











Projetar uma arquitetura de dados robusta exige um profundo entendimento de como as informações se conectam, se relacionam e persistem. No centro desse projeto está o Diagrama de Relacionamento de Entidades (ERD). Embora tradicionalmente associado a bancos de dados relacionais, a semântica dos ERDs evoluiu para atender às diversas necessidades dos ambientes NoSQL modernos. Este guia explora as nuances da modelagem de relacionamentos de dados em diferentes paradigmas de armazenamento, garantindo integridade estrutural sem sacrificar desempenho.
Conceitos Fundamentais de Modelagem de Dados 🏗️
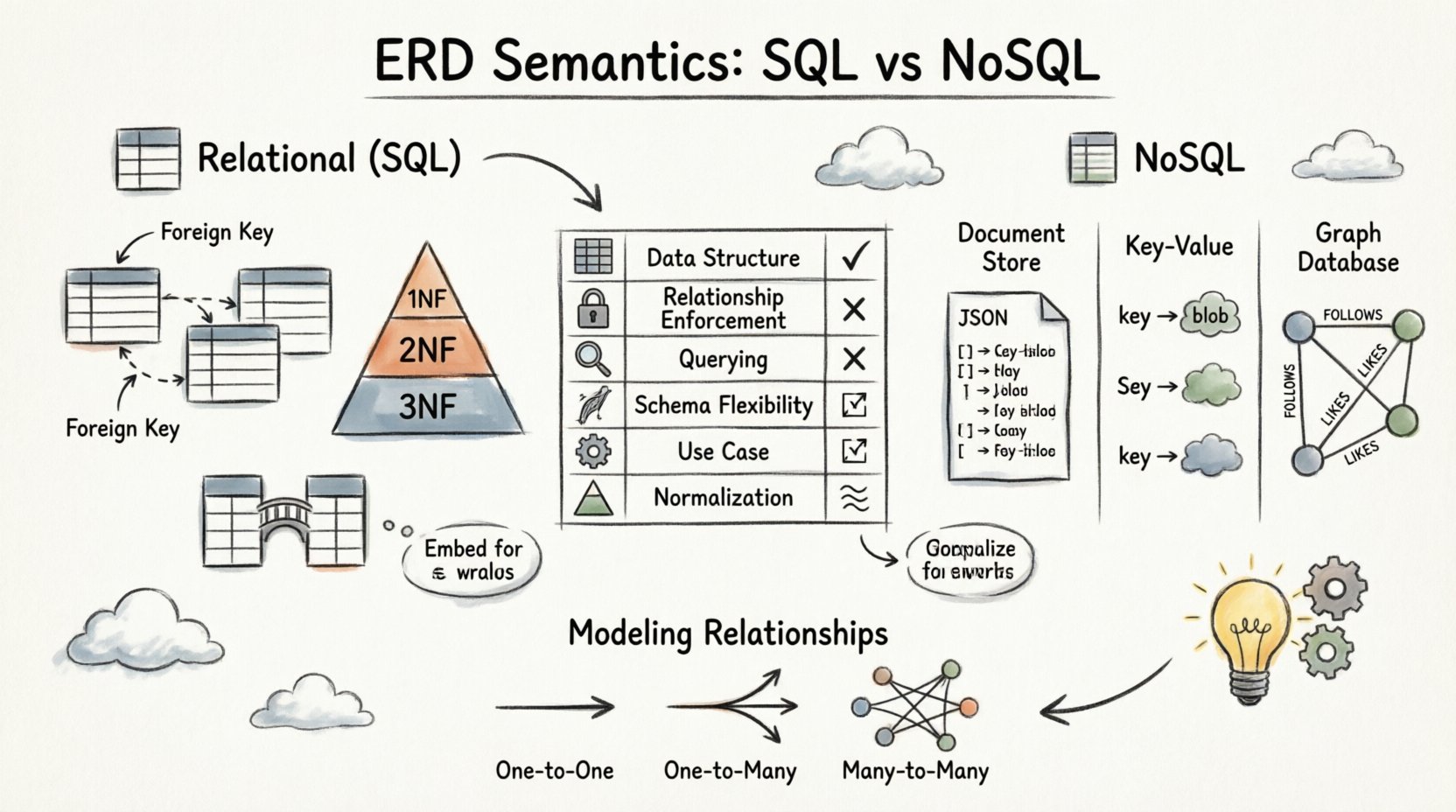
Antes de mergulhar em tipos específicos de banco de dados, é essencial estabelecer um vocabulário compartilhado. Um Diagrama de Relacionamento de Entidades serve como uma planta visual. Ele define as entidades (tabelas, coleções ou documentos), seus atributos (colunas, campos ou propriedades) e as relações que as conectam.
