











Die Datenmodellierung ist oft der unsichtbare Rückgrat jeder Softwareanwendung. Während der Code, der die Geschäftslogik ausführt, im Rampenlicht steht, bestimmt das darunterliegende Schema Leistungsfähigkeit, Skalierbarkeit und Wartbarkeit. Für viele Junior-Entwickler ist das Entitäts-Beziehungs-Diagramm (ERD) eine einfache Übung, bei der man nur Kästchen zeichnet und Linien verbindet. Diese Einfachheit ist jedoch trügerisch. Ein schlecht konstruiertes ERD erzeugt eine Schuldenlast, die sich im Laufe der Zeit vergrößert und zu komplexen Abfragen, Datenintegritätsproblemen und schwierigen Migrationen führt.
Dieser Leitfaden untersucht die versteckte Komplexitätslücke. Er zeigt auf, wo der Bruch zwischen theoretischem Wissen und praktischer Anwendung entsteht. Durch das Verständnis dieser Fallstricke können Entwickler über die einfache Diagrammierung hinaus zu echtem architektonischem Denken gelangen.
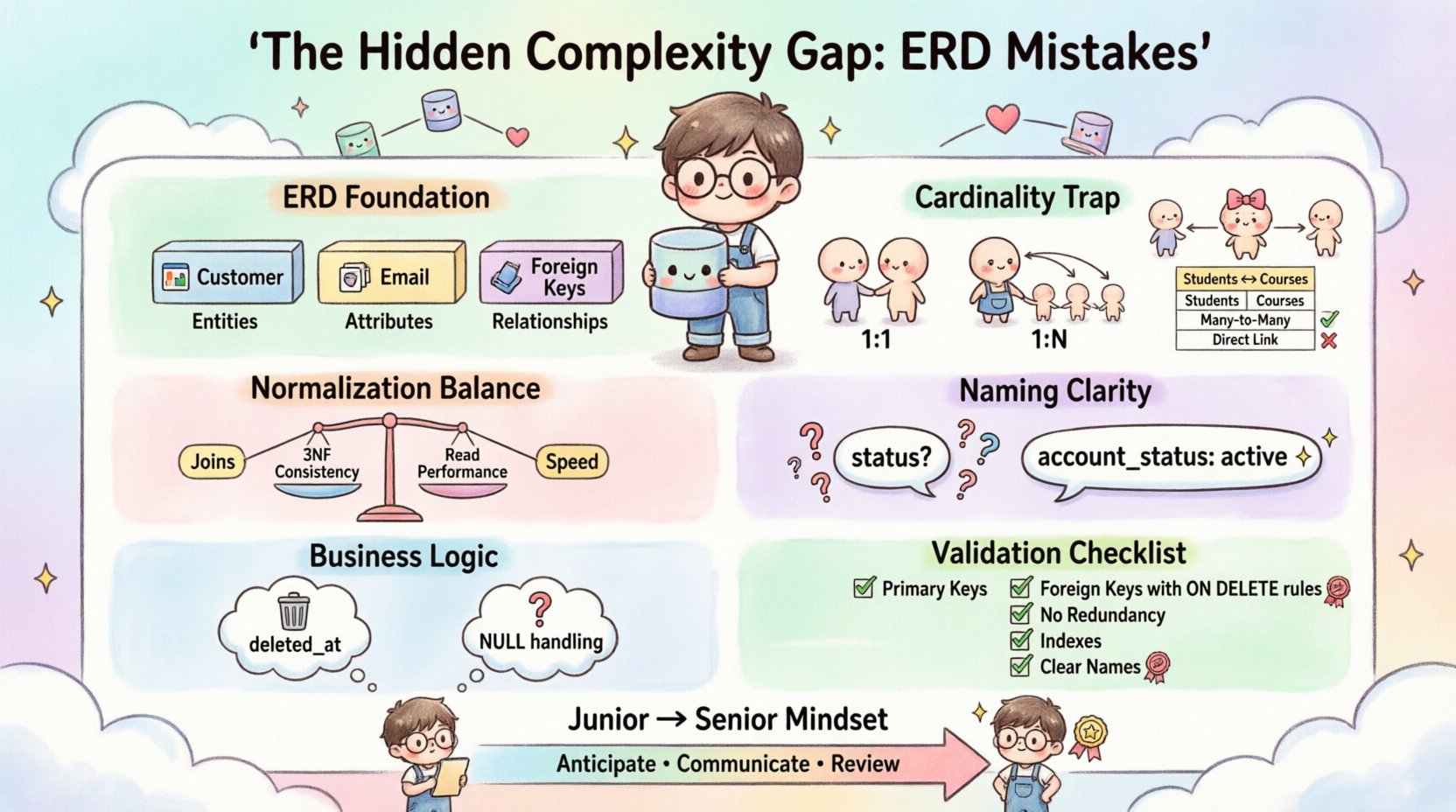
1. Das Fundament der Datenmodellierung verstehen 🏗️
Bevor man sich mit Fehlern beschäftigt, ist es unerlässlich, klarzustellen, was ein ERD eigentlich darstellt. Es ist nicht einfach nur eine Zeichnung; es ist ein Vertrag zwischen der Anwendung und der Speicher-Ebene. Ein ERD visualisiert Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Fremdschlüssel).
Wenn ein Ingenieur dies als statisches Artefakt betrachtet, das einmal erstellt und danach vergessen wird, verpasst er die dynamische Natur der Daten. Datenmodelle entwickeln sich weiter, je nachdem, wie sich die Geschäftsanforderungen ändern. Ein Junior-Entwickler könnte sich auf die unmittelbare Funktion konzentrieren, beispielsweise die Speicherung des Namens eines Benutzers, und dabei übersehen, wie dieser Benutzer mit anderen Entitäten wie Bestellungen, Abonnements oder Protokollen interagiert.
