











Projetar a arquitetura de dados para um sistema backend de grande escala é uma tarefa fundamental que determina a longevidade e a estabilidade de toda a aplicação. Um Diagrama de Relacionamento de Entidades, comumente abreviado como ERD, serve como o projeto arquitetônico para essa estrutura. Ele mapeia visualmente a estrutura dos dados, definindo como diferentes partes de informações se conectam, se relacionam e interagem dentro do sistema. Em um contexto empresarial, onde a consistência, integridade e escalabilidade dos dados são fundamentais, seguir os padrões estabelecidos de ERD não é meramente uma boa prática; é uma necessidade.
Sem uma abordagem padronizada para modelagem de dados, os sistemas backend correm o risco de se tornarem frágeis. Convenções de nomeação inconsistentes, relacionamentos ambíguos e normalização deficiente podem levar a gargalos de desempenho, ciclos de manutenção difíceis e corrupção de dados. Este guia explora os padrões críticos e metodologias necessárias para criar esquemas de banco de dados robustos adequados para ambientes empresariais complexos. Analisaremos os componentes principais, sistemas de notação, regras de normalização e estratégias de governança que equipes profissionais utilizam para garantir que suas camadas de dados permaneçam confiáveis ao longo do tempo.
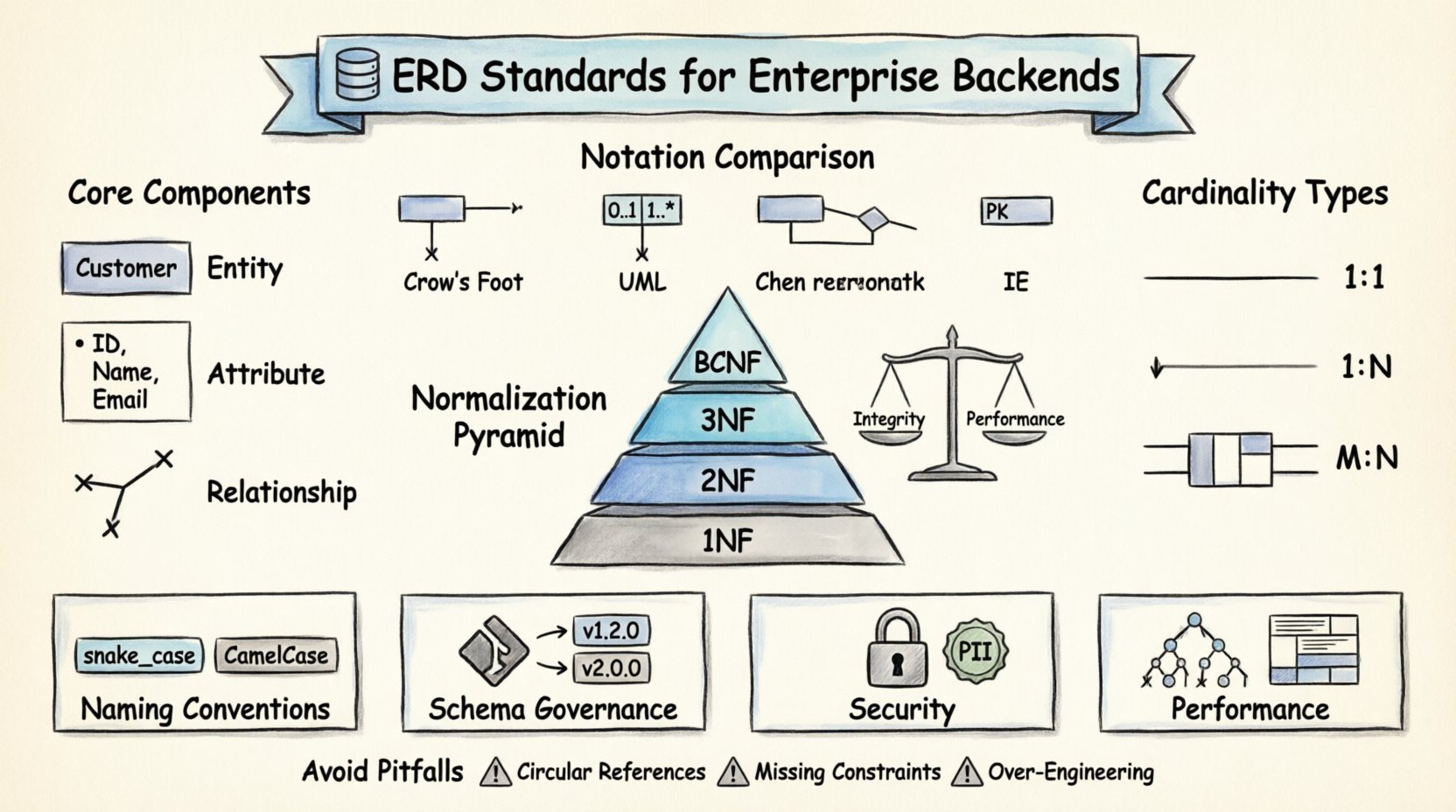
Componentes Principais de um ERD Empresarial 🧩
Antes de mergulhar nos padrões específicos, é essencial compreender os blocos de construção fundamentais que constituem um ERD. Cada diagrama em um ambiente profissional depende de três elementos principais. Esses elementos atuam em conjunto para descrever a estrutura lógica dos dados.
- Entidades: Elas representam objetos ou conceitos do mundo real sobre os quais os dados são armazenados. Em um contexto de backend, uma entidade geralmente mapeia diretamente uma tabela do banco de dados. Exemplos incluem Cliente, Pedido, ou Produto. As entidades devem ser claramente definidas para garantir que cada registro tenha uma identidade única.
