











सिस्टम विश्लेषण तकनीकी आवश्यकताओं और कार्यात्मक डिजाइन के बीच के अंतर को पार करने के लिए दृश्य संचार पर भारी निर्भरता करता है। उपलब्ध मॉडलिंग तकनीकों में से, डेटा फ्लो डायग्राम (DFD) एक मूल उपकरण के रूप में उभरता है जो जानकारी के सिस्टम के माध्यम से गति को मानचित्रित करने के लिए उपयोग किया जाता है। यह मार्गदर्शिका DFD के विस्तृत अवलोकन के साथ आती है, जिसमें उनके घटकों, संरचनाओं और अनुप्रयोगों को विस्तार से समझाया गया है, जिसमें किसी विशिष्ट सॉफ्टवेयर उत्पाद पर निर्भरता नहीं है। चाहे आप एक छात्र हों, एक व्यावसायिक विश्लेषक हों या एक विकासकर्ता हों, इन आरेखों को समझना स्पष्टता और सटीकता के लिए आवश्यक है।
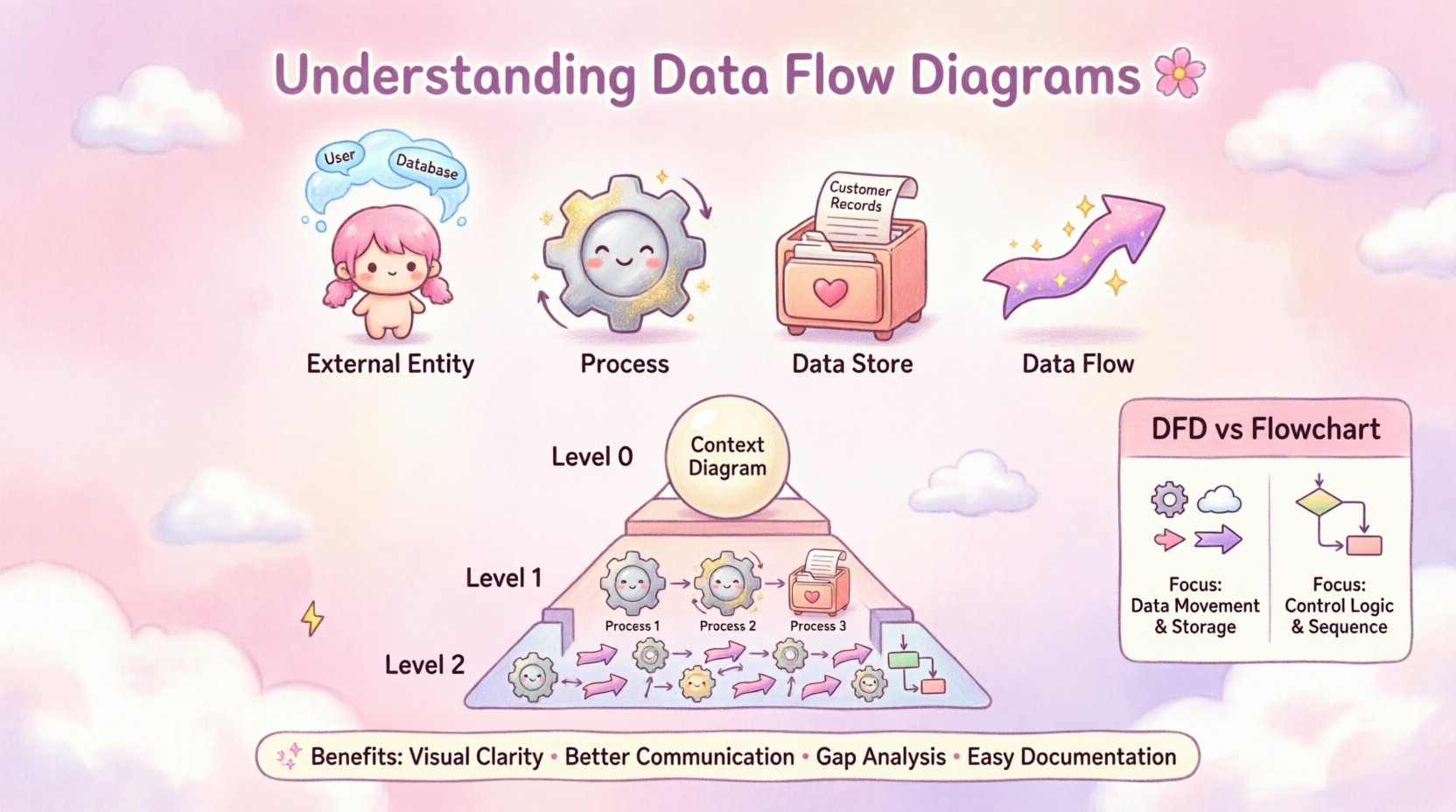
🧩 डेटा फ्लो डायग्राम क्या है?