- Entidade: Um objeto ou conceito distinto dentro do domínio de negócios. Em um contexto de banco de dados, isso poderia ser um Usuário, um Produto ou um Pedido.
- Atributo: Uma propriedade que descreve a entidade. Exemplos incluem id, nome, criado_em, ou status.
- Relação: A associação entre duas entidades. Isso define como os dados em uma entidade se conectam aos dados em outra.
- Cardinalidade: O aspecto numérico de uma relação. Ela especifica se uma relação é um para um, um para muitos ou muitos para muitos.
Ao criar um ERD, o objetivo é representar a lógica do mundo real da aplicação. Um diagrama bem construído reduz a ambiguidade para os desenvolvedores e garante que as consultas possam ser escritas de forma eficiente mais tarde no ciclo de desenvolvimento.
Semântica em Ambientes Relacionais 🗃️
No modelo relacional, os dados são armazenados em tabelas com esquemas rígidos. A semântica do ERD aqui é rígida e governada pela teoria dos conjuntos e pelos princípios da primeira forma normal. Toda relação é obrigada pelo motor do banco de dados para manter a integridade referencial.
1. A Função das Chaves Estrangeiras
As chaves estrangeiras são a base dos ERDs relacionais. Elas ligam fisicamente as tabelas. Quando um ERD mostra uma linha conectando duas tabelas, a implementação depende de uma coluna de chave estrangeira na tabela filha que referencia a chave primária da tabela pai.
- Implementação: Um valor numérico ou alfanumérico armazenado em uma coluna.
- Restrição: O motor do banco de dados impede registros órfãos. Você não pode inserir um valor em uma coluna de chave estrangeira a menos que ele exista na chave primária referenciada.
- Cascateamento: Ações no registro pai (exclusão ou atualização) podem se propagar automaticamente para os registros filhos com base em regras definidas.
2. Normalização e Integridade
Os ERDs relacionais priorizam a normalização. Esse processo reduz a redundância de dados organizando atributos em grupos lógicos. Um ERD bem normalizado geralmente parece mais complexo devido ao número de tabelas envolvidas.
- 1FN: Garante atomicidade; cada célula contém um único valor.
- 2FN: Remove dependências parciais; os atributos dependem da chave primária inteira.
- 3FN: Remove dependências transitivas; atributos não-chave dependem apenas da chave primária.
Essa estrutura garante que os dados sejam consistentes. Se um usuário alterar seu nome, a atualização ocorre em um único local, e todos os registros que referenciam esse usuário veem a mudança imediatamente.
3. Tratamento de Relacionamentos Muitos para Muitos
Relacionamentos muitos para muitos são semanticamente distintos em sistemas relacionais. Você não pode vincular diretamente duas tabelas nesse caso. Em vez disso, é necessário uma tabela intermediária de junção.
- Estrutura: Uma tabela que contém as chaves primárias de ambas as entidades relacionadas.
- Função: Essa tabela atua como uma ponte, permitindo que múltiplos registros na Entidade A se conectem a múltiplos registros na Entidade B.
- Consulta: Recuperar esses dados exige uma
JOINoperação, que pode ser computacionalmente cara em conjuntos de dados grandes se não for indexada corretamente.
