











Die Datenbankleistung ist oft unsichtbar, bis sie zu einem kritischen Engpass wird. Wenn Benutzer Verzögerungen, Timeouts oder nicht reagierende Oberflächen erleben, liegt der Ursprung häufig unter der Oberfläche der Anwendungsschicht. Er befindet sich in der Architektur der Daten selbst. Der Leitfaden, der steuert, wie Daten strukturiert, miteinander verknüpft und gespeichert werden, ist das Entitäts-Beziehungs-Diagramm (ERD). Ein gut gestaltetes ERD gewährleistet Datenintegrität und effiziente Abrufvorgänge. Im Gegensatz dazu führt ein fehlerhaftes Diagramm zu Latenz, die durch keine Menge an Anwendungscaching vollständig behoben werden kann.
Diese Anleitung bietet einen tiefen Einblick in die Fehlersuche bei langsamen Abfragen durch Analyse des zugrundeliegenden Schema-Designs. Wir werden untersuchen, wie strukturelle Entscheidungen innerhalb des ERD die Abfrageausführungspläne, I/O-Operationen und die Gesamtreaktionsfähigkeit des Systems direkt beeinflussen. Durch das Verständnis der Mechanismen der relationellen Gestaltung können Sie Leistungsprobleme an ihrer Quelle diagnostizieren, anstatt nur Symptome zu behandeln.
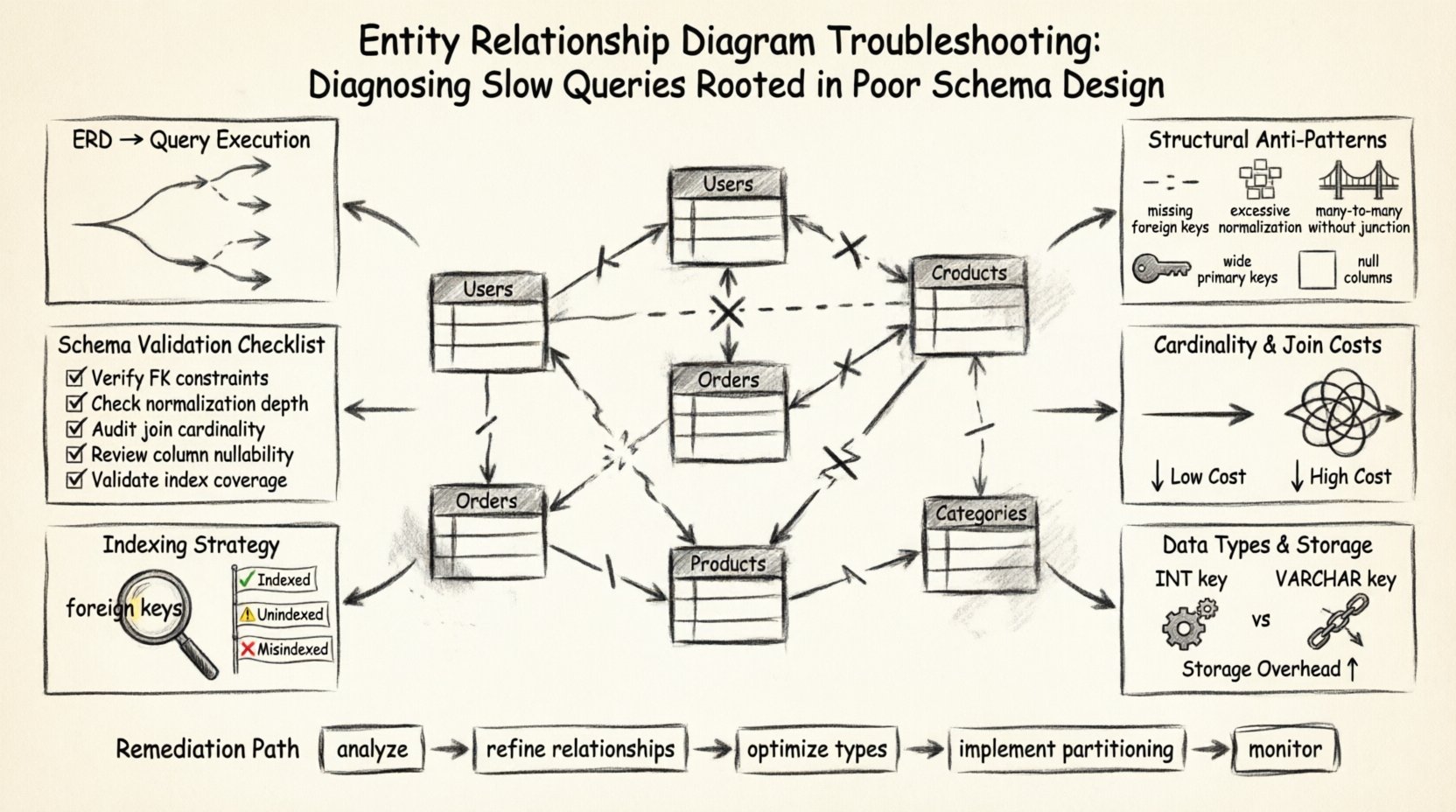
🏗️ Die Grundlage: Wie ERDs die Abfrageausführung beeinflussen
Bevor ein Problem diagnostiziert wird, ist es entscheidend, die Beziehung zwischen der visuellen Darstellung der Daten und der physischen Ausführung von Befehlen zu verstehen. Ein ERD ist nicht lediglich ein Diagramm zur Dokumentation; es ist eine Reihe von Regeln, die die Datenbankengine erzwingen muss. Jede Linie zwischen Tabellen, jede definierte Einschränkung und jedes spezifizierte Datentyp bestimmt, wie der Speicher-Engine Informationen liest und schreibt.