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का दृश्य प्रतिनिधित्व है। कंप्यूटर प्रोग्राम फ्लोचार्ट्स के विपरीत जो नियंत्रण तर्क या निर्णय बिंदुओं पर ध्यान केंद्रित करते हैं, एक DFD केवल डेटापर ध्यान केंद्रित करता है। यह दिखाता है कि डेटा सिस्टम में कैसे प्रवेश करता है, इसे कैसे प्रसंस्कृत किया जाता है, इसे कहाँ संग्रहीत किया जाता है, और यह कहाँ से बाहर निकलता है। यह अंतर महत्वपूर्ण है क्योंकि यह क्याएक सिस्टम के कैसे.
एक DFD को डेटा ट्रैफिक के लिए एक मानचित्र के रूप में सोचें। यह विशिष्ट कोड या हार्डवेयर को नहीं दिखाता है, बल्कि जानकारी द्वारा अनुसरण किए जाने वाले तार्किक मार्गों को दिखाता है। इस अमूल्य अभिव्यक्ति के कारण स्टेकहोल्डर्स को तकनीकी कार्यान्वयन विवरणों में डूबने से पहले सिस्टम को उच्च स्तर पर समझने में सक्षम होते हैं।
- फोकस: डेटा के स्थानांतरण और परिवर्तन।
- दायरा: भौतिक कार्यान्वयन के बजाय तार्किक प्रक्रियाएँ।
- उपयोगकर्ता: व्यावसायिक विश्लेषक, सिस्टम डिजाइनर और प्रोजेक्ट प्रबंधक।
- आउटपुट: सिस्टम की सीमाओं और बातचीत का स्पष्ट दृश्य प्रतिनिधित्व।
🛠️ DFD के मुख्य घटक
एक वैध डेटा फ्लो डायग्राम बनाने के लिए, आपको उन चार मूल आकृतियों को समझना होगा जो डायग्राम का निर्माण करती हैं। प्रत्येक आकृति सिस्टम के भीतर एक विशिष्ट कार्य या एकता का प्रतिनिधित्व करती है। इन घटकों को समझना सटीक मॉडल बनाने की पहली कड़ी है।
1. बाहरी एकाइयाँ (👤)
बाहरी एकाइयाँ वे स्रोत या गंतव्य हैं जो मॉडल किए जा रहे सिस्टम की सीमा के बाहर स्थित हैं। वे सिस्टम से बातचीत करती हैं लेकिन उसका हिस्सा नहीं हैं। इनमें लोग, संगठन या अन्य सिस्टम शामिल हो सकते हैं।
- शब्दावली: समाप्तिकर्ता, स्रोत, निकास या अभिनेता के रूप में भी जाना जाता है।
- उदाहरण: एक ग्राहक आदेश देना, एक बैंक भुगतान प्रक्रिया करना, या एक बाहरी मौसम सेवा।
- भूमिका: डेटा इनपुट शुरू करता है या डेटा आउटपुट प्राप्त करता है।
2. प्रक्रियाएँ (⚙️)
प्रक्रियाएँ ऐसी क्रियाएँ हैं जो इनपुट डेटा को आउटपुट डेटा में बदलती हैं। वे डेटा के रूप, सामग्री या वितरण को बदलती हैं। प्रत्येक प्रक्रिया को वैध होने के लिए कम से कम एक इनपुट और कम से कम एक आउटपुट होना चाहिए।
- शब्दावली: कार्य, परिवर्तन या गतिविधियाँ।
- उदाहरण: कर की गणना, उपयोगकर्ता लॉगिन की पुष्टि, या बिल जनरेट करना।
- नियम: एक प्रक्रिया का अस्तित्व तभी हो सकता है जब उसमें डेटा के आने या बाहर निकलने की प्रवाह हो।
