











When architects design data models, the Entity Relationship Diagram (ERD) serves as the foundational blueprint. It is not merely a visual representation of tables and columns; it is a specification of relationships, integrity, and flow. Among the most critical components within this structure are foreign keys. While often associated solely with data integrity, their impact extends deeply into performance metrics, storage efficiency, and query execution speed.
This analysis explores the technical mechanics of foreign keys within the context of ERD performance. We will examine how these constraints influence indexing strategies, locking mechanisms, and the overall scalability of the database schema. The goal is to provide a clear understanding of the trade-offs involved when defining relationships in a physical model.
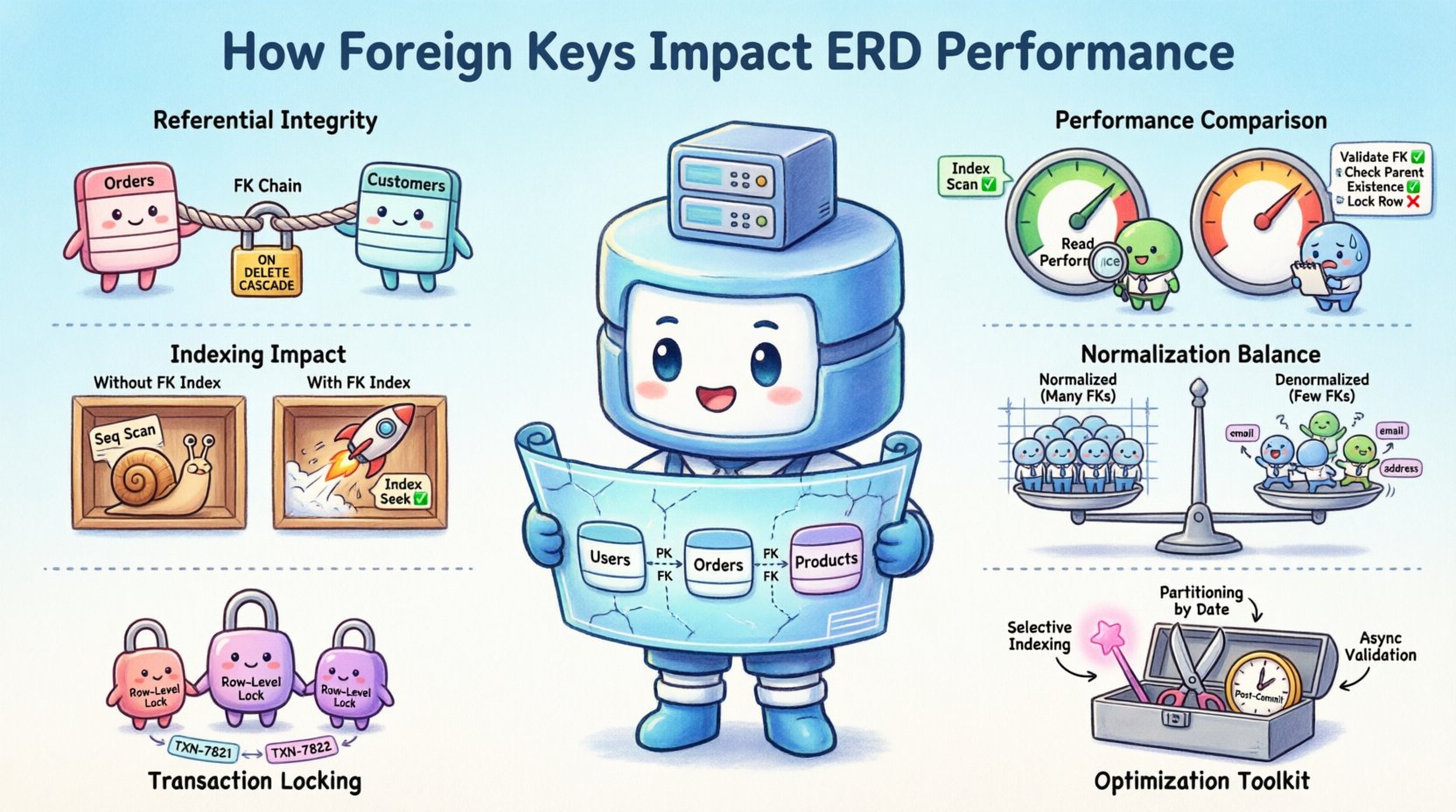
Understanding the Core Function of Foreign Keys ⚙️
A foreign key is a constraint that links a column in one table to the primary key of another. This linkage enforces referential integrity, ensuring that a record in the child table corresponds to an existing record in the parent table. However, the implementation of this constraint carries computational costs.
From a performance perspective, the foreign key acts as a signal to the database engine. It informs the query planner about the existence of a relationship, which can influence join algorithms. But it also introduces overhead during data manipulation.
- Insert Operations: When a new row is added to a child table, the engine must verify that the referenced parent key exists.