Wenn eine Abfrage eingereicht wird, analysiert der Datenbank-Optimierer die Anfrage anhand der Schema-Metadaten. Wenn das Schema mehrdeutig oder ineffizient ist, kann der Optimierer einen suboptimalen Pfad wählen. Dies äußert sich oft als vollständige Tabellen-Suche statt eines Index-Suchvorgangs oder als verschachtelte Schleifen-Verknüpfung, die die Verarbeitungszeit exponentiell erhöht.
Wichtige Bereiche, in denen das ERD die Leistung beeinflusst, sind:
- Verknüpfungs-Komplexität: Die Anzahl der definierten Beziehungen bestimmt die Anzahl der Verknüpfungen, die erforderlich sind, um verwandte Daten abzurufen.
- Integritätsbeschränkungen für Daten: Fremdschlüssel und eindeutige Beschränkungen fügen Schreibvorgängen Overhead hinzu, können aber Lesevorgänge optimieren.
- Normalisierungsstufen: Der Grad, in dem Daten über Tabellen verteilt werden, beeinflusst das Datenvolumen, das bei der Abrufung gescannt wird.
- Indexierungsstrategie: Das Schema-Design bestimmt, wo Indizes logisch platziert werden können, um häufige Abfragemuster zu unterstützen.
🔍 Identifizierung struktureller Anti-Muster
Viele Leistungsprobleme stammen aus Mustern, die während der ursprünglichen Entwurfsphase akzeptabel waren, aber mit wachsender Datenmenge zu Lasten werden. Diese Anti-Muster erscheinen oft subtil im Diagramm, verursachen aber erhebliche Reibung im Abfrage-Engine. Im Folgenden finden Sie eine Aufschlüsselung häufiger struktureller Fehler und ihrer direkten Auswirkungen auf die Geschwindigkeit.
| Anti-Muster | Visueller Indikator im ERD | Leistungsbeeinflussung |
|---|---|---|
| Fehlende Fremdschlüssel | Linien, die Tabellen verbinden, ohne dass Einschränkungen definiert sind. | Erlaubt verwaiste Datensätze, was dazu zwingt, komplexe Abfragen manuell zu filtern, um ungültige Daten zu entfernen. |
| Übermäßige Normalisierung | Hohe Anzahl von Tabellen mit Beziehungen über einzelne Spalten. | Erfordert übermäßige Verknüpfungen, um eine einzelne logische Entität wiederherzustellen, was die CPU-Auslastung erhöht. |
| Viele-zu-Viele ohne Zwischentabelle | Direkte Viele-zu-Viele-Beziehungslinien zwischen zwei Entitäten. | Datenbank-Engines erfordern typischerweise eine Brückentabelle; fehlt diese, führt dies zu ineffizienten Workarounds. |
| Breite Primärschlüssel | Komposite Schlüssel mit mehreren großen Spalten. | Erhöht die Größe aller Indizes, die auf diesen Schlüssel verweisen, und verlangsamt die Abfragen. |
| Null-gefüllte Spalten | Attribute, die ohne logischen Grund als nullbar markiert sind. | Kann die Verwendung von Indizes verhindern oder die Selektivität von Indizes verringern, was zu vollständigen Durchsuchungen führt. |
🔗 Beziehungskardinalität und Join-Kosten
Die Kardinalität definiert, wie viele Instanzen einer Entität mit Instanzen einer anderen Entität verknüpft sind. Dies ist der entscheidende Aspekt des ERDs im Hinblick auf die Abfrageleistung. Falsche Kardinalitätsdefinitionen zwingen das System dazu, mehr Zeilen zu verarbeiten, als notwendig sind, um eine Abfrage zu erfüllen.
