











Los diagramas de flujo de datos (DFD) siguen siendo una piedra angular del análisis y diseño de sistemas. Aunque a menudo se introducen en cursos introductorios, su aplicación en entornos de ingeniería de software complejos requiere un enfoque matizado. Esta guía explora técnicas avanzadas para construir, analizar y mantener diagramas de flujo de datos. Avanzamos más allá de las representaciones básicas de cajas y flechas para abordar la concurrencia, la integridad de los datos y la alineación arquitectónica. Ya sea que esté refactorizando sistemas heredados o diseñando nuevas arquitecturas de microservicios, dominar estos diagramas garantiza claridad en la comunicación y precisión en la implementación.
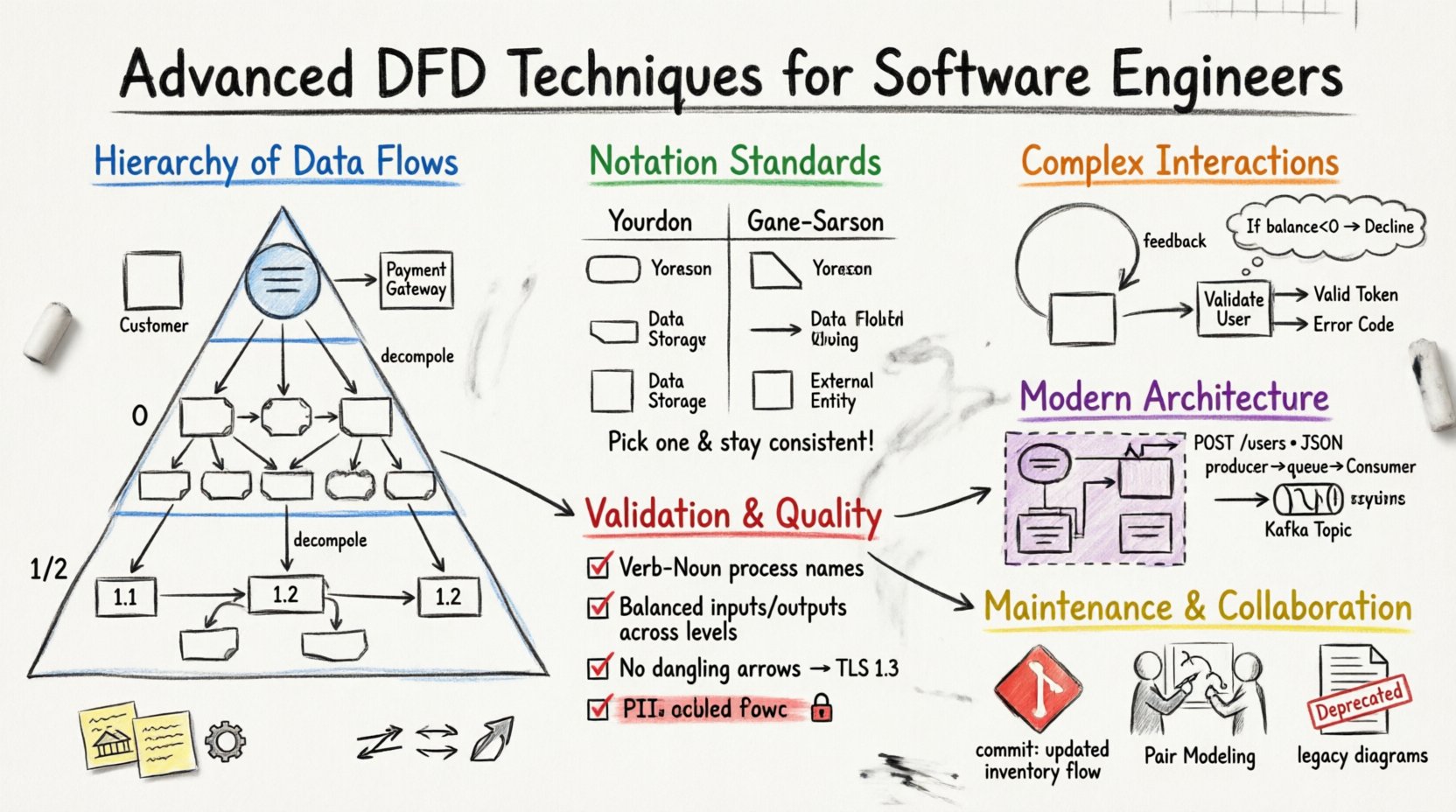
🏗️ Comprendiendo la jerarquía de los flujos de datos
Una estrategia sólida de DFD se basa en un enfoque por capas. Visualizar un sistema en un solo nivel a menudo oculta dependencias críticas. Al descomponer el sistema en niveles específicos, los ingenieros pueden gestionar la complejidad y mantener el enfoque en los detalles relevantes.