- Atributos: Os atributos descrevem as propriedades ou características específicas de uma entidade. Eles correspondem às colunas dentro de uma tabela. Para uma entidade Cliente entidade, os atributos podem incluir IDCliente, NomeCompleto, e EnderecoEmail. Definir corretamente os tipos de dados para os atributos é crucial para a integridade dos dados.
- Relacionamentos: Os relacionamentos definem como as entidades interagem entre si. Eles estabelecem as restrições e associações entre as tabelas. Por exemplo, um único Cliente pode fazer vários Pedidos. Esse relacionamento determina as restrições de chave estrangeira e a lógica de junção necessárias no backend.
No desenvolvimento de nível empresarial, esses componentes não são apenas conceitos abstratos; são a base para otimização de consultas, controle de acesso e estratégias de migração de dados. Um ERD bem documentado permite que os desenvolvedores compreendam o fluxo de dados sem precisar inspecionar cada linha de código.
Padrões de Notação e Convenções Visuais 📐
Não existe uma sintaxe universal única para desenhar ERDs, mas existem padrões amplamente aceitos que garantem clareza e consistência entre diferentes equipes. Escolher uma notação e mantê-la é uma decisão crítica de governança.
Notação Chen versus Pés de Corvo
Historicamente, a notação Chen era o padrão, utilizando retângulos para entidades e losangos para relacionamentos. Embora clara, é menos comum em ferramentas modernas de desenvolvimento de software. A notação Pés de Corvo tornou-se a preferência da indústria por várias razões:
- Clareza na Cardinalidade: Utiliza símbolos específicos (linhas, círculos e “pés”) para indicar visualmente relacionamentos um-para-um, um-para-muitos e muitos-para-muitos.
- Suporte de Ferramentas: A maioria das ferramentas modernas de design de banco de dados e utilitários de engenharia reversa suporta nativamente símbolos Pés de Corvo ou derivados do UML.
- Legibilidade: Geralmente é mais compacto e mais fácil de ler ao lidar com esquemas complexos e interconectados.
