









企业架构需要精确的定义,以确保系统按预期运行。数据是这种功能的基础。在ArchiMate框架内建模时,理解数据的存放位置以及它如何与应用程序交互至关重要。应用层为可视化信息处理方式提供了特定的上下文。本指南详细介绍了在此特定层中构建数据模型的方法。我们将探讨准确表示所需的关系、元素和最佳实践。
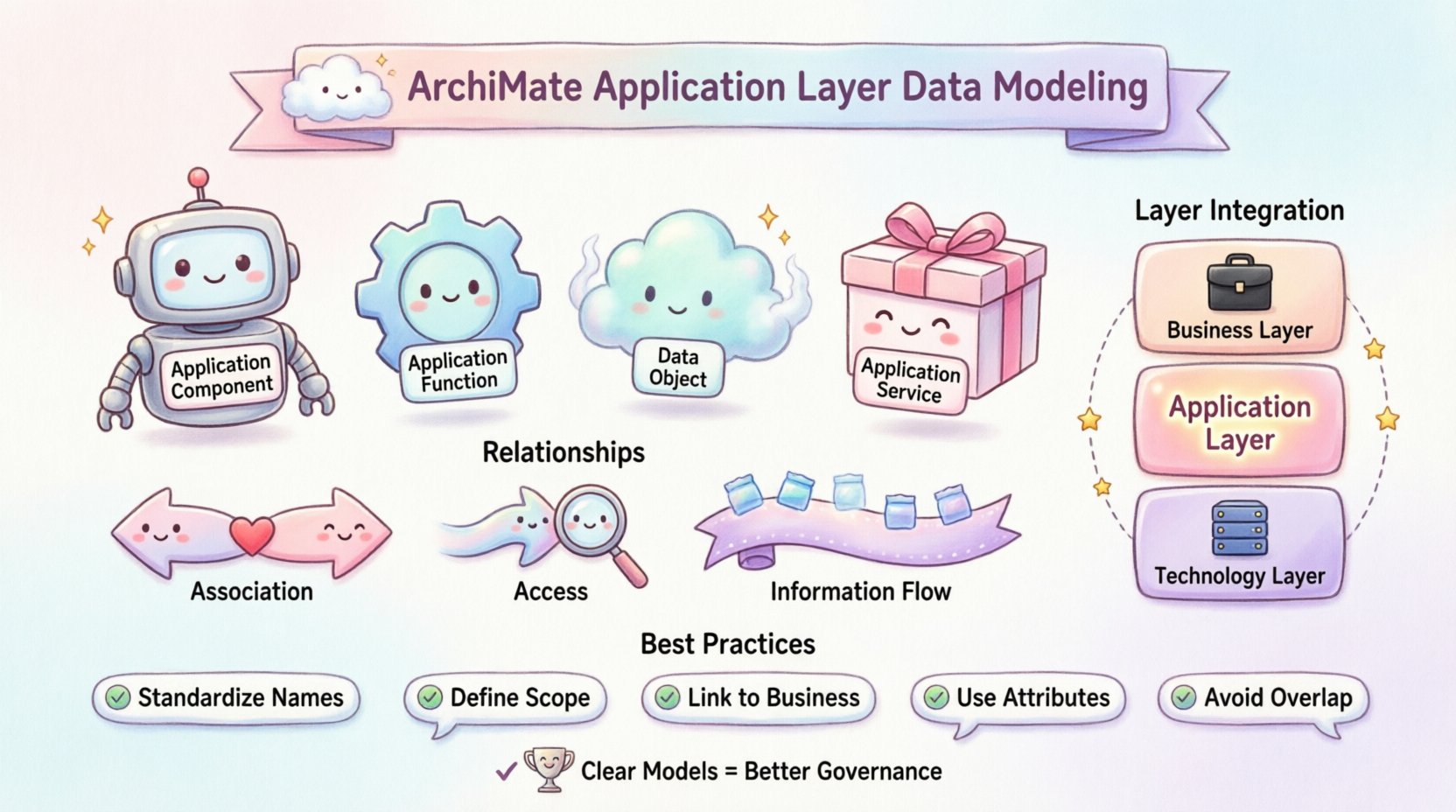
📊 应用层的上下文
应用层充当业务需求与技术实现之间的接口。它描述了为组织提供功能的软件组件和服务。与关注流程和角色的业务层不同,应用层关注的是数据处理的如何数据处理的如何。此层中的数据对象代表由特定应用程序管理的信息状态。
正确构建这些模型可以避免歧义。清晰的模型确保利益相关者了解哪个应用程序拥有哪些数据。这种清晰性有助于治理并减少技术债务。以下是此结构中涉及的核心组件:
- 应用组件: 一个可部署的软件单元,用于处理信息。
- 应用功能: 应用组件执行的逻辑功能。
- 数据对象: 应用程序所管理的信息状态或文档。
- 应用服务: 应用程序向外部世界提供的能力。
🔗 定义数据关系
关系定义了架构内数据的流动和依赖。在应用层中,特定的关系类型映射了信息在功能和组件之间的流动。理解这些映射对于追踪数据血统至关重要。
1. 与数据对象的关联
一个关联关系表示某个特定功能或组件与数据对象进行交互。这是数据建模中最常见的连接。它意味着该功能会读取、写入或修改数据对象。
- 方向: 通常为双向,尽管语义可能暗示流动方向。
- 使用场景: 用于表示所有权或直接访问。
- 示例: “客户管理功能”与“客户记录”数据对象相关联。
2. 访问关系
虽然与关联类似,但一个访问 关系指一个函数访问一个数据对象。这通常用于交互以读取为主的情况,或者当该函数是客户端,访问由另一个组件管理的数据存储时。
- 使用场景: 区分所有权和使用。
- 清晰性: 有助于识别哪个组件是事实的来源。
3. 信息流
信息流 描述数据从一个元素到另一个元素的流动。在应用层,这通常发生在函数之间,或函数与外部实体之间。
- 触发条件: 当特定事件发生时,数据流动。
- 格式: 流动携带特定类型的数据对象。
- 上下文: 有助于集成映射。
📝 将数据对象映射到函数
为了有效组织数据,必须将对象映射到操作它们的函数。这种映射创建了数据所有权的矩阵。下表概述了不同数据元素如何与应用函数交互。
| 数据元素类型 | 函数交互 | 关系类型 |
|---|---|---|
| 事务记录 | 处理函数 | 访问 |
| 主数据 | 管理函数 | 关联 |
| 日志文件 | 监控函数 | 访问 |
| 报告输出 | 报告函数 | 信息流 |
