











Les performances de la base de données sont souvent invisibles jusqu’à ce qu’elles deviennent un goulot d’étranglement critique. Lorsque les utilisateurs éprouvent des retards, des timeouts ou des interfaces inaccessibles, la cause fondamentale réside souvent en dessous de la couche d’application. Elle réside dans l’architecture des données elles-mêmes. Le plan directeur qui régule la manière dont les données sont structurées, liées et stockées est le diagramme Entité-Relation (ERD). Un ERD bien conçu garantit l’intégrité des données et une récupération efficace. À l’inverse, un diagramme défectueux introduit une latence que aucun niveau de mise en cache au niveau de l’application ne peut entièrement résoudre.
Ce guide offre une analyse approfondie du dépannage des requêtes lentes en examinant la conception sous-jacente du schéma. Nous explorerons comment les décisions structurelles au sein de l’ERD influencent directement les plans d’exécution des requêtes, les opérations d’E/S et la réactivité globale du système. En comprenant les mécanismes de la conception relationnelle, vous pouvez diagnostiquer les problèmes de performance à leur source plutôt que de traiter les symptômes.
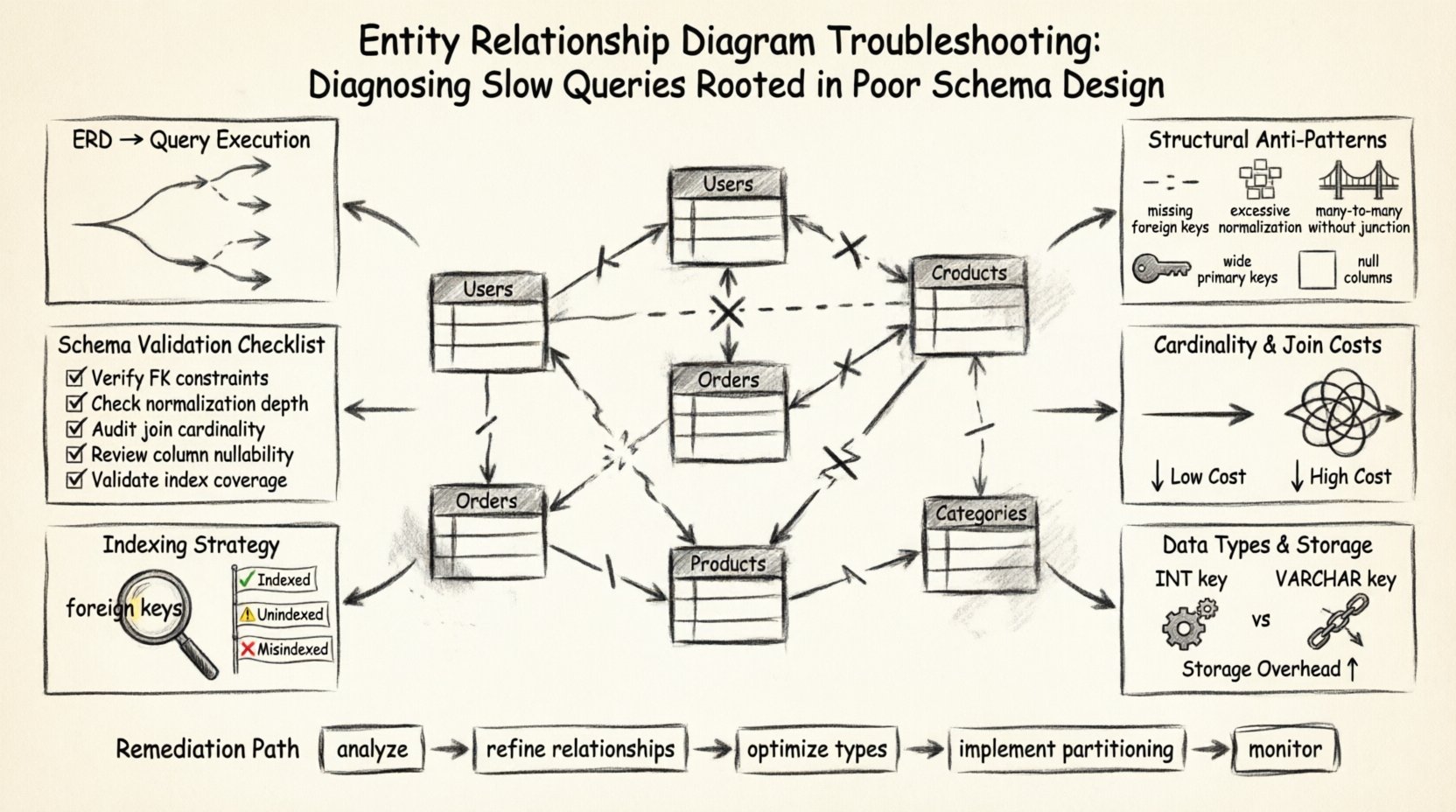
🏗️ La Fondation : Comment les ERD influencent l’exécution des requêtes
Avant de diagnostiquer un problème, il est essentiel de comprendre la relation entre la représentation visuelle des données et l’exécution physique des commandes. Un ERD n’est pas simplement un schéma de documentation ; c’est un ensemble de règles que le moteur de base de données doit appliquer. Chaque ligne tracée entre les tables, chaque contrainte définie et chaque type de données spécifié détermine la manière dont le moteur de stockage lit et écrit les informations.