Comparação de Sistemas de Notação
| Estilo de Notação | Representação de Entidades | Representação de Relacionamentos | Melhor Caso de Uso |
|---|---|---|---|
| Pés de Corvo | Retângulo | Linhas com símbolos (pés de corvo, círculo, linha) | Design de Banco de Dados Relacional |
| Diagrama de Classes UML | Caixa de Classe com compartimentos | Setas com multiplicidades (0..1, 1..*) | Modelagem Orientada a Objetos |
| Chen | Retângulo | Forma de losango conectando entidades | Modelos Acadêmicos/Teóricos |
| IE (Engenharia de Informação) | Retângulo com atributos | Linhas com indicadores de chave primária | Documentação do Sistema Legado |
Para backends corporativos, a notação Crow’s Foot é geralmente recomendada devido à sua correspondência direta com restrições relacionais. Ela minimiza ambiguidades quando desenvolvedores interpretam o diagrama durante a implementação.
Normalização: Garantindo a Integridade dos Dados 🔄
A normalização é o processo de organizar dados em um banco de dados para reduzir a redundância e melhorar a integridade dos dados. Embora sistemas modernos às vezes desnormalizem para desempenho, compreender as regras de normalização é essencial para projetar um esquema inicial sólido.
As Formas Normais
- Primeira Forma Normal (1NF):Cada coluna deve conter valores atômicos. Listas de valores em uma única célula são proibidas. Isso garante que cada interseção entre linha e coluna contenha uma única peça de dados indivisível.
- Segunda Forma Normal (2NF):A tabela deve estar na 1NF, e todos os atributos não-chave devem depender plenamente da chave primária. Isso evita dependências parciais, em que uma coluna depende apenas de parte de uma chave composta.
- Terceira Forma Normal (3NF):A tabela deve estar na 2NF, e não deve haver dependências transitivas. Atributos não-chave não devem depender de outros atributos não-chave. Por exemplo, se Cidade depende de CEP, e CEP depende de ID, Cidadea Cidade deveria ser movida para uma tabela separada.
- Forma Normal de Boyce-Codd (BCNF):Uma versão mais rigorosa da 3NF. Exige que, para toda dependência funcional X → Y, X deve ser um superchave. Isso trata certos casos especiais na 3NF em que um determinante é uma chave candidata, mas não a chave primária.
Compromissos da Normalização
| Nível | Benefício | Custo |
|---|---|---|
| Alta Normalização (3NF/BCNF) | Redundância mínima, alta integridade | Mais junções necessárias para consultas |
| Baixa Normalização (Denormalizada) | Melhor desempenho de leitura | Maior risco de inconsistência de dados |
Sistemas empresariais geralmente visam a 3FN em seus esquemas transacionais. Quando o desempenho de leitura se torna um gargalo, a denormalização é aplicada de forma seletiva em visualizações específicas ou tabelas de relatórios, em vez do esquema transacional principal.
Convenções de Nomeação e Higiene de Esquemas 🏷️
Uma convenção de nomeação consistente é vital para a manutenibilidade. Quando múltiplas equipes trabalham no mesmo backend, ambiguidade na nomeação leva a erros. Um padrão deve ser documentado e imposto por meio de ferramentas de linting ou scripts de validação de esquema.
Regras de Nomeação de Tabelas
- Plural vs. Singular: Há uma discussão, mas a consistência é fundamental. Nomes no plural (por exemplo, Usuários, Pedidos) geralmente soam melhor em frases em inglês. Nomes no singular (por exemplo, Usuário, Pedido) são geralmente preferidos em contextos orientados a objetos. Escolha um e aplique globalmente.
- Underlines vs. CamelCase: Underlines (snake_case) são padrão para identificadores SQL. CamelCase (camelCase) é comum no código da aplicação. Certifique-se de que a camada do banco de dados e a camada da aplicação concordem na estratégia de tradução.
- Evite Palavras Reservadas: Nunca nomeie uma tabela ou coluna usando palavras reservadas do banco de dados (por exemplo, Grupo, Selecionar, Pedido). Isso evita erros de sintaxe durante a geração de consultas.
