











Construir software para la nube requiere un cambio de mentalidad. Las arquitecturas monolíticas tradicionales dependían de componentes estrechamente acoplados que compartían memoria y sistemas de archivos locales. Las aplicaciones nativas en la nube, sin embargo, operan en entornos distribuidos, a menudo abarcando múltiples redes y fronteras de seguridad. Para navegar esta complejidad, los ingenieros necesitan representaciones visuales claras de cómo fluye la información a través del sistema. Es aquí donde el Diagrama de Flujo de Datos (DFD) se convierte en una herramienta esencial. Al mapear el flujo de datos entre procesos, almacenes y entidades externas, los equipos pueden diseñar sistemas robustos, escalables y seguros sin depender de conjeturas.
Esta guía explora cómo aplicar los principios del DFD específicamente en contextos nativos en la nube. Examinaremos los componentes fundamentales, las adaptaciones necesarias para sistemas distribuidos y los pasos prácticos para crear diagramas que sigan siendo útiles a medida que evoluciona la infraestructura. Ya sea que esté diseñando un ecosistema de microservicios o una cadena de funciones sin servidor, comprender el movimiento de datos es la base de una ingeniería confiable.
🌩️ Comprendiendo el Cambio hacia el Modelado Nativo en la Nube
En un entorno tradicional en instalación propia, un sistema suele existir dentro de una única frontera física. Los datos fluyen localmente entre procesos. En un entorno nativo en la nube, las fronteras son fluidas. Una única aplicación lógica podría constar de decenas de servicios independientes que se ejecutan en contenedores, orquestados en diferentes regiones o zonas de disponibilidad. La latencia de red, la consistencia eventual y las políticas de seguridad introducen variables que no existen en los diseños monolíticos.
Al crear un Diagrama de Flujo de Datos para este entorno, debe tener en cuenta:
- Fronteras de Red:Los datos a menudo cruzan redes públicas o VPCs seguras. Cada salto representa un punto potencial de fallo o latencia.
- Gestión del Estado:Los servicios en la nube suelen ser sin estado. Los procesos deben recuperar el estado desde almacenes externos en lugar de mantenerlo en memoria.
- Comunicación Asíncrona:Las llamadas síncronas (solicitud-respuesta) no siempre son la mejor opción. Las colas de mensajes y las secuencias de eventos cambian la forma en que los datos fluyen entre los componentes.