- Delete Operations: Removing a row from a parent table may require cascading updates or checks on dependent child records.
- Update Operations: Changing a primary key in a parent table necessitates updating every foreign key reference in the child tables.
These checks are not instantaneous. They require locking mechanisms to prevent race conditions where two transactions attempt to modify related data simultaneously. Consequently, the density of foreign keys in an ERD directly correlates with the complexity of transaction management.
Performance Metrics: Read vs. Write Workloads 📊
Database performance is rarely uniform across all operations. Foreign keys impact read and write workloads differently. Understanding this distinction is crucial for tuning schema design.
1. Read Performance (Query Execution)
When a query involves joining two tables, the presence of a foreign key relationship can assist the optimizer. If statistics are maintained, the engine can estimate the cardinality of the join more accurately. This often leads to better execution plans.
- Join Optimization: The query planner may choose hash joins or merge joins based on known cardinality constraints.
- Index Usage: Foreign keys often prompt the creation of indexes on the child table columns. These indexes accelerate lookups during joins.
- Cache Efficiency: Properly indexed foreign keys allow for more efficient page reads from memory, reducing disk I/O.
2. Write Performance (Data Manipulation)
Writes are where foreign keys introduce significant latency. Every insertion or update must validate the constraint.
- Lookup Overhead: The system must search the parent table index to confirm the key exists. This adds a read operation to every write.
- Cascading Costs: If cascading deletes or updates are enabled, a single action on a parent record can trigger updates across multiple child tables.
- Locking Contention: Foreign keys create dependencies between rows. If two transactions try to insert into the same parent, they may block each other waiting for the integrity check to complete.
The Indexing Relationship 🔗
One of the most common misconceptions is that foreign keys automatically create indexes. In many database engines, this is not the default behavior. However, relying on a foreign key without an index on the child column is a performance bottleneck.
Without an index on the foreign key column:
- The database must perform a full table scan to verify the existence of the parent key during inserts.
- Join operations between the parent and child tables will be significantly slower, often resorting to nested loop joins.
- Referential integrity checks become expensive as the dataset grows.
Conversely, adding an index to the foreign key column solves these issues but introduces its own costs:
- Storage Overhead: Every index consumes disk space and memory.
- Write Slowdown: Every time a row is inserted, updated, or deleted, the index must be modified.
- Fragmentation: Over time, indexes can become fragmented, requiring maintenance operations.
Table: Foreign Key Indexing Impact
| Factor | Without FK Index | With FK Index |
|---|---|---|
| Insert Speed | Slower (Full scan check) | Faster (Index lookup) |
| Join Speed | Slow (Nested Loops) | Fast (Hash/Merge Join) |
| Storage Usage | Low | Higher |
| Update Overhead | Low | High (Index maintenance) |
ERD Visualization and Complexity 🎨
An ERD is a tool for communication between developers, architects, and stakeholders. The density of foreign keys affects how readable the diagram is. A diagram cluttered with excessive relationships can obscure the core data flow.
1. Visual Clutter
When an entity has many outgoing or incoming foreign keys, the lines connecting them create a “spaghetti diagram” effect. This makes it difficult to trace data lineage or understand the core dependencies of a specific entity.
- Line Crossings: Too many relationships cause lines to cross, reducing clarity.
- Node Size: Entities with high relationship counts require larger bounding boxes, disrupting layout symmetry.
- Interpretation Time: Engineers spend more time deciphering the model rather than implementing logic.
2. Logical vs. Physical Models
It is often necessary to distinguish between the logical ERD and the physical schema. The logical model focuses on business rules and relationships. The physical model focuses on performance and implementation.
- Logical Level: All relationships should be represented to ensure business rules are captured.
- Physical Level: Some relationships may be removed or denormalized to improve query speed.
This separation allows the ERD to remain a valid business document while the underlying database is optimized for specific workload patterns.
Normalization and the Foreign Key Balance ⚖️
The decision to normalize a database involves introducing foreign keys. Normalization reduces redundancy and ensures data consistency. However, it increases the number of joins required to retrieve data.
Third Normal Form (3NF)
In 3NF, every non-key attribute depends on the whole key. This results in a schema with many tables and many foreign keys.
- Pros: Minimal data duplication, consistent updates, lower storage for text fields.
- Cons: Complex queries requiring multiple joins, potential performance degradation on read-heavy systems.
Denormalization Strategies
For high-performance reporting or read-heavy applications, denormalization is a viable strategy. This involves removing foreign keys and duplicating data.
- Materialized Views: Pre-calculated results stored as tables reduce the need for joins.
- Redundant Columns: Storing the name of a category directly in the transaction table avoids a join to the category table.
- Trade-off: You sacrifice write performance and increase storage to gain read speed.
