











No mundo da arquitetura de software, poucos conceitos têm tanta importância quanto o Diagrama de Relacionamento de Entidades (ERD). É o projeto dos seus dados, o mapa que orienta os desenvolvedores pelo complexo cenário de tabelas, chaves e relacionamentos. Quando uma aplicação apresenta lentidão, a primeira reação costuma ser culpar o esquema. A suposição é clara: se o diagrama é perfeito, o desempenho também deve ser perfeito.
Essa é uma crença comum. 🧐 Embora um ERD bem projetado seja fundamental, não é uma solução mágica para velocidade. Um modelo lógico perfeito não se traduz automaticamente em execução física de alta velocidade. Compreender a lacuna entre a teoria do design e a realidade em tempo de execução é crucial para construir sistemas que permaneçam responsivos sob pressão.
Este guia explora por que um ERD perfeito não garante tempos de resposta rápidos e quais outros fatores críticos influenciam o desempenho do banco de dados. Analisaremos as camadas de manipulação de dados, desde motores de armazenamento até a latência da rede, para revelar os verdadeiros motores da velocidade da aplicação.
📐 Compreendendo o Diagrama de Relacionamento de Entidades
Antes de mergulhar em métricas de desempenho, precisamos esclarecer o que um ERD representa na verdade. Um ERD é um artefato lógico. Ele descreve o que dados existem e como eles se relacionam com outros dados. Define entidades (tabelas), atributos (colunas) e relacionamentos (chaves estrangeiras).
- Entidades:Objetos do mundo real representados como tabelas.
- Atributos:Características desses objetos armazenadas em colunas.
- Relacionamentos:Os links entre entidades, frequentemente garantidos por chaves primárias e estrangeiras.
- Cardinalidade:A relação numérica entre entidades (um-para-um, um-para-muitos).
O principal objetivo de um ERD é a integridade dos dados. Ele garante que os dados permaneçam consistentes, precisos e úteis ao longo do tempo. Evita registros órfãos e mantém a integridade referencial. No entanto, integridade não é o mesmo que velocidade. Um trinco que mantém uma porta fechada protege o conteúdo dentro, mas não a torna mais rápida para abrir.
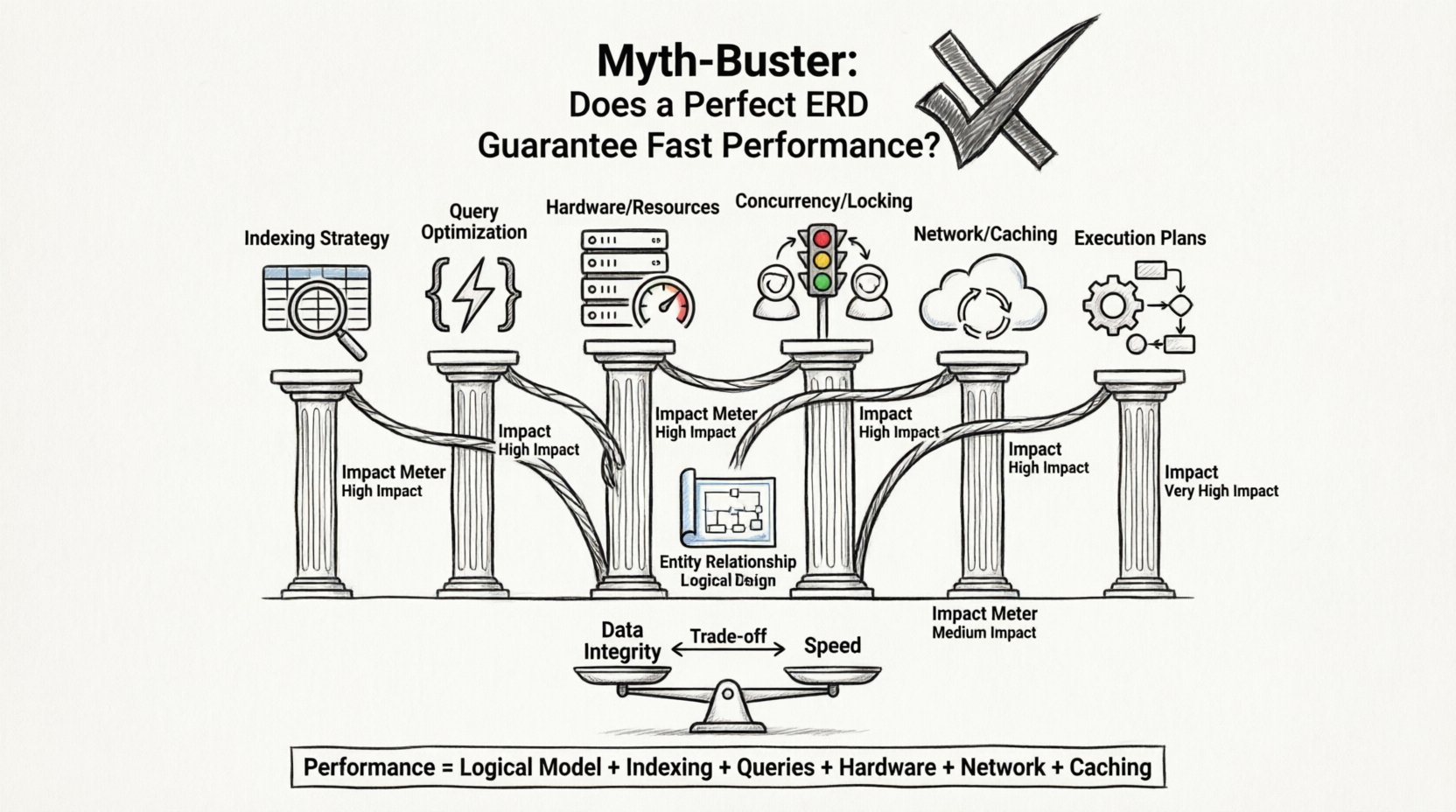
⚡ A Equação de Desempenho: Além do Esquema
O tempo de resposta da aplicação é a soma de muitos componentes. O banco de dados é apenas uma parte dessa equação. Mesmo que o motor do banco de dados recupere os dados instantaneamente, a aplicação ainda pode parecer lenta devido a gargalos em outras partes.