- Zonas de Seguridad:Los datos que entran en una periferia deben ser autenticados y cifrados antes de alcanzar los procesos internos.
Visualizar estas restricciones desde el principio previene la deuda arquitectónica. Un diagrama que ignora la segmentación de red o los requisitos sin estado dará lugar a un sistema difícil de depurar y escalar. El objetivo no es solo mostrar hacia dónde va el dato, sino destacar dónde se transforma, almacena y protege.
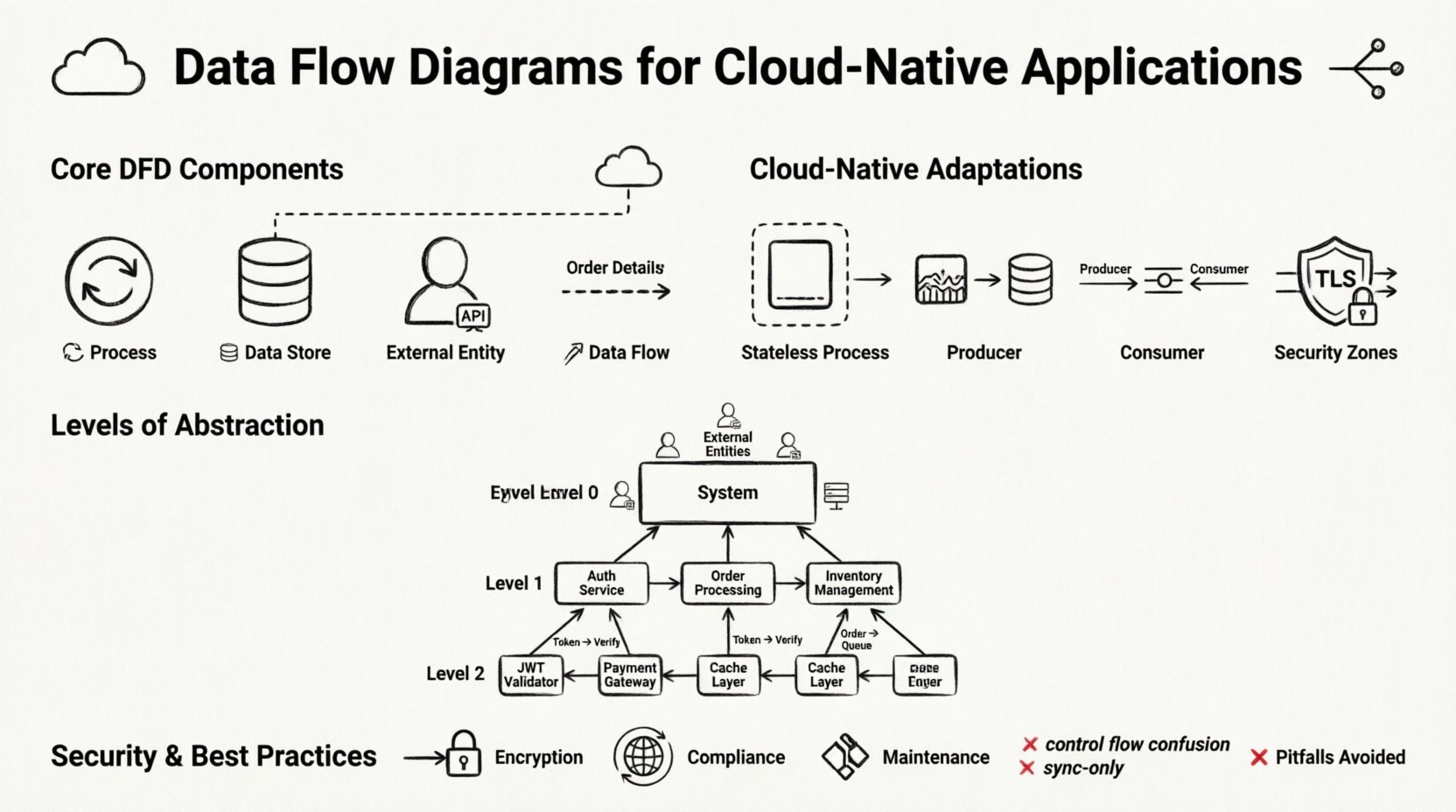
🧩 Componentes Fundamentales de un Diagrama de Flujo de Datos
Antes de adaptar estos diagramas para la nube, debemos establecer los bloques de construcción estándar. Un DFD no es un diagrama de flujo; no muestra lógica de control ni temporización. Muestra el movimiento de datos. Los cuatro elementos principales permanecen consistentes, incluso en sistemas distribuidos.
1. Procesos 🔄
Un proceso representa una actividad que transforma datos de entrada en datos de salida. En un contexto nativo en la nube, un proceso suele ser una función, una aplicación contenerizada o una instancia de microservicio. Es importante nombrar los procesos según lo que hacen, no según su nombre técnico. Por ejemplo, en lugar de «API de UserService», use «Validar Credenciales de Usuario». Esto mantiene el diagrama enfocado en la lógica de transformación de datos.
- Transformación:Cada proceso debe cambiar los datos de alguna manera. Si los datos pasan sin modificación, no deberían representarse como un proceso.
- Encapsulamiento:En los microservicios, cada proceso está encapsulado. La lógica interna está oculta; solo importan las interfaces de entrada y salida para el diagrama.
- Sin Estado:La mayoría de los procesos en la nube son efímeros. No conservan memoria de interacciones anteriores. Esto debe reflejarse en los requisitos de flujo de datos.
2. Almacenes de Datos 🗄️
Un almacén de datos representa un lugar donde los datos descansan mientras no están siendo procesados. En la nube, esto podría ser una base de datos relacional, una tienda de documentos NoSQL, un cubo de almacenamiento de objetos o una caché distribuida. A diferencia de un sistema de archivos, los almacenes de datos en la nube suelen accederse a través de una red.
- Persistencia:Los datos deben guardarse en un almacén si necesitan sobrevivir a un fallo del proceso o a un reinicio.
- Patrones de Acceso: Las bases de datos con acceso intensivo de lectura difieren de las con acceso intensivo de escritura. El diagrama debe indicar el tipo de acceso si afecta significativamente la arquitectura.
