



Les diagrammes d’architecture logicielle deviennent souvent obsolètes peu de temps après leur création. Ce phénomène, connu sous le nom de détérioration de la documentation, crée un écart entre le plan écrit et le système réel. Les équipes passent des heures à mettre à jour manuellement les diagrammes, pour constater qu’ils sont à nouveau périmés dès le prochain sprint. Le modèle C4 propose une approche structurée pour visualiser l’architecture logicielle, mais compter sur des outils de dessin manuels pour chaque modification n’est pas viable à grande échelle. L’automatisation comble cet écart. En intégrant les processus de génération dans le cycle de développement, les organisations maintiennent une documentation visuelle précise et à jour sans sacrifier la vitesse d’ingénierie.
Ce guide explore des stratégies concrètes pour automatiser la création et la maintenance des diagrammes du modèle C4. Nous nous concentrons sur les mécanismes d’extraction, d’intégration et de validation, afin de garantir que la documentation reste un élément vivant du code source, plutôt qu’une charge statique.
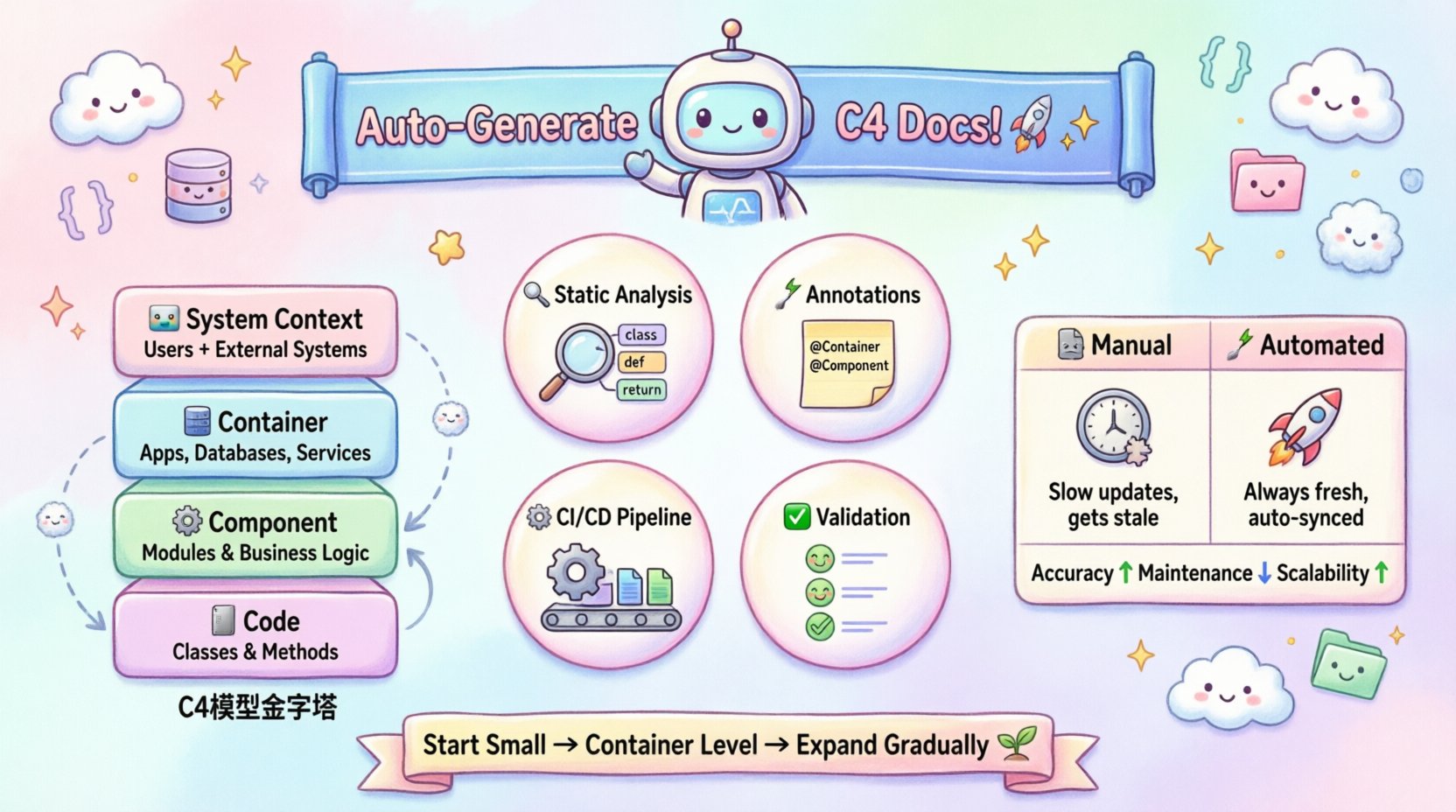
Comprendre les besoins d’automatisation du modèle C4 🧩
Le modèle C4 structure la documentation d’architecture en quatre niveaux hiérarchiques. Chaque niveau s’adresse à un public différent et nécessite des sources de données distinctes. Automatiser ce modèle exige de comprendre quelles données alimentent chaque couche.