Aqui estão os principais fatores que influenciam a velocidade, muitas vezes superando o design do esquema:
1. Estratégia de Indexação
Um ERD define chaves primárias e chaves estrangeiras, que frequentemente geram índices automaticamente. No entanto, esses índices padrão raramente são suficientes para consultas complexas. O desempenho depende fortemente de índices secundários adaptados a padrões específicos de consulta.
- Índices Ausentes:Sem um índice em uma coluna frequentemente filtrada, o banco de dados deve realizar uma varredura completa da tabela. Isso lê cada linha, o que é exponencialmente mais lento em conjuntos de dados grandes.
- Custo de Índice:Muitos índices tornam mais lenta as operações de escrita. Cada inserção ou atualização exige a atualização de cada índice associado a essa tabela.
- Seletividade:Um índice em uma coluna com baixa seletividade (por exemplo, gênero ou status) pode ser ignorado pelo otimizador de consultas.
2. Otimização de Consultas
A forma como os dados são solicitados importa mais do que como são armazenados. Uma consulta mal escrita pode paralisar um esquema perfeito. Problemas comuns incluem:
- Problemas N+1:Buscar um registro pai e, em seguida, percorrer todos eles para buscar os filhos individualmente. Isso gera múltiplos ida e volta ao banco de dados em vez de uma única operação JOIN.
- Uso de SELECT *:Recuperar todas as colunas aumenta o tráfego de rede e o uso de memória, mesmo que apenas uma seja necessária.
- Conversões Implícitas:Comparar uma string com um número ou uma data com um timestamp pode impedir o uso de índices.
- JOINs Complexos:Fazer JOINs em múltiplas tabelas grandes sem filtragem adequada aumenta significativamente a carga computacional.
3. Hardware e Infraestrutura
A eficiência do software não pode superar limitações físicas. O hardware subjacente determina o limite para o desempenho.
- Tipo de Armazenamento:Unidades de Estado Sólido (SSDs) são significativamente mais rápidas que unidades de disco rígido (HDDs) para operações de I/O aleatórias.
- Memória (RAM):Se o conjunto de dados em uso couber na RAM, as consultas são quase instantâneas. Se os dados precisarem ser buscados no disco, a latência aumenta.
- Potência da CPU:Cálculos complexos, ordenação e agregação exigem poder de processamento.
- Latência de Rede:A distância entre o servidor de aplicação e o servidor de banco de dados adiciona milissegundos a cada solicitação.
