











L’architecture logicielle repose fondamentalement sur la gestion de la complexité. À mesure que les systèmes grandissent, la nécessité de modèles mentaux clairs devient cruciale pour les équipes d’ingénierie. Le modèle C4 propose une approche structurée pour visualiser l’architecture logicielle à travers une hiérarchie d’abstractions. Dans cette hiérarchie, deux niveaux spécifiques suscitent souvent des confusions : les conteneurs et les composants. Comprendre la distinction entre ces deux éléments est essentiel pour une communication efficace, une conception évolutif et une documentation maintenable.
Ce guide explore les subtilités des conteneurs et des composants dans le cadre du modèle C4. Nous examinerons leurs définitions, leurs responsabilités, leurs frontières et la manière dont ils interagissent au sein d’une conception de système plus large. En clarifiant ces concepts, les équipes peuvent créer des diagrammes qui servent vraiment leur objectif : la communication.
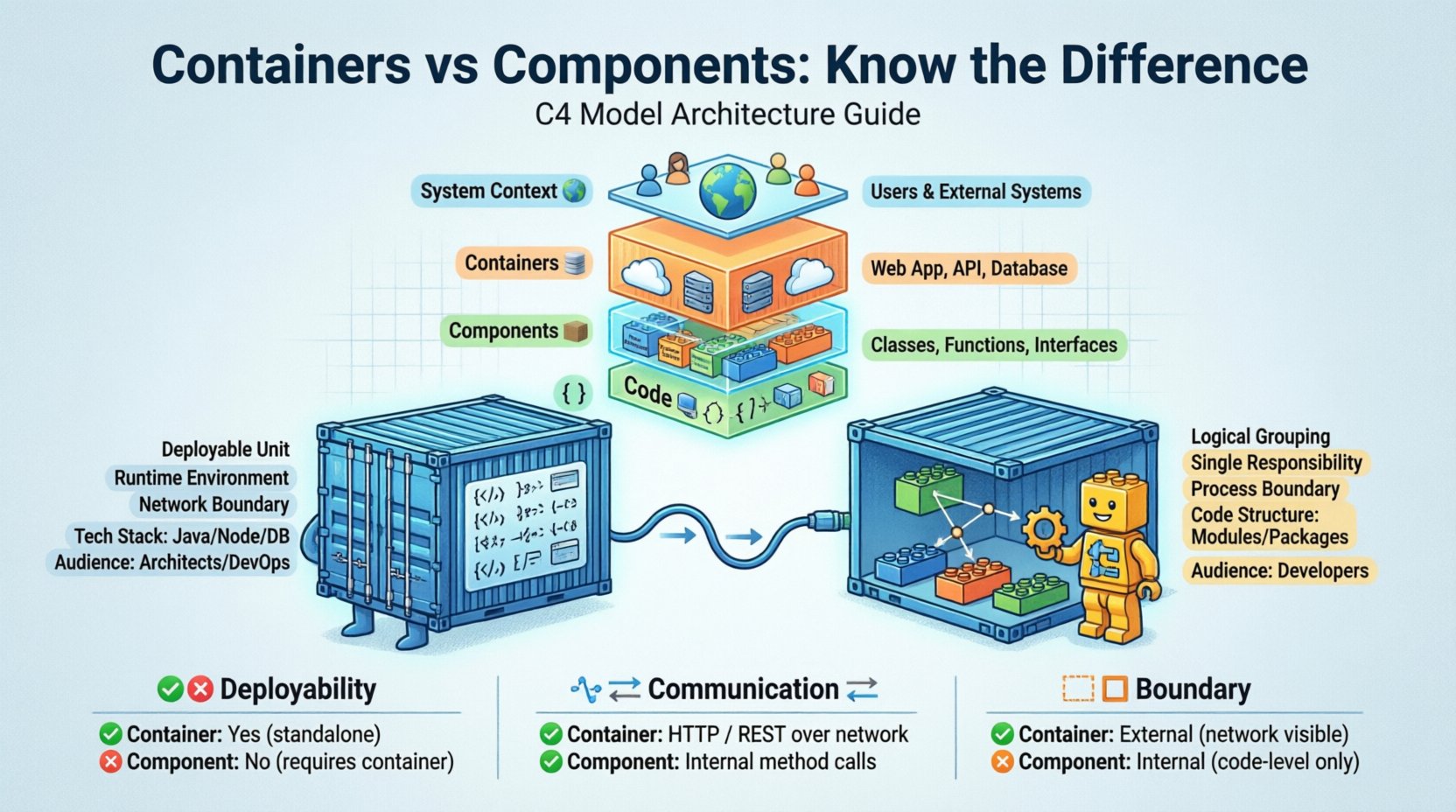
Comprendre la hiérarchie du modèle C4 📊
Avant de plonger dans les différences spécifiques entre les conteneurs et les composants, il est nécessaire de comprendre où ils s’inscrivent dans le modèle C4. Ce modèle est conçu comme une approche en couches, permettant aux architectes et aux développeurs d’agrandir ou de réduire le niveau de détail du système selon leurs besoins.