🌐 Diagramas de contexto: la vista general
El diagrama de contexto sirve como definición de límite para el sistema. Representa el software como un único proceso e identifica todas las entidades externas que interactúan con él. Este nivel es crucial para definir el alcance de un proyecto.
- Entidades externas: Son usuarios, otros sistemas o dispositivos de hardware fuera del límite. Ejemplos incluyen un Cliente, una Pasarela de Pagos o una Base de Datos Heredada.
- Flujos de datos: Las flechas indican el movimiento de información hacia dentro o hacia fuera del sistema. Las etiquetas deben especificar el contenido, como «Solicitud de pedido» o «Datos de factura».
- Proceso único: El sistema en sí se representa como un rectángulo redondeado, a menudo etiquetado con el nombre del sistema.
Al crear un diagrama de contexto, evite incluir procesos internos. El objetivo es establecer el contrato de interfaz. Si una entidad envía datos pero nunca los recibe, verifique si ese flujo es necesario. De manera similar, asegúrese de que se capturen todas las entradas requeridas de fuentes externas.
📉 Nivel 0: La vista general del sistema
También conocido como el diagrama de «nivel superior» o «padre», el Nivel 0 expande el proceso único del diagrama de contexto en subsistemas principales o áreas funcionales. Este nivel proporciona un mapa de alto nivel de las capacidades del sistema sin detallar la lógica interna.
Las características clave del Nivel 0 incluyen:
- Procesos principales:Normalmente de 5 a 9 procesos. Demasiados indican la necesidad de un agrupamiento de nivel superior; demasiados pocos sugieren funcionalidad ausente.
- Almacenes de datos: Identifique dónde se almacena la información persistente. Este nivel muestra *que* los datos se almacenan, no necesariamente cómo están estructurados.
- Consistencia de flujo: Cada entrada y salida del diagrama de contexto debe aparecer aquí. Esto garantiza que la descomposición no haya alterado el contrato externo del sistema.
🧩 Niveles 1 y 2: Estrategias de descomposición
A medida que profundiza en el Nivel 1 y el Nivel 2, el enfoque se desplaza hacia funciones específicas y manipulación de datos. Aquí es donde se documenta la lógica del trabajo de ingeniería.
- Descomposición: Descomponga los procesos del Nivel 0 en subprocesos. Por ejemplo, «Procesar pedido» podría convertirse en «Validar inventario», «Cobrar pago» y «Generar comprobante».
- Detallado: Cada proceso debe numerarse (por ejemplo, 1.0, 1.1, 1.2) para rastrear las relaciones entre diagramas.
- Acceso a almacenes de datos: Marque claramente qué procesos leen o escriben en qué almacenes de datos. Evite conexiones directas entre entidades externas y almacenes de datos; todo acceso debe pasar por un proceso.
Al descomponer, asegúrese de que no se pierdan los flujos de datos. Un error común es omitir un flujo de datos en un diagrama hijo que existía en el diagrama padre. Esto se conoce como una violación de “equilibrio”.