Lorsqu’une requête est soumise, l’optimiseur de base de données analyse la demande par rapport aux métadonnées du schéma. Si le schéma est ambigu ou inefficace, l’optimiseur peut choisir un chemin sous-optimal. Cela se manifeste souvent par un balayage complet de table au lieu d’une recherche d’index, ou par une jointure imbriquée qui multiplie le temps de traitement de manière exponentielle.
Les principaux domaines où l’ERD influence les performances incluent :
- Complexité des jointures : Le nombre de relations définies détermine le nombre de jointures nécessaires pour récupérer les données associées.
- Contraintes d’intégrité des données : Les clés étrangères et les contraintes uniques ajoutent une surcharge aux opérations d’écriture, mais peuvent optimiser les opérations de lecture.
- Niveaux de normalisation : Le degré auquel les données sont réparties sur plusieurs tables affecte le volume de données analysées lors de la récupération.
- Stratégie d’indexation : La conception du schéma détermine où les index peuvent être logiquement placés pour soutenir les modèles de requêtes courants.
🔍 Identification des anti-modèles structurels
Beaucoup de problèmes de performance proviennent de modèles acceptables pendant la phase initiale de conception, mais qui deviennent des fardeaux à mesure que le volume de données augmente. Ces anti-modèles apparaissent souvent subtils sur le diagramme, mais causent des frictions importantes dans le moteur de requêtes. Ci-dessous se trouve une analyse des défauts structurels courants et de leur impact direct sur la vitesse.
| Anti-modèle | Indicateur visuel dans l’ERD | Impact sur les performances |
|---|---|---|
| Clés étrangères manquantes | Lignes reliant les tables sans définition de contraintes. | Permet des enregistrements orphelins, obligeant les requêtes complexes à filtrer manuellement les données non valides. |
| Normalisation excessive | Grand nombre de tables avec des relations à une seule colonne. | Exige un nombre excessif de jointures pour reconstruire une entité logique unique, augmentant ainsi l’utilisation du CPU. |
| Relation plusieurs-à-plusieurs sans table de jonction | Lignes directes de relation plusieurs-à-plusieurs entre deux entités. | Les moteurs de base de données exigent généralement une table de jonction ; son absence conduit à des solutions inefficaces. |
| Clés primaires larges | Clés composées avec plusieurs colonnes de grande taille. | Augmente la taille de tous les index faisant référence à cette clé, ralentissant les recherches. |
| Colonnes remplies de valeurs nulles | Attributs marqués comme pouvant être nuls sans raison logique. | Peut empêcher l’utilisation des index ou réduire la sélectivité des index, entraînant des analyses complètes. |
🔗 Cardinalité des relations et coût des jointures
La cardinalité définit combien d’instances d’une entité sont liées à des instances d’une autre. C’est l’aspect le plus critique du schéma ERD en matière de performance des requêtes. Des définitions incorrectes de cardinalité obligent le système à traiter plus de lignes qu’il n’est nécessaire pour satisfaire une requête.
Lors du dépannage des requêtes lentes, vous devez vérifier que les relations du schéma correspondent aux exigences logiques de l’application. Si une relation est définie comme Many-to-Many alors qu’elle devrait être One-to-Many, le moteur de requête préparera une jointure à travers une table de jonction qui peut ne pas exister ou être peuplée de manière inefficace.
Problèmes courants de cardinalité
- Cardinalité non définie : Si le schéma ne précise pas si une relation est obligatoire ou facultative, l’optimiseur de requête peut supposer le pire des scénarios, ajoutant des vérifications supplémentaires pour les valeurs nulles.
- Relations récursives : Les tables auto-référentielles (par exemple, une table Employé qui se réfère à elle-même pour le gestionnaire) peuvent entraîner un imbriquage profond dans les requêtes. Sans index approprié sur la colonne auto-référentielle, ces requêtes deviennent exponentiellement plus lentes.
- Dépendances circulaires : Réseaux complexes de relations où la table A est liée à B, B à C, et C revient à A. Cette structure rend le parcours du graphe de données difficile pour le moteur, entraînant souvent la création de tables temporaires en mémoire.