Beim Beheben von langsamen Abfragen müssen Sie sicherstellen, dass die Beziehungen im Diagramm den logischen Anforderungen der Anwendung entsprechen. Wenn eine Beziehung als Many-to-Many definiert ist, obwohl sie One-to-Many sein sollte, bereitet der Abfrage-Engine sich auf einen Join über eine Verbindungstabelle vor, die möglicherweise nicht existiert oder ineffizient befüllt ist.
Häufige Kardinalitätsprobleme
- Undefinierte Kardinalität: Wenn das Diagramm nicht angibt, ob eine Beziehung obligatorisch oder optional ist, kann der Abfrage-Optimierer vom schlechtesten Fall ausgehen und zusätzliche Prüfungen auf Nullwerte hinzufügen.
- Rekursive Beziehungen:Selbstreferenzierende Tabellen (z. B. eine Mitarbeiter-Tabelle, die sich selbst für einen Manager referenziert) können zu tiefen Verschachtelungen in Abfragen führen. Ohne geeignete Indizierung der selbstreferenzierenden Spalte werden diese Abfragen exponentiell langsamer.
- Zirkuläre Abhängigkeiten:Komplexe Netzwerke von Beziehungen, bei denen Tabelle A auf B verweist, B auf C und C zurück auf A. Diese Struktur macht das Durchlaufen des Daten-Graphen für die Engine schwierig und führt oft dazu, dass temporäre Tabellen im Speicher erstellt werden.
Um diese Probleme zu mindern, stellen Sie sicher, dass das ERD klar zwischen optionalen und obligatorischen Verbindungen unterscheidet. Obligatorische Verbindungen ermöglichen es dem Optimierer, Null-Prüfungen zu überspringen, was die Ausführungszeit verbessert. Optionale Verbindungen erfordern zusätzliche Logik, um Fälle zu behandeln, in denen die Beziehung nicht existiert.
📏 Datentypen und Speichereffizienz
Die Wahl der Datentypen innerhalb der Schema-Definition hat einen tiefgreifenden Einfluss auf die Speichergröße und die Vergleichsgeschwindigkeit. Eine Abfrage, die zwei Spalten mit unterschiedlichen Typen vergleicht, löst oft implizite Umwandlungen aus. Diese Umwandlungen verhindern die Nutzung von Indizes und zwingen die Engine dazu, jede Zeile zu verarbeiten.
Speicherimplikationen
Wenn das Schema für alle Spalten einen generischen Datentyp verwendet, z. B. ein großes Textfeld für kurze Codes, verbraucht es mehr Festplattenspeicher und Arbeitsspeicher. Dies verringert die effektive Größe des Pufferpools, was bedeutet, dass weniger heiße Datenseiten im Speicher gehalten werden können. Folglich muss das System mehr Daten aus dem langsameren Festplattensubsystem lesen.
Vergleichsleistung
Integer-Vergleiche sind deutlich schneller als String-Vergleiche. Wenn das ERD einen Fremdschlüssel als Zeichenkette (z. B. VARCHAR) statt als Ganzzahl (z. B. INT) definiert, muss die Join-Operation Zeichen für Zeichen vergleichen, anstatt binäre numerische Vergleiche durchzuführen. Dies fügt für jede verarbeitete Zeile zusätzliche CPU-Zyklen hinzu.
- Verwenden Sie feste Längentypen: Verwenden Sie für Felder wie Ländercodes oder Status-Flags feste Längen-Strings. Variable Längen-Strings bringen Overhead mit sich, da die Länge bei jedem Lesen berechnet werden muss.
- Vermeiden Sie große Texte in Schlüsseln: Verwenden Sie niemals eine textreiche Spalte als Primär- oder Fremdschlüssel. Dies führt dazu, dass jeder Index, der darauf verweist, unnötig groß wird.
- Passen Sie Datentypen zwischen Eltern- und Kindtabelle an: Stellen Sie sicher, dass der Datentyp in der Kindtabelle genau dem der Elterntabelle entspricht. Selbst eine geringfügige Differenz (z. B. INT vs BIGINT) kann eine Umwandlung während Joins erzwingen.