- Entitäten: Sie stellen Gegenstände oder Konzepte der realen Welt dar (z. B. Kunde, Produkt, Rechnung).
- Attribute: Sie sind die Eigenschaften, die die Entität definieren (z. B. E-Mail, Preis, Datum).
- Beziehungen: Sie definieren, wie Entitäten miteinander interagieren (z. B. Eins-zu-Viele, Viele-zu-Viele).
Ein robustes Modell berücksichtigt zukünftiges Wachstum. Es berücksichtigt, wie ein „Kunde“ zu einem „Benutzer“ werden könnte oder wie ein „Produkt“ Varianten benötigen könnte. Das ursprüngliche Diagramm sollte flexibel genug sein, um diese Änderungen zu ermöglichen, ohne dass eine vollständige Neugestaltung erforderlich ist.
2. Die Kardinalitätsfalle: Falsche Interpretation von Beziehungen 🔄
Die Kardinalität ist die häufigste Ursache für strukturelle Fehler bei der Datenbankgestaltung. Sie definiert die numerische Beziehung zwischen Instanzen von Entitäten. Ein Missverständnis führt zu ineffizientem Speicherplatz und komplexer Join-Logik.
Häufige Kardinalitäts-Szenarien
Ingenieure neigen oft dazu, die offensichtlichste Beziehung zu wählen, ohne Randfälle zu berücksichtigen. Betrachten Sie die folgenden Szenarien, bei denen Annahmen zu Fehlern führen:
- Eins-zu-Eins (1:1):Häufig übermäßig verwendet. Wenn zwei Entitäten eine 1:1-Beziehung haben, sollten sie oft in einer einzigen Tabelle zusammengefasst werden, um die Join-Kosten zu reduzieren, es sei denn, eine strenge Sicherheits-Trennung ist erforderlich.
