











O modelamento de dados é frequentemente a estrutura invisível de qualquer aplicativo de software. Enquanto o código que executa a lógica de negócios recebe a atenção, o esquema por trás dele determina desempenho, escalabilidade e manutenibilidade. Para muitos engenheiros júnior, o Diagrama de Relacionamento de Entidades (ERD) é uma tarefa simples de desenhar caixas e conectar linhas. No entanto, essa simplicidade é enganosa. Um ERD mal construído gera uma dívida que se acumula com o tempo, levando a consultas complexas, problemas de integridade de dados e migrações difíceis.
Este guia explora a lacuna oculta de complexidade. Identifica onde ocorre a desconexão entre o conhecimento teórico e a aplicação prática. Ao compreender esses pontos fracos, os desenvolvedores podem ir além do simples diagramação para um pensamento arquitetônico verdadeiro.
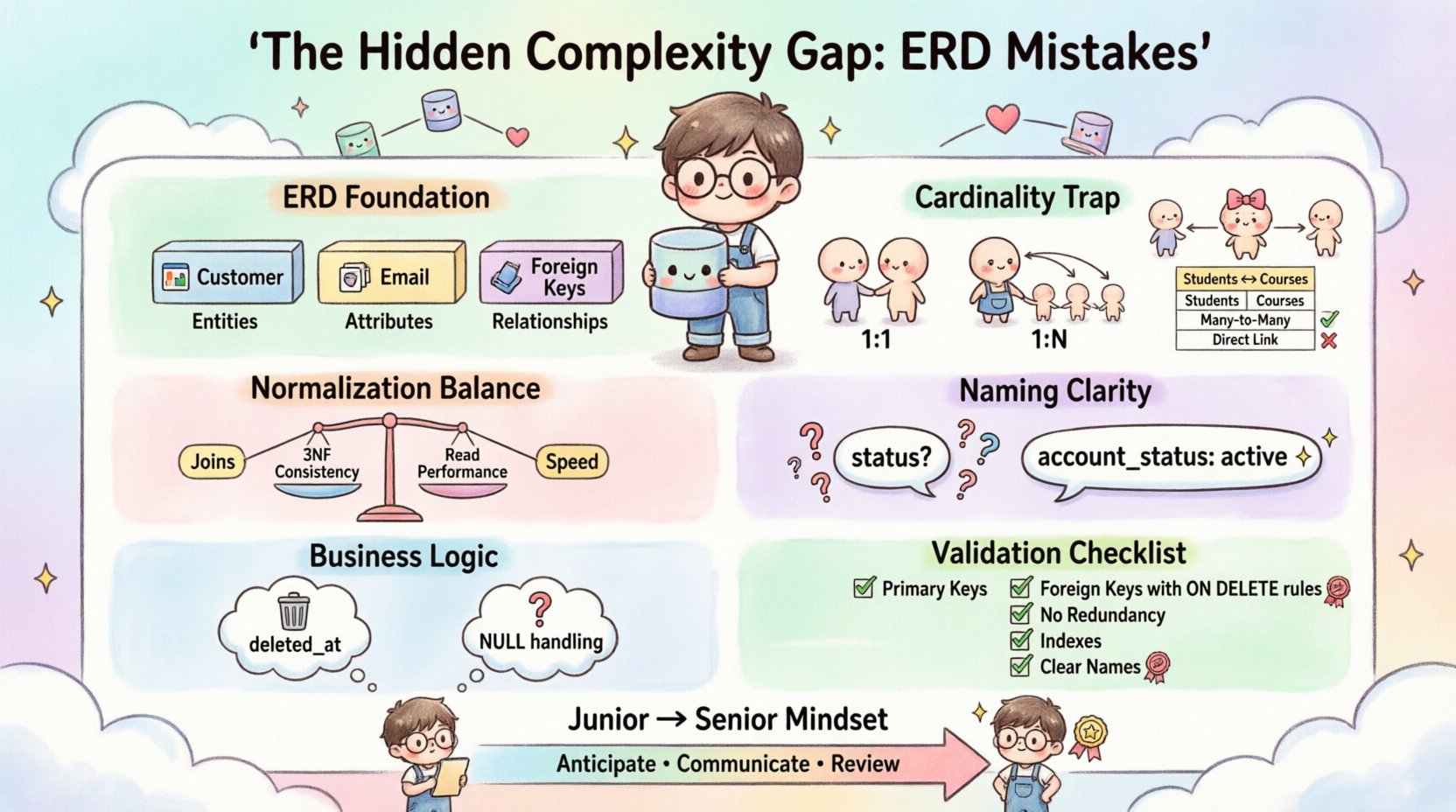
1. Compreendendo a Fundação do Modelamento de Dados 🏗️
Antes de mergulhar nos erros, é essencial estabelecer o que um ERD realmente representa. Ele não é meramente um desenho; é um contrato entre a aplicação e a camada de armazenamento. Um ERD visualiza entidades (tabelas), atributos (colunas) e relacionamentos (chaves estrangeiras).