🔣 Normas de notación y semántica de símbolos
Elegir el sistema de notación adecuado garantiza que los diagramas sean universalmente comprendidos por el equipo de desarrollo. Aunque las normas varían, dos enfoques principales dominan la industria.
| Característica | Notación de Your-Donnell | Notación de Gane-Sarson |
|---|---|---|
| Procesos | Rectángulos redondeados | Rectángulos con esquinas recortadas |
| Almacenes de datos | Rectángulos abiertos | Rectángulos abiertos |
| Entidades externas | Cuadrados | Cuadrados |
| Flujos de datos | Líneas con flechas | Líneas con flechas |
| Etiquetas | Frases sustantivas | Frases sustantivas |
La consistencia es fundamental. Mezclar notaciones dentro del mismo conjunto de documentación genera confusión. Elija una norma y adhírase a ella en todos los diagramas. La elección depende a menudo de la cultura de ingeniería o de las plantillas de documentación existentes.
⚙️ Gestión de interacciones de datos complejas
Los sistemas del mundo real rara vez son lineales. Involucran bucles, lógica de ramificación y eventos asíncronos. Representar estas dinámicas en un diagrama estático requiere técnicas específicas.
🔄 Manejo de bucles e iteraciones
Los DFD no son diagramas de flujo; no muestran explícitamente el flujo de control (si-entonces-sino). Sin embargo, los bucles de datos son comunes. Por ejemplo, un proceso de “Calcular impuestos” podría enviar datos a un almacén de “Búsqueda de tasas” y recibir el resultado de vuelta.
- Bucles de retroalimentación:Utilice flechas que regresen a un proceso para indicar una nueva evaluación. Etiquételas claramente para mostrar qué datos se están actualizando.
- Procesos iterativos:Si un proceso se repite hasta que se cumpla una condición, indique la condición en la descripción del proceso o en una anotación de texto. Evite dibujar el bucle como una línea de flujo de control.
- Actualizaciones de datos:Muestra el flujo de datos que regresa al almacén de datos para indicar una operación de actualización.
🧭 Representación de puntos de decisión
La lógica de decisión pertenece a la descripción del proceso, no al diagrama en sí. Un proceso denominado «Validar usuario» implica lógica interna. No dividas el proceso en «Validar» y «Denegar». Mantén el proceso atómico.
- Diferenciación de salidas:Si un proceso envía datos diferentes según una decisión interna, utiliza etiquetas distintas para los flujos de datos (por ejemplo, «Token válido» frente a «Código de error»).
- Anotaciones:Utiliza cuadros de texto para aclarar los criterios de decisión. Por ejemplo, «Si el saldo < 0, flujo ‘Rechazar’».
- Atomicidad:Asegúrate de que cada proceso realice una única función lógica. Si maneja múltiples decisiones distintas, considera dividirlo en procesos separados.
🔗 Integración de DFDs con arquitecturas modernas
La ingeniería de software ha evolucionado. El cambio hacia sistemas distribuidos, computación en la nube y diseños impulsados por APIs cambia la forma en que percibimos los flujos de datos. Los DFD deben adaptarse para reflejar estas realidades sin volverse obsoletos.
☁️ Microservicios y puntos finales de API
En una arquitectura monolítica, un proceso podría representar un módulo. En un entorno de microservicios, un proceso representa a menudo una instancia de servicio. El flujo de datos se convierte en una llamada a una API.
- Límites del servicio:Dibuja un cuadro alrededor de un conjunto de procesos que constituyen un único microservicio. Los flujos de datos que cruzan esta frontera son solicitudes de red.
- Contratos de API:Etiqueta los flujos de datos con el punto final de API específico o la estructura de carga útil (por ejemplo, «POST /usuarios», «Carga útil JSON»).
- Inestabilidad:Si un servicio es sin estado, no muestres un almacén de datos dentro de los límites del servicio, a menos que sea para caché temporal. El almacenamiento persistente debe ser externo.