- Eins-zu-Viele (1:N): Die häufigste Beziehung. Ein einzelnes Eltern-Element steht in Beziehung zu mehreren Kind-Elementen. Der Fremdschlüssel muss auf der Kind-Seite stehen.
- Viele-zu-Viele (M:N): Hier vergrößert sich die Komplexitätslücke. Eine direkte M:N-Beziehung ist in einem relationalen Modell ohne eine Zwischentabelle physisch nicht möglich.
Tabelle: Fehler bei der Implementierung der Kardinalität
| Szenario | Falscher Ansatz | Richtiger Ansatz |
|---|---|---|
| Schüler und Kurse | Hinzufügen einer „CourseID“-Spalte zur „Student“-Tabelle | Erstellen einer „Student_Course“-Zwischentabelle |
| Aufträge und Produkte | Einbetten von Produktinformationen direkt in die Auftrags-Tabelle | Verknüpfen über eine OrderItems-Tabelle |
| Mitarbeiter und Abteilungen | Erlauben, dass ein Mitarbeiter mehreren Abteilungen ohne eine Verbindungstabelle angehört | Trennen der Abbildungsbeziehung |
Wenn Ingenieure versuchen, eine Many-to-Many-Beziehung durch Wiederholung von Daten in einer einzigen Tabelle zu erzwingen, führen sie Redundanz ein. Wenn sich der Preis eines Produkts ändert, muss er in jedem Auftragsdokument aktualisiert werden, in dem dieses Produkt erscheint. Dies verstößt gegen die Normalisierungsprinzipien und führt zu Wartungs-Albträumen.
3. Normalisierungsmythen und Realitätsprüfungen 📉
Normalisierung ist ein Standardkonzept, das in akademischen Ausbildungen vermittelt wird. Ziel ist es, Datenredundanz zu reduzieren und die Integrität zu verbessern. Allerdings normalisieren Junior-Entwickler oft bis ins Extreme (bis zu 5NF), ohne die Leistungsabwägungen zu berücksichtigen.
Die Falle der Übernormalisierung
Ein über-normalisierter Schema teilt die Daten in zu viele Tabellen auf. Obwohl dies Konsistenz gewährleistet, zwingt es die Anwendung, übermäßige Joins durchzuführen. Jeder Join fügt zusätzlichen Rechenaufwand hinzu. In Systemen mit hohem Datenverkehr kann dies zu einer Engstelle werden.
- 1NF (Erste Normalform):Atomare Werte. Keine Listen in einer einzelnen Zelle.
- 2NF (Zweite Normalform):Keine partiellen Abhängigkeiten. Alle nicht-schlüsselbasierten Attribute müssen auf den gesamten Primärschlüssel abhängen.
- 3NF (Dritte Normalform):Keine transitiven Abhängigkeiten. Attribute sollten nicht von anderen nicht-schlüsselbasierten Attributen abhängen.
Ein häufiger Fehler ist die Annahme, dass 3NF immer das Ziel ist. In einigen Fällen ist die De-Normalisierung eine bewusste Gestaltungsoption. Zum Beispiel vermeidet das Speichern einer „Gesamtbestellsumme“ direkt in der Auftrags-Tabelle die Berechnung der Summe der Artikel bei jeder Anzeige des Auftrags. Dies tauscht Schreibleistung gegen Leseleistung aus.
Tabelle: Normalisierung gegenüber De-Normalisierung
| Faktor | Normalisiert (3NF) | De-normalisiert |
|---|---|---|
| Datenredundanz | Niedrig | Hoch |
| Schreibgeschwindigkeit | Schnell | Langsam |
| Lesegeschwindigkeit | Langsam (mehr Joins) | Schnell |
| Datenintegrität | Hoch | Niedriger (erfordert Logik) |
Die Entscheidung, die Normalisierung aufzuheben, muss datengestützt sein. Sie sollte nicht willkürlich erfolgen. Ingenieure müssen die Abfrageleistung profilieren, bevor sie Tabellen zusammenführen. Blindes Folgen von Normalisierungsregeln ohne Kontext führt zu Systemen, die konsistent, aber langsam sind.