- Diagramme de contexte du système 🌍 :Montre le système logiciel et ses utilisateurs. Cela nécessite des métadonnées de haut niveau sur la portée du produit et les dépendances externes.
- Diagramme de conteneurs 📦 :Affiche les choix technologiques de haut niveau et le flux de données entre les conteneurs. Cela nécessite des informations sur les unités de déploiement et les environnements d’exécution.
- Diagramme de composants ⚙️ :Découpe les conteneurs en composants logiques. Cela nécessite une analyse de la structure du code source pour identifier les classes, modules et interfaces.
- Diagramme de code 💻 :Montre les relations entre les classes et les méthodes. Cela exige une analyse statique approfondie du code source.
Les stratégies d’automatisation varient considérablement selon le niveau visé. Les diagrammes de contexte sont plus faciles à générer à partir de fichiers de configuration, tandis que les diagrammes de code exigent une logique de parsing complexe. Tenter d’automatiser tous les niveaux simultanément peut introduire du bruit. Il est souvent plus efficace de privilégier d’abord les niveaux Conteneur et Composant, car ils offrent le meilleur retour sur investissement pour la plupart des équipes.
Stratégie 1 : Analyse statique du code et parsing 🔍
La méthode la plus robuste pour automatiser la documentation d’architecture repose sur l’analyse statique. Elle consiste à lire le code source sans l’exécuter afin de construire un arbre syntaxique abstrait (AST). À partir de l’AST, nous pouvons extraire des relations telles que l’héritage, les dépendances et les appels de méthode.
Extraction des relations entre composants
Pour générer automatiquement des diagrammes de composants, le système doit identifier des regroupements logiques au sein du code. Cela peut être réalisé grâce à :
- Conventions de nommage des paquets/modules :Analyser les structures de répertoires pour inférer les limites des conteneurs. Un dossier nommé
facturationreprésente probablement un conteneur ou un composant majeur. - Conteneurs d’injection de dépendances :De nombreux frameworks modernes s’appuient sur des fichiers de configuration pour connecter les composants. Le parsing de ces fichiers de configuration révèle le graphe de dépendances sans avoir à compiler l’application.
- Implémentation d’interfaces :Identifier les classes qui implémentent des interfaces spécifiques. Cela aide à définir les limites des composants de manière plus précise que la structure des fichiers seule.
Gestion des fuites d’abstraction
Un défi courant dans la génération de diagrammes basés sur le code est la fuite d’abstraction. Cela se produit lorsque la représentation visuelle révèle des détails d’implémentation internes qui devraient rester masqués. Par exemple, un diagramme de composants devrait montrer qu’unService de paiementutilise unDatabaseConnector, pas qu’il appelle une méthode privée spécifique au sein d’une bibliothèque tierce.
Pour atténuer cela, la logique d’automatisation doit définir des règles de filtrage. Ces règles excluent :
- Importations de la bibliothèque standard.
- Code généré (tel que le code boilerplate provenant d’outils ORM).
- Classes d’aide internes qui ne représentent pas la logique métier.
En appliquant ces filtres, les diagrammes générés restent de haut niveau et lisibles, préservant ainsi l’intention du modèle C4.
Stratégie 2 : Génération pilotée par des annotations et des métadonnées 📝
Bien que l’analyse statique soit puissante, elle ne peut pas toujours capturer l’intention métier derrière le code. Parfois, une classe est nomméeOrderProcessor, mais elle gère égalementRemboursements aussi. La structure du code seule ne permet pas d’expliquer la frontière.
Les annotations permettent aux développeurs de marquer explicitement les éléments architecturaux. Cette approche combine l’intention humaine avec le rendu automatisé.
Définition des frontières architecturales
Les développeurs peuvent ajouter des balises de métadonnées aux classes ou modules pour définir leur rôle dans la hiérarchie C4. Par exemple, une balise spécifique pourrait indiquer qu’une classe appartient au niveauContainer niveau. Ces métadonnées peuvent être stockées dans des commentaires, des fichiers de configuration ou des attributs spécifiques indépendants du langage.
Les avantages de cette approche incluent :
- Intention explicite : Le diagramme reflète la manière dont l’équipe perçoit le système, et non seulement la manière dont le compilateur le voit.
