











Diseñar la estructura de datos para una aplicación moderna requiere una consideración cuidadosa de cómo se conectan, persisten y escalan la información. En el centro de este proceso de diseño se encuentra el Diagrama de Relaciones de Entidades (ERD). Este modelo visual sirve como plano de construcción para comprender las entidades de datos y sus interacciones. A medida que crece la complejidad de la aplicación, la elección entre un enfoque relacional y uno basado en grafos se vuelve crítica. Ambos métodos ofrecen ventajas distintas según la naturaleza de las relaciones de datos y los requisitos de rendimiento del sistema.
Comprender los matices de cada técnica de modelado permite a los arquitectos construir sistemas que sean robustos, mantenibles y eficientes. Esta guía explora los principios fundamentales, las diferencias estructurales y las implicaciones prácticas de elegir entre ERDs relacionales y basados en grafos. Al examinar estos métodos en profundidad, los equipos pueden tomar decisiones informadas que se alineen con su lógica empresarial específica y sus limitaciones técnicas.
🏛️ El enfoque relacional: estructura e integridad
El modelo relacional ha sido la columna vertebral de la gestión de datos durante décadas. Se basa en una estructura rígida en la que los datos se organizan en tablas compuestas por filas y columnas. En un ERD relacional, las entidades se representan como tablas, y las relaciones se definen mediante claves foráneas que vinculan claves primarias entre diferentes tablas.
Principios fundamentales del modelado relacional
- Normalización:Las bases de datos relacionales priorizan la normalización para reducir la redundancia. Los datos se dividen en múltiples tablas para garantizar que cada pieza de información se almacene en un solo lugar. Esto minimiza las anomalías de datos durante actualizaciones o eliminaciones.
- Integridad referencial:Las restricciones garantizan que las relaciones permanezcan válidas. Si se elimina un registro en una tabla padre, las reglas determinan cómo se manejan los registros hijos, como la eliminación en cascada o la prohibición de la acción.
- Definición de esquema:La estructura se define antes de la inserción de datos. Cada columna debe tener un tipo de dato y una restricción específicos, garantizando la consistencia en todo el conjunto de datos.
- Lenguaje de consulta:El acceso a los datos generalmente implica el lenguaje de consulta estructurado (SQL). Este lenguaje permite operaciones complejas de unión para recuperar datos distribuidos en múltiples tablas.
Fortalezas de los ERD relacionales
Los diagramas relacionales destacan en escenarios donde la consistencia de los datos es fundamental. Son ideales para sistemas que manejan transacciones financieras, gestión de inventarios o cualquier aplicación donde se requiera un cumplimiento estricto de reglas.
- Integridad de los datos:El esquema estricto impone reglas que evitan que los datos inválidos ingresen al sistema. Esto es crucial para el cumplimiento normativo y los registros de auditoría.
- Madurez:La tecnología es ampliamente comprendida. Las herramientas para visualización, depuración y mantenimiento son abundantes y estandarizadas.
- Cumplimiento ACID:Los sistemas relacionales suelen cumplir con Atomicidad, Consistencia, Aislamiento y Durabilidad. Esto garantiza que las transacciones se procesen de forma confiable, incluso en caso de fallas del sistema.
- Eficiencia de las uniones:Para datos profundamente normalizados con menos niveles de relaciones, unir tablas es eficiente y predecible.
Limitaciones a considerar
A pesar de sus fortalezas, los modelos relacionales enfrentan desafíos al manejar datos altamente interconectados. A medida que aumenta el número de relaciones, la complejidad de las uniones crece.
- Uniones complejas:Consultar datos que abarcan muchas tablas puede provocar una degradación del rendimiento. Cada unión añade una sobrecarga computacional.
- Rigidez del esquema:Cambiar la estructura de una base de datos relacional requiere a menudo scripts de migración. Esto puede ser arriesgado y consumir mucho tiempo en entornos de producción.
- Profundidad de modelado:Representar relaciones muchos a muchos o estructuras recursivas (como jerarquías organizacionales) requiere tablas de unión o claves auto-referenciadas, lo que puede complicar el diagrama y las consultas.
🕸️ El enfoque basado en grafos: las conexiones como primera clase
El modelado basado en grafos desplaza el enfoque desde los propios datos hacia las conexiones entre puntos de datos. En este enfoque, las relaciones se almacenan como enlaces explícitamente definidos, en lugar de inferirse mediante claves foráneas. Esto hace que el modelo de grafo sea especialmente adecuado para redes, estructuras sociales y motores de recomendación.
Principios fundamentales del modelado de grafos
- Nodos y aristas:Las entidades se representan como nodos y las relaciones como aristas. Cada nodo y arista puede contener propiedades, lo que permite metadatos ricos sin necesidad de tablas adicionales.
