











Model C4 stał się standardem wizualizacji architektury oprogramowania, oferując jasną hierarchię od Kontekstu do Kontenera, Składnika i Kodu. Jednak wzrost obliczeń bezserwerowych wprowadza unikalne wyzwania dla tego statycznego modelu. Funkcje bezserwerowe są chwilowe, wyzwalane zdarzeniami i często zarządzane przez dostawców chmury, co czyni ich reprezentację w strukturalnym diagramie nieprostą. Ten przewodnik szczegółowo opisuje, jak dokładnie modelować architektury bezserwerowe z wykorzystaniem zasad C4, nie zależnie od konkretnych narzędzi dostawcy. 📚
Rozumienie napięcia: C4 wobec bezserwerowości 🤔
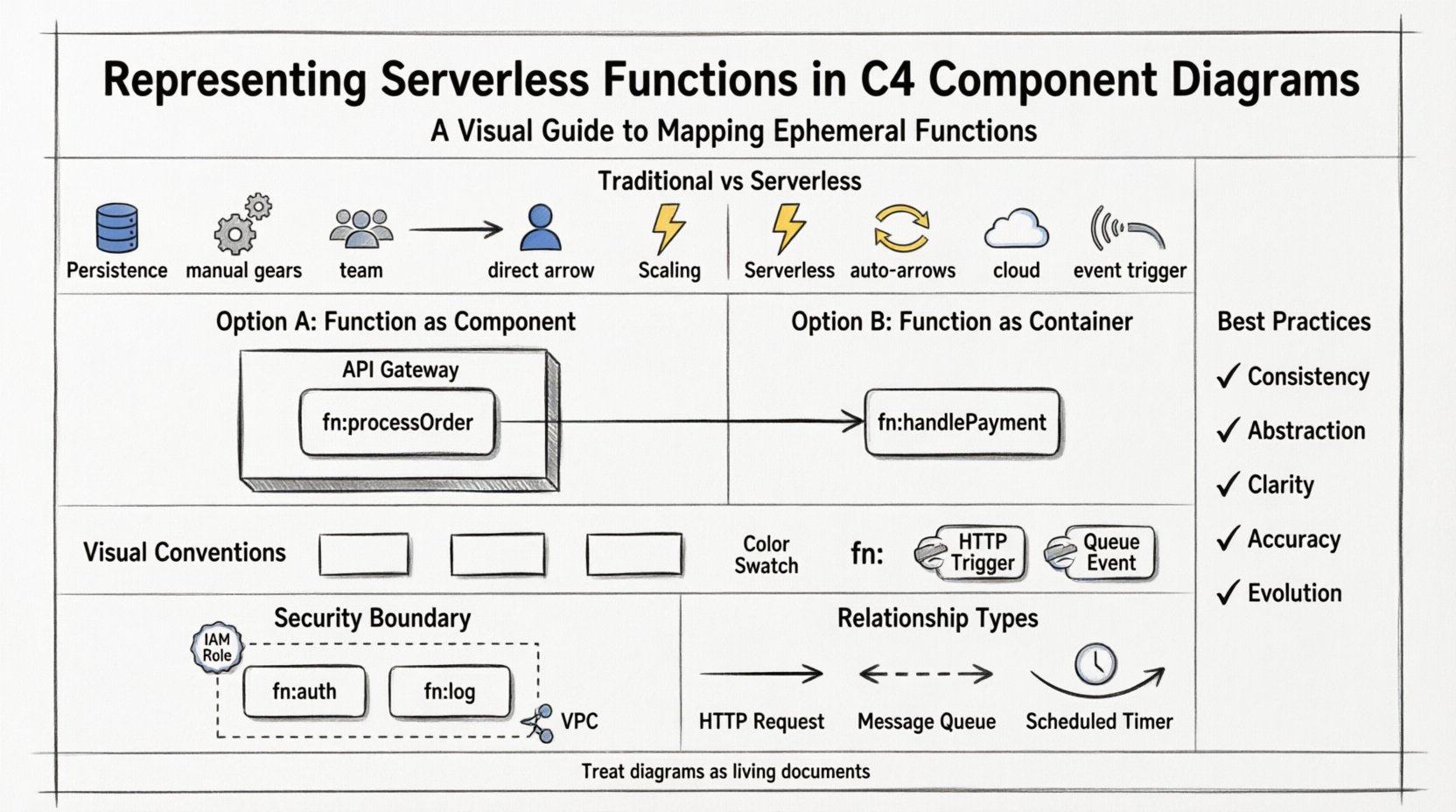
Model C4 został zaprojektowany z myślą o tradycyjnych strukturach aplikacji. Zakłada pewien poziom trwałej pamięci i stanu wewnątrz kontenerów. Funkcje bezserwerowe z kolei są zaprojektowane jako bezstanowe i skalowane na żądanie. Gdy próbujesz przypisać funkcję do składnika C4, pojawiają się pytania dotyczące granic, cyklu życia i własności. Bez jasnych wytycznych diagramy mogą stać się zatłoczone lub mylące, zakrywając rzeczywisty przepływ danych i sterowania. Musimy dostosować model, aby odzwierciedlał dynamiczny charakter współczesnej infrastruktury chmury. 🌥️
Aby wypełnić tę przerwę, musimy zrozumieć podstawowe różnice:
- Trwałość:Tradycyjne kontenery często utrzymują stan w pamięci. Funkcje bezserwerowe tego nie robią. Są niszczone po wykonaniu.