- Niveau 1 : Contexte du système 🌍 – Montre le système dans son ensemble et son interaction avec les utilisateurs et d’autres systèmes.
- Niveau 2 : Conteneurs 📦 – Représente les éléments de base de haut niveau du système, tels que des applications web, des applications mobiles ou des bases de données.
- Niveau 3 : Composants 🧱 – Découpe les conteneurs en unités fonctionnelles plus petites et cohérentes.
- Niveau 4 : Code 💻 – Détaille la structure interne des composants, y compris les classes et les interfaces.
Le passage du niveau 2 au niveau 3 est là où la distinction entre les conteneurs et les composants devient la plus significative. Bien que les deux représentent des éléments structurels, ils s’adressent à des publics différents et répondent à des questions différentes concernant l’organisation du système.
Définir le niveau des conteneurs 📦
Un conteneur est une unité logicielle déployable. Il représente un environnement d’exécution distinct où le code s’exécute. Les conteneurs sont les frontières physiques ou logiques où un système vit réellement. Ce sont les éléments que vous déployez sur un serveur, une plateforme cloud ou un périphérique.
Caractéristiques d’un conteneur
- Déployable : Un conteneur est une unité indépendante pouvant être installée et exécutée séparément.
- Environnement d’exécution : Il fournit l’infrastructure nécessaire (comme une JVM, un navigateur ou un système d’exploitation) pour exécuter le code.
- Pile technologique : Les conteneurs impliquent souvent un choix technologique spécifique, comme une application Java, un serveur Node.js ou une base de données PostgreSQL.
- Frontière : La communication entre les conteneurs s’effectue par le réseau ou à travers des protocoles définis.
Exemples courants
Lorsque vous modélisez au niveau des conteneurs, vous pouvez identifier les éléments suivants :
- Une application serveur web (par exemple, une application React en cours d’exécution dans un navigateur).
- Un microservice backend (par exemple, une API en cours d’exécution dans un conteneur Docker).
- Une application mobile installée sur le téléphone d’un utilisateur.
- Un serveur de base de données stockant des données persistantes.
- Un broker de file d’attente de messages gérant la communication asynchrone.
La question clé à ce niveau est : Comment le système est-il séparé physiquement ou logiquement ?Les conteneurs définissent les limites du déploiement et les limites des piles technologiques.
Définition du niveau des composants 🧱
Une fois que vous entrez dans un conteneur, l’architecture devient plus fine. Les composants sont les éléments de construction internes qui constituent un conteneur. Ce ne sont pas des unités déployables en elles-mêmes ; plutôt, ils représentent des regroupements logiques de fonctionnalités au sein d’une seule unité de déploiement.
Caractéristiques d’un composant
- Regroupement logique : Un composant regroupe des fonctionnalités liées. Il s’agit d’une frontière conceptuelle, pas nécessairement physique.
- Responsabilité unique : Idéalement, un composant effectue une tâche spécifique ou un ensemble étroitement lié de tâches.
- Structure interne : Les composants masquent leurs détails d’implémentation interne. Ils communiquent avec d’autres composants à travers des interfaces définies.