- Recorrido:Las consultas están diseñadas para recorrer caminos desde un nodo hasta otro. El motor de base de datos se optimiza para seguir enlaces en lugar de escanear tablas.
- Flexibilidad del esquema:Aunque los esquemas pueden ser obligatorios, los modelos de grafos permiten a menudo enfoques sin esquema o con esquema en la lectura. Se pueden añadir nuevos tipos de relaciones sin alterar toda la estructura.
- Coincidencia de patrones:Las consultas se centran en encontrar patrones específicos de conectividad. Esto es eficiente para encontrar amigos de amigos, caminos más cortos o características compartidas.
Fortalezas de los ERD de grafos
Los diagramas de grafos destacan cuando el valor del sistema reside en las conexiones entre entidades. Proporcionan una representación natural para redes complejas.
- Eficiencia de navegación:Recuperar datos a través de múltiples grados de separación es significativamente más rápido. La base de datos sigue los enlaces directamente sin escanear todo el conjunto de datos.
- Relaciones dinámicas:Añadir nuevos tipos de conexiones no requiere migraciones de esquema. Esto permite una iteración rápida y respuestas a requisitos empresariales en evolución.
- Claridad visual:Los ERD de grafos a menudo reflejan el modelo mental de los datos. Los interesados pueden ver fácilmente cómo se relacionan las entidades sin entender condiciones de unión complejas.
- Manejo de jerarquías profundas:Las relaciones recursivas, como categorías dentro de categorías, se representan de forma natural como cadenas de nodos y aristas.
Limitaciones a considerar
Los modelos de grafos no son una solución universal. Introducen desafíos específicos que deben gestionarse.
- Rendimiento de escritura:Aunque las lecturas son rápidas, mantener las relaciones durante escrituras de alto volumen puede ser más complejo que inserciones simples.
- Alcance de transacciones:Gestionar transacciones a través de un grafo distribuido puede ser más desafiante que actualizar filas en una sola tabla.
- Complejidad de consultas: Escribir consultas de recorrido eficaces requiere una mentalidad diferente a la de escribir uniones SQL. Implica comprender los algoritmos de búsqueda de caminos.
- Ecosistema de herramientas: Aunque crece, el ecosistema para la gestión de datos de grafos es más pequeño que el de los sistemas relacionales, lo que podría afectar la contratación y la disponibilidad de soporte.
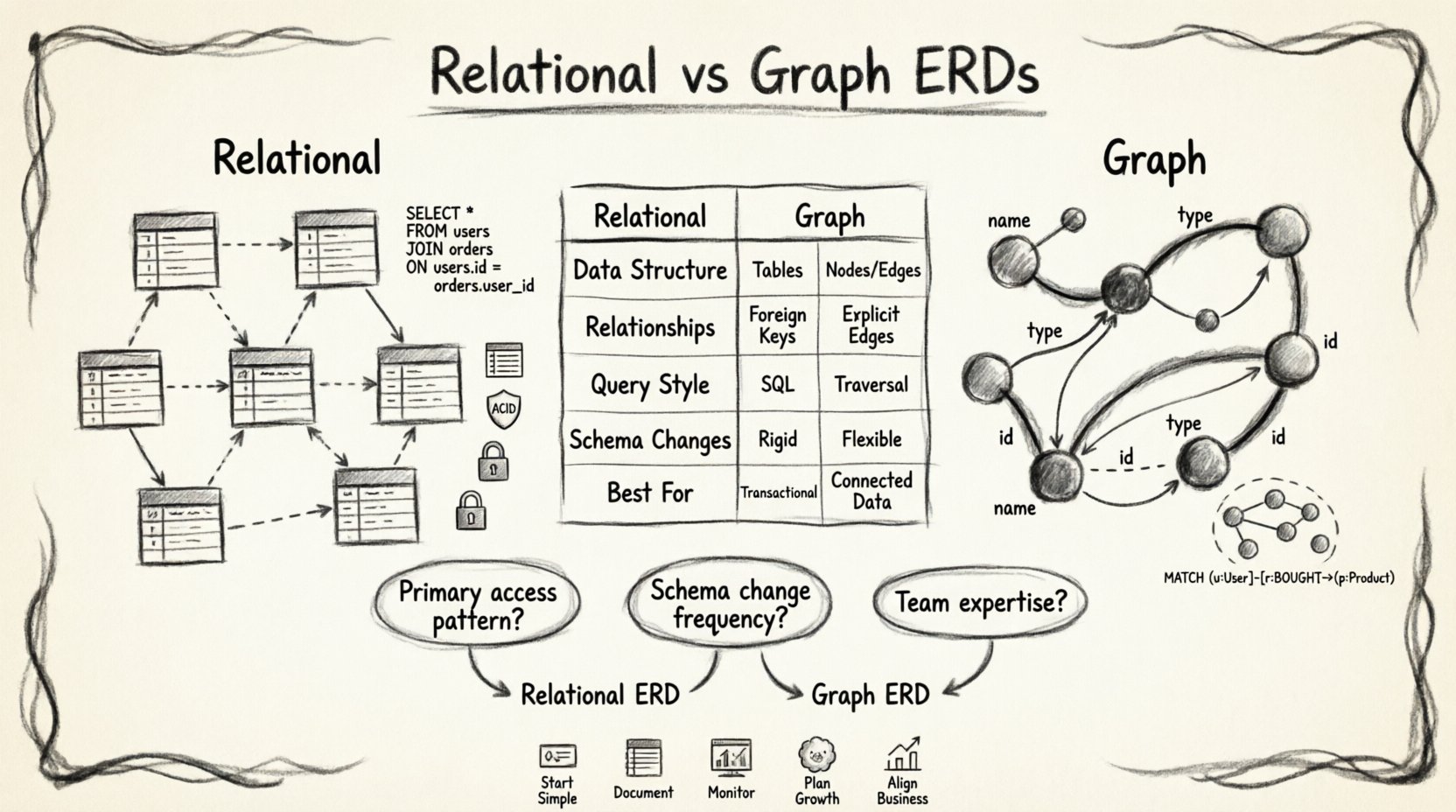
⚖️ Análisis comparativo: Diferencias clave
Para comprender claramente los compromisos, es útil ver los dos enfoques lado a lado. La siguiente tabla describe las principales diferencias a lo largo de dimensiones arquitectónicas comunes.
| Dimensión | Enfoque ERD relacional | Enfoque ERD basado en grafos |
|---|---|---|
| Estructura de datos | Tablas, filas, columnas | Nodos, aristas, propiedades |
| Almacenamiento de relaciones | Claves foráneas (implícitas) | Aristas explícitas (de primer orden) |