Pour atténuer ces problèmes, assurez-vous que le schéma ERD distingue clairement les liens facultatifs et obligatoires. Les liens obligatoires permettent à l’optimiseur de sauter les vérifications de valeurs nulles, ce qui améliore la vitesse d’exécution. Les liens facultatifs nécessitent une logique supplémentaire pour gérer les cas où la relation n’existe pas.
📏 Types de données et efficacité du stockage
Le choix des types de données dans la définition du schéma a un impact profond sur la taille du stockage et la vitesse de comparaison. Une requête qui compare deux colonnes de types différents déclenche souvent des conversions implicites. Ces conversions empêchent l’utilisation des index et obligent le moteur à traiter chaque ligne.
Implications du stockage
Lorsque le schéma utilise un type de données générique pour toutes les colonnes, comme un champ texte long pour des codes courts, il consomme davantage d’espace disque et de mémoire. Cela réduit la taille effective du pool de tampons, ce qui signifie qu’il y a moins de pages de données chaudes pouvant être conservées en mémoire. En conséquence, le système doit lire davantage de données depuis le sous-système disque plus lent.
Performance des comparaisons
Les comparaisons d’entiers sont nettement plus rapides que les comparaisons de chaînes. Si le schéma ERD définit une clé étrangère comme une chaîne (par exemple, VARCHAR) au lieu d’un entier (par exemple, INT), l’opération de jointure doit comparer caractère par caractère au lieu d’utiliser une comparaison binaire numérique. Cela ajoute des cycles CPU à chaque ligne traitée.
- Utilisez des types de longueur fixe : Pour des champs comme les codes pays ou les indicateurs d’état, utilisez des chaînes de longueur fixe. Les chaînes de longueur variable introduisent une surcharge pour calculer la longueur à chaque lecture.
- Évitez les grands textes dans les clés : N’utilisez jamais une colonne à contenu textuel important comme clé primaire ou étrangère. Cela gonfle chaque index qui la référence.
- Correspondance des types parent et enfant : Assurez-vous que le type de données dans la table enfant correspond exactement à celui de la table parent. Même une légère différence (par exemple, INT vs BIGINT) peut forcer une conversion lors des jointures.
🔑 Visibilité et stratégie d’indexation
Un schéma ERD est la représentation visuelle de la structure logique, mais il doit aussi informer la stratégie d’indexation physique. Bien que les index soient souvent ajoutés après la construction du schéma, la phase de conception doit anticiper où ils sont nécessaires. Une requête qui filtre sur une colonne non indexée est un indicateur principal d’un manque dans la conception.
Opportunités d’indexation dans le MCD
Lors de la revue du diagramme pour identifier les goulets d’étranglement de performance, recherchez les colonnes fréquemment utilisées dans les conditions de recherche ou les jointures.
- Clés étrangères : Elles doivent presque toujours être indexées. Si une requête joint la Table A à la Table B sur une clé étrangère, et que la clé dans la Table B n’est pas indexée, le moteur doit scanner toute la Table B pour chaque ligne de la Table A.
- Drapeaux d’état : Les colonnes qui définissent l’état d’un enregistrement (par exemple, Is_Active, Order_Status) sont souvent utilisées dans les clauses WHERE. Si elles ne sont pas indexées, le filtrage se transforme en une analyse complète de la table.
- Plages de dates : Les tables contenant des journaux d’audit ou des registres de transactions interrogent souvent par date. La colonne de date doit être indexée pour permettre des recherches par plage efficaces.
Il est crucial d’équilibrer le nombre d’index par rapport à la performance des écritures. Chaque index ajoute une surcharge aux opérations INSERT, UPDATE et DELETE. Toutefois, un schéma mal indexé, très utilisé en lecture, entraîne une latence système qui dépasse le coût des écritures. Le MCD aide à visualiser quelles tables sont très utilisées en lecture (par exemple, les tables de référence) par rapport à celles très utilisées en écriture (par exemple, les journaux de transactions), guidant ainsi la décision d’indexation.
🚫 La pathologie de jointure
L’une des causes les plus fréquentes de requêtes lentes est le chemin de jointure. Cela désigne la séquence selon laquelle le moteur de base de données connecte les tables pour satisfaire une requête. Un schéma mal conçu peut contraindre le moteur à suivre un chemin logiquement correct mais coûteux en calcul.
Produits cartésiens
Si le schéma manque de contraintes appropriées ou si la logique de requête ne spécifie pas correctement les conditions de jointure, le moteur peut produire un produit cartésien. Cela se produit lorsque chaque ligne de la Table A est combinée avec chaque ligne de la Table B. L’ensemble de résultats croît de manière exponentielle, et la requête peut expirer ou consommer toute la mémoire disponible.
Dans le MCD, cela se produit souvent lorsque une relation plusieurs-à-plusieurs n’est pas correctement mediée par une table de jonction, ou lorsque la table de jonction manque des contraintes de clés étrangères nécessaires.