3. डेटा स्टोरेज (🗃️)
डेटा स्टोरेज सिस्टम के भीतर जानकारी कहाँ संग्रहीत होती है, इसका प्रतिनिधित्व करते हैं। यह एक भौतिक डेटाबेस सर्वर नहीं है, बल्कि एक तार्किक भंडारण है। इसका अर्थ है कि डेटा बाद में प्राप्त करने या उपयोग करने के लिए संग्रहीत किया जा रहा है।
- शब्दावली: फाइलें, डेटाबेस या भंडारण स्थल।
- उदाहरण: एक ग्राहक डेटाबेस, लेनदेन का लॉग, या अस्थायी कैश।
- अंतरक्रिया: डेटा भंडारण के लिए अंदर आता है और प्राप्त करने के लिए बाहर निकलता है।
4. डेटा प्रवाह (➡️)
डेटा प्रवाह एकता, प्रक्रियाओं और स्टोरेज के बीच डेटा के गति को दर्शाते हैं। इन्हें तीरों द्वारा दर्शाया जाता है। तीर की दिशा डेटा के लिए ली गई पथ को दर्शाती है। तीर पर लेबल डेटा की सामग्री का वर्णन करता है।
- शब्दावली: संयोजन, लिंक या प्रवाह।
- आवश्यकता: एक संज्ञा वाक्यांश (जैसे, “आदेश विवरण”) के साथ लेबल किया जाना चाहिए।
- नियम: तीरों को बिना किसी प्रक्रिया के बीच में डेटा स्टोरेज को सीधे पार नहीं करना चाहिए।
📊 नोटेशन शैलियों की तुलना
डेटा प्रवाह आरेख बनाने के लिए दो मुख्य शैलियाँ हैं। जबकि वे समान अवधारणाओं का प्रतिनिधित्व करती हैं, उपयोग किए जाने वाले प्रतीक थोड़े अलग होते हैं। अंतर को जानना अलग टीमों या विधियों द्वारा बनाए गए आरेखों के अर्थ समझने में मदद करता है।
| विशेषता | यूरडॉन और डीमार्को | गेन और सर्सन |
|---|---|---|
| प्रक्रियाएँ | गोल आयत | कोनों वाले आयत |
| बाहरी एंटिटीज | आयत | वर्ग |
| डेटा स्टोर | खुले छोर वाला आयत | खुला आयत |
| डेटा प्रवाह | तीर | तीर |
| लेबलिंग | प्रक्रिया वृत्तों पर संख्याएँ | प्रक्रिया आयतों पर संख्याएँ |
दोनों शैलियाँ मान्य हैं, लेकिन प्रोजेक्ट के भीतर सुसंगतता महत्वपूर्ण है। एक शैली चुनें और दस्तावेज़ीकरण के दौरान उसका पालन करें।
📉 विघटन के स्तर
डेटा प्रवाह आरेख अक्सर परतों में बनाए जाते हैं, जिसे विघटन के रूप में जाना जाता है। इससे आप एक उच्च स्तर के समीक्षा से शुरू कर सकते हैं और धीरे-धीरे विवरण जोड़ सकते हैं। एक जटिल प्रणाली को प्रबंधनीय टुकड़ों में बाँटने से आरेख पढ़ने और बनाए रखने में आसानी होती है।
स्तर 0: संदर्भ आरेख
संदर्भ आरेख सबसे ऊँचे स्तर के सारांश का प्रतिनिधित्व करता है। यह प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और इसके बाहरी एंटिटीज के साथ संबंध को दर्शाता है। यह प्रश्न का उत्तर देता है: “प्रणाली की सीमा क्या है?”