- Skalowanie:Kontenery skalują się za pomocą koordynacji (np. Kubernetes). Bezserwerowe skalują się automatycznie w zależności od ilości zdarzeń.
- Właścicielstwo:Kontenery są często zarządzane przez zespół programistów. Środowiska wykonawcze bezserwerowe są zarządzane przez dostawcę chmury.
- Punkty wejścia:Interfejsy API są często wyzwalaczem funkcji bezserwerowych, a nie bezpośrednią interakcją użytkownika z trwającym procesem.
Mapowanie bezserwerowości na hierarchię C4 🗺️
Gdzie znajdują się funkcje bezserwerowe w hierarchii C4? Odpowiedź zależy od poziomu szczegółowości wymaganego przez odbiorcę. Nie ma jednej poprawnej odpowiedzi, ale są najlepsze praktyki zapewniające jasność. 🛠️
Opcja 1: Bezserwerowość jako składnik ⚙️
To najpowszechniejszy sposób. Traktujesz funkcję bezserwerową jakoskładnik wewnątrzkontenera. Kontener reprezentuje usługę logiczną lub bramę interfejsu API, która kieruje ruch do funkcji. To rozdzielenie jest kluczowe, ponieważ oddziela punkt wejścia (bramę) od wykonania logiki (funkcji).
- Kontener:Brama interfejsu API lub balansujący obciążenie, która akceptuje żądania HTTP.
- Składnik:Określona funkcja bezserwerowa przetwarzająca żądanie.
- Zalety:Jasno rozdziela kwestie routingu od logiki biznesowej.
Opcja 2: Bezserwerowość jako kontener 📦
W niektórych przypadkach pojedyncza funkcja działa jako pełny punkt wejścia dla mikroserwisu. Jeśli funkcja bezpośrednio obsługuje logikę interfejsu API i dostęp do danych, może być modelowana jako kontener. Jest to często stosowane dla mniejszych, samodzielnych usług, gdzie koszt definiowania osobnego kontenera bramy jest niepotrzebny.
- Kontener: Sam funkcja bezserwerowa.
- Granica: Funkcja sama obsługuje walidację danych wejściowych i formatowanie danych wyjściowych.
- Zalety: Uproszcza schematy dla małych aplikacji bezserwerowych.
Tabela porównawcza: Strategie umiejscowienia 📊
| Strategia | Najlepsze zastosowanie | Złożoność | Przejrzystość |
|---|---|---|---|
| Funkcja jako komponent | Dojrzałe mikroserwisy z wyraźnymi bramami | Średnia | Wysoka |
| Funkcja jako kontener | Proste funkcje jednokierunkowe | Niska | Średnia |
| Wiele funkcji jako komponenty | Złożone przepływy pracy z koordynacją | Wysoka | Wysoka |
Zasady wizualne dla bezserwerów 🎨
Spójność w reprezentacji wizualnej pomaga stakeholderom szybko identyfikować elementy bezserwerowe. Choć model C4 nie nakłada obowiązku używania konkretnych ikon, przyjęcie zasad ułatwia czytelność. Używaj standardowych kształtów komponentów, ale dodaj wizualne wskazówki wskazujące cechy bezserwerowe.
Ikony i stylizacja
- Kształt: Użyj standardowego prostokąta komponentu (zakrzywionego lub kwadratowego).