📨 Mensajería asíncrona y colas
No todos los flujos de datos ocurren en tiempo real. Los trabajos en segundo plano y las arquitecturas basadas en eventos dependen de colas.
- Colas como almacenes de datos:Representa las colas de mensajes (por ejemplo, RabbitMQ, temas de Kafka) utilizando el símbolo de almacén de datos. Esto aclara que los datos se persisten temporalmente.
- Productor/Consumidor:Muestra el proceso productor escribiendo en la cola y el proceso consumidor leyendo desde ella. El flujo está desacoplado.
- Implicaciones de latencia:Anota en las anotaciones que los datos no están disponibles de inmediato después de escribirlos. Esto es crítico para comprender el comportamiento del sistema durante escenarios de fallo.
🛡️ Validación y verificación de consistencia
Un diagrama solo es útil si refleja con precisión el sistema. La validación asegura que el modelo sea matemática y lógicamente correcto. Los ingenieros deben realizar estas verificaciones antes de finalizar la documentación.
⚖️ Verificación de equilibrio de datos
Cada flujo de datos que entra en un diagrama debe ser contabilizado. Este es el principio de conservación de datos.
- Coincidencia de entradas/salidas:Asegúrese de que cada entrada del diagrama padre aparezca en el diagrama hijo. Ninguna entrada puede desaparecer.
- Completa salida:Todas las salidas definidas en un nivel superior deben estar presentes en el nivel inferior. Si un proceso hijo genera una nueva salida, debe justificarse como un nuevo requisito o un efecto secundario interno.
- Consistencia del almacenamiento:Los almacenes de datos deben ser coherentes entre niveles. Si se crea un almacén en el nivel 1, debe existir en el nivel 0.
🏷️ Convenciones de nomenclatura
La claridad en la nomenclatura previene la ambigüedad. Las etiquetas poco claras son la fuente más común de malentendidos en la documentación técnica.
- Formato verbo-nombre:Los procesos deben nombrarse con un verbo y un sustantivo (por ejemplo, “Calcular impuestos”, “Actualizar perfil”). Evite usar solo sustantivos (por ejemplo, “Impuestos”) o frases verbales sin objeto (por ejemplo, “Calculando”).
- Etiquetas de flujo de datos:Use sustantivos específicos (por ejemplo, “ID de factura”, “Sesión de usuario”). Evite términos vagos como “Datos” o “Información”.
- Nombres de entidades:Las entidades externas deben ser coherentes. “Cliente” no debe cambiar a “Cliente” o “Usuario” dentro del mismo conjunto de diagramas.
🔄 Mantenimiento y ciclo de vida de la documentación
Los diagramas de flujo de datos no son artefactos estáticos. Deben evolucionar conforme cambia el software. Un diagrama desactualizado es peor que no tener ningún diagrama, ya que genera una falsa sensación de comprensión.
📦 Control de versiones para diagramas
Trate los diagramas como código. Guárdelos en un sistema de control de versiones junto con el repositorio de código fuente.
- Mensajes de confirmación:Documente los cambios en los commits de diagramas. “Añadido proceso de pasarela de pago”, “Actualizado flujo de inventario”.
- Diferenciación visual:Use herramientas que permitan la comparación visual de diagramas para detectar cambios estructurales no intencionados.
- Enlace:Enlace los diagramas con las solicitudes de extracción o tickets específicos que causaron el cambio. Esto proporciona trazabilidad.
🤝 Estrategias de colaboración
La documentación es un esfuerzo de equipo. Depender de un solo arquitecto para mantener los DFD genera cuellos de botella y información obsoleta.
- Modelado en pareja:Haga que dos ingenieros dibujen un diagrama juntos durante la fase de diseño. Esto detecta errores temprano.
- Ciclos de revisión:Incluya revisiones de DFD en el proceso estándar de revisión de código. Si cambia el código, el diagrama debe actualizarse o señalarse como desincronizado.
