











Designing the data architecture for a large-scale backend system is a foundational task that dictates the longevity and stability of the entire application. An Entity Relationship Diagram, commonly abbreviated as ERD, serves as the blueprint for this architecture. It visually maps out the structure of the data, defining how different pieces of information connect, relate, and interact within the system. In an enterprise context, where data consistency, integrity, and scalability are paramount, adhering to established ERD standards is not merely a best practice; it is a necessity.
Without a standardized approach to data modeling, backend systems risk becoming fragile. Inconsistent naming conventions, ambiguous relationships, and poor normalization can lead to performance bottlenecks, difficult maintenance cycles, and data corruption. This guide explores the critical standards and methodologies required to build robust database schemas suitable for complex enterprise environments. We will examine the core components, notation systems, normalization rules, and governance strategies that professional teams employ to ensure their data layers remain reliable over time.
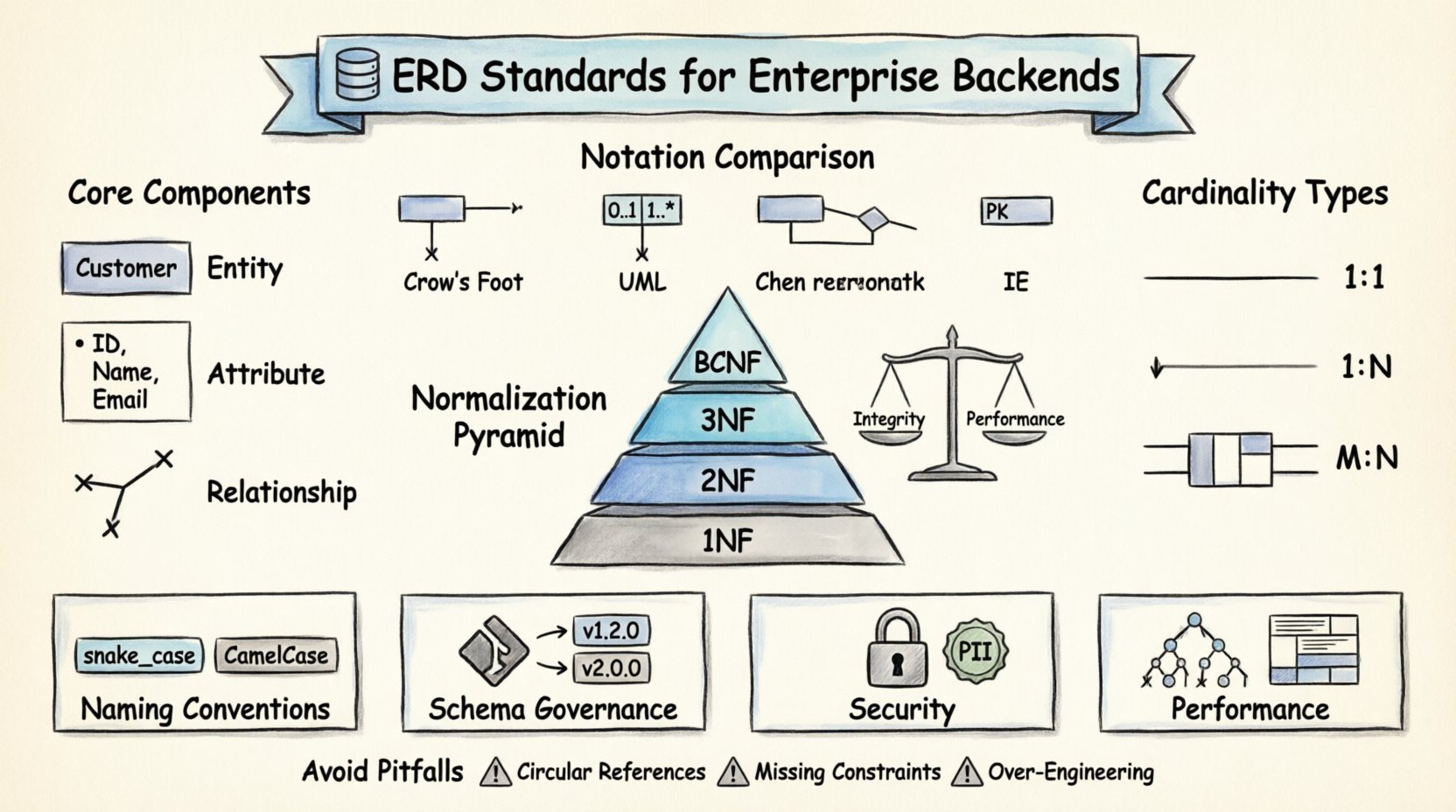
Core Components of an Enterprise ERD 🧩
Before diving into the specific standards, it is essential to understand the fundamental building blocks that constitute an ERD. Every diagram in a professional setting relies on three primary elements. These elements work in tandem to describe the logical structure of the data.
- Entities: These represent the real-world objects or concepts about which data is stored. In a backend context, an entity often maps directly to a database table. Examples include Customer, Order, or Product. Entities must be clearly defined to ensure that every record has a unique identity.
