In the world of software architecture, few concepts carry as much weight as the Entity Relationship Diagram (ERD). It is the blueprint of your data, the map that guides developers through the complex landscape of tables, keys, and relationships. When an application lags, the first instinct is often to blame the schema. The assumption is clear: if the diagram is perfect, the performance must be perfect.
This is a common misconception. 🧐 While a well-designed ERD is foundational, it is not a silver bullet for speed. A flawless logical model does not automatically translate into a high-speed physical execution. Understanding the gap between design theory and runtime reality is crucial for building systems that remain responsive under pressure.
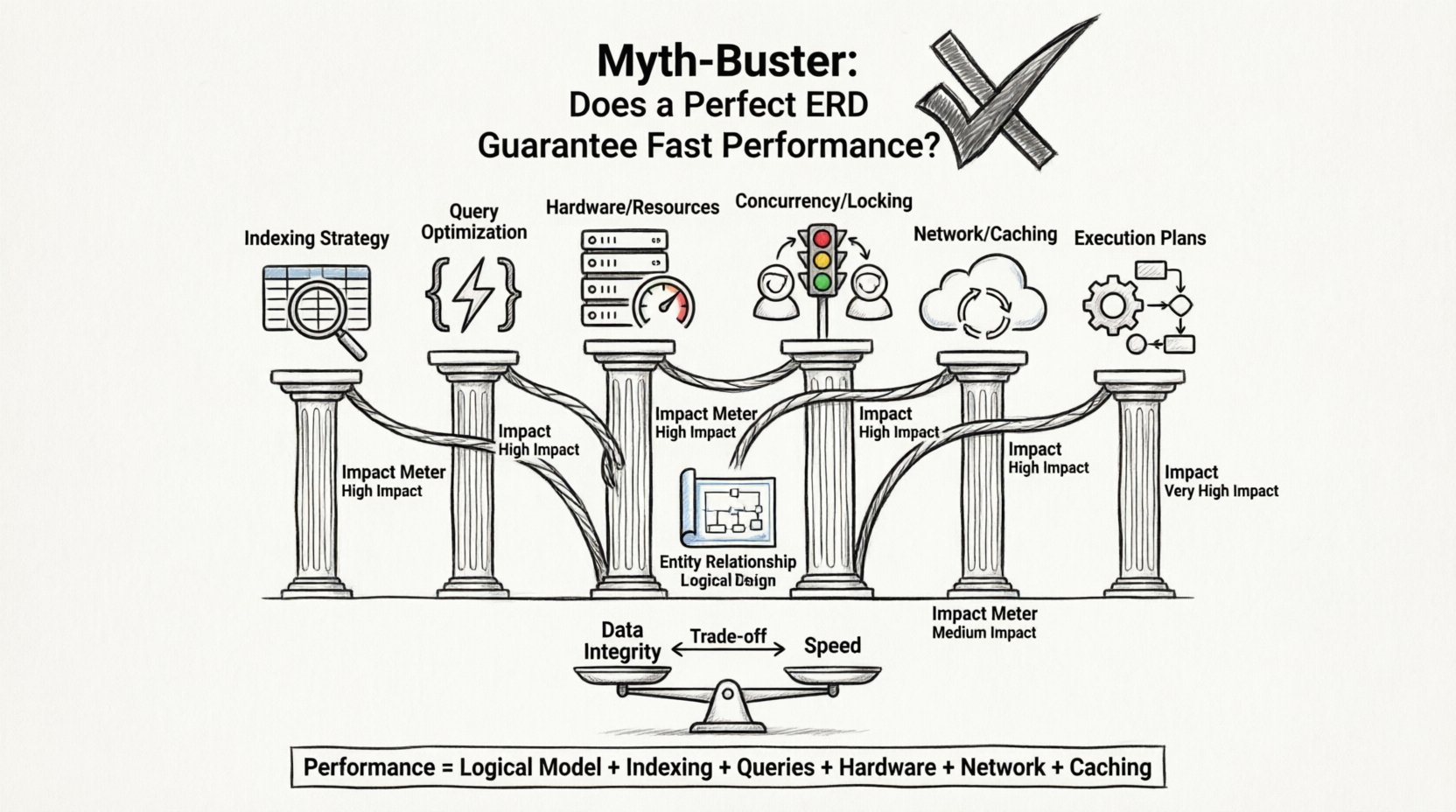
This guide explores why a perfect ERD does not guarantee fast response times and what other critical factors influence database performance. We will dissect the layers of data handling, from storage engines to network latency, to reveal the true drivers of application speed.