- Kodowanie kolorów: Przypisz określony kolor (np. jasny szary lub konkretny akcent) wszystkim komponentom bezserwerowym, aby odróżnić je od trwałych kontenerów.
- Etykiety: Poprzedź nazwy funkcji znakiem
fn:lubfunc:aby wskazać ich chwilowy charakter. - Adnotacje: Dodaj tekst wskazujący środowisko uruchomieniowe lub typ wyzwalacza (np. „Wyzwalacz HTTP”, „Zdarzenie kolejki”).
Wskazywanie chwilowego charakteru
Ponieważ funkcje bezserwerowe są niszczone po wykonaniu, możesz użyć linii przerywanych lub specjalnych stylów obramowania, aby to sugerować. Jednak standardowe linie pełne są często preferowane pod kątem jasności odniesień logicznych. Kluczem jest dokumentowanie cyklu życia w notatkach do diagramu, a nie wyłącznie opieranie się na stylach linii.
Modelowanie relacji i zależności 🔗
Zrozumienie, jak funkcje bezserwerowe oddziałują na inne części systemu, jest kluczowe. Relacje w diagramach C4 reprezentują przepływ danych i zależności, a nie tylko łączność sieciową.
Relacje wyzwalaczy
Funkcje bezserwerowe są zwykle sterowane zdarzeniami. Musisz jasno przedstawić źródło tych zdarzeń.
- Żądania HTTP: Połącz kontener API Gateway z komponentem funkcji za pomocą relacji „Żądanie”.
- Kolejki komunikatów: Jeśli funkcja pobiera komunikaty z kolejki, narysuj relację od kontenera kolejki do komponentu funkcji.
- Zegary: W przypadku zadań zaplanowanych wskazuj relację „Harmonogram” od kontenera harmonogramu.
Kwestie przepływu danych
Funkcje bezserwerowe często przetwarzają dane bez długotrwałego przechowywania. Upewnij się, że twój diagram odzwierciedla ten bezstanowy charakter.
- Stan tymczasowy: Jeśli dane są przechowywane w pamięci podczas wykonywania, nie modeluj ich jako komponentu bazy danych.
- Przechowywanie trwałego: Połącz funkcję z zewnętrznymi usługami przechowywania (np. przechowywanie obiektów lub bazy danych) jasno. Nie zakładaj, że funkcja posiada dane.
- Wyjście: Jasno pokaż, gdzie trafia wynik funkcji (np. odpowiedź dla klienta lub komunikat do innej kolejki).
Bezpieczeństwo i granice 🔒
Bezpieczeństwo często pomijane jest w diagramach architektury najwyższego poziomu, ale jest kluczowe dla rozwiązań bezserwerowych. Zarządzanie tożsamością i dostępem (IAM) odgrywa tu większą rolę niż w tradycyjnych aplikacjach kontenerowych.
Definiowanie granic bezpieczeństwa
Każda funkcja bezserwerowa powinna mieć zdefiniowaną granicę bezpieczeństwa. Na diagramie grupuj funkcje, które współdzielą te same role IAM lub zasady sieciowe. Pomaga to w audycji i zrozumieniu rozprzestrzenienia uprawnień.
- Grupowanie:Użyj granicy „Kontekst systemu” lub „Kontener” do grupowania funkcji według domeny bezpieczeństwa.
- Uprawnienia:Oznacz składniki poziomem dostępu wymaganym (np. „Tylko do odczytu”, „Dostęp administratora”).
- Sieć:Wskazuj, czy funkcja działa w prywatnej chmurze (VPC) lub jest publicznie dostępna.
Uwierzytelnianie i autoryzacja
Zamodeluj przepływ tokenów uwierzytelniających. Czy funkcja sama weryfikuje token, czy opiera się na bramie API? Ta różnica wpływa na to, gdzie znajduje się logika bezpieczeństwa w architekturze.
Typowe pułapki i wyzwania ⚠️
Modelowanie architektur bezserwerowych wiąże się z określonymi wyzwaniami, które mogą prowadzić do niepoprawnych diagramów, jeśli nie zostaną rozwiązane.
Zbyt szczegółowe modelowanie
Łatwo się zgubić w szczegółach każdej funkcji. Jeśli masz setki małych funkcji, nie modeluj każdej z nich osobno na diagramie składników. Połącz je w logiczne grupy lub składniki wyższego poziomu.