- Réduction du bruit : Les développeurs peuvent marquer les classes internes inutilisées pour les cacher de la vue générée.
- Mises à jour rapides : Lorsqu’un composant change, mettre à jour l’annotation est plus rapide que de réécrire un fichier de diagramme.
Mappage des annotations aux diagrammes
Le pipeline d’automatisation lit ces annotations pour remplir les nœuds du diagramme. Une couche de mappage traduit les métadonnées du code en propriétés spécifiques au diagramme, telles que les étiquettes, les formes et les couleurs. Cela garantit une cohérence dans l’ensemble de la documentation.
| Type d’annotation | Niveau C4 | Exemple d’utilisation |
|---|---|---|
@ContexteSysteme |
Contexte | Marque le point d’entrée racine de l’application. |
@Conteneur |
Conteneur | Identifier les serveurs web, les bases de données ou les microservices. |
@Composant |
Composant | Regrouper les classes de logique métier associées. |
@Code |
Code | Marquer des classes spécifiques pour des diagrammes de classes détaillés. |
Stratégie 3 : Intégration du pipeline CI/CD ⚙️
L’automatisation de la documentation échoue si elle est située en dehors du pipeline de déploiement. Si les développeurs ne voient pas immédiatement les résultats de leurs modifications, ils ignoreront la documentation. Intégrer la génération au processus d’intégration continue (CI) garantit que les diagrammes sont toujours synchronisés avec le code.
Le déclencheur de génération
Le processus d’automatisation doit être déclenché par des événements spécifiques. Les déclencheurs courants incluent :
- Envoi de code :Lancer la génération après chaque validation pour détecter les écarts immédiats.
- Demande de fusion :Générer des diagrammes sur les demandes de fusion pour permettre aux validateurs de vérifier les modifications architecturales.
- Tâche planifiée :Exécuter chaque nuit pour détecter les écarts causés par des modifications de configuration manuelles.
Publication des artefacts
Une fois générés, les diagrammes doivent être stockés et versionnés. Le pipeline doit produire les diagrammes sous forme de fichiers statiques (comme PNG ou SVG) et les stocker dans un dépôt ou un stockage d’artefacts. Cela permet de lier la documentation depuis le fichier README du projet ou la wiki interne.
La publication automatisée garantit que :
- Il existe une seule source de vérité pour les diagrammes.
- Les anciennes versions des diagrammes sont archivées mais non perdues.
- Le contrôle d’accès peut être géré de manière centralisée.
Stratégie 4 : Validation et contrôle de qualité ✅
La génération automatisée ne garantit pas la correction. Un script peut créer un diagramme qui reflète fidèlement le code mais qui est architecturalement incorrect. Par exemple, le code pourrait comporter une dépendance circulaire que le diagramme révèle clairement.
Vérification automatisée des diagrammes
Tout comme le code possède des vérificateurs, les diagrammes peuvent avoir des règles. Les scripts de validation peuvent vérifier la sortie générée par rapport aux normes architecturales. Les vérifications courantes incluent :
- Règles de dépendance : Assurez-vous que le
Backendconteneur ne dépend pas directement duFrontendconteneur. - Consistance des noms : Vérifiez que les noms des conteneurs correspondent aux conventions de nommage définies.
- Complétude : Vérifiez que chaque point de terminaison d’API public est représenté dans le diagramme de contexte.
Revue par un être humain dans la boucle
L’automatisation gère la majeure partie du travail, mais une surveillance humaine reste essentielle. Les équipes doivent examiner les diagrammes générés lors des réunions de conception architecturale. Cela déplace l’attention du dessin de lignes à la discussion des implications des connexions présentées.
Cette approche hybride prévient le syndrome de la « boîte noire » où les développeurs font confiance aveuglément au diagramme sans comprendre la structure sous-jacente.
Comparaison des approches manuelles et automatisées 📊
Pour comprendre la valeur de l’automatisation, nous devons comparer l’effort et la précision de la documentation manuelle par rapport à la documentation automatisée.
| Aspect | Approche manuelle | Approche automatisée |
|---|---|---|
| Précision | Élevée au départ, dégrade rapidement au fil du temps. | Consistamment élevée, reflète l’état actuel du code. |
| Coût de maintenance | Élevé. Nécessite un temps dédié aux mises à jour. | Faible. Les mises à jour ont lieu automatiquement lors des modifications du code. |
| Évolutivité | Faible. Difficile à gérer sur de grands bases de code. | Élevée. Évolue avec le nombre de dépôts. |
| Consistance | Faible. Varie selon l’auteur et l’outil. | Élevé. Imposé par des modèles et des styles. |
| Vitesse des retours | Lent. Les modifications ne sont visibles qu’après une mise à jour manuelle. | Rapide. Retours immédiats pendant le développement. |
Aborder les défis courants 🛑
Mettre en œuvre l’automatisation n’est pas sans friction. Les équipes rencontrent souvent des obstacles spécifiques qui peuvent compromettre le processus.