4. Concorrência e Bloqueios
Quando múltiplos usuários acessam o sistema simultaneamente, o banco de dados deve gerenciar conflitos. É aqui que o desempenho frequentemente degrada.
- Contenção de Bloqueios:Se uma transação mantém um bloqueio em uma linha, as outras devem esperar. Alta contenção leva a tempos esgotados e tempos de resposta lentos.
- Deadlocks:Duas transações esperando uma pela outra podem causar uma paralisação em toda a sistema.
- Níveis de Isolamento:Níveis de isolamento mais altos (por exemplo, Serializável) fornecem garantias mais fortes, mas reduzem a concorrência e a velocidade.
📊 Impacto do ERD em Comparação com Outros Fatores de Desempenho
Para visualizar a influência do ERD em comparação com outras variáveis, considere a seguinte análise. Esta tabela destaca onde o ERD oferece valor e onde falha.
| Fator | Impacto na Velocidade de Leitura | Impacto na Velocidade de Escrita | Função do ERD |
|---|---|---|---|
| Estrutura do Esquema de Tabela | Médio | Médio | Define relacionamentos e normalização. |
| Indexação | Alto | Baixo | O ERD define chaves, mas nem todos os índices. |
| Lógica de Consulta | Muito Alto | Médio | O ERD não determina a sintaxe da consulta. |
| Recursos de Hardware | Alto | Alto | Nenhum. Independente do esquema. |
| Latência de Rede | Alto | Médio | Nenhum. Independente do esquema. |
| Pool de Conexões | Médio | Médio | Nenhum. Configuração da aplicação. |
🧱 O Trade-Off da Normalização
Um dos tópicos mais debatidos no design de banco de dados é a normalização. O ERD geralmente visa a Terceira Forma Normal (3FN) para reduzir a redundância. Embora isso economize espaço e garanta consistência, pode prejudicar o desempenho.
Quando os dados são altamente normalizados, uma única peça de informação é armazenada em um único local. Para recuperá-la, o sistema deve percorrer múltiplos JOINs. Cada JOIN adiciona sobrecarga computacional.
Considere um cenário em que você precisa exibir o perfil de um usuário junto com seu último pedido e os detalhes do produto. Em um ERD normalizado, isso pode exigir a junção de quatro tabelas. Se essas tabelas forem grandes, a CPU gasta tempo significativo ordenando e correspondendo linhas.
Denormalização é uma técnica usada para contrariar isso. Envolve a duplicação de dados para reduzir a necessidade de JOINs. Isso melhora a velocidade de leitura, mas complica as operações de escrita e corre o risco de inconsistência de dados. Um ERD perfeito não decide automaticamente onde traçar essa linha. É uma decisão estratégica baseada na proporção de leitura/escrita.
🔍 Aprofundamento: Planos de Execução de Consultas
O motor do banco de dados não executa consultas exatamente como escritas. Ele analisa o pedido e gera um Plano de Execução. Esse plano determina a ordem das operações, quais índices usar e se realizar uma varredura ou uma busca.
Um ERD fornece metadados sobre os tipos de dados e restrições. No entanto, o otimizador usa estatísticas sobre a distribuição dos dados para tomar decisões. Se as estatísticas estiverem desatualizadas, o otimizador pode escolher um plano subótimo, ignorando os melhores índices disponíveis.
Por exemplo, se uma tabela tem 10 milhões de linhas, mas as estatísticas acreditam que tem 100, o otimizador pode decidir que uma varredura completa é mais barata do que uma busca em índice. Isso leva a um desempenho lento, apesar de um ERD bem estruturado.
🛡️ Integridade de Dados vs. Velocidade
Há uma tensão intrínseca entre garantir a integridade dos dados e maximizar a velocidade. Um ERD impõe regras de integridade, como restrições e gatilhos.
- Restrições de Chave Estrangeira: Garantem a integridade referencial. Na exclusão ou atualização, o sistema deve verificar tabelas relacionadas. Isso adiciona latência às operações de escrita.
- Gatilhos:Scripts automatizados que são executados em alterações de dados. Embora úteis para lógica, adicionam tempo de processamento a cada transação.
- Restrições Únicas: Exigem que o sistema verifique valores existentes antes de inserir novos.
Em sistemas de alta taxa de transferência, essas verificações às vezes são desativadas ou adiadas para melhorar a velocidade. Um ERD perfeito inclui todas essas regras, mas um sistema de alto desempenho pode exigir uma abordagem modificada.