这种结构化方法有助于识别数据冗余。如果多个功能与同一数据对象相关联,则必须验证它们是否共享同一数据源,或者其中一个是否为副本。这种验证有助于保证数据的一致性。
🛠️ 建模的最佳实践
在构建这些模型时,一致性至关重要。遵循既定的规范可确保架构在长时间内依然易于理解。以下实践应融入建模过程。
- 标准化命名规范: 确保数据对象具有清晰且唯一的名称。避免使用未在其他地方记录的缩写。
- 明确界定范围: 判断数据对象是逻辑的还是物理的。应用层通常处理逻辑数据结构。
- 与业务层关联: 将数据对象追溯到业务对象。这确保了业务上下文得以保留。
- 使用属性: 为数据对象定义属性,以描述其结构,而不会使图表过于复杂。
- 避免重叠: 除非有特殊原因(例如逻辑与物理之分),否则不要在多个层级中对同一数据对象进行建模。
⚠️ 应避免的常见陷阱
即使经验丰富的架构师在建模数据时也会犯错。识别这些模式可以避免大量返工。以下是结构化过程中常见的问题。
1. 层级混淆
将业务对象直接放入应用层会造成混淆。业务对象属于业务层。应用层应包含代表这些业务概念实现的数据对象。
- 纠正方法: 通过实现关系将业务对象映射到数据对象。
- 影响: 层级混淆会模糊业务意图与系统功能之间的界限。
2. 过度建模
试图在应用层中记录数据库中的每一个字段会导致图表杂乱。该层的目的是展示能力与流程,而非详细的数据结构。
- 纠正方法: 使用高层次的数据对象。仅在技术规范需要时才深入到物理模型。
- 影响: 保持架构的可查看性和可维护性。
3. 忽视持久性
数据模型必须考虑持久性。某些数据是临时的(内存中),而其他数据是存储的(数据库中)。未能区分这两者可能导致对系统韧性的错误假设。
- 更正:请注意属性中的持久化机制,或通过单独的技术层映射。
- 影响:明确数据生命周期和恢复需求。
🔗 与其他层的集成
应用层并非孤立存在。它与业务层和技术层相连。适当的集成可确保架构的一致性。
与业务层的连接
应用层中的数据支持业务流程。一个实现关系将业务对象与应用数据对象关联起来。这证实了应用程序支持业务需求。
- 流程:业务流程创建业务对象 → 应用功能创建应用数据对象。
- 优势:确保从需求到实现的可追溯性。
与技术层的连接
应用层依赖技术层进行存储和计算。部署关系将应用组件映射到技术节点。应用层中的数据对象可能在技术层中实现为数据存储。
- 映射:应用数据对象 → 技术数据存储。
- 优势:验证技术基础设施是否支持逻辑数据需求。
📈 数据治理管理
模型结构化后,可作为治理的参考。数据治理策略可应用于模型中的各个元素,确保符合合规性和质量标准。
- 所有权:为模型中的特定数据对象指定数据所有者。
- 分类:根据敏感性对数据对象进行标记(例如:公开、内部、机密)。
- 保留:定义与数据对象相关的保留策略。
- 访问控制:将业务层的角色映射到访问数据的功能上。