Semântica em Ambientes NoSQL 📦
Bancos de dados NoSQL oferecem flexibilidade. A semântica do ERD muda de aplicação estrutural para representação lógica. O diagrama torna-se mais um guia de padrão de design do que uma definição rígida de esquema. Modelos NoSQL diferentes lidam com relacionamentos de maneiras distintas.
1. Armazenamento de Documentos e Incorporação
Em bancos de dados orientados a documentos, os dados são armazenados como documentos semelhantes ao JSON. O ERD frequentemente sugere incorporar dados relacionados diretamente dentro de um único documento para otimizar o desempenho de leitura.
- Um para Muitos: Um documento pai pode conter uma matriz de objetos filhos. Isso evita a necessidade de junções durante a recuperação.
- Implicação: Atualizações nos dados filhos exigem a reescrita de todo o documento pai. Isso pode levar a contenção se o documento pai se tornar muito grande.
- Leitura vs. Escrita: Essa abordagem otimiza para leituras. Ela troca o desempenho de escrita e redundância de dados pela velocidade.
2. Armazenamentos de Chave-Valor
Os armazenamentos de chave-valor tratam os dados como blocos opacos. As semânticas do ERD aqui são mínimas. As relações são frequentemente inferidas pela camada de aplicação, e não pelo motor do banco de dados.
- Referência:Documentos frequentemente contêm uma ID de referência para outro documento, semelhante a uma chave estrangeira, mas sem aplicação de restrições.
- Responsabilidade:A lógica da aplicação deve garantir que a ID referenciada exista e seja válida. Não há restrição no nível do banco de dados.
- Caso de uso:Melhor para cache, gerenciamento de sessões ou estruturas de dados altamente flexíveis, onde as relações não são a principal preocupação.
3. Bancos de Dados de Grafos
Bancos de dados de grafos são projetados especificamente para relações. O ERD neste contexto mapeia diretamente para nós e arestas. Talvez seja a interpretação mais literal de um Diagrama de Entidade-Relacionamento.
- Nós:Representam entidades (por exemplo, Pessoa, Localização).
- Arestas:Representam relações (por exemplo, MORA_EM, CONHECE).
- Propriedades:Tanto nós quanto arestas podem ter atributos associados a eles.
- Travessia:As consultas seguem as arestas. Uma relação não é uma pesquisa; é uma travessia de caminho.
Análise Comparativa de Abordagens de Modelagem 📊
Compreender as diferenças entre esses ambientes ajuda na escolha da ferramenta certa para a tarefa. A tabela a seguir mostra como as semânticas do ERD se traduzem entre esses sistemas.
| Funcionalidade | Relacional (SQL) | Armazenamento de Documentos | Banco de Dados de Grafos |
|---|---|---|---|
| Estrutura de Dados | Tabelas com linhas e colunas | Documentos JSON | Nós e Arestas |
| Aplicação de Relações | Chaves Estrangeiras (Rígidas) | Manual / Nível de Aplicação | Referências de Aresta Nativas |
| Consulta de Relacionamentos | Operações JOIN | Consulta ou Incorporação | Percurso de Caminho |
| Flexibilidade de Esquema | Esquema Fixo | Esquema Dinâmico | Semi-Estruturado |
| Caso de Uso Principal | Integridade de Transação | Gestão de Conteúdo / Hierarquias | Redes / Grafos Sociais |
| Normalização | Alta (3FN / FNBC) | Baixa (Desnormalizada) | Não Aplicável |
Modelagem de Relacionamentos: Uma Análise Aprofundada 🔗
A forma como os relacionamentos são representados em um DER determina os padrões de consulta e as características de desempenho da aplicação. Vamos analisar em detalhes cardinalidades específicas.
Relacionamentos Um para Um
Este é o relacionamento mais simples. Um registro na Tabela A corresponde exatamente a um registro na Tabela B.
- Implementação em SQL: Uma chave estrangeira em qualquer uma das tabelas com uma restrição única.
- Implementação em NoSQL: Frequentemente mesclados em um único documento para evitar consultas, ou armazenados separadamente com uma referência única.