4. Namenskonventionen und semantische Klarheit 🏷️
Schema-Namen sind das Vokabular der Datenbank. Wenn das Vokabular mehrdeutig ist, wird das System für zukünftige Entwickler unverständlich. Dies ist ein häufiges Problem, bei dem technische Präzision der Kürze geopfert wird.
Ein Feld namens Status ist gefährlich. Was bedeutet es? Ist es ein aktives Konto? Eine ausstehende Zahlung? Ein gelöschtes Dokument? Ohne Kontext geht die Bedeutung verloren. Ebenso führt die Verwendung von Pluralnamen für Tabellen (z. B. Benutzer) im Gegensatz zu Singularnamen (z. B. Benutzer) zu Inkonsistenzen.
- Konsistenz: Wenn eine Tabelle
snake_caseverwendet, müssen allesnake_case. - Beschreibbarkeit: Verwenden Sie Namen, die die Daten beschreiben, nicht nur das Format. Vermeiden Sie generische Begriffe wie
tabelle1oderDaten. - Kontext: Fügen Sie den Entitätsnamen in den Beziehungsschlüssel ein, falls Mehrdeutigkeit besteht. Verwenden Sie
benutzer_idanstelle von einfach nuridwenn möglich.
Betrachten Sie die Situation eines Systems mit mehreren Benutzertypen: Administratoren, Kunden und Lieferanten. Eine einzelne Tabelle namens Benutzer könnte eine Rolle Spalte enthalten. Dies ist eine „Gott-Tabelle“. Ein besseres Vorgehen ist die Verwendung separater Tabellen oder einer klaren Vererbungsstrategie. Diese Unterscheidung wird entscheidend, wenn Berechtigungen und Datenzugriffsregeln zwischen den Rollen stark abweichen.
5. Ignorieren der Geschäftslogik in der technischen Gestaltung 🧠
Der größte Unterschied zwischen Junior- und Senior-Entwicklern ist das Verständnis der Geschäftslogik. Ein Junior-Entwickler könnte ein Schema erstellen, das den aktuellen Codeanforderungen perfekt entspricht, aber versagt, wenn sich die Geschäftsregeln ändern.
Der Missbrauch des „Weichen Löschen“
Viele Entwickler fügen einfach eine gelöscht_am Spalte zu einer Tabelle hinzu. Das funktioniert für einfache Fälle. Wenn jedoch ein Benutzer gelöscht wird, sollten dann deren zugehörige Protokolle ebenfalls gelöscht werden? Sollten ihre Finanzdaten aus Audit-Zwecken erhalten bleiben? Das ERD sollte diese Einschränkungen durch Constraints und Trigger widerspiegeln, nicht nur durch Anwendungscode.
Das „Null“-Problem
Die Zulassung von NULL-Werten ist oft eine Quelle verborgener Komplexität. In einigen Fällen ist NULL semantisch anders als eine leere Zeichenkette oder Null. Wenn ein Feld optional ist, sollte das ERD dies eindeutig anzeigen. Die Verwendung von NULL-Werten zur Steuerung der Logik wird jedoch abgeraten.
- Referenzielle Integrität: Fremdschlüssel sollten idealerweise nicht NULL sein, es sei denn, die Beziehung ist wirklich optional.
- Berechnungen: NULL-Werte breiten sich in Berechnungen aus und führen zu NULL-Ergebnissen. Dies kann Aggregationsabfragen stören.
- Indizes: Die Behandlung von NULL-Werten in Indizes variiert je nach Datenbank-Engine und kann die Abfrageleistung beeinflussen.