- परिधि: पूरी प्रणाली का प्रतिनिधित्व करने वाली एक केंद्रीय प्रक्रिया।
- विवरण: आंतरिक डेटा स्टोर या उप-प्रक्रियाओं को दिखाया नहीं गया है।
- उपयोग: स्टेकहोल्डर्स और प्रबंधन के लिए परिधि को परिभाषित करने के लिए उपयोग किया जाता है।
स्तर 1: विघटन
स्तर 1 संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में बाँटता है। इससे प्रणाली के मुख्य कार्यों का पता चलता है। यह प्रणाली डिज़ाइन के लिए उपयोग की जाने वाली सबसे आम विवरण स्तर है।
- विवरण: मुख्य प्रक्रियाओं, प्रमुख डेटा स्टोर और बाहरी एंटिटीज को दिखाता है।
- उपयोग: विकासकर्मियों द्वारा मुख्य कार्यात्मक क्षेत्रों को समझने के लिए उपयोग किया जाता है।
लेवल 2 और उससे आगे
अधिक विस्तार (लेवल 2, लेवल 3) विशिष्ट उप-प्रक्रियाओं में गहराई से जाता है। यह केवल उन जटिल कार्यों के लिए आवश्यक है जिनके लिए विस्तृत विवरण आवश्यक होता है।
- विवरण:लेवल 1 प्रक्रिया के भीतर बारीक चरण।
- उपयोग: विस्तृत तर्क विवरण या दस्तावेजीकरण के लिए उपयोग किया जाता है।
स्तरों के बीच सुसंगतता बनाए रखना महत्वपूर्ण है। लेवल 1 प्रक्रिया के इनपुट और आउटपुट को लेवल 0 आरेख में एकल प्रक्रिया के इनपुट और आउटपुट के साथ मेल बैठाना चाहिए। इसे कहा जाता हैसंतुलन.
🛣️ डेटा फ्लो डायग्राम कैसे बनाएं
DFD बनाना एक व्यवस्थित प्रक्रिया है। एक संरचित दृष्टिकोण का पालन करने से यह सुनिश्चित होता है कि परिणामी आरेख सही और उपयोगी हो। शुरुआत करने के लिए विशेष उपकरणों की आवश्यकता नहीं है; आप पेन और कागज से तर्क की खोज शुरू कर सकते हैं।
चरण 1: बाहरी एंटिटीज की पहचान करें
सबसे पहले यह तय करें कि कौन या क्या प्रणाली के साथ बातचीत करता है। सभी उपयोगकर्ताओं, विभागों या बाहरी प्रणालियों की सूची बनाएं जो प्रणाली को डेटा भेजते हैं या प्रणाली से डेटा प्राप्त करते हैं।
- प्रश्न: प्रक्रिया कौन शुरू करता है?
- प्रश्न: अंतिम परिणाम कौन प्राप्त करता है?