- Quando usar: Perfis de usuário separados dos detalhes de autenticação, ou configurações vinculadas a ambientes específicos.
Relacionamentos Um para Muitos
Este é o tipo de relacionamento mais comum. Um registro na Tabela A está relacionado a muitos registros na Tabela B.
- Implementação em SQL: Uma chave estrangeira na Tabela B referenciando a Tabela A.
- Armazenamento de Documentos: Incorporar o lado “Muitos” dentro do documento do lado “Um” como um array. Isso é eficiente para ler toda a hierarquia de uma vez.
- Banco de Dados de Grafos: Criar uma aresta do nó “Um” para múltiplos nós “Muitos”.
- Consideração: Se o lado “Muitos” crescer significativamente, incorporar em um armazenamento de documentos pode atingir os limites de armazenamento. Pode ser necessário um abordagem híbrida (referências em vez de incorporação).
Relacionamentos Muitos para Muitos
Esse relacionamento exige uma ponte em SQL, mas se comporta de forma diferente em outros sistemas.
- Implementação em SQL: Uma tabela de junção contendo IDs de ambas as tabelas pais.
- Armazenamento de Documentos: Frequentemente desnormalizado. Cada documento contém uma lista de IDs ou objetos completos da entidade relacionada. Isso duplica dados, mas acelera a recuperação.
- Banco de Dados de Grafos: Esse é o ponto forte nativo do modelo. Os nós são conectados diretamente sem uma tabela intermediária.
- Desafio de Consistência: Em armazenamentos de documentos, manter as listas sincronizadas entre múltiplos documentos é difícil. Atualizações em uma entidade compartilhada devem ser propagadas manualmente para todos os documentos que a referenciam.
Evolução de Esquema e Flexibilidade 🔄
Requisitos de software mudam. Modelos de dados devem evoluir sem quebrar aplicações existentes. O significado do ERD determina o quão facilmente essa evolução pode ocorrer.
1. Migração de Esquema em SQL
Alterar um esquema relacional é uma operação significativa. Muitas vezes envolve bloquear tabelas ou executar migrações durante períodos de inatividade.
- Adicionando Colunas: Geralmente seguro e rápido.
- Renomeando Colunas: Exige reescrever a estrutura da tabela e atualizar todas as consultas dependentes.
- Alterando Tipos de Dados: Pode ser arriscado se a conversão de dados falhar ou se a lógica da aplicação depender do tipo antigo.
2. Flexibilidade de Esquema no NoSQL
Sistemas NoSQL geralmente permitem abordagens sem esquema ou com esquema na leitura. O ERD é uma orientação, e não uma lei.
- Adicionando Campos: Você pode adicionar novos campos a documentos específicos sem afetar os outros.
- Versionamento: É comum adicionar números de versão aos documentos para gerenciar diferentes estruturas ao longo do tempo.
- Compromisso: A falta de aplicação de regras significa que problemas de qualidade dos dados podem surgir. O aplicativo deve validar os dados antes de gravá-los.
Implicações de Desempenho das Escolhas de Modelagem ⚡
A estrutura do seu ERD afeta diretamente a velocidade das consultas. Não existe uma solução única para todos os casos; o design deve estar alinhado com os padrões de acesso da aplicação.
1. Cargas de trabalho com leitura intensiva
Se o aplicativo lê dados com frequência, mas atualiza com pouca frequência, a desnormalização é vantajosa.
- Estratégia: Incorporar dados relacionados para reduzir o número de consultas necessárias.
- Benefício: Menos operações de E/S e menor latência.
- Custo: Uso aumentado de armazenamento e lógica de atualização complexa.
2. Cargas de trabalho com escrita intensiva
Se o aplicativo atualiza dados com frequência, prefere-se a normalização ou armazenamento separado.
- Estratégia: Armazene os dados na sua forma mais atômica e faça junções ou referências no momento da consulta.
- Benefício: Única fonte de verdade; as atualizações ocorrem em um único local.
- Custo: Maior latência de leitura devido a junções ou múltiplas consultas.