Quando um engenheiro trata isso como um artefato estático criado uma vez e depois esquecido, ele ignora a natureza dinâmica dos dados. Os modelos de dados evoluem conforme os requisitos de negócios mudam. Um engenheiro júnior pode se concentrar na funcionalidade imediata, como armazenar o nome de um usuário, ignorando como esse usuário interage com outras entidades, como pedidos, assinaturas ou registros.
- Entidades: Elas representam objetos ou conceitos do mundo real (por exemplo, Cliente, Produto, Fatura).
- Atributos: São as propriedades que definem a entidade (por exemplo, E-mail, Preço, Data).
- Relacionamentos: Eles definem como as entidades interagem (por exemplo, Um-para-Muitos, Muitos-para-Muitos).
Um modelo robusto leva em conta o crescimento futuro. Ele antecipa como um “Cliente” pode se tornar um “Usuário” ou como um “Produto” pode precisar de variações. O diagrama inicial deve ser flexível o suficiente para acomodar essas mudanças sem exigir uma reconstrução completa.
2. A Armadilha da Cardinalidade: Interpretação Incorreta de Relacionamentos 🔄
A cardinalidade é a fonte mais comum de falhas estruturais no design de banco de dados. Ela define a relação numérica entre instâncias de entidades. O entendimento incorreto disso leva a armazenamento ineficiente e lógica de junção complexa.
Cenários Comuns de Cardinalidade
Engenheiros frequentemente optam pela relação mais óbvia sem considerar casos extremos. Considere os seguintes cenários em que suposições levam a erros:
- Um-para-Um (1:1):Freqüentemente sobreutilizado. Se duas entidades têm uma relação 1:1, elas geralmente devem ser mescladas em uma única tabela para reduzir a sobrecarga de junção, a menos que seja necessária uma separação de segurança rígida.
- Um-para-Muitos (1:N): A relação mais frequente. Um registro Pai está relacionado a múltiplos registros Filhos. A chave estrangeira deve residir no lado do Filho.
- Muitos-para-Muitos (M:N): É aqui que a lacuna de complexidade se amplia. Uma relação M:N direta não é fisicamente possível em um modelo relacional sem uma tabela intermediária.
Tabela: Erros na Implementação de Cardinalidade
| Cenário | Abordagem Incorreta | Abordagem Correta |
|---|---|---|
| Alunos e Cursos | Adicionando uma coluna “CourseID” na tabela “Student” | Criando uma tabela de junção “Student_Course” |
| Pedidos e Produtos | Inserindo detalhes do produto diretamente na tabela de Pedidos | Vinculando por meio de uma tabela OrderItems |
| Funcionários e Departamentos | Permitindo que um funcionário pertença a múltiplos departamentos sem uma tabela de junção | Separando a relação de mapeamento |
Quando engenheiros tentam forçar uma relação muitos para muitos em uma única tabela repetindo dados, introduzem redundância. Se o preço de um produto mudar, ele precisa ser atualizado em cada registro de pedido onde esse produto aparecer. Isso viola os princípios de normalização e cria pesadelos de manutenção.
3. Mitos de Normalização e Verificações de Realidade 📉
A normalização é um conceito padrão ensinado em ambientes acadêmicos. O objetivo é reduzir a redundância de dados e melhorar a integridade. No entanto, engenheiros júnior frequentemente normalizam em grau extremo (até 5NF) sem considerar os trade-offs de desempenho.
A Armadilha da Sobrenormalização
Um esquema sobrenormalizado divide os dados em demasiadas tabelas. Embora isso garanta consistência, força a aplicação a realizar joins excessivos. Cada join adiciona custo computacional. Em sistemas de alta carga, isso pode se tornar um gargalo.
- 1FN (Primeira Forma Normal):Valores atômicos. Nenhuma lista em uma única célula.
- 2FN (Segunda Forma Normal):Sem dependências parciais. Todos os atributos não-chave devem depender da chave primária inteira.
- 3FN (Terceira Forma Normal):Sem dependências transitivas. Os atributos não devem depender de outros atributos não-chave.
Um erro comum é assumir que a 3FN é sempre o objetivo. Em alguns casos, a desnormalização é uma escolha de design deliberada. Por exemplo, armazenar um “Valor Total do Pedido” diretamente na tabela de Pedidos evita o cálculo da soma dos itens toda vez que o pedido é exibido. Isso troca desempenho de gravação por desempenho de leitura.