这一治理层的价值超越了简单的可视化。它将架构模型转变为管理工具。定期审查这些模型,可确保治理策略与实际系统行为保持一致。
🧩 高级场景
有时,标准建模不足以应对复杂场景。高级情况需要仔细考虑关系和约束。
1. 复杂的数据转换
当数据经历重大转换时,可能涉及多个功能。一个功能可能读取原始数据并输出处理后的数据。
- 建模:使用两个不同的数据对象来表示输入和输出状态。
- 关联:通过转换功能将它们连接起来。
- 优势:清晰地展示了转换所增加的价值。
2. 共享数据资源
多个应用程序可能共享同一数据资源。这可能造成潜在的瓶颈或安全风险。
- 建模:创建一个单一的数据对象,并将其与多个应用功能关联。
- 分析:使用此视图分析竞争和锁定策略。
- 优势:突出显示依赖关系和共享风险。
3. 历史数据
应用程序通常需要存储数据的历史版本。这需要对基于时间的属性进行建模。
- 建模:向数据对象添加属性以表示版本控制或生效日期。
- 关系:确保功能正确处理更新逻辑。
- 优势:支持审计追踪和合规性要求。
🔍 审查与验证
在构建数据模型之后,必须进行验证。此过程确保模型准确反映目标状态。验证包括检查完整性、一致性和正确性。
- 完整性:所有关键数据对象是否都已表示?
- 一致性:模型中名称和定义是否一致?
- 正确性:关系是否准确反映了系统行为?
建议在此阶段引入领域专家。他们可以验证建模的流程是否符合实际的运行情况。这一反馈循环能够提高架构的准确性。
🔄 模型维护
架构不是一次性任务。系统会不断演进,数据模型也必须随之更新。维护工作包括跟踪变更并相应地更新模型。
- 变更管理:将架构更新整合到变更请求流程中。
- 版本控制:保留模型版本的历史记录,以追踪其演变过程。
- 文档:当模型元素发生变化时,更新相关文档。
模型与实际系统之间的定期同步可以防止偏差。当模型不再反映现实情况时,就会产生偏差,使其对规划失去作用。
📉 衡量成功
如何判断结构化工作是否成功?可以使用多个指标来衡量数据建模的有效性。
- 减少冗余:识别出更少的重复数据存储。
- 提升清晰度:利益相关者可以轻松追踪数据流。
- 更快的集成:新系统可以根据定义好的数据契约进行集成。
- 更好的治理:数据政策得到一致执行。
这些指标为架构工作提供了量化依据。它们展示了结构化数据模型对组织的价值。
🎯 关键要素总结
简要回顾一下,应用层数据模型依赖于特定的元素和关系。一个成功的模型能够无缝整合这些组件。
- 元素:应用组件、功能、服务和数据对象。
- 关系:关联、访问、信息流和实现。
- 层:业务层、应用层、技术层和动机层。
- 流程:定义、映射、验证和维护。
通过遵循这些原则,架构师可以创建强大的模型,以支持组织的数据战略。结果是清晰地展示了信息如何在技术环境中驱动业务价值。