











In the evolution of software architecture, few challenges are as persistent as the tension between historical data modeling and modern scalability requirements. Many organizations find themselves managing backend systems built on Entity Relationship Diagrams (ERDs) designed years ago, often under different assumptions about load, concurrency, and hardware. When a legacy schema encounters high-throughput demands, performance degradation is not merely a nuisance; it is a structural failure. This guide explores the technical realities of optimizing these diagrams without discarding the business logic embedded within them.
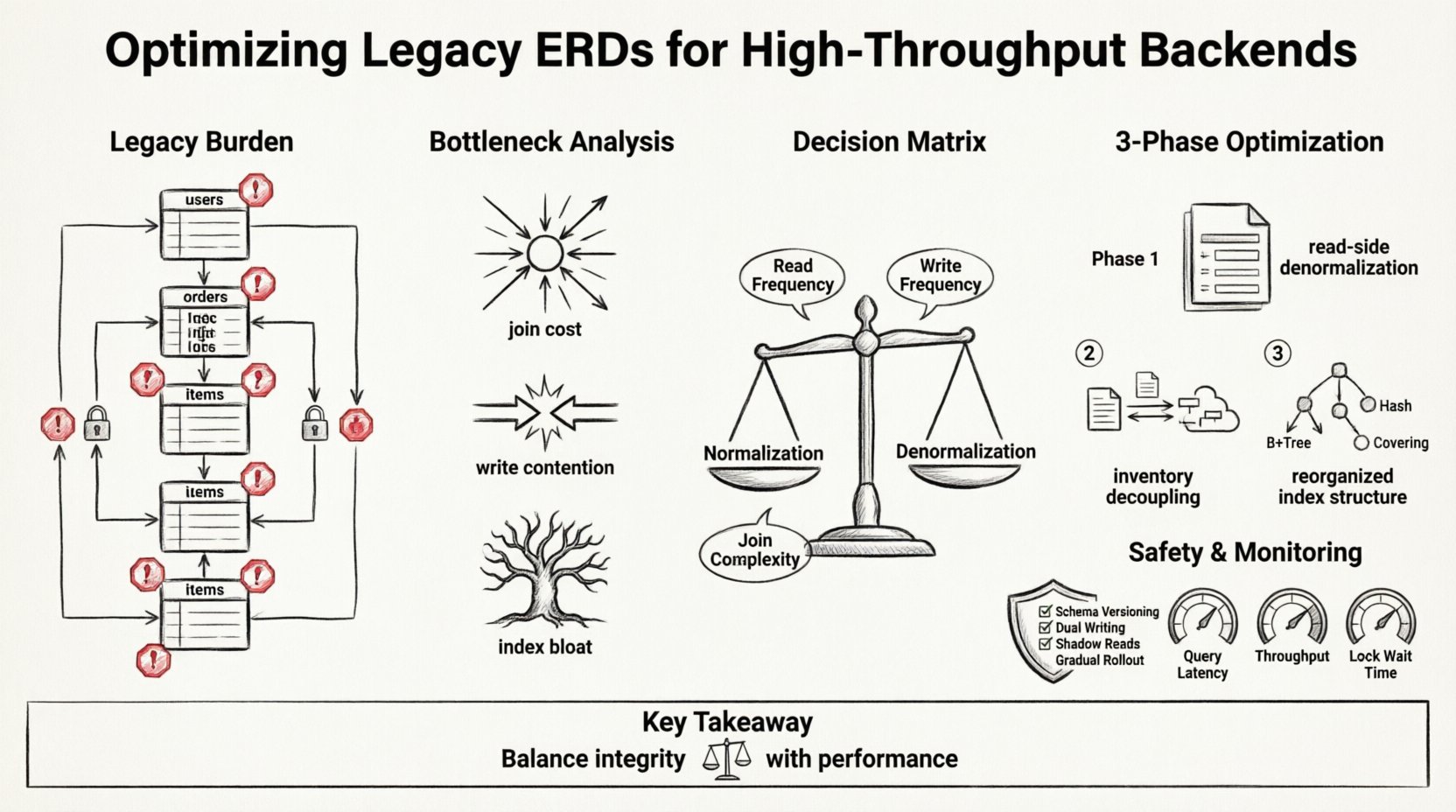
Understanding the Legacy Burden 💾
Legacy ERDs often reflect the needs of the past. They prioritize data integrity and normalization above all else. In a single-node environment with moderate traffic, this approach works well. The strict adherence to Third Normal Form (3NF) minimizes redundancy and ensures consistency. However, when the system scales to millions of transactions per second, the cost of these relationships becomes prohibitive.