📐 Understanding the Entity Relationship Diagram
Before diving into performance metrics, we must clarify what an ERD actually represents. An ERD is a logical artifact. It describes what data exists and how it relates to other data. It defines entities (tables), attributes (columns), and relationships (foreign keys).
- Entities: Real-world objects represented as tables.
- Attributes: Characteristics of those objects stored in columns.
- Relationships: The links between entities, often enforced via primary and foreign keys.
- Cardinality: The numerical relationship between entities (one-to-one, one-to-many).
The primary goal of an ERD is data integrity. It ensures that data remains consistent, accurate, and usable over time. It prevents orphaned records and maintains referential integrity. However, integrity is not the same as velocity. A lock that holds a door shut protects the contents inside, but it does not make the door open faster.
⚡ The Performance Equation: Beyond the Schema
Application response time is the sum of many components. The database is just one part of this equation. Even if the database engine retrieves data instantly, the application may still feel slow due to bottlenecks elsewhere.
Here are the key factors that influence speed, often overshadowing the schema design:
1. Indexing Strategy
An ERD defines primary keys and foreign keys, which often generate indexes automatically. However, these default indexes are rarely sufficient for complex queries. Performance relies heavily on secondary indexes tailored to specific query patterns.
- Missing Indexes: Without an index on a frequently filtered column, the database must perform a full table scan. This reads every row, which is exponentially slower on large datasets.
- Index Overhead: Too many indexes slow down write operations. Every insert or update requires updating every index associated with that table.
- Selectivity: An index on a column with low selectivity (e.g., gender or status) may be ignored by the query optimizer.
2. Query Optimization
The way data is requested matters more than how it is stored. A poorly written query can cripple a perfect schema. Common issues include:
- N+1 Problems: Fetching a parent record and then looping through it to fetch children individually. This generates multiple round trips to the database instead of a single JOIN.
- SELECT * Usage: Retrieving all columns increases network traffic and memory usage, even if only one is needed.
- Implicit Conversions: Comparing a string to a number or a date to a timestamp can prevent the use of indexes.
- Complex JOINs: Joining multiple large tables without proper filtering increases the computational load significantly.
3. Hardware and Infrastructure
Software efficiency cannot overcome physical limitations. The underlying hardware dictates the ceiling for performance.
- Storage Type: Solid State Drives (SSDs) are significantly faster than Hard Disk Drives (HDDs) for random I/O operations.
- Memory (RAM): If the working set of data fits in RAM, queries are nearly instant. If data must be fetched from disk, latency increases.
- CPU Power: Complex calculations, sorting, and aggregation require processing power.
- Network Latency: The distance between the application server and the database server adds milliseconds to every request.
4. Concurrency and Locking
When multiple users access the system simultaneously, the database must manage conflicts. This is where performance often degrades.
- Lock Contention: If one transaction holds a lock on a row, others must wait. High contention leads to timeouts and slow response times.
- Deadlocks: Two transactions waiting for each other can cause a system-wide halt.
- Isolation Levels: Higher isolation levels (e.g., Serializable) provide stronger guarantees but reduce concurrency and speed.
📊 ERD Impact vs. Other Performance Factors
To visualize the influence of the ERD compared to other variables, consider the following breakdown. This table highlights where the ERD provides value and where it falls short.
| Factor | Impact on Read Speed | Impact on Write Speed | Role of ERD |
|---|---|---|---|
| Table Schema Structure | Medium | Medium | Defines relationships and normalization. |
| Indexing | High | Low | ERD defines keys, but not all indexes. |
| Query Logic | Very High | Medium | ERD does not dictate query syntax. |
| Hardware Resources | High | High | None. Independent of schema. |
| Network Latency | High | Medium | None. Independent of schema. |
| Connection Pooling | Medium | Medium | None. Application configuration. |
🧱 The Normalization Trade-Off
One of the most debated topics in database design is normalization. The ERD typically aims for Third Normal Form (3NF) to reduce redundancy. While this saves space and ensures consistency, it can hurt performance.
When data is highly normalized, a single piece of information is stored in one place. To retrieve it, the system must traverse multiple JOINs. Each JOIN adds computational overhead.
Consider a scenario where you need to display a user’s profile along with their latest order and the product details. In a normalized ERD, this might require joining four tables. If these tables are large, the CPU spends significant time sorting and matching rows.