चरण 2: मुख्य प्रक्रिया को परिभाषित करें
पूरी प्रणाली का एकल बबल या आयत के रूप में प्रतिनिधित्व करें। यह आपका लेवल 0 आरेख है। बाहरी एंटिटीज को इस केंद्रीय प्रक्रिया से जोड़ने वाली तीर खींचें ताकि मुख्य डेटा इनपुट और आउटपुट दिखाई दें।
चरण 3: मुख्य प्रक्रिया को विभाजित करें
केंद्रीय प्रक्रिया को उप-प्रक्रियाओं में तोड़ें। इनपुट को आउटपुट में बदलने के लिए आवश्यक मुख्य कार्यों की पहचान करें। इन्हें स्पष्ट रूप से लेबल करें।
चरण 4: डेटा स्टोर जोड़ें
यह पहचानें कि डेटा कहाँ सहेजा जाना चाहिए। यदि किसी जानकारी की बाद में आवश्यकता हो या इतिहास के खिलाफ सत्यापित करनी हो, तो वह डेटा स्टोर में आता है। प्रक्रियाओं को इन स्टोर्स से जोड़ें।
चरण 5: डेटा फ्लो को लेबल करें
सुनिश्चित करें कि प्रत्येक तीर को लेबल दिया गया हो। लेबल एक्र्शन के बजाय डेटा का वर्णन करना चाहिए। उदाहरण के लिए, “इन्वॉइस डेटा” का उपयोग करें, “इन्वॉइस भेजें” के बजाय।
चरण 6: संतुलन के लिए समीक्षा करें
जांचें कि मुख्य प्रक्रिया के इनपुट और आउटपुट उप-प्रक्रियाओं के इनपुट और आउटपुट के योग के बराबर हैं। यदि कोई डेटा फ्लो बिना स्रोत के गायब हो जाता है या दिखाई देता है, तो आरेख संतुलित नहीं है।
🚫 बचने के लिए सामान्य गलतियाँ
यहां तक कि अनुभवी विश्लेषक भी प्रणाली के मॉडलिंग में गलतियां कर सकते हैं। सामान्य जाल में रहने के बारे में जागरूक होने से आप अधिक साफ और सटीक आरेख बना सकते हैं।
- काले छेद: केवल इनपुट वाली प्रक्रिया और कोई आउटपुट नहीं। डेटा आता है लेकिन कभी बाहर नहीं जाता, जिसका अर्थ है कि प्रणाली में त्रुटि है।
- चमत्कार: केवल आउटपुट वाली प्रक्रिया और कोई इनपुट नहीं। डेटा बिना किसी कारण के दिखाई देता है, जो तार्किक रूप से असंभव है।
- डेटा स्टोर त्रुटियाँ: एक प्रक्रिया के बिना डेटा स्टोर को बाहरी एजेंसी से सीधे जोड़ना। डेटा स्टोर से बाहरी स्रोत तक सीधे नहीं जा सकता।
- ओवरलैपिंग लेबल: नामवाचक शब्दों के बजाय क्रियाओं का उपयोग डेटा प्रवाह लेबल के लिए करना। डेटा प्रवाह नामवाचक शब्द होते हैं (जैसे “रिपोर्ट”), क्रियाओं (जैसे “रिपोर्ट जनरेट करें”) नहीं।
- लाइनों का प्रतिच्छेदन: कभी-कभी अनिवार्य हो सकता है, लेकिन लाइनों का प्रतिच्छेदन आरेख को पढ़ने में कठिन बना सकता है। प्रवाह को सुंदर तरीके से रास्ता देने की कोशिश करें।
🆚 डीएफडी बनाम फ्लोचार्ट्स
डेटा प्रवाह आरेखों और फ्लोचार्ट्स को गलती से एक दूसरे से भ्रमित करना आम बात है। दोनों में आकृतियाँ और तीर होते हैं, लेकिन उनके उद्देश्य अलग होते हैं। अंतर को समझने से सिस्टम डिजाइन के दौरान भ्रम से बचा जा सकता है।
| पहलू | डेटा प्रवाह आरेख (DFD) | फ्लोचार्ट |
|---|---|---|
| फोकस | डेटा गति और परिवर्तन | नियंत्रण प्रवाह और निर्णय तर्क |
| प्रक्रिया आकृति | वृत्त या गोल कोने वाला आयत | आयत |
| निर्णय | प्रतिनिधित्व नहीं किया गया | हीरे के आकार द्वारा प्रतिनिधित्व किया गया |