🚦 Passos Práticos para Otimização
Se o seu aplicativo está lento, não redesenhe imediatamente o seu ERD. Siga uma abordagem sistemática para identificar o gargalo.
1. Analise Consultas Lentas
Habilite o registro de consultas para capturar declarações de longa duração. Use ferramentas de perfil para ver onde o tempo é gasto. Está esperando por bloqueios? Está varrendo linhas? Está processando lógica?
2. Revise o Uso de Índices
Verifique quais índices estão realmente sendo usados. Índices não utilizados consomem armazenamento e atrasam as escritas. Crie índices que correspondam às cláusulas WHERE e JOIN das suas consultas frequentes.
3. Otimize a Alocação de Hardware
Garanta que o servidor do banco de dados tenha memória RAM suficiente para armazenar em cache o conjunto de trabalho. Se o banco de dados for limitado pela memória, adicionar mais RAM trará resultados imediatos. Se for limitado pela CPU, talvez seja necessário atualizar o processador ou otimizar o código.
4. Implemente o Cache
Não toda solicitação precisa acessar o banco de dados. Use um cache em memória (como Redis ou Memcached) para dados frequentemente acessados. Isso evita completamente o banco de dados para operações de leitura.
5. Monitore a Concorrência
Monitore os bloqueios em espera. Se os usuários estiverem enfrentando tempos limite, revise os comprimentos das transações. Mantenha as transações curtas para liberar os bloqueios rapidamente.
🔄 O Papel da Evolução do Esquema
Aplicações mudam. Requisitos mudam. O ERD deve evoluir com o negócio. Um esquema que era perfeito há seis meses pode estar obsoleto hoje devido a novas funcionalidades ou aumento no volume de dados.
Estratégias de migração importam. Mover dados de uma tabela pequena para uma tabela grande particionada pode melhorar o desempenho. Alterar tipos de dados de VARCHAR para INT pode reduzir o armazenamento e melhorar as velocidades de varredura. Essas decisões acontecem após o ERD inicial ser criado.
ERDs estáticos não levam em conta o crescimento dos dados. À medida que os dados crescem, as características de desempenho mudam. Um design que funcionava com 10.000 registros pode falhar com 10 milhões. É por isso que o ajuste de desempenho é um processo contínuo, e não uma tarefa única.
🧩 Considerações sobre NoSQL
O conceito de ERD aplica-se mais estritamente a bancos de dados relacionais. Em ambientes NoSQL, o modelo de dados é diferente. Armazenamentos de documentos, armazenamentos de chave-valor e bancos de dados de grafos lidam com relacionamentos de forma distinta.
Em um armazenamento de documentos, os dados podem ser embutidos para evitar junções. Isso simula a desnormalização por design. Em um banco de dados de grafos, os relacionamentos são cidadãos de primeira classe, armazenados explicitamente para otimizar a navegação.
O mito da garantia do ERD é ainda mais acentuado aqui. No NoSQL, o esquema é frequentemente flexível ou dinâmico. O desempenho depende fortemente dos padrões de acesso definidos no código da aplicação, e não de um diagrama rígido.
🏁 Pensamentos Finais sobre Arquitetura de Dados
Construir uma aplicação rápida exige uma visão holística. O ERD é um ponto de partida crítico, garantindo que os dados estejam organizados logicamente. Ele evita o caos e mantém a integridade. No entanto, ele não é o motor que impulsiona a velocidade.
O desempenho é o resultado de uma sinergia entre:
- Um modelo lógico sólido.
- Indexação estratégica.
- Escrita eficiente de consultas.
- Recursos de hardware adequados.
- Configuração de rede adequada.
- Estratégias eficazes de cache.
Atribuir a culpa ao esquema por tempos de resposta lentos é uma solução rápida que leva a correções erradas. Um diagrama perfeito em papel não pode compensar um disco lento, um tempo limite de rede ou uma consulta mal escrita. A engenharia de desempenho verdadeira envolve olhar além do projeto para o fluxo real de dados.
Quando você auditou seu sistema, comece pelo ERD para garantir a correção. Em seguida, vá para o plano de execução para garantir eficiência. Por fim, avalie a infraestrutura para garantir capacidade. Apenas abordando todas as camadas é possível alcançar a responsividade esperada pelos usuários.