Sous-requête vs. Jointure
La conception du schéma influence si une requête peut être exécutée comme une simple jointure ou nécessite une sous-requête. Les sous-requêtes exécutent souvent la requête interne une fois pour chaque ligne de la requête externe, entraînant une complexité temporelle quadratique. Un schéma normalisé permettant des jointures directes est généralement préféré aux structures dénormalisées qui obligent à utiliser des sous-requêtes.
✅ Liste de vérification de validation du schéma
Pour diagnostiquer systématiquement les requêtes lentes à partir du MCD, effectuez une revue structurée. Cette liste de vérification garantit que vous examinez chaque composant critique de la conception.
1. Revue des contraintes de clés étrangères
- Toutes les clés étrangères sont-elles explicitement définies dans le diagramme ?
- Incluent-elles des règles de cascade qui pourraient entraîner un déplacement de données non désiré ?
- Le type de données des deux côtés de la relation est-il identique ?
2. Analyse de la fréquence des jointures
- Identifiez les tables qui sont jointes les plus fréquemment dans la logique de l’application.
- Ces tables sont-elles adjacentes dans le diagramme, ou le chemin nécessite-t-il de traverser plusieurs tables intermédiaires ?
- Peut-on regrouper certaines de ces tables intermédiaires pour réduire la profondeur des jointures ?
3. Vérification de la possibilité de NULL
- Les colonnes qui ne peuvent jamais être NULL sont-elles explicitement marquées comme NOT NULL ?
- Le schéma autorise-t-il les valeurs NULL sur des colonnes faisant partie d’un index ?
4. Vérification des types de données
- Les champs numériques utilisent-ils la taille la plus petite appropriée (par exemple, TINYINT par rapport à BIGINT) ?
- Les champs texte utilisent-ils la longueur correcte pour éviter le troncature ou un stockage excessif ?
5. Évaluer la couverture des index
- Les clés primaires et les clés étrangères ont-elles des index ?
- Les colonnes fréquemment filtrées sont-elles indexées ?
- Existe-t-il un index composite pour les requêtes courantes sur plusieurs colonnes ?
🛠️ Étapes pratiques pour la correction
Une fois que le MCD a été analysé et que les problèmes ont été identifiés, la phase suivante est la correction. Cela consiste à modifier le schéma afin de le mettre en conformité avec les exigences de performance sans compromettre l’intégrité des données.
Affiner les relations : Si le MCD montre des relations trop complexes, envisagez de les simplifier. Cela pourrait signifier introduire une dénormalisation dans des zones spécifiques, fortement sollicitées en lecture, afin de réduire le besoin de jointures. Par exemple, stocker un comptage mis en cache des éléments associés dans la table parente peut éliminer la nécessité de joindre et de compter à chaque fois.
Optimiser les types de données : Modifiez les types de données pour des alternatives plus efficaces. Si une date est stockée uniquement par jour, utilisez un type date uniquement plutôt qu’un type datetime avec l’heure. Si un ID est numérique, assurez-vous qu’il n’est pas stocké sous forme de chaîne.
Mettre en œuvre le partitionnement : Pour des tables très grandes, le MCD pourrait devoir refléter une stratégie de partitionnement. Bien que le partitionnement soit souvent un détail d’implémentation physique, la conception logique doit tenir compte de la manière dont les données sont regroupées. Le partitionnement par date ou région permet à l’engine de scanner uniquement les segments pertinents des données.
🔎 Considérations finales
Le dépannage des performances est un processus itératif. Le MCD sert d’élément central dans ce processus. En traitant le diagramme comme un document vivant qui reflète à la fois la structure logique et les contraintes de performance physique, vous pouvez maintenir un système de base de données réactif même à mesure que les données augmentent.
Souvenez-vous qu’aucun design unique ne convient à toutes les situations. Un schéma optimisé pour des écritures fréquentes peut se comporter différemment d’un autre optimisé pour des requêtes analytiques complexes. L’objectif est d’aligner la conception du schéma sur les modèles d’accès spécifiques de votre application. Revoyez régulièrement le MCD à la lumière des métriques réelles de performance des requêtes afin de détecter les écarts tôt.
En vous concentrant sur l’intégrité structurelle du modèle de données, vous éliminez les causes racines de la latence. Cette approche est plus durable que l’application de correctifs au niveau de la couche application. Une base de schéma solide garantit que le système peut évoluer, s’adapter et fonctionner de manière fiable au fil du temps.
Continuez à surveiller les plans d’exécution des requêtes après avoir apporté des modifications. Visualiser le plan d’exécution permet de confirmer que l’optimiseur utilise correctement les nouveaux index et contraintes. Cette boucle de retour complète le cycle de dépannage, garantissant que les améliorations théoriques dans le MCD se traduisent par des gains de performance tangibles dans l’environnement en production.