- Prefixos para Metadados: Use prefixos como _audit, _log, ou _temp para distinguir tabelas auxiliares das entidades principais do negócio.
Regras de Nomeação de Colunas
- Chaves Estrangeiras: Indique claramente a relação. Se uma coluna referencia a tabela Usuários tabela, nomeie-a como id_usuario em vez de id_usuario ou fk_usuario.
- Bandeiras Booleanas: Use prefixos como is_ ou has_. Por exemplo, is_ativo ou has_assinatura.
- Campos de Data e Hora: Especifique o escopo. Use criado_em ou atualizado_em em vez de data ou hora.
Relacionamentos e Cardinalidade 🔄
Compreender a cardinalidade é a diferença entre um banco de dados funcional e um quebrado. A cardinalidade define o número exato de instâncias de uma entidade que podem ou devem estar associadas a cada instância de outra entidade.
Tipos de Relacionamentos
- Um para Um (1:1): Uma instância da Entidade A está associada a exatamente uma instância da Entidade B. Isso é raro na lógica central dos negócios, mas comum em dados de segurança ou configuração. Exemplo: Um Usuário tem um Perfil.
- Um para Muitos (1:N): Uma instância da Entidade A está associada a muitas instâncias da Entidade B. Este é o relacionamento mais comum. Exemplo: Uma Departamento tem muitos Funcionários.
- Muitos para Muitos (M:N): Muitas instâncias da Entidade A estão associadas a muitas instâncias da Entidade B. Isso exige uma tabela de junção (entidade associativa). Exemplo: Alunos e Cursos.
Opcionalidade e Restrições
A cardinalidade não conta toda a história; é a opcionalidade que conta. Isso se refere a se a relação é obrigatória ou opcional.
- Obrigatório (Participação Obrigatória): Uma instância de entidade deveestar associada a outra. Por exemplo, um Pedido deveter um Cliente.
- Opcional (Participação Opcional): Uma instância de entidade podeexistir sem uma relação. Por exemplo, um Produtopode existir sem um Pedidoregistro ainda.
Aplicar essas regras ao nível do banco de dados usando restrições (NOT NULL, Chaves Estrangeiras) é muito mais confiável do que aplicá-las no código da aplicação. Isso protege contra desvios de dados e garante que o esquema permaneça a fonte da verdade.
Gestão de Esquema e Controle de Versão 📜
Em ambientes corporativos, o esquema do banco de dados é código. Ele deve ser versionado, revisado e gerenciado com a mesma rigorosidade do código-fonte da aplicação. Um diagrama ER não é um documento estático; ele evolui conforme as exigências do negócio mudam.
Estratégias de Migração
- Compatibilidade para frente:As alterações devem ser projetadas para acomodar dados antigos. Evite remover colunas imediatamente; em vez disso, marque-as como obsoletas.
- Compatibilidade para trás:Novas versões do esquema não devem quebrar consultas existentes. Use visualizações para abstrair alterações da camada da aplicação.
- Alterações Atômicas:Cada script de migração deve representar uma única alteração lógica. Isso facilita os retornos se ocorrer um erro.
Manutenção da Documentação
Um ERD que não é atualizado é uma responsabilidade. Certifique-se de que o processo de geração do diagrama seja automatizado. Idealmente, o ERD deveria ser gerado diretamente dos arquivos de definição de esquema (DML) para evitar desalinhamentos entre a documentação e o estado real do banco de dados.
- Automatize a geração do ERD em cada confirmação.
- Exija revisão de esquema no processo de solicitação de pull.
- Marque versões principais do esquema para correlacionar com lançamentos de aplicativos.
Considerações de Segurança e Privacidade 🔒
Backends corporativos lidam com informações sensíveis. A fase de design do ERD deve levar em conta requisitos de segurança e privacidade, especialmente em relação às Informações Pessoais Identificáveis (PII).
Classificação de Dados
- Dados Públicos:Informação que pode ser compartilhada abertamente. Nenhuma manipulação especial necessária.