Denoormalization is a technique used to counter this. It involves duplicating data to reduce the need for JOINs. This improves read speed but complicates write operations and risks data inconsistency. A perfect ERD does not automatically decide where to draw this line. It is a strategic decision based on read/write ratios.
🔍 Deep Dive: Query Execution Plans
The database engine does not execute queries exactly as written. It analyzes the request and generates an Execution Plan. This plan determines the order of operations, which indexes to use, and whether to perform a scan or a seek.
An ERD provides metadata about the data types and constraints. However, the optimizer uses statistics about data distribution to make decisions. If the statistics are outdated, the optimizer might choose a suboptimal plan, ignoring the best indexes available.
For example, if a table has 10 million rows but the statistics think it has 100, the optimizer might decide a full scan is cheaper than an index seek. This leads to slow performance despite a well-structured ERD.
🛡️ Data Integrity vs. Speed
There is an inherent tension between ensuring data integrity and maximizing speed. An ERD enforces integrity rules like constraints and triggers.
- Foreign Key Constraints: Ensure referential integrity. On delete or update, the system must check related tables. This adds latency to write operations.
- Triggers: Automated scripts that run on data changes. While useful for logic, they add processing time to every transaction.
- Unique Constraints: Require the system to check existing values before inserting new ones.
In high-throughput systems, these checks are sometimes disabled or deferred to improve speed. A perfect ERD includes all these rules, but a high-performance system might require a modified approach.
🚦 Practical Steps for Optimization
If your application is slow, do not immediately redraw your ERD. Follow a systematic approach to identify the bottleneck.
1. Analyze Slow Queries
Enable query logging to capture long-running statements. Use profiling tools to see where time is spent. Is it waiting on locks? Is it scanning rows? Is it processing logic?
2. Review Index Usage
Check which indexes are actually being used. Unused indexes consume storage and slow down writes. Create indexes that match the WHERE and JOIN clauses of your frequent queries.
3. Optimize Hardware Allocation
Ensure the database server has enough RAM to cache the working set. If the database is memory-bound, adding more RAM will yield immediate results. If it is CPU-bound, you may need to upgrade the processor or optimize the code.
4. Implement Caching
Not every request needs to hit the database. Use an in-memory cache (like Redis or Memcached) for frequently accessed data. This bypasses the database entirely for read operations.
5. Monitor Concurrency
Watch for lock waits. If users are experiencing timeouts, review transaction lengths. Keep transactions short to release locks quickly.
🔄 The Role of Schema Evolution
Applications change. Requirements shift. The ERD must evolve with the business. A schema that was perfect six months ago may be obsolete today due to new features or increased data volume.
Migration strategies matter. Moving data from a small table to a large partitioned table can improve performance. Changing data types from VARCHAR to INT can reduce storage and improve scan speeds. These decisions happen after the initial ERD is created.
Static ERDs do not account for data growth. As data scales, the performance characteristics change. A design that worked with 10,000 records might fail with 10 million. This is why performance tuning is an ongoing process, not a one-time task.
🧩 NoSQL Considerations
The concept of an ERD applies most strictly to relational databases. In NoSQL environments, the data model is different. Document stores, key-value stores, and graph databases handle relationships differently.
In a document store, data might be embedded to avoid joins. This mimics denormalization by design. In a graph database, relationships are first-class citizens, stored explicitly to optimize traversal.
The myth of the ERD guarantee is even more pronounced here. In NoSQL, the schema is often flexible or dynamic. Performance depends heavily on the access patterns defined in the application code rather than a rigid diagram.
🏁 Final Thoughts on Data Architecture
Building a fast application requires a holistic view. The ERD is a critical starting point, ensuring data is organized logically. It prevents chaos and maintains integrity. However, it is not the engine that drives speed.
Performance is the result of a synergy between:
- A solid logical model.
- Strategic indexing.
- Efficient query writing.
- Adequate hardware resources.
- Proper network configuration.
- Effective caching strategies.
Blaming the schema for slow response times is a shortcut that leads to the wrong fixes. A perfect diagram on paper cannot compensate for a slow disk, a network timeout, or a poorly written query. True performance engineering involves looking beyond the blueprint to the actual flow of data.
When you audit your system, start with the ERD to ensure correctness. Then, move to the execution plan to ensure efficiency. Finally, evaluate the infrastructure to ensure capacity. Only by addressing all layers can you achieve the responsiveness users expect.