Gérer le comportement dynamique
L’analyse statique ne peut pas voir le comportement à l’exécution. Un microservice pourrait charger dynamiquement des plugins invisibles dans le code source. Pour y remédier, les équipes peuvent compléter l’analyse statique par un traçage à l’exécution. En instrumentant l’application, le système peut enregistrer les dépendances au moment du chargement, ce qui peut ensuite être réintégré dans le processus de génération de documentation.
Gérer les environnements polyglottes
Les systèmes modernes utilisent souvent plusieurs langages de programmation. Un seul outil d’automatisation ne peut pas nécessairement les supporter également. La solution consiste à adopter une représentation intermédiaire unifiée (IR). Chaque parseur de langage convertit son code en IR, et le générateur de diagrammes lit à partir de l’IR. Cela sépare la logique de parsing de la logique de visualisation.
Contrôle de version pour les diagrammes
Si les diagrammes sont générés, doivent-ils être validés dans le dépôt ? C’est un débat au sein de la communauté. Les diagrammes validés permettent un meilleur examen du code et un historique des versions, mais peuvent provoquer des conflits de fusion. Les diagrammes stockés (générés en temps réel) évitent les conflits, mais nécessitent que l’environnement de construction soit disponible pour les visualiser. Une approche hybride est souvent la meilleure : stocker les annotations sources et la configuration, mais générer les images pour la visualisation.
Maintenance et évolution du système 🔄
Une fois l’automatisation en place, l’attention se concentre sur le maintien de la qualité de la logique de génération. Les règles qui filtrent le code ou cartographient les annotations évoluent avec l’évolution de la base de code.
- Audits réguliers : Planifier des revues trimestrielles des règles de génération pour s’assurer qu’elles ne sont pas devenues obsolètes.
- Canal de retours : Permettre aux développeurs de signaler directement les diagrammes incorrects. Cela crée une boucle de retour pour améliorer les scripts d’automatisation.
- Normes de documentation : Mettre à jour les normes de codage de l’équipe pour les aligner sur les exigences des diagrammes. Par exemple, si une nouvelle convention de nommage des paquets est nécessaire pour les diagrammes, elle doit faire partie des directives de codage.
En traitant l’automatisation elle-même comme du logiciel, les équipes peuvent appliquer le même niveau de rigueur au pipeline de documentation qu’au code de l’application.
L’impact sur la dette technique 📉
L’un des bénéfices les plus importants de la documentation architecturale automatisée est la réduction de la dette technique. Lorsque la documentation est précise, les architectes peuvent prendre de meilleures décisions. Ils peuvent voir l’impact réel d’un changement avant d’écrire une seule ligne de code.
En outre, les diagrammes automatisés facilitent l’identification du code obsolète. Si un diagramme montre un composant qui n’a pas été mis à jour depuis des années, il se distingue visuellement. Ce repère visuel peut déclencher des initiatives de refactoring sans avoir besoin d’une recherche approfondie dans le code.
Une documentation précise aide également à l’intégration des nouveaux membres de l’équipe. Au lieu de poser des questions aux ingénieurs expérimentés sur le fonctionnement du système, les nouveaux embauchés peuvent consulter les diagrammes générés pour comprendre l’architecture de haut niveau. Cela réduit la charge cognitive sur l’équipe et accélère la productivité.
Réflexions finales sur la mise en œuvre 🚀
Automatiser la documentation architecturale ne consiste pas à remplacer la compréhension humaine par des machines. C’est plutôt éliminer la friction qui empêche les équipes de maintenir leurs connaissances à jour. En exploitant l’analyse statique, les annotations et l’intégration CI/CD, les organisations peuvent maintenir une carte vivante de leurs systèmes.
La clé du succès réside dans le fait de commencer petit. Commencez au niveau du conteneur, intégrez-le dans le pipeline et validez les résultats. Au fur et à mesure que le processus prouve sa valeur, étendez-le au niveau du composant et du code. Avec le temps, la documentation devient un actif fiable qui soutient plutôt qu’entrave le développement.
Souvenez-vous que l’objectif est la clarté. Que ce soit manuel ou automatisé, le diagramme doit communiquer l’architecture de manière efficace. Si l’automatisation produit un désordre, il vaut mieux s’arrêter et affiner les règles plutôt que de pousser des données inexactes. Avec les bonnes stratégies, la documentation architecturale devient une partie intégrante et fluide de la culture du génie logiciel.