6. Der Wartungsaufwand schlechter Gestaltung 🔧
Technische Schulden gehen nicht nur um langsamen Code; es geht um strukturelle Starrheit. Ein schlecht gestaltetes ERD macht Änderungen schmerzhaft. Wenn eine neue Anforderung kommt, beispielsweise die Hinzufügung einer „Rechnungsadresse“, die von einer „Lieferadresse“ getrennt ist, muss der Ingenieur prüfen, ob das aktuelle Schema dies unterstützt.
Migration-Alpträume
Die Änderung des Schemas einer Produktionsdatenbank mit Millionen von Datensätzen erfordert sorgfältige Planung. Wenn das ERD nicht mit Migrationen im Blick entworfen wurde, kann die Änderung eines Spaltentyps oder das Aufteilen einer Tabelle das System stundenlang sperren. Diese Ausfallzeit beeinträchtigt Umsatz und Benutzervertrauen.
Strategien zur Minderung dieses Problems sind:
- Versionskontrolle für das Schema: Behandeln Sie die Datenbankstruktur wie Anwendungscode.
- Rückwärtskompatibilität: Fügen Sie Spalten vor dem Löschen hinzu. Behalten Sie alte Spalten bis zum Abschluss der Migration bei.
- Dokumentation: Der ERD sollte die Quelle der Wahrheit sein. Wenn er nicht mit der Datenbank übereinstimmt, ist die Datenbank falsch.
7. Praktische Prüfliste für die ERD-Validierung ✅
Um ein robustes Design zu gewährleisten, sollten Ingenieure eine Validierungs-Checkliste durchlaufen, bevor sie die Diagramm endgültig festlegen. Dieser Prozess hilft dabei, logische Fehler zu erkennen, bevor die Implementierung beginnt.
Validierung vor der Implementierung
| Prüfung | Frage | Bestehenskriterien |
|---|---|---|
| Primärschlüssel | Hat jede Tabelle einen eindeutigen Bezeichner? | Ja, Auto-Inkrement oder UUID |
| Fremdschlüssel | Sind Beziehungen explizit definiert? | Ja, mit ON DELETE/UPDATE-Regeln |
| Redundanz | Wird irgendeine Daten in mehr als einem Ort gespeichert? | Nein, es sei denn, die Denormalisierung ist bewusst |
| Skalierbarkeit | Kann dies das Zehnfache des aktuellen Datenvolumens bewältigen? | Indizes existieren auf Fremdschlüsseln |
| Lesbarkeit | Kann ein neuer Mitarbeiter den Ablauf in 5 Minuten verstehen? | Klare Namenskonventionen |
8. Werkzeuge im Vergleich zu Konzepten 🛠️
Es ist leicht, sich auf die Funktionen eines bestimmten Werkzeugs zu verlassen, um Gestaltungsprobleme zu lösen. Doch das Werkzeug ist dem Konzept untergeordnet. Egal, ob man ein visuelles Modellierungswerkzeug verwendet oder direkt SQL-Skripte schreibt, die zugrundeliegende Logik bleibt dieselbe.
Einige Ingenieure erstellen Diagramme, die optisch perfekt aussehen, aber syntaktisch im Zielfeld-Database unmöglich sind. Zum Beispiel erlauben einige Werkzeuge zirkuläre Abhängigkeiten in der visuellen Ebene, während der Datenbank-Engine sie ablehnen wird. Der Fokus muss auf den Regeln der relationale Integrität liegen, anstatt auf der Zeichenoberfläche.
- Visuelle Konsistenz: Verwenden Sie Standard-Symbole für Beziehungen (Crow’s Foot-Notation).
- Validierung: Führen Sie das Schema gegen eine Testdatenbank aus, um die Einschränkungen zu überprüfen.
- Zusammenarbeit: Überprüfen Sie das Diagramm mit Stakeholdern, die den Geschäftsbereich verstehen, nicht nur mit technischen Kollegen.
