
1. Conventions de nommage 📝
Les étiquettes doivent être descriptives. Évitez les termes vagues comme « Processus 1 » ou « Donnée A ». Utilisez plutôt des combinaisons verbe-nom pour les processus, comme « Valider le mot de passe ». Pour les flux de données, utilisez des noms qui décrivent le contenu, comme « Adresse de livraison » ou « Reçu de paiement ». Une nomenclature cohérente aide les utilisateurs à naviguer dans le diagramme sans deviner.
2. Éviter les boucles de flux de données 🚫
Un flux de données ne doit pas boucler immédiatement sur le même processus. Bien que les données puissent revenir à un processus après avoir traversé d’autres composants, les boucles directes sur soi-même indiquent souvent une erreur logique ou une mauvaise compréhension de la frontière du processus. Un processus doit recevoir une entrée, la transformer, puis produire une sortie. Si la sortie est directement renvoyée à lui-même, cela implique un traitement infini.
3. Minimisation des croisements 🧵
Un diagramme encombré est un diagramme inutile. Disposez les composants de manière à ce que les flux de données s’effectuent naturellement, généralement de gauche à droite ou du haut vers le bas. Minimisez le nombre de croisements de flèches. Si les lignes se croisent, il devient difficile de suivre le parcours de données spécifiques. Utilisez des courbes ou des interruptions pour maintenir un flux visuel fluide.
4. Granularité cohérente 📏
Dans un même diagramme, le niveau de détail doit être cohérent. Ne mélangez pas des processus de haut niveau avec des sous-processus de bas niveau. Si un processus est décomposé en trois étapes, tous les autres processus majeurs dans cette même vue doivent être au même niveau de décomposition.
Péchés courants et solutions ⚠️
Même les analystes expérimentés commettent des erreurs lors de la construction de diagrammes. Reconnaître ces pièges courants peut économiser du temps pendant le processus de revue.
Le trou noir
Un trou noir se produit lorsqu’un processus possède des entrées mais aucune sortie. Les données entrent dans le processus et disparaissent. Cela indique généralement un magasin de données manquant ou un flux manquant vers une entité externe. Tout processus qui accepte des données doit produire un résultat.
Le processus miraculeux
C’est l’inverse d’un trou noir. Un processus miraculeux possède des sorties mais aucune entrée. Il génère des données sans consommer aucune information. Cela est physiquement impossible. Chaque sortie doit être dérivée de données d’entrée.
Données fantômes
Les données fantômes désignent les flux de données implicites mais non dessinés. Si un processus a besoin d’un identifiant client pour fonctionner, mais qu’aucune flèche ne transporte cet identifiant vers le processus, la logique est incomplète. Toute exigence de données doit être explicitement connectée.
Confusion autour des entités externes
Les analystes confondent parfois des composants internes avec des entités externes. Si un composant fait partie de la frontière du système, il s’agit d’un processus ou d’un magasin. S’il est à l’extérieur du système, il s’agit d’une entité. Dessiner une ligne de frontière aide à clarifier cette distinction.
Intégration dans le cycle de vie du développement 🛠️
Les diagrammes de flux de données ne sont pas des artefacts statiques ; ce sont des documents vivants qui évoluent avec le projet. Ils jouent un rôle dans diverses étapes du cycle de vie du développement logiciel.
- Recueil des exigences :Les DFD aident à capturer les besoins des utilisateurs en visualisant comment les données entrent et sortent de l’entreprise. Ils valident que tous les points de données requis ont été identifiés.
- Conception du système :Ils guident la conception de la base de données. Les magasins de données dans le DFD se traduisent directement en tables ou collections dans le schéma de la base de données.
- Tests :Les cas de test peuvent être dérivés des flux de données. Si un flux existe dans le diagramme, il doit être testé pour garantir l’intégrité des données.
- Maintenance :Lorsqu’il y a des changements, le DFD est mis à jour. Il fournit une vue d’ensemble à haut niveau qui aide les nouveaux membres de l’équipe à comprendre rapidement le système.
La psychologie de la visualisation 🧠
Pourquoi faisons-nous confiance aux diagrammes plutôt qu’au texte ? Le cerveau humain traite les informations visuelles beaucoup plus rapidement que le texte. Un DFD exploite le raisonnement spatial pour organiser une logique complexe. Il permet au spectateur de voir des relations qui pourraient se perdre dans un paragraphe de texte.
Lorsque les parties prenantes voient le diagramme, elles peuvent repérer instantanément les connexions manquantes. Un vide dans les flèches est plus visible qu’un vide dans un document de spécifications. Cette immédiateté visuelle réduit le risque d’interprétation erronée. Elle crée un modèle mental partagé au sein de l’équipe.
Avenir de la visualisation des données 🔮
À mesure que les systèmes deviennent de plus en plus distribués et nativement cloud, le rôle du DFD reste pertinent. Les systèmes modernes impliquent des microservices, des APIs et des intégrations tierces. Ce sont essentiellement des entités externes et des flux de données.
Les outils automatisés de documentation commencent à générer des diagrammes de flux de données à partir des dépôts de code. Bien que ces outils soient utiles pour maintenir la cohérence, une revue manuelle reste nécessaire pour garantir la correction logique du flux. Les principes fondamentaux de la décomposition et de l’équilibre restent constants, quelle que soit la pile technologique.
Résumé de la valeur stratégique 💡
Les diagrammes de flux de données offrent une approche structurée pour comprendre les systèmes d’information. Ils décomposent la complexité en composants gérables. Ils facilitent la communication entre les équipes techniques et non techniques. Ils constituent une base pour la conception de bases de données et l’optimisation des processus.
En respectant les principes d’équilibre, de nommage clair et d’abstraction appropriée, les analystes peuvent créer des diagrammes qui résistent à l’épreuve du temps. Que l’on construise une nouvelle application ou que l’on effectue une vérification d’une application existante, le DFD reste un outil fondamental pour visualiser le flux d’information. Il transforme la logique abstraite en une carte concrète qui guide le développement et assure l’alignement avec les objectifs métiers.
Lorsque vous aborderez une tâche d’analyse de système, rappelez-vous que la clarté est l’objectif. Utilisez le DFD pour cartographier le parcours de vos données. Assurez-vous que chaque élément d’information a une source, une destination et un chemin. Cette discipline aboutira à des systèmes plus robustes et à moins d’ambiguïtés.