Table: Normalization vs. Performance
| Aspect | Normalized (Many FKs) | Denormalized (Few FKs) |
|---|---|---|
| Data Integrity | High (Enforced by FK) | Low (Manual checks needed) |
| Query Complexity | High (Multiple Joins) | Low (Single Table) |
| Write Speed | Faster (Less Redundancy) | Slower (Update All Copies) |
| Read Speed | Slower | Faster |
Concurrency and Locking Mechanisms 🔒
Foreign keys introduce a specific type of locking behavior known as predicate locking or gap locking in certain database engines. When a transaction modifies a row that is referenced by a foreign key, it must lock not just the row being changed, but potentially the parent row as well.
1. Deadlocks
Highly connected schemas with many foreign keys are prone to deadlocks. This occurs when two transactions hold locks on resources the other needs.
- Scenario: Transaction A updates Parent Table X. Transaction B updates Child Table Y referencing X.
- Conflict: If both transactions try to lock the other’s resource in different orders, the system halts both.
2. Granularity
Database engines often lock at the row level. However, foreign key constraints can force locks at the index level. If an index is scanned to verify a foreign key, the entire index range may be locked.
- Impact: High concurrency systems may experience reduced throughput if foreign key checks block other transactions.
- Mitigation: Careful ordering of transactions and ensuring indexes are aligned with query patterns can reduce contention.
Storage Overhead and Memory Footprint 💾
Every foreign key column consumes storage. While a single integer or UUID might seem small, in a system with billions of records, this accumulates.
1. Data Types and Alignment
The data type of the foreign key must match the primary key. If the primary key is a composite key (multiple columns), the foreign key must also be composite.
- Composite Keys: These increase the size of the index significantly. A composite FK index can be much larger than a single-column index.
- Nullability: If the foreign key allows nulls, the storage engine must handle the null bitmap, adding slight overhead.
2. Memory Usage
Indexes reside in memory during query execution. A large number of foreign keys with corresponding indexes can exhaust available buffer pool memory.
- Cache Pollution: Frequently accessed data gets pushed out of memory to make room for index structures.
- Swap Usage: If memory is insufficient, the system may swap to disk, drastically slowing down performance.
Optimization Strategies for ERD Performance 🚀
To maintain a healthy balance between integrity and speed, specific strategies should be applied during the design phase.
1. Selective Indexing
Do not index every foreign key blindly. Analyze query patterns.
- High Frequency Joins: If two tables are frequently joined, index the foreign key.
- Infrequent Relationships: If a relationship is rarely queried, the index overhead may outweigh the benefits.
2. Partitioning
Partitioning large tables can isolate foreign key checks to specific data segments.
- Range Partitioning: Split data by date or ID range.
- Impact: Reduces the size of the index that needs to be scanned during integrity checks.
3. Asynchronous Validation
In some high-throughput systems, strict referential integrity is enforced asynchronously.
- Process: Data is inserted without immediate FK checks.
- Cleanup: A background job validates and cleans up orphaned records periodically.
- Benefit: Drastically improves write performance at the cost of temporary data inconsistency.
Common Pitfalls to Avoid ⚠️
Even experienced architects can fall into traps when designing ERDs with heavy foreign key usage.
- Chained Relationships: Long chains of foreign keys (A → B → C → D) make queries deep and difficult to optimize.
- Self-Referencing Keys: A table referencing itself (e.g., Employee → Manager) can complicate recursive queries and indexing strategies.
- Wide Primary Keys: Using a multi-column primary key forces the foreign key to be wide, bloating all child indexes.
- Ignoring Statistics: If the database engine lacks up-to-date statistics on foreign key columns, the query planner may choose poor execution plans.
Future-Proofing Your Schema 🔮
Designing for current performance is essential, but scalability requires foresight. Foreign keys can become bottlenecks as data volume grows exponentially.
1. Horizontal Scaling
When moving to a distributed database, foreign key constraints become challenging.
- Sharding: Foreign keys that span shards are difficult to maintain without central coordination.
- Consistency: Maintaining ACID properties across nodes with foreign key dependencies requires complex protocols.
2. Schema Evolution
As requirements change, relationships may need to be altered.
- Altering Keys: Changing a foreign key constraint on a large table can lock the table for extended periods.
- Migration: Tools used for schema migrations must handle foreign key dependencies to avoid breaking production data.
Summary of Key Considerations 📝
The decision to include foreign keys in an ERD is not binary. It is a calculation of integrity needs against performance costs.
- Integrity: Foreign keys are the primary mechanism for enforcing data rules automatically.
- Performance: They introduce overhead in writes and require index maintenance.
- Design: A clean ERD aids communication, but a dense ERD may indicate over-normalization.
- Optimization: Indexing, partitioning, and denormalization are tools to manage the impact of FKs.
By analyzing the specific workload of the application, architects can determine the optimal density of foreign keys. The goal is a schema that is robust enough to prevent errors but flexible enough to handle high-velocity data processing.
Effective database design requires continuous monitoring. As data patterns shift, the performance profile of the foreign keys will change. Regular review of execution plans and lock statistics ensures that the Entity Relationship Diagram remains an accurate reflection of the system’s behavior over time.