- Seguridad:Las bases de datos sensibles requieren controles de acceso diferentes. Esta distinción es vital para auditorías de seguridad.
3. Entidades externas 👥
Las entidades externas son fuentes o destinos de datos fuera de los límites del sistema. Pueden ser usuarios humanos, APIs de terceros, sistemas heredados o dispositivos de hardware. En un diagrama nativo de nube, las entidades externas representan a menudo el borde de internet o servicios de otras nubes.
- Confiado frente a no confiado:Distinga entre datos provenientes de un servicio interno conocido frente al tráfico de internet público.
- Activación:Las entidades suelen iniciar el flujo. Una solicitud de usuario activa un proceso; un trabajo programado activa una sincronización de datos.
4. Flujos de datos 📡
Los flujos de datos son las flechas que conectan los componentes. Representan la transmisión de datos. En entornos en la nube, estos flujos a menudo atraviesan redes. Las etiquetas en las flechas son críticas. Deben describir el paquete de datos, no el protocolo. Por ejemplo, etiquete la flecha como «Detalles del pedido» en lugar de «HTTP POST». Esto mantiene el diagrama independiente del protocolo y preparado para el futuro.
- Direccionalidad:Los flujos son unidireccionales. Si los datos se mueven de ida y vuelta, dibuje dos flechas separadas.
- Volumen:Los flujos de datos de alto volumen podrían requerir infraestructura diferente (por ejemplo, ancho de banda dedicado) en comparación con los flujos de control de bajo volumen.
- Cifrado:Los flujos que cruzan límites de seguridad deben marcarse como cifrados para destacar los requisitos de cumplimiento.
☁️ Adaptación de DFDs para sistemas distribuidos
Los DFD estándar asumen un sistema cohesivo. Los sistemas nativos de nube son distribuidos. Para que un DFD sea útil en este contexto, debe modelar explícitamente la naturaleza distribuida de la infraestructura. Esto implica añadir capas de abstracción que representen la topología de red y los límites de servicio.
Límites de servicio
Los microservicios son los bloques de construcción estándar de las aplicaciones nativas de nube. Cada servicio debería ser idealmente un proceso distinto en su diagrama. Sin embargo, dibujar cada servicio individual puede generar confusión. Un enfoque común consiste en agrupar servicios relacionados en un dominio lógico, como «Dominio de facturación» o «Dominio de gestión de usuarios». Esto permite ver el flujo de alto nivel mientras se oculta la complejidad interna.
Pasarelas de API
La mayoría de las aplicaciones nativas de nube están detrás de una pasarela de API o un balanceador de carga. Este componente actúa como el único punto de entrada. En un DFD, la pasarela es un proceso que enruta las solicitudes. Maneja la autenticación, el control de tasa y la traducción de protocolos. No trate la pasarela como un simple conducto; modifica activamente el flujo de datos.
Arquitecturas basadas en eventos
Muchos sistemas modernos utilizan patrones basados en eventos. Un productor genera un evento, y un consumidor lo procesa más adelante. Esto rompe el enlace síncrono entre proceso y flujo de datos. En un DFD, representa esto usando una cola de eventos o un flujo como almacén de datos. El productor escribe el evento; el consumidor lo lee. Esta desacoplación es crucial para la resiliencia.
| Componente | Monolito tradicional | Adaptación nativa de nube |
|---|---|---|
| Proceso | Función en memoria | Microservicio contenedorizado / Función sin servidor |
| Almacén de datos | Archivo local / Base de datos SQL | Base de datos en la nube administrada / Almacenamiento de objetos |
| Flujo | Llamada a memoria local | HTTP / gRPC / Cola de mensajes |
| Estado | Memoria compartida | Almacén de estado externo |
📉 Niveles de abstracción en la arquitectura en la nube
Los sistemas complejos requieren múltiples niveles de diagramas. Intentar capturar todos los detalles en una sola vista conduce a la confusión. El enfoque estándar de DFD con niveles 0, 1 y 2 funciona bien para sistemas en la nube cuando se aplica correctamente.