Tabela: Normalização vs. Desnormalização
| Fator | Normalizado (3FN) | Desnormalizado |
|---|---|---|
| Redundância de Dados | Baixa | Alta |
| Velocidade de Gravação | Rápido | Mais lento |
| Velocidade de Leitura | Mais lento (mais joins) | Rápido |
| Integridade dos Dados | Alto | Mais Baixo (Requer Lógica) |
A decisão de denormalizar deve ser orientada por dados. Ela não deve acontecer arbitrariamente. Os engenheiros precisam analisar o desempenho das consultas antes de mesclar tabelas. Seguir cegamente as regras de normalização sem contexto leva a sistemas que são consistentes, mas lentos.
4. Convenções de Nomeação e Clareza Semântica 🏷️
Os nomes de esquema são o vocabulário do banco de dados. Se o vocabulário for ambíguo, o sistema torna-se incompreensível para desenvolvedores futuros. Esse é um problema frequente em que a precisão técnica é sacrificada pela brevidade.
Um campo chamado status é perigoso. O que isso significa? É uma conta ativa? Um pagamento pendente? Um registro excluído? Sem contexto, o significado se perde. Da mesma forma, usar nomes no plural para tabelas (por exemplo, Usuários) em vez de singular (por exemplo, Usuário) cria inconsistência.
- Consistência: Se uma tabela usa
snake_case, todas devem usarsnake_case. - Descritividade: Use nomes que descrevam os dados, e não apenas o formato. Evite termos genéricos como
tabela1oudados. - Contexto: Inclua o nome da entidade na chave de relacionamento se houver ambiguidade. Use
id_usuarioem vez de apenasidquando possível.
Considere o cenário de um sistema com vários tipos de usuários: Administradores, Clientes e Fornecedores. Uma única tabela chamada Usuários pode conter uma papel coluna. Esse é uma “Tabela de Deus”. Uma abordagem melhor é usar tabelas separadas ou uma estratégia clara de herança. Essa distinção se torna crítica quando permissões e regras de acesso a dados divergem significativamente entre papéis.
5. Ignorar a Lógica de Negócio no Projeto Técnico 🧠
A maior diferença entre engenheiros júnior e sênior está no entendimento da lógica de negócios. Um engenheiro júnior pode criar um esquema que atende perfeitamente aos requisitos atuais do código, mas falha quando as regras de negócios mudam.
O Equívoco do “Exclusão Suave”
Muitos desenvolvedores simplesmente adicionam uma deleted_at coluna em uma tabela. Isso funciona em casos simples. No entanto, se um usuário for excluído, seus registros associados devem ser excluídos? Os registros financeiros devem permanecer para conformidade com auditorias? O ERD deve refletir essas restrições por meio de restrições e gatilhos, e não apenas no código da aplicação.
O Problema do “Null”
Permitir valores NULL frequentemente é fonte de complexidade oculta. Em alguns casos, NULL tem significado semântico diferente de uma string vazia ou zero. Se um campo for opcional, o ERD deve indicar claramente isso. No entanto, depender de NULLs para controle de lógica é desencorajado.
- Integridade Referencial: Chaves estrangeiras idealmente não devem ser NULL, a menos que a relação seja verdadeiramente opcional.
- Cálculos: Valores NULL se propagam em cálculos, resultando em resultados NULL. Isso pode quebrar consultas de agregação.
- Índices: O tratamento de NULLs em índices varia conforme o motor de banco de dados, potencialmente afetando o desempenho de consultas.
6. A Carga de Manutenção de um Projeto Ruim 🔧
A dívida técnica não é apenas sobre código lento; é sobre rigidez estrutural. Um ERD mal projetado torna as mudanças dolorosas. Quando chega uma nova exigência, como adicionar um “Endereço de Cobrança” separado do “Endereço de Entrega”, o engenheiro deve avaliar se o esquema atual suporta isso.
Pesadelos de Migração
Alterar o esquema de um banco de dados de produção com milhões de registros exige planejamento cuidadoso. Se o ERD não foi projetado levando em conta migrações, alterar o tipo de uma coluna ou dividir uma tabela pode travar o sistema por horas. Esse tempo de inatividade afeta receita e confiança do usuário.
Estratégias para mitigar isso incluem:
- Controle de Versão para o Esquema: Trate a estrutura do banco de dados como código da aplicação.
- Compatibilidade com Versões Anteriores: Adicione colunas antes de remover as antigas. Mantenha as colunas antigas até que a migração esteja completa.
- Documentação: O ERD deve ser a fonte da verdade. Se ele não corresponder ao banco de dados, o banco de dados está errado.
7. Checklist Prático para Validação do ERD ✅
Para garantir um design robusto, os engenheiros devem passar por uma checklist de validação antes de finalizar o diagrama. Esse processo ajuda a identificar erros lógicos antes do início da implementação.