🔑 Sichtbarkeit und Strategie der Indizierung
Ein ERD ist die visuelle Darstellung der logischen Struktur, sollte aber auch die physische Indizierungsstrategie beeinflussen. Obwohl Indizes oft nach der Erstellung des Schemas hinzugefügt werden, sollte die Entwurfsphase vorhersehen, wo sie benötigt werden. Eine Abfrage, die nach einer Spalte filtert, die nicht indiziert ist, ist ein primäres Indiz für eine Designlücke.
Indizierungsmöglichkeiten im ERD
Beim Überprüfen des Diagramms auf Leistungsengpässe sollten Sie nach Spalten suchen, die häufig in Suchbedingungen oder Joins verwendet werden.
- Fremdschlüssel: Diese sollten fast immer indiziert werden. Wenn eine Abfrage Table A mit Table B über einen Fremdschlüssel verknüpft und der Schlüssel in Table B nicht indiziert ist, muss die Engine für jede Zeile in Table A die gesamte Table B scannen.
- Status-Flags: Spalten, die den Zustand einer Aufzeichnung definieren (z. B. Is_Active, Order_Status), werden oft in WHERE-Klauseln verwendet. Wenn diese nicht indiziert sind, wird die Filterung zu einer vollständigen Tabellensuche.
- Datumbereiche: Tabellen mit Audit-Protokollen oder Transaktionsprotokollen fragen oft nach Datum ab. Die Datums-Spalte sollte indiziert werden, um effiziente Bereichssuchen zu ermöglichen.
Es ist entscheidend, die Anzahl der Indizes gegen die Schreibleistung abzuwägen. Jeder Index fügt Überhead für INSERT-, UPDATE- und DELETE-Operationen hinzu. Ein schlecht indiziertes, leseschweres Schema verursacht jedoch Systemverzögerungen, die die Schreibkosten überwiegen. Der ERD hilft dabei, sichtbar zu machen, welche Tabellen leseschwer (z. B. Abfrage-Tabellen) sind im Gegensatz zu schreibschweren (z. B. Transaktionsprotokolle), was die Entscheidung für Indizes leitet.
🚫 Das Join-Pathologie
Eine der häufigsten Ursachen für langsame Abfragen ist der Join-Pfad. Dies bezieht sich auf die Reihenfolge, in der die Datenbankengine Tabellen verknüpft, um eine Anforderung zu erfüllen. Ein schlecht gestaltetes Schema kann die Engine dazu zwingen, einen Pfad einzuschlagen, der logisch korrekt, aber rechnerisch kostspielig ist.
Kartesische Produkte
Wenn das Schema keine geeigneten Einschränkungen enthält oder wenn die Abfrage-Logik die Join-Bedingungen nicht korrekt angibt, kann die Engine ein kartesisches Produkt erzeugen. Dies geschieht, wenn jede Zeile in Table A mit jeder Zeile in Table B kombiniert wird. Die Ergebnismenge wächst exponentiell, und die Abfrage kann ablaufen oder allen verfügbaren Speicher verbrauchen.
Im ERD geschieht dies oft, wenn eine Many-to-Many-Beziehung nicht ordnungsgemäß durch eine Verbindungstabelle vermittelt wird, oder wenn die Verbindungstabelle notwendige Fremdschlüssel-Einschränkungen fehlen.
Unterabfrage im Vergleich zu Join
Die Schema-Design beeinflusst, ob eine Abfrage als einfacher Join ausgeführt werden kann oder eine Unterabfrage erfordert. Unterabfragen führen oft dazu, dass die innere Abfrage für jede Zeile der äußeren Abfrage einmal ausgeführt wird, was eine quadratische Zeitkomplexität verursacht. Ein normalisiertes Schema, das direkte Joins ermöglicht, wird im Allgemeinen einem de-normalisierten Aufbau vorgezogen, der Unterabfragen erzwingt.
✅ Schema-Validierungs-Checkliste
Um langsame Abfragen systematisch auf Basis des ERD zu beheben, führen Sie eine strukturierte Überprüfung durch. Diese Checkliste stellt sicher, dass Sie jedes kritische Element des Designs prüfen.
1. Fremdschlüssel-Einschränkungen überprüfen
- Sind alle Fremdschlüssel im Diagramm explizit definiert?
- Enthalten sie Kaskadenregeln, die unbeabsichtigte Datenbewegungen verursachen könnten?
- Ist der Datentyp auf beiden Seiten der Beziehung identisch?
2. Häufigkeit der Joins analysieren
- Identifizieren Sie Tabellen, die in der Anwendungslogik am häufigsten miteinander verknüpft werden.