Consider the following common characteristics found in older schemas:
- Deep Join Chains: Queries requiring five or more joins to retrieve a single record.
- Heavy Foreign Key Constraints: Rigid integrity checks that block concurrent writes.
- Centralized Locking: Hotspots on specific tables that become bottlenecks during peak loads.
- Denormalization Gaps: A lack of redundant data stores for read-heavy operations.
These patterns are not inherently “wrong.” They were correct for their time. The challenge lies in adapting them to a distributed, high-concurrency environment where latency is the primary currency.
Analyzing the Bottlenecks 🔍
Before altering the diagram, one must understand where the system bleeds performance. High-throughput backends are often limited by I/O operations, network latency between services, and lock contention. The ERD dictates how data is accessed, which directly influences these metrics.
1. Join Costs
Every join is a disk read and a CPU cycle. In a legacy system, a single user profile request might trigger a cascade of lookups across five tables. As traffic increases, the database spends more time navigating relationships than executing logic. This is particularly true when indexes cannot cover the entire join path.
2. Write Contention
Normalization requires writing data to multiple locations to maintain integrity. If a transaction updates a user profile and logs an activity event, two tables must be modified. If these tables reside on the same shard, the lock duration increases. If they are distributed, the transaction becomes a two-phase commit, adding significant overhead.
3. Index Bloat
To support complex joins, legacy systems accumulate indexes. Over time, these indexes slow down write operations. The database must update every index on every insert or update. In high-throughput scenarios, this write amplification can saturate the storage subsystem.
Refactoring Strategy: Normalization vs. Denormalization ⚖️
The core of optimization lies in rethinking the trade-off between data integrity and query speed. While strict normalization ensures consistency, high-performance systems often require pragmatic denormalization. This does not mean abandoning structure; it means accepting redundancy to reduce latency.
The following table outlines the decision matrix for schema changes:
| Criteria | Keep Normalized | Apply Denormalization |
|---|---|---|
| Read Frequency | Low (Batch processing) | High (Real-time dashboards) |
| Write Frequency | High (Core transactions) | Low (Audit logs) |
| Consistency Requirement | Strong ACID | Eventual Consistency acceptable |
| Join Complexity | Simple (1-2 joins) | Complex (3+ joins) |
| Data Volatility | Static (Reference data) | Dynamic (User state) |
Implementing this strategy requires careful planning. You are not just changing tables; you are changing how the application perceives data.
Case Study Walkthrough: E-Commerce Transaction Engine 🛒
To illustrate this process, consider a fictional e-commerce platform. The legacy system handles order processing, inventory management, and customer profiles. The ERD was designed for a single database instance with a focus on preventing overselling of stock.
The Legacy State
In the original design, the orders table referenced order_items, which referenced products. The products table referenced inventory. To display an order detail page, the backend executed a query joining all four tables. Additionally, every order update required a lock on the inventory table to ensure accuracy.
Key Issues Identified:
- Latency: Page load times spiked to 800ms during sales events.
- Deadlocks: High concurrency on inventory updates caused transaction rollbacks.
- Scalability: The database could not shard the
inventorytable due to frequent cross-shard joins.
The Optimization Process
The team decided to refactor the ERD in three phases. The goal was to decouple read paths from write paths.
Phase 1: Read-Side Denormalization
The first step involved creating a snapshot of product data within the order records. Instead of joining to the products table at query time, the system copied the product name, price, and SKU into the order_items table at the moment of purchase.
- Benefit: Order history remains accurate even if product data changes later.
- Benefit: The query no longer requires a join to the product table.
- Risk: Price discrepancies if a product is updated after an order is placed.
- Mitigation: The UI displays the price at the time of purchase as “Historical Price”.