- Documentos vivos:Evite archivar diagramas antiguos. En su lugar, márquelos como «Obsoletos» o «Herencia» dentro del repositorio. Esto preserva el historial sin ensuciar la vista actual.
🧠 Consideraciones avanzadas de implementación
Más allá de la representación visual, las estructuras de datos subyacentes y la lógica determinan el flujo. Los ingenieros deben considerar las limitaciones físicas de los datos.
📏 Volumen de datos y rendimiento
Los DFD describen el flujo lógico, no el rendimiento. Sin embargo, los flujos de alto volumen afectan el diseño.
- Flujos de datos masivos:Si un flujo implica archivos grandes o registros, indíquelo con una etiqueta. Esto podría desencadenar la decisión de usar un mecanismo de transporte diferente.
- Compresión:Indique si los datos se comprimen antes de la transmisión. Esto afecta la carga de procesamiento en el extremo receptor.
- Codificación:Especifique las codificaciones de caracteres si el flujo cruza límites de plataforma (por ejemplo, UTF-8 frente a ASCII).
🔒 Seguridad y control de acceso
La seguridad no es una consideración posterior. Debe ser visible en el flujo de datos.
- Cifrado:Marque los flujos que requieren cifrado. Use una etiqueta como «Flujo cifrado» o «TLS 1.3».
- Manejo de información personal identificable:Resalte los flujos que contienen información personal identificable. Esto garantiza que se cumplan los requisitos de cumplimiento en el diseño.
- Autenticación:Muestre dónde se pasan las credenciales. Evite mostrar contraseñas en flujos de texto plano; etiquételas como «Token de autenticación».
📝 Lista de verificación para la calidad del diagrama
Antes de finalizar un conjunto de diagramas de flujo de datos, revise esta lista de validación.
- ¿Están todas las entidades externas claramente definidas?
- ¿Tienen todos los flujos de datos etiquetas descriptivas?
- ¿Cada proceso está nombrado con una estructura verbo-nombre?
- ¿Hay líneas cruzadas que puedan reenrutarse para mayor claridad?
- ¿Aparece cada entrada en el diagrama padre en el diagrama hijo?
- ¿Las almacenes de datos están adecuadamente separados de los procesos?
- ¿Está el diagrama equilibrado con el diagrama de contexto?
- ¿Hay alguna flecha suelta (flujos sin destino)?
- ¿Es consistente la notación en todo el conjunto de documentos?
- ¿Se han señalado las restricciones de seguridad en los flujos sensibles?
Al adherirse a estas técnicas avanzadas, los ingenieros de software pueden producir documentación que sirva como una planta confiable para el desarrollo. Los diagramas de flujo de datos (DFD) cierran la brecha entre los requisitos abstractos y la implementación concreta. Facilitan la comunicación entre los interesados, reducen la ambigüedad en la lógica y proporcionan una base para las pruebas. Cuando se mantienen con disciplina y se actualizan rigurosamente, siguen siendo una herramienta poderosa en el arsenal de ingeniería.
🚀 Reflexiones finales sobre la modelización de sistemas
El valor de un diagrama de flujo de datos reside en su capacidad para simplificar la complejidad. Elimina el ruido de la sintaxis y los detalles de implementación para centrarse en el movimiento del valor. Para los ingenieros de software, este enfoque es esencial. Permite la detección temprana de defectos de diseño, una incorporación más clara para nuevos miembros del equipo y un modelo mental compartido de la arquitectura del sistema. Comprométase con el proceso de modelado. Requiere esfuerzo, pero el retorno de inversión en claridad del sistema es sustancial.
Recuerde que el diagrama es un medio para un fin. Apoya al código, no al revés. Mantenga los diagramas ágiles, precisos y accesibles. A medida que el sistema evoluciona, permita que los diagramas evolucionen con él. Este enfoque dinámico garantiza que la documentación siga siendo un activo vivo y no una carga estática.