- Attributes: Attributes describe the specific properties or characteristics of an entity. They correspond to the columns within a table. For a Customer entity, attributes might include CustomerID, FullName, and EmailAddress. Properly defining data types for attributes is crucial for data integrity.
- Relationships: Relationships define how entities interact with one another. They establish the constraints and associations between tables. For instance, a single Customer can place multiple Orders. This relationship dictates the foreign key constraints and join logic required in the backend.
In enterprise-grade development, these components are not just abstract concepts; they are the basis for query optimization, access control, and data migration strategies. A well-documented ERD allows developers to understand the data flow without needing to inspect every line of code.
Notation Standards and Visual Conventions 📐
There is no single universal syntax for drawing ERDs, but there are widely accepted standards that ensure clarity and consistency across different teams. Choosing a notation and sticking to it is a critical governance decision.
Chen Notation vs. Crow’s Foot
Historically, the Chen notation was the standard, utilizing rectangles for entities and diamonds for relationships. While clear, it is less common in modern software development tools. The Crow’s Foot notation has become the industry preference for several reasons:
- Clarity in Cardinality: It uses specific symbols (lines, circles, and “feet”) to denote one-to-one, one-to-many, and many-to-many relationships visually.
- Tool Support: Most modern database design tools and reverse-engineering utilities support Crow’s Foot or UML-derived symbols natively.
- Readability: It is generally more compact and easier to read when dealing with complex, interconnected schemas.
Comparison of Notation Systems
| Notation Style | Entity Representation | Relationship Representation | Best Use Case |
|---|---|---|---|
| Crow’s Foot | Rectangle | Lines with symbols (crows foot, circle, line) | Relational Database Design |
| UML Class Diagram | Class Box with compartments | Arrows with multiplicities (0..1, 1..*) | Object-Oriented Modeling |
| Chen | Rectangle | Diamond shape connecting entities | Academic/Theoretical Models |
| IE (Information Engineering) | Rectangle with attributes | Lines with primary key indicators | Legacy System Documentation |
For enterprise backends, the Crow’s Foot notation is generally recommended due to its direct mapping to relational constraints. It minimizes ambiguity when developers interpret the diagram during implementation.
Normalization: Ensuring Data Integrity 🔄
Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. While modern systems sometimes denormalize for performance, understanding the normalization rules is essential for designing a sound initial schema.
The Normal Forms
- First Normal Form (1NF): Every column must contain atomic values. Lists of values in a single cell are prohibited. This ensures that every intersection of row and column holds a single, indivisible piece of data.
- Second Normal Form (2NF): The table must be in 1NF, and all non-key attributes must be fully dependent on the primary key. This prevents partial dependencies where a column depends on only part of a composite key.
- Third Normal Form (3NF): The table must be in 2NF, and there must be no transitive dependencies. Non-key attributes should not depend on other non-key attributes. For example, if City depends on ZipCode, and ZipCode depends on ID, City should be moved to a separate table.
- Boyce-Codd Normal Form (BCNF): A stricter version of 3NF. It requires that for every functional dependency X → Y, X must be a superkey. This handles certain edge cases in 3NF where a determinant is a candidate key but not the primary key.
Normalization Trade-Offs
| Level | Benefit | Cost |
|---|---|---|
| High Normalization (3NF/BCNF) | Minimal redundancy, high integrity | More joins required for queries |
| Low Normalization (Denormalized) | Faster read performance | Higher risk of data inconsistency |
Enterprise systems typically aim for 3NF in their transactional schemas. When read performance becomes a bottleneck, denormalization is applied selectively to specific views or reporting tables, rather than the core transactional schema.
Naming Conventions and Schema Hygiene 🏷️
A consistent naming convention is vital for maintainability. When multiple teams work on the same backend, ambiguity in naming leads to errors. A standard should be documented and enforced via linting tools or schema validation scripts.
Table Naming Rules
- Plural vs. Singular: There is a debate, but consistency is key. Plural names (e.g., Users, Orders) often read better in English sentences. Singular names (e.g., User, Order) are often preferred in object-oriented contexts. Select one and apply it globally.
- Underscores vs. CamelCase: Underscores (snake_case) are standard for SQL identifiers. CamelCase (camelCase) is common in application code. Ensure the database layer and application layer agree on the translation strategy.
- Avoid Reserved Keywords: Never name a table or column using reserved database keywords (e.g., Group, Select, Order). This prevents syntax errors during query generation.
- Prefixes for Metadata: Use prefixes like _audit, _log, or _temp to distinguish auxiliary tables from core business entities.
Column Naming Rules
- Foreign Keys: Clearly indicate the relationship. If a column references the Users table, name it user_id rather than uid or fk_user.
- Boolean Flags: Use prefixes like is_ or has_. For example, is_active or has_subscription.
- Datetime Fields: Specify the scope. Use created_at or updated_at instead of generic date or time.
Relationships and Cardinality 🔄
Understanding cardinality is the difference between a working database and a broken one. Cardinality defines the exact number of instances of one entity that can or must be associated with each instance of another entity.