Phase 2: Inventory Decoupling
The inventory table was the source of contention. The team moved inventory tracking to a separate, high-frequency write store. The order system sends an asynchronous message to reserve stock rather than executing a synchronous SQL lock.
- Benefit: Write throughput increased by 400%.
- Benefit: No more blocking on the main order transaction.
- Trade-off: Orders can be placed even if inventory is momentarily out of sync.
- Mitigation: A background process reconciles discrepancies between the order system and inventory.
Phase 3: Index Restructuring
With denormalized data, the old indexes on foreign keys became redundant. The team removed them and added composite indexes optimized for the new query patterns. For example, an index on (customer_id, created_at) replaced the need to scan the entire order table.
Implementation Phases and Safety 🛡️
Changing a live schema is a high-risk operation. The following phases ensure stability during the transition.
1. Schema Versioning
Do not drop old columns immediately. Keep them in place but mark them as deprecated. This allows the application to roll back if the new logic fails. Use migration scripts that add columns before removing them.
2. Dual Writing
During the transition, write data to both the old structure and the new structure. The application logic routes reads to the new structure, but writes go to both. This provides a fallback if the new schema is incomplete.
3. Shadow Reads
Before redirecting live traffic, run the new queries on a copy of the production data. Compare the results of the legacy queries against the optimized queries to ensure data accuracy.
4. Gradual Rollout
Use feature flags to enable the new schema for a small percentage of users (e.g., 1%). Monitor error rates and latency. If metrics remain stable, increase the percentage incrementally.
Monitoring and Validation 📊
Optimization is not a one-time event. It requires continuous monitoring to ensure the changes hold up under load. Key performance indicators (KPIs) must be established before starting the refactoring.
Core Metrics to Track:
- Query Latency: 95th and 99th percentile response times.
- Throughput: Transactions per second (TPS) without errors.
- Lock Wait Time: Average time a transaction waits for a lock.
- Replication Lag: Delay between primary and replica nodes (if applicable).
- Cache Hit Ratio: Effectiveness of read caching strategies.
Alerting thresholds should be set based on the baseline metrics collected before the changes. If latency spikes, the system should automatically revert to the legacy schema or route traffic to a fallback service.
Common Pitfalls to Avoid ⚠️
Even with a solid plan, technical debt often resurfaces in unexpected ways. Be aware of these common errors.
- Ignoring Data Migration Costs: Moving terabytes of data to new structures takes time. Plan for maintenance windows or background migration tools.
- Over-Optimizing Reads: If you denormalize too much, write performance will suffer. Balance the read/write ratio of your specific workload.
- Forgetting Application Logic: The schema change is only half the battle. The application code must be updated to handle the new data structure.
- Neglecting Testing: Unit tests often cover happy paths. Stress tests are required to find race conditions in the new schema.
Long-Term Maintenance Strategies 🔧
Once the optimization is complete, the team must maintain the new architecture. Documentation is critical. Every table, column, and relationship should be tagged with its purpose and ownership.
Regular Audits:
Schedule quarterly reviews of the ERD. Identify tables that are growing disproportionately or queries that are becoming slower. Database growth often reveals new bottlenecks that were not present during the initial refactoring.
Automated Schema Checks:
Integrate schema validation into the CI/CD pipeline. Prevent developers from adding new joins or removing critical constraints without approval. This ensures the system remains optimized over time.
Team Training:
Ensure all backend engineers understand the new data model. A shared understanding of the schema reduces the likelihood of introducing new technical debt through ad-hoc queries.
Final Thoughts on Data Modeling 🔗
Optimizing a legacy Entity Relationship Diagram is a balancing act between historical accuracy and future scalability. There is no single “correct” schema. The right model is the one that supports your current business goals while allowing room for growth.
By focusing on the specific bottlenecks of your system—whether they are join costs, lock contention, or index bloat—you can make targeted improvements. The case study demonstrates that even deeply entrenched structures can be modernized without a complete rewrite. The key is to proceed methodically, validate rigorously, and maintain a clear view of the trade-offs involved.
Data modeling is not static. It evolves with the traffic it serves. Treat your ERD as a living document that requires the same care and attention as the code that queries it. With the right approach, you can transform a legacy system into a high-performance engine capable of handling the demands of the modern web.