Nivel 0: Diagrama de contexto
El diagrama de contexto muestra todo el sistema como un único proceso. Destaca las entidades externas que interactúan con el sistema. Para una aplicación en la nube, esto define el perímetro. Responde a la pregunta: «¿Qué entra al sistema y qué sale de él?». Es la vista de mayor nivel, útil para los interesados que necesitan comprender el alcance sin detalles técnicos.
- Enfoque:Límites del sistema y interfaces externas.
- Detalles:Mínimos. Un proceso central.
- Casos de uso:Definición del alcance del proyecto y planificación de seguridad a alto nivel.
Nivel 1: Procesos principales
El nivel 1 divide el proceso central en subprocesos principales. En un contexto nativo en la nube, estos suelen ser los principales dominios funcionales. Por ejemplo, un diagrama de nivel 1 para una plataforma de comercio electrónico podría mostrar «Procesamiento de pedidos», «Gestión de inventario» y «Manejo de pagos» como procesos distintos. Este nivel revela cómo fluye la información entre los grupos principales de servicios.
- Enfoque:Módulos funcionales principales y sus interacciones.
- Detalles:Entradas y salidas para cada módulo principal.
- Casos de uso:Revisión arquitectónica y descomposición de servicios.
Nivel 2: Lógica detallada
El nivel 2 se enfoca en subprocesos específicos. Es aquí donde los detalles de la implementación técnica adquieren relevancia. Por ejemplo, el proceso «Manejo de pagos» podría ampliarse para mostrar «Validar tarjeta», «Cargar cuenta» y «Actualizar comprobante». Este nivel es utilizado por los desarrolladores que implementan servicios específicos.
- Enfoque: Lógica interna de servicios específicos.
- Detalle: Transformaciones específicas de datos y almacenes locales de datos.
- Casos de uso: Escenarios de implementación de desarrollo y pruebas.
🔒 Seguridad y cumplimiento en el mapeo de datos
La seguridad no es una consideración posterior en el desarrollo nativo de la nube; es un requisito de diseño. Un diagrama de flujo de datos es una excelente herramienta para identificar riesgos de seguridad. Al rastrear el recorrido de los datos, puedes detectar dónde la información sensible podría estar expuesta o almacenada de forma inadecuada.
Identificación de datos sensibles
No todos los flujos de datos son iguales. La información personal identificable (PII), los registros financieros y los datos de salud requieren un manejo más estricto. En tu diagrama, marca los flujos que contienen datos sensibles. Esto garantiza que cada proceso que interactúa con estos datos sea revisado para cumplir con las normativas.
- Cifrado en tránsito: Los flujos que cruzan los límites de red deben estar cifrados (TLS/SSL). Marca estos flujos claramente.
- Cifrado en reposo: Los almacenes de datos que contienen información sensible deben estar cifrados. Indícalo en la etiqueta del almacén de datos.
- Control de acceso: Identifica qué procesos están autorizados para leer o escribir en almacenes de datos específicos. Esto ayuda a establecer el control de acceso basado en roles (RBAC).
Límites de cumplimiento
Diferentes regiones tienen leyes diferentes sobre la soberanía de datos. Los datos podrían necesitar permanecer dentro de un límite geográfico específico. Un DFD ayuda a visualizar estas restricciones. Si un proceso en la Región A envía datos a la Región B, este flujo debe marcarse para revisión legal. Esto evita violaciones accidentales de regulaciones como el GDPR o el CCPA.
⚠️ Errores comunes y cómo evitarlos
Crear DFDs para sistemas en la nube es desafiante. Hay errores comunes que los equipos cometen, a menudo derivados de intentar mapear patrones antiguos a entornos nuevos. Evitar estos errores garantiza que tus diagramas permanezcan precisos y útiles.
1. Mezclar control y flujo de datos
Los DFD no deben mostrar lógica de control. No dibujes flechas para indicar ‘si esto, entonces aquello’. Usa puntos de decisión o notas externas para la lógica, pero mantén las flechas enfocadas en el movimiento de datos. En sistemas en la nube, donde la lógica de control a menudo se maneja mediante plataformas de orquestación, el DFD debe centrarse en el contenido (payload).
2. Ignorar flujos asíncronos
Los sistemas en la nube rara vez son completamente síncronos. Los trabajos se ejecutan en segundo plano. Si solo dibujas flujos de solicitud-respuesta síncronos, tu diagrama será incompleto. Incluye siempre trabajos en segundo plano y flujos de eventos como flujos de datos hacia o desde almacenes de datos.