- Dados Internos:Informação exclusiva para funcionários. Listas de controle de acesso (ACLs) devem ser consideradas.
- Dados Restritos:Dados sensíveis como senhas, registros médicos ou detalhes financeiros. Esses campos exigem criptografia em repouso e em trânsito.
Mascaramento e Anonimização
No ERD, marque os campos que exigem mascaramento em ambientes não de produção. Isso ajuda os desenvolvedores a entender quais colunas precisam de tratamento especial durante os testes. Embora o diagrama em si não impeça a segurança, orienta a implementação de políticas de segurança.
- Identifique explicitamente as colunas que contêm PII.
- Defina campos de auditoria (por exemplo, last_modified_by) para rastrear quem acessou ou alterou os dados.
- Garanta que chaves estrangeiras não exponham IDs internos que possam ser enumerados.
Planejamento de Desempenho e Escalabilidade 🚀
Embora o ERD se concentre na estrutura, ele também deve considerar o desempenho. Um esquema logicamente correto, mas fisicamente lento, falhará sob carga.
Estratégia de Indexação
As relações definidas no ERD determinam onde os índices são necessários. Chaves estrangeiras devem ser indexadas para acelerar junções e verificações de restrições. No entanto, o excesso de indexação pode retardar operações de escrita.
- Chaves Primárias: Sempre indexado.
- Chaves Estrangeiras: Sempre indexado para melhorar o desempenho de junções.
- Colunas de Busca: As colunas frequentemente usadas em cláusulas WHERE devem ter índices.
Particionamento e Shardização
Para conjuntos de dados massivos, o ERD pode indicar estratégias de particionamento. Se os dados são naturalmente agrupados (por exemplo, por Região ou Data), isso deve ser refletido no design do esquema. Isso permite que o banco de dados distribua a carga entre vários nós físicos.
Armadilhas Comuns para Evitar ⚠️
Mesmo equipes experientes cometem erros. Reconhecer padrões comuns de falhas ajuda na construção de um sistema resiliente.
- Referências Circulares: Evite relacionamentos em que a Entidade A depende de B e B depende de A, criando um ciclo que complica a exclusão ou atualização de dados.
- Restrições Ausentes: Contar com o código da aplicação para impor regras (por exemplo, garantir que um Preço seja positivo) é arriscado. Use restrições CHECK no banco de dados.
- Engenharia Excessiva: Não modele cada cenário futuro possível. Projete de acordo com os requisitos atuais, com flexibilidade suficiente para adaptação, mas evite criar tabelas para casos de uso hipotéticos.
- Valores Codificados: Evite armazenar códigos de status como inteiros sem uma tabela de consulta. Use uma tabela de referência para status como StatusPedido para manter a clareza.
Implementando Padrões na Sua Fluxo de Trabalho 🛠️
Adotar esses padrões exige uma mudança de cultura. Não basta simplesmente desenhar um diagrama; o diagrama deve impulsionar o processo de desenvolvimento.
- Design Primeiro: Exija que o ERD seja aprovado antes de escrever quaisquer scripts de migração.
- Revisões de Código: Inclua alterações no esquema na lista padrão de revisão de código.
- Treinamento: Garanta que todos os engenheiros de back-end compreendam os conceitos de normalização e cardinalidade.
- Ferramentas:Invista em ferramentas de design de esquema que suportem colaboração e versionamento.
Ao tratar o Diagrama de Relacionamento de Entidades como um componente vivo e dinâmico da arquitetura do sistema, equipes empresariais podem garantir que suas camadas de dados permaneçam robustas. O esforço investido na padronização da fase de design traz benefícios em menor dívida técnica e maior confiabilidade do sistema. Um banco de dados bem estruturado é a base sobre a qual aplicações escaláveis são construídas.
Quando você prioriza clareza, consistência e integridade em seu modelagem de dados, cria uma base que suporta o crescimento. Os padrões descritos aqui fornecem uma estrutura para essa base. Segui-los garante que seu backend permaneça manutenível, seguro e eficiente à medida que sua organização cresce.