| Estilo de consulta | Declarativo (SQL) | Recorridos / coincidencia de patrones |
| Cambios de esquema | Costosos (migraciones) | Flexible (opciones sin esquema) |
| Mejor caso de uso | Datos transaccionales, estructurados | Datos en red, conectados |
| Aplicación de integridad | Restricciones estrictas | Nivel de aplicación o configurable |
| Escalabilidad | Escalabilidad vertical | Escalabilidad horizontal |
| Complejidad de la consulta | Altos Join = Más lento | Alta profundidad = Eficiente |
🛠️ Consideraciones de implementación
Elegir entre estos enfoques implica más que simples preferencias técnicas. Requiere una evaluación del ciclo de vida de la aplicación, la experiencia del equipo y los objetivos de mantenimiento a largo plazo.
Evolution y migración de esquemas
En un entorno relacional, evolucionar el esquema es un proceso deliberado. Añadir una columna o cambiar un tipo de datos a menudo requiere bloquear tablas o ejecutar scripts de migración. Esto puede afectar la disponibilidad. En contraste, los modelos de grafos permiten introducir nuevos tipos de relaciones sin afectar a los nodos existentes. Esta flexibilidad apoya ciclos de desarrollo ágiles donde los requisitos cambian con frecuencia.
Sin embargo, esta flexibilidad tiene un costo. Sin un cumplimiento estricto del esquema, la calidad de los datos puede degradarse con el tiempo. Los equipos deben implementar estrategias de gobernanza para garantizar que el grafo permanezca usable y consultable.
Rendimiento de consultas e índices
La optimización del rendimiento difiere significativamente entre los dos modelos. Los sistemas relacionales dependen de índices en columnas para acelerar las búsquedas. Al unir múltiples tablas, el optimizador determina el plan de ejecución más eficiente.
Los sistemas de grafos dependen de índices en nodos y aristas. El motor de recorrido sigue los punteros directamente. Para consultas que requieren anidamiento profundo, como «encontrar todos los proveedores que suministran piezas a productos que se envían a clientes en la región X», un modelo de grafo evita el costo exponencial de múltiples uniones.
Requisitos de consistencia de datos
Las aplicaciones que manejan dinero, registros médicos o contratos legales requieren una consistencia fuerte. Los modelos relacionales proporcionan mecanismos integrados para garantizar que cada transacción sea válida antes de confirmarse. Los modelos de grafos pueden soportar consistencia, pero a menudo requieren más configuración para lograr el mismo nivel de garantía en nodos distribuidos.
Integración con sistemas existentes
La mayoría de las organizaciones ya tienen una infraestructura relacional. Introducir un modelo de grafo a menudo requiere persistencia políglota. Esto significa mantener dos almacenes de datos diferentes y asegurarse de que permanezcan sincronizados. La capa de integración añade complejidad a la arquitectura.