9. Realweltszenarien des Versagens ⚠️
Abstrakte Konzepte zu verstehen ist eine Sache; sie in der Praxis versagen zu sehen, ist etwas anderes. Nachfolgend finden Sie häufige Szenarien, bei denen eine schlechte ERD-Designführung zu greifbaren Problemen führt.
Szenario A: Die unendliche Schleife
Ein Entwickler erstellt eine Beziehung zwischen Benutzer und Teams bei dem ein Benutzer einer Gruppe angehört und eine Gruppe von einem Benutzer geleitet wird. Wenn der Fremdschlüssel auf dieselbe Tabelle verweist, ohne eine klare Wurzel zu haben, treten während der Einfügung zirkuläre Referenzfehler auf. Das ERD muss zwischen „Mitglied“- und „Leiter“-Beziehungen klar unterscheiden.
Szenario B: Der stille Datenverlust
Eine BestellungTabelle verweist auf eine ProduktTabelle. Die ON DELETEEinschränkung ist auf CASCADE. Wenn ein Produkt aus dem Katalog entfernt wird, werden alle zugehörigen Bestellungen gelöscht. Dadurch wird die historische Verkaufsdaten zerstört. Das ERD sollte die referenzielle Aktion explizit als RESTRICT oder SET NULL festlegen, je nach Geschäftsanforderung.
Szenario C: Die langsame Suche
Eine Tabelle wird mit einer nameSpalte erstellt. Ingenieure fragen diese Tabelle häufig ab, um Benutzer anhand ihres Namens zu finden. Ohne einen Index in der Entwurfsphase zu definieren, führt die Datenbank eine vollständige Tabellenabfrage durch. Das ERD sollte anzeigen, welche Spalten suchintensiv sind und Indizierung erfordern.
10. Entwicklung von einem Junior- zu einem Senior-Mindset 🚀
Der Übergang beinhaltet eine Verschiebung des Fokus von „Funktioniert es?“ zu „Skaliert es?“ und „Ist es wartbar?“.
- Voraussicht: Prognostizieren zukünftiger Anforderungen basierend auf Branchentrends.
- Kommunikation: Übersetzen technischer Beschränkungen in geschäftliche Risiken.
- Überprüfung: Nehmen Sie niemals an, dass ein Diagramm korrekt ist, ohne eine Peer-Review durchzuführen.
Junior-Engineer arbeiten oft isoliert. Senior-Engineer arbeiten zusammen. Das ERD ist ein Kommunikationswerkzeug. Es schließt die Lücke zwischen Entwicklern, Produktmanagern und Stakeholdern. Wenn das Diagramm verwirrend ist, werden die Erwartungen falsch ausgerichtet.
Abschließende Gedanken zur Datenintegrität 🎯
Die Erstellung einer Datenbank-Schema ist keine einmalige Aufgabe; es ist eine fortlaufende Disziplin. Die Komplexitätslücke besteht, weil die Konsequenzen hoch sind. Ein Fehler im Anwendungscode kann schnell behoben werden. Ein Fehler im Datenmodell erfordert oft eine Migration, Datenbereinigung und Ausfallzeiten.
Durch die Einhaltung strenger Modellierungsprinzipien, tiefes Verständnis der Kardinalität und die Priorisierung von Geschäftslogik gegenüber Bequemlichkeit können Ingenieure die Lücke schließen. Das Ziel ist nicht, ein perfektes Diagramm zu erstellen, sondern eine Grundlage zu schaffen, die die Entwicklung der Software unterstützt. Daten sind das wertvollste Gut, das eine Anwendung besitzt. Den Schutz ihrer Struktur ist die Verantwortung jedes Ingenieurs, der am Bauprozess beteiligt ist.
Nehmen Sie sich die Zeit, Ihre Diagramme zu überprüfen. Fragen Sie jede Beziehung. Überprüfen Sie jede Beschränkung. Die Zeit, die Sie in der Entwurfsphase investieren, spart Monate an Aufwand in der Wartungsphase.