- Zasada ogólna:Jeśli składnik jest zbyt mały, aby mieć własną charakterystyczną zachowanie, połącz go z rodzicem.
- Abstrakcja:Użyj składnika „Usługa” do przedstawienia grupy powiązanych funkcji.
Ignorowanie chłodnych startów
Choć nie jest to bezpośrednio element wizualny, pojęcie „chłodnych startów” (opóźnienie podczas inicjalizacji funkcji) wpływa na architekturę. Możesz chcieć oznaczyć składniki, w których opóźnienie jest krytyczne. To wpływa na decyzje dotyczące przypisanej konkurencji lub warstw buforowania.
Zakładanie synchronicznego wykonania
Wiele funkcji bezserwerowych działa asynchronicznie. Nie modeluj ich tak, jakby zawsze zwracały bezpośredni odpowiedź HTTP. Użyj różnych typów relacji (np. „Wystrzel i zapomnij” lub „Zdarzenie”), aby oznaczyć przepływy asynchroniczne.
Dokumentacja i utrzymanie 📝
Diagram C4 jest tak dobry, jak jego dokładność w czasie. Architektury bezserwerowe często się zmieniają. Aby utrzymać diagramy:
- Kontrola wersji:Przechowuj diagramy razem z kodem infrastruktury.
- Automatyzacja:Używaj narzędzi, które mogą generować diagramy z definicji kodu, jeśli to możliwe.
- Cykle przeglądu:Aktualizuj diagramy podczas retrospekcji sprintów lub przeglądów architektonicznych.
- Tagi: Użyj etykiet na diagramie, aby wskazać datę ostatniej przeglądu.
Zaawansowane scenariusze: koordynacja i stan 🔄
Złożone aplikacje bezserwerowe często obejmują koordynację. Możesz użyć silnika przepływu pracy do zarządzania serią funkcji. Jak to pasuje do modelu C4?
Silniki przepływu pracy
Zamodeluj silnik przepływu pracy jako Kontener. Poszczególne kroki w przepływie pracy są Komponentami. Oddziela to logikę sterowania (przepływ pracy) od logiki wykonania (funkcje).
- Kontener: Koordynator przepływu pracy.
- Komponent: Funkcja kroku A, funkcja kroku B.
- Zależność: „Wyzwania” lub „Koordynuje”.
Zarządzanie stanem
Jeśli Twoja aplikacja bezserwerowa wymaga stanu, musi on być zewnętrzny. Nie sugeruj istnienia stanu wewnątrz funkcji. Jawnie połącz funkcję z komponentem bazy danych lub pamięci podręcznej. To utrwala wzorzec bezstanowy w modelu wizualnym.
Podsumowanie najlepszych praktyk ✅
Aby zapewnić, że Twoje diagramy C4 pozostają skuteczne dla architektur bezserwerowych, przestrzegaj tych podstawowych zasad:
- Spójność: Używaj tej samej stylizacji wizualnej dla wszystkich komponentów bezserwerowych.
- Abstrakcja: Nie modeluj każdej pojedynczej funkcji, jeśli dodaje to szum.
- Przejrzystość: Jasno rozróżnij między wyzwalaczami, logiką i przechowywaniem danych.
- Dokładność: Odbij rzeczywiste granice wdrożenia i uprawnienia.
- Ewolucja: Traktuj diagramy jako żywe dokumenty, które ewoluują razem z kodem.
Ostateczne rozważania dotyczące wizualizacji architektury 🌟
Reprezentowanie funkcji bezserwerowych w modelu C4 wymaga zmiany nastawienia. Nie rysuj tylko pudełek; mapuj dynamiczne zachowania na statyczne reprezentacje. Przestrzegając tych wytycznych, tworzysz diagramy, które są skutecznymi narzędziami komunikacji dla programistów, architektów i stakeholderów. Celem nie jest tylko dokumentowanie tego, co istnieje, ale wyjaśnienie, jak system zachowuje się pod obciążeniem, podczas awarii i w różnych środowiskach. Dobrze narysowany diagram C4 dla architektury bezserwerowej zmniejsza niepewność i przyspiesza podejmowanie decyzji. 🚀
Pamiętaj, że wartość diagramu polega na zrozumieniu, które oferuje, a nie na skomplikowaniu rysunku. Zachowaj prostotę, dokładność i aktualizuj go regularnie. Ta metoda zapewnia, że Twoja architektura pozostanie zrozumiała w miarę ewolucji środowiska technologicznego. 🛠️