🌐 Estrategias híbridas para aplicaciones modernas
Muchas aplicaciones modernas no encajan fácilmente en una sola categoría. Un enfoque híbrido a menudo proporciona el mejor equilibrio. Esta estrategia implica usar una base de datos relacional para datos transaccionales principales y un almacén de grafos para consultas intensivas en relaciones.
Microservicios y propiedad de datos
En una arquitectura de microservicios, diferentes servicios pueden poseer modelos de datos diferentes. El servicio de usuarios podría usar un modelo relacional para gestionar cuentas de forma segura. El servicio de recomendaciones podría usar un modelo de grafo para analizar preferencias y conexiones de usuarios. Esta separación permite que cada servicio se optimice para su carga de trabajo específica.
Patrones de sincronización
Mantener los dos almacenes sincronizados requiere un diseño cuidadoso. Se pueden usar arquitecturas basadas en eventos para propagar cambios. Cuando un registro se actualiza en el almacén relacional, se dispara un evento para actualizar los nodos correspondientes en el almacén de grafos.
- Captura de datos de cambio: Monitoreo del registro de transacciones de la base de datos relacional para detectar cambios.
- Captura de eventos: Almacenar los cambios de estado como una secuencia de eventos que pueden reproducirse para construir el estado del grafo.
- Procesamiento por lotes: Trabajos periódicos que reconstruyen el índice del grafo a partir de la fuente relacional.
📊 Marco de decisión
Al enfrentarse a la decisión de qué enfoque de ERD adoptar, considere las siguientes preguntas.
- ¿Cuál es el patrón de acceso principal? Si la aplicación necesita agrupar datos a través de muchas tablas, lo relacional suele ser mejor. Si la aplicación necesita recorrer relaciones, lo gráfico es superior.
- ¿Con qué frecuencia cambia el esquema?Los cambios frecuentes sugieren un enfoque de grafo o basado en documentos. Los esquemas estables se adaptan bien a los modelos relacionales.
- ¿Cuál es la tolerancia para la redundancia de datos?Los modelos relacionales minimizan la redundancia. Los modelos de grafo a menudo aceptan redundancia para acelerar las lecturas.
- ¿Cuál es la experiencia del equipo?El SQL relacional se enseña ampliamente. Los lenguajes de consulta de grafos requieren capacitación específica para que el equipo sea efectivo.
- ¿Cuáles son los requisitos de cumplimiento?Las industrias altamente reguladas suelen preferir la trazabilidad de los sistemas relacionales.
🔮 Tendencias futuras en modelado de datos
El panorama del modelado de datos sigue evolucionando. A medida que las aplicaciones se vuelven más complejas, las líneas entre los enfoques relacionales y de grafos podrían difuminarse aún más.
Híbridos grafo-relacionales
Algunas plataformas de bases de datos emergentes intentan combinar las fortalezas de ambos. Ofrecen tablas relacionales con capacidades nativas de recorrido de grafos. Esto permite a los desarrolladores utilizar un único motor para la integridad transaccional y el análisis de redes.
Diseño de esquemas impulsado por IA
La inteligencia artificial comienza a ayudar en el modelado de datos. Las herramientas pueden analizar patrones de uso y sugerir diseños de esquemas óptimos. Pueden recomendar cuándo normalizar los datos o cuándo introducir índices de relaciones.
Escalado nativo en la nube
La infraestructura en la nube está impulsando ambos modelos hacia el escalado horizontal. Las bases de datos relacionales distribuidas y los grupos de grafos distribuidos se están convirtiendo en estándar. Esto reduce la fricción del escalado y permite la distribución global de datos.
📝 Resumen de mejores prácticas
Independientemente del enfoque elegido, ciertos principios se aplican a todos los esfuerzos exitosos de modelado de datos.
- Empieza simple:No sobrediseñes el modelo inicial. Comienza con las entidades principales y añade complejidad a medida que evolucionen los requisitos.
- Documenta las relaciones:Documenta claramente la cardinalidad y la dirección de las relaciones. Esto es vital para alinear al equipo.
- Monitorea el rendimiento:Monitorea continuamente el rendimiento de las consultas. Un modelo que parece bueno en papel puede funcionar mal en producción.
- Planifica para el crecimiento:Diseña pensando en el escalado. Considera cómo el modelo manejará 10 veces o 100 veces el volumen actual de datos.
- Alinea con el negocio:Asegúrate de que el modelo de datos refleje el dominio del negocio. El diagrama debe contar la historia de la lógica del negocio.
Elegir entre ERDs relacionales y basados en grafos no se trata de encontrar la solución perfecta. Se trata de seleccionar la herramienta adecuada para el problema específico que se enfrenta. Al comprender las fortalezas y limitaciones de cada enfoque, los arquitectos pueden construir sistemas resilientes, eficientes y adaptables a necesidades futuras. La decisión depende finalmente de la naturaleza de los datos y de los requisitos operativos de la aplicación.