| लूपिंग | स्पष्ट रूप से नहीं दिखाया गया | तीरों के साथ स्पष्ट रूप से दिखाया गया |
| समय | समय से स्वतंत्र | समय से जुड़ा |
यदि आप चरणों के क्रम, निर्णय और लूप को वर्णित करना चाहते हैं, तो फ्लोचार्ट उपयुक्त है। यदि आप डेटा की आवश्यकताओं और स्टोरेज का वर्णन करना चाहते हैं, तो डीएफडी सही चयन है।
🌟 डेटा फ्लो डायग्राम्स के उपयोग के लाभ
इन डायग्राम्स को बनाने में समय निवेश करने का क्यों कारण है? मूल्य स्पष्टता और संचार में निहित है। एक अच्छी तरह से बनाया गया DFD प्रणाली की डेटा आवश्यकताओं के लिए एकमात्र सच्चाई का स्रोत के रूप में कार्य करता है।
- दृश्य स्पष्टता:जब जटिल प्रणालियों को दृश्य रूप में दिखाया जाता है, तो उन्हें समझना आसान हो जाता है।
- संचार:तकनीकी टीमों और व्यावसायिक हितधारकों के बीच के अंतर को पार करता है।
- अंतर विश्लेषण:अनुपस्थित डेटा प्रवाह या परिभाषित नहीं किए गए प्रक्रियाओं की पहचान करने में मदद करता है।
- दस्तावेज़ीकरण:भविष्य के प्रणाली रखरखाव और अपग्रेड के लिए आधार रेखा प्रदान करता है।
- परीक्षण:परीक्षकों को समझने में मदद करता है कि प्रत्येक चरण पर कौन सी डेटा की अपेक्षा की जानी चाहिए।
🔍 वास्तविक दुनिया के अनुप्रयोग उदाहरण
एक सरल पुस्तकालय प्रबंधन प्रणाली के बारे में सोचें। इस परिदृश्य के लिए DFD कैसा दिखेगा?
- बाहरी एकाधिकार:लाइब्रेरियन और सदस्य।
- प्रक्रिया:पुस्तक जारी करना, पुस्तक वापस करना, कैटलॉग खोजना।
- डेटा भंडार:पुस्तक भंडार, सदस्य रिकॉर्ड।
- प्रवाह:एक सदस्य एक पुस्तक मांगता है (इनपुट)। प्रणाली भंडार की जांच करती है (प्रक्रिया)। यदि उपलब्ध है, तो यह रिकॉर्ड को अद्यतन करती है (प्रक्रिया)। पुस्तक जारी की जाती है (आउटपुट)।
यह उदाहरण दिखाता है कि डेटा सदस्य से प्रणाली तक कैसे आती है, पुस्तकालय रिकॉर्ड के साथ बातचीत करती है और एक लेनदेन के रूप में परिणाम देती है। किसी विशिष्ट सॉफ्टवेयर का उल्लेख नहीं किया गया है; तर्क अपने आप में खड़ा है।
📝 सर्वोत्तम प्रथाओं का सारांश
अपने डेटा फ्लो डायग्राम्स के प्रभावी होने की गारंटी देने के लिए, निर्माण प्रक्रिया के दौरान इन दिशानिर्देशों को ध्यान में रखें।
- सरल रखें:एक ही डायग्राम में भीड़ न बनाएं। विभाजन का उपयोग करें।
- संगत नामकरण का उपयोग करें:सुनिश्चित करें कि सभी स्तरों पर डेटा प्रवाह लेबल मेल खाते हों।
- हितधारकों के साथ प्रमाणीकरण करें: उन लोगों के साथ आरेखों की समीक्षा करें जो प्रणाली का उपयोग करते हैं।
- डेटा पर ध्यान केंद्रित करें: याद रखें कि यह डेटा के बारे में है, न कि नियंत्रण या समय के बारे में।
- पुनरावृत्ति करें: आरेख अक्सर पहली ड्राफ्ट में पूर्ण नहीं होते हैं। उन्हें संशोधित करने की उम्मीद रखें।
इन सिद्धांतों का पालन करने से आप ऐसे मॉडल बनाते हैं जो दृढ़, स्पष्ट और किसी भी परियोजना के लिए मूल्यवान संपत्ति हैं। डेटा प्रवाह के नक्शा बनाने में लगाए गए प्रयास के फलस्वरूप त्रुटियों में कमी और स्पष्ट आवश्यकताएं आती हैं।