3. Sobrediseñar para herramientas específicas
No diseñes tu diagrama basado en las capacidades de una herramienta o plataforma específica. Si eliges una base de datos o un broker de mensajes específicos, el diagrama podría volverse obsoleto cuando cambies de tecnología. Enfócate en el flujo lógico de datos, no en la implementación física.
4. Descuidar flujos de error
Los caminos exitosos son fáciles de dibujar. Los caminos de falla son más difíciles pero necesarios. En un entorno en la nube, los servicios fallan con frecuencia. Indica dónde se registra la información de error o dónde se activan mecanismos de reintento. Esto ayuda a diseñar sistemas robustos de monitoreo y alertas.
🔄 Mantenimiento de diagramas con el tiempo
Un diagrama solo es útil si es preciso. Las aplicaciones nativas de la nube cambian rápidamente. Se añaden nuevos servicios, otros se descontinúan y los modelos de datos evolucionan. Si el diagrama no coincide con el sistema en funcionamiento, se convierte en una documentación engañosa. Aquí tienes cómo mantenerlos.
- Control de versiones:Trata los diagramas como código. Guárdalos en tu sistema de control de versiones junto con el código de tu aplicación. Esto garantiza el historial y la trazabilidad.
- Ciclos de revisión:Incluye las actualizaciones de diagramas en tu proceso de revisión de código. Si un desarrollador cambia un flujo de datos, el diagrama debe actualizarse en el mismo commit o solicitud de extracción.
- Generación automática:Donde sea posible, genera diagramas a partir del código o de las definiciones de infraestructura como código. Esto reduce la brecha entre la documentación y la realidad.
- Alineación con los interesados:Revisa periódicamente los diagramas con los interesados no técnicos. Esto asegura que el nivel de abstracción siga siendo adecuado para la audiencia.
📋 Comparación de los DFD con otras vistas arquitectónicas
Es común confundir los DFD con otros diagramas como los diagramas de secuencia o los diagramas de arquitectura del sistema. Comprender la diferencia te ayuda a elegir la herramienta adecuada para la tarea.
| Tipo de diagrama | Enfoque principal | Mejor utilizado para |
|---|---|---|
| Diagrama de flujo de datos | Movimiento y transformación de datos | Diseño de sistemas, auditoría de seguridad, mapeo de datos |
| Diagrama de secuencia | Interacción basada en el tiempo entre objetos | Integración de API, depuración de cadenas de llamadas |
| Arquitectura del sistema | Infraestructura y despliegue | DevOps, escalabilidad, requisitos de hardware |
| Entidad-Relación | Estructura y relaciones de datos | Diseño de bases de datos, planificación de esquemas |
Un DFD complementa estas vistas. Mientras que un diagrama de arquitectura muestra dónde se encuentran los servidores, un DFD muestra cómo viaja la información entre ellos. Mientras que un diagrama de secuencia muestra el orden de las llamadas, un DFD muestra la carga útil. Usarlos juntos proporciona una imagen completa del sistema.
🚀 Tendencias futuras en modelado en la nube
A medida que evolucionan las tecnologías en la nube, también lo hacen los requisitos para el modelado. El auge del cómputo sin servidor y del cómputo periférico introduce nuevos desafíos. Los flujos de datos se vuelven más descentralizados. Los procesos se ejecutan más cerca del usuario. Este cambio requiere que los DFD consideren nodos periféricos y recursos de cómputo temporales.
Además, la integración de la inteligencia artificial en los flujos de trabajo añade complejidad. Los modelos de IA consumen datos y generan conocimientos. Estos procesos a menudo requieren grandes conjuntos de datos y hardware especializado. Los DFD futuros necesitarán representar estos procesos intensivos en cómputo y las tuberías de datos que los alimentan. Los principios fundamentales permanecen iguales, pero la granularidad y el alcance se ampliarán.
Al adherirse a los fundamentos de los Diagramas de Flujo de Datos mientras se adapta a las realidades de la nube, los equipos de ingeniería pueden construir sistemas que sean transparentes, seguros y escalables. Visualizar los datos no es solo un ejercicio de documentación; es un paso crítico en el proceso de diseño que previene errores antes de que lleguen a producción.