Types of Relationships
- One-to-One (1:1): One instance of Entity A is associated with exactly one instance of Entity B. This is rare in core business logic but common for security or configuration data. Example: A User has one Profile.
- One-to-Many (1:N): One instance of Entity A is associated with many instances of Entity B. This is the most common relationship. Example: One Department has many Employees.
- Many-to-Many (M:N): Many instances of Entity A are associated with many instances of Entity B. This requires a junction table (associative entity). Example: Students and Courses.
Optionality and Constraints
Cardinality does not tell the whole story; optionality does. This refers to whether the relationship is mandatory or optional.
- Mandatory (Mandatory Participation): An entity instance must be associated with another. For example, an Order must have a Customer.
- Optional (Optional Participation): An entity instance may exist without a relationship. For example, a Product may exist without an Order record yet.
Enforcing these rules at the database level using constraints (NOT NULL, Foreign Keys) is far more reliable than enforcing them in application code. It protects against data drift and ensures that the schema remains the source of truth.
Schema Governance and Version Control 📜
In enterprise environments, the database schema is code. It must be versioned, reviewed, and managed with the same rigor as application source code. An ERD is not a static document; it evolves as the business requirements change.
Migration Strategies
- Forward Compatibility: Changes should be designed to accommodate old data. Avoid dropping columns immediately; instead, mark them as deprecated.
- Backward Compatibility: New schema versions should not break existing queries. Use views to abstract changes from the application layer.
- Atomic Changes: Each migration script should represent a single logical change. This makes rollbacks easier if an error occurs.
Documentation Maintenance
An ERD that is not updated is a liability. Ensure that the diagram generation process is automated. Ideally, the ERD should be generated directly from the schema definition files (DML) to prevent drift between the documentation and the actual database state.
- Automate ERD generation on every commit.
- Require schema review in the pull request process.
- Tag major schema versions to correlate with application releases.
Security and Privacy Considerations 🔒
Enterprise backends handle sensitive information. The ERD design phase must account for security and privacy requirements, particularly regarding Personally Identifiable Information (PII).
Data Classification
- Public Data: Information that can be shared openly. No special handling required.
- Internal Data: Information for employees only. Access control lists (ACLs) should be considered.
- Restricted Data: Sensitive data like passwords, health records, or financial details. These fields require encryption at rest and in transit.
Masking and Anonymization
In the ERD, mark fields that require masking in non-production environments. This helps developers understand which columns need special handling during testing. While the diagram itself does not enforce security, it guides the implementation of security policies.
- Identify columns containing PII explicitly.
- Define audit fields (e.g., last_modified_by) to track who accessed or changed data.
- Ensure foreign keys do not expose internal IDs that could be enumerated.
Performance and Scalability Planning 🚀
While the ERD focuses on structure, it must also consider performance. A schema that is logically sound but physically slow will fail under load.
Indexing Strategy
The relationships defined in the ERD dictate where indexes are needed. Foreign keys should be indexed to speed up joins and constraint checks. However, over-indexing can slow down write operations.
- Primary Keys: Always indexed.
- Foreign Keys: Always indexed to improve join performance.
- Search Columns: Columns frequently used in WHERE clauses should have indexes.
Partitioning and Sharding
For massive datasets, the ERD might hint at partitioning strategies. If data is naturally grouped (e.g., by Region or Date), this should be reflected in the schema design. This allows the database to distribute load across multiple physical nodes.
Common Pitfalls to Avoid ⚠️
Even experienced teams make mistakes. Recognizing common patterns of failure helps in building a resilient system.
- Circular References: Avoid relationships where Entity A depends on B, and B depends on A, creating a loop that complicates data deletion or updates.
- Missing Constraints: Relying on application code to enforce rules (e.g., ensuring a Price is positive) is risky. Use CHECK constraints in the database.
- Over-Engineering: Do not model every possible future scenario. Design for the current requirements with enough flexibility to adapt, but avoid creating tables for hypothetical use cases.
- Hardcoded Values: Avoid storing status codes as integers without a lookup table. Use a reference table for statuses like OrderStatus to maintain clarity.
Implementing Standards in Your Workflow 🛠️
Adopting these standards requires a shift in culture. It is not enough to simply draw a diagram; the diagram must drive the development process.
- Design First: Require the ERD to be approved before writing any migration scripts.
- Code Reviews: Include schema changes in the standard code review checklist.
- Training: Ensure all backend engineers understand normalization and cardinality concepts.
- Tooling: Invest in schema design tools that support collaboration and versioning.
By treating the Entity Relationship Diagram as a living, breathing component of the system architecture, enterprise teams can ensure their data layers remain robust. The effort invested in standardizing the design phase pays dividends in reduced technical debt and improved system reliability. A well-structured database is the bedrock upon which scalable applications are built.
When you prioritize clarity, consistency, and integrity in your data modeling, you create a foundation that supports growth. The standards outlined here provide a framework for that foundation. Following them ensures that your backend remains maintainable, secure, and efficient as your organization scales.