Validação Pré-Implementação
| Verificação | Pergunta | Critérios de Aprovação |
|---|---|---|
| Chaves Primárias | Cada tabela possui um identificador único? | Sim, auto-incremento ou UUID |
| Chaves Estrangeiras | As relações estão explicitamente definidas? | Sim, com regras ON DELETE/UPDATE |
| Redundância | Alguma informação está armazenada em mais de um local? | Não, a menos que a desnormalização seja intencional |
| Escalabilidade | Isso pode lidar com 10 vezes o volume atual de dados? | Índices existem nas chaves estrangeiras |
| Legibilidade | Um novo contratado consegue entender o fluxo em 5 minutos? | Convenções de nomeação claras |
8. Ferramentas vs. Conceitos 🛠️
É fácil depender dos recursos de uma ferramenta específica para resolver problemas de design. No entanto, a ferramenta é secundária em relação ao conceito. Seja usando uma ferramenta de modelagem visual ou escrevendo scripts SQL diretamente, a lógica subjacente permanece a mesma.
Alguns engenheiros criam diagramas que parecem perfeitos visualmente, mas são sintaticamente impossíveis no banco de dados alvo. Por exemplo, algumas ferramentas permitem dependências circulares na camada visual, enquanto o motor do banco de dados as rejeitará. O foco deve permanecer nas regras de integridade relacional, e não na interface de desenho.
- Consistência Visual: Use símbolos padrão para relacionamentos (notação de pé de corvo).
- Validação: Execute o esquema em um banco de dados de teste para verificar as restrições.
- Colaboração:Revise o diagrama com partes interessadas que compreendam o domínio do negócio, e não apenas colegas técnicos.
9. Cenários do Mundo Real de Falhas ⚠️
Compreender conceitos abstratos é uma coisa; ver esses conceitos falharem na prática é outra. Abaixo estão cenários comuns em que um mau design de ERD leva a problemas concretos.
Cenário A: O Loop Infinito
Um desenvolvedor cria uma relação entre Usuários e Equipesonde um usuário pertence a uma equipe, e uma equipe é liderada por um usuário. Se a chave estrangeira aponta para a mesma tabela sem uma raiz clara, ocorrem erros de referência circular durante a inserção. O ERD deve distinguir claramente entre as relações “Membro” e “Líder”.
Cenário B: A Perda Silenciosa de Dados
Uma Ordem tabela referencia uma Produto tabela. A ON DELETE restrição está definida como CASCADE. Quando um produto é removido do catálogo, todas as ordens associadas são excluídas. Isso destrói os dados históricos de vendas. O ERD deve definir explicitamente a ação referencial como RESTRICT ou SET NULL dependendo da necessidade do negócio.
Cenário C: A Busca Lenta
Uma tabela é criada com uma nomecoluna. Engenheiros consultam esta tabela com frequência para encontrar usuários pelo nome. Sem um índice definido na fase de design, o banco de dados realiza uma varredura completa da tabela. O ERD deve indicar quais colunas são intensivas em busca e exigem indexação.
10. Evoluindo do Pensamento de Júnior para Sênior 🚀
A transição envolve mudar o foco de “Funciona?” para “Escalável?” e “Mantido?”.
- Antecipação: Antecipe requisitos futuros com base nas tendências da indústria.
- Comunicação: Traduza restrições técnicas em riscos para o negócio.
- Revisão: Nunca assuma que um diagrama está correto sem revisão por pares.
Engenheiros júnior geralmente trabalham de forma isolada. Engenheiros sênior colaboram. O ERD é uma ferramenta de comunicação. Ele fecha a lacuna entre desenvolvedores, gerentes de produto e partes interessadas. Se o diagrama for confuso, as expectativas estarão desalinhadas.
Pensamentos Finais sobre a Integridade dos Dados 🎯
Construir um esquema de banco de dados não é uma tarefa única; é uma disciplina contínua. A lacuna de complexidade existe porque os riscos são altos. Um erro no código da aplicação pode ser corrigido rapidamente. Um erro no modelo de dados frequentemente exige uma migração, limpeza de dados e tempo de inatividade.
Ao seguir princípios rigorosos de modelagem, compreender profundamente a cardinalidade e priorizar a lógica de negócios em vez da conveniência, os engenheiros podem fechar essa lacuna. O objetivo não é criar um diagrama perfeito, mas sim construir uma base que suporte a evolução do software. Os dados são o ativo mais valioso que uma aplicação possui. Proteger sua estrutura é responsabilidade de cada engenheiro envolvido no processo de construção.
Dê o tempo necessário para revisar seus diagramas. Questione cada relacionamento. Verifique cada restrição. O tempo investido na fase de design poupa meses de esforço na fase de manutenção.