- Sind diese Tabellen im Diagramm benachbart, oder erfordert der Pfad das Durchlaufen mehrerer Zwischentabellen?
- Können einige dieser Zwischentabellen zusammengefasst werden, um die Join-Tiefe zu reduzieren?
3. Prüfung der NULL-Zulässigkeit
- Sind Spalten, die niemals NULL sein können, explizit als NOT NULL markiert?
- Erlaubt das Schema NULL-Werte in Spalten, die Teil eines Indexes sind?
4. Datentypen überprüfen
- Werden numerische Felder mit der kleinsten geeigneten Größe verwendet (z. B. TINYINT gegenüber BIGINT)?
- Werden Textfelder mit der richtigen Länge verwendet, um Abkürzungen oder übermäßigen Speicherplatz zu vermeiden?
5. Prüfung der Indexabdeckung
- Haben Primärschlüssel und Fremdschlüssel Indizes?
- Sind häufig gefilterte Spalten indiziert?
- Gibt es einen zusammengesetzten Index für häufige Abfragen mit mehreren Spalten?
🛠️ Praktische Schritte zur Behebung
Sobald das ERD analysiert und Probleme identifiziert wurden, folgt die Phase der Behebung. Dabei wird das Schema so geändert, dass es den Leistungsanforderungen entspricht, ohne die Datenintegrität zu gefährden.
Beziehungen verfeinern: Wenn das ERD übermäßig komplexe Beziehungen zeigt, sollten diese vereinfacht werden. Dies könnte bedeuten, in bestimmten, lesedichten Bereichen eine Denormalisierung einzuführen, um die Notwendigkeit von Joins zu reduzieren. Zum Beispiel kann das Speichern einer zwischengespeicherten Anzahl von zugehörigen Elementen in der übergeordneten Tabelle die Notwendigkeit vermeiden, jedes Mal zu joinen und zu zählen.
Daten-Typen optimieren: Ändern Sie Daten-Typen in effizientere Alternativen. Wenn ein Datum nur für den Tag gespeichert wird, verwenden Sie einen Datumstyp ohne Uhrzeit anstelle eines Datums/Uhrzeit-Typs. Wenn eine ID numerisch ist, stellen Sie sicher, dass sie nicht als Zeichenkette gespeichert wird.
Partitionierung implementieren: Bei sehr großen Tabellen könnte das ERD eine Partitionierungsstrategie widerspiegeln müssen. Obwohl Partitionierung oft ein physischer Implementierungsdetail ist, sollte die logische Gestaltung berücksichtigen, wie die Daten gruppiert werden. Die Partitionierung nach Datum oder Region ermöglicht es dem System, nur die relevanten Datenabschnitte zu scannen.
🔎 Abschließende Überlegungen
Die Leistungsdiagnose ist ein iterativer Prozess. Das ERD dient als zentrales Artefakt in diesem Prozess. Indem man das Diagramm als lebendiges Dokument behandelt, das sowohl die logische Struktur als auch die physischen Leistungsbeschränkungen widerspiegelt, kann man ein Datenbanksystem aufrechterhalten, das auch bei wachsenden Datenbeständen reaktionsschnell bleibt.
Denken Sie daran, dass kein einziges Design für alle Szenarien geeignet ist. Eine für häufige Schreibvorgänge optimierte Schema kann sich anders verhalten als eine für komplexe analytische Abfragen optimierte. Ziel ist es, die Schema-Designs an die spezifischen Zugriffsmuster Ihrer Anwendung anzupassen. Überprüfen Sie das ERD regelmäßig anhand tatsächlicher Abfrageleistungsmetriken, um Abweichungen frühzeitig zu erkennen.
Durch die Fokussierung auf die strukturelle Integrität des Datenmodells beseitigen Sie die Ursachen für Latenz. Dieser Ansatz ist nachhaltiger als das Anbringen von Patches auf der Anwendungsebene. Eine solide Schema-Grundlage stellt sicher, dass das System über die Zeit skalieren, sich anpassen und zuverlässig funktionieren kann.
Führen Sie die Überwachung der Abfrage-Ausführungspläne weiterhin durch, nachdem Änderungen vorgenommen wurden. Die Visualisierung des Ausführungsplans kann bestätigen, dass der Optimierer die neuen Indizes und Einschränkungen korrekt nutzt. Dieser Feedback-Loop schließt den Fehlerbehebungszyklus ab und stellt sicher, dass die theoretischen Verbesserungen im ERD in greifbare Leistungsverbesserungen in der Produktionsumgebung umgesetzt werden.