3. Estratégias de Indexação
Independentemente do tipo de banco de dados, o ERD indica onde os índices são necessários.
- Relacional: Índices são colocados em chaves estrangeiras e colunas usadas em
WHEREcláusulas. - Documento:Os índices são colocados em campos que são consultados com frequência. Campos aninhados podem exigir uma sintaxe específica de indexação.
- Gráfico:Os índices são colocados em rótulos de nós e propriedades de arestas para acelerar os pontos de início da navegação.
Ambientes Híbridos e Persistência Poliglota 🧩
Arquiteturas modernas frequentemente usam várias tecnologias de banco de dados simultaneamente. Isso é conhecido como persistência poliglota. A semântica do ERD deve preencher essas lacunas.
1. Padrões de Consistência de Dados
Quando os dados se estendem por múltiplos sistemas, a consistência torna-se complexa.
- ACID:Bancos de dados relacionais oferecem consistência forte. As transações abrangem múltiplas tabelas dentro do mesmo banco de dados.
- BASE:Bancos de dados NoSQL frequentemente favorecem a disponibilidade e a consistência eventual. As transações podem ser limitadas a um único documento.
- Padrão Saga:Para transações distribuídas entre sistemas, um padrão saga gerencia operações de longa duração coordenando transações locais.
2. O Papel do ERD em Sistemas Híbridos
O ERD atua como um mapa conceitual. Ele define as relações lógicas, mesmo que o armazenamento físico difira.
- Mapeamento:Desenvolvedores usam o ERD para decidir quais dados vão para qual armazenamento.
- Integração:O diagrama ajuda a visualizar onde a sincronização de dados é necessária entre os sistemas.
- Documentação:Oferece uma visão unificada para os interessados que podem não entender as diferenças técnicas entre os motores de armazenamento.
Melhores Práticas para Modelagem de Dados Robusta 🛡️
Para garantir manutenibilidade e desempenho de longo prazo, siga esses princípios ao projetar seus ERDs.
- Compreenda o Domínio:Comece com os requisitos de negócios. Não modele dados que não apoiem um caso de uso específico.
- Escolha a Ferramenta Certa:Escolha o tipo de banco de dados com base nas relações de dados, e não apenas em tendências. Use grafos para redes complexas, documentos para conteúdo e SQL para transações.
- Documente Relacionamentos Explicitamente:Marque claramente a cardinalidade no diagrama. Ambiguidade leva a erros na implementação.
- Planeje o Crescimento: Considere como o volume de dados crescerá. Um array embutido se tornará muito grande? Uma tabela de junção se tornará um gargalo?
- Itere o Design: Diagramas ER não são estáticos. Aperfeiçoe-os conforme a aplicação evolui e novas restrições forem descobertas.
- Valide na Camada de Aplicação: Especialmente no NoSQL, implemente lógica de validação para garantir a integridade dos dados, já que o banco de dados pode não enforceá-la.
Conclusão sobre Semântica de Modelagem 📝
As semânticas de um Diagrama de Relacionamento de Entidades não são universais; elas se adaptam à tecnologia de armazenamento subjacente. Em sistemas relacionais, o ERD é um contrato imposto pelo motor do banco de dados. Em sistemas NoSQL, é um guia de padrões para a camada de aplicação. Compreender essas diferenças permite que arquitetos projetem sistemas que sejam escaláveis e consistentes ao mesmo tempo.
Ao analisar cuidadosamente a cardinalidade, escolher o modelo de armazenamento apropriado e antecipar mudanças futuras, as equipes podem construir camadas de dados que suportem lógica de negócios complexa sem comprometer o desempenho. A chave está em alinhar o modelo lógico com as capacidades físicas do ambiente escolhido.
Independentemente de trabalhar com tabelas, documentos ou grafos, os princípios fundamentais de identificar entidades e definir suas conexões permanecem constantes. Um ERD claro serve como a base para uma arquitetura de software confiável, pontuando a lacuna entre requisitos de negócios e implementação técnica.