- Non déployable : Vous ne déployez pas un composant indépendamment. Vous déployez le conteneur qui le contient.
Exemples courants
À l’intérieur d’un conteneur backend, vous pouvez trouver des composants tels que :
- Un module d’authentification chargé de la connexion des utilisateurs.
- Un moteur de rapport qui génère des documents PDF.
- Un gestionnaire d’index de recherche qui gère l’indexation des données.
- Une couche de mise en mémoire tampon qui stocke des données temporaires pour des raisons de performance.
La question clé à ce niveau est : Comment la fonctionnalité est-elle organisée au sein de l’unité de déploiement ? Les composants définissent la structure interne et la séparation des préoccupations.
Différences clés entre conteneurs et composants 📋
La confusion survient souvent parce que les deux termes décrivent une structure. Toutefois, la distinction réside dans le déploiement, la technologie et l’ampleur. Le tableau ci-dessous décrit les principales différences.
| Fonctionnalité | Conteneur (Niveau 2) | Composant (Niveau 3) |
|---|---|---|
| Déployabilité | Oui, c’est une unité déployable. | Non, c’est une partie d’une unité déployable. |
| Communication | Par le réseau (HTTP, TCP, etc.). | Dans le même processus (appels de méthode, API internes). |
| Technologie | Définit l’environnement d’exécution (par exemple, JVM, navigateur). | Définit la structure du code (par exemple, modules, packages). |
| Frontière | Frontière du système (externe). | Frontière interne (à l’intérieur du conteneur). |
| Public cible | Parties prenantes, architectes, DevOps. | Développeurs, ingénieurs. |
Granularité et frontières 🔍
La différence de granularité est l’aspect le plus pratique de cette distinction. Un conteneur représente une frontière coûteuse à franchir. Le déplacement des données entre les conteneurs nécessite des appels réseau, une sérialisation et la gestion de latences ou d’échecs potentiels. Un composant représente une frontière peu coûteuse à franchir. Le passage des données entre les composants se fait dans la mémoire du même processus.
La frontière réseau
Lorsque vous concevez un conteneur, vous prenez une décision concernant la topologie réseau. Vous décidez où a lieu l’appel réseau. Par exemple, si vous avez un monolithe, vous pouvez avoir un seul conteneur. Si vous le divisez en microservices, vous avez maintenant plusieurs conteneurs. Il s’agit d’une décision architecturale importante.
La frontière du processus
Lorsque vous concevez un composant, vous prenez une décision concernant l’organisation du code. Vous décidez comment structurer la base de code pour la maintenir. Les composants vous permettent d’isoler la logique. Si vous modifiez la logique dans un composant, cela ne devrait pas briser la logique dans un autre, à condition que l’interface reste stable.
Implications pour la documentation 📝
Créer des diagrammes précis exige de savoir à quel niveau vous dessinez. Mélanger des conteneurs et des composants dans le même diagramme peut entraîner une ambiguïté. Cela obscurcit la topologie de déploiement et confond la logique interne.
Meilleures pratiques pour la conception de diagrammes
- Gardez les niveaux séparés : Ne mélangez pas les conteneurs et les composants dans une seule vue, sauf si vous montrez explicitement une hiérarchie. Utilisez des diagrammes distincts pour chaque niveau.
- Concentrez-vous sur le public cible : Utilisez le diagramme de conteneur pour la direction technique et la planification de l’infrastructure. Utilisez le diagramme de composant pour les équipes de développement et les revues de code.
- Libellez clairement : Assurez-vous que chaque boîte est étiquetée comme conteneur ou composant afin d’éviter toute confusion.
- Définir les interfaces : Au niveau du composant, concentrez-vous sur les interfaces. Au niveau du conteneur, concentrez-vous sur les protocoles (HTTP, gRPC, etc.).
Erreurs courantes et pièges 🚫
Même les ingénieurs expérimentés peuvent éprouver des difficultés avec cette distinction. Voici quelques pièges courants à éviter lors de la modélisation de l’architecture.
1. Traiter chaque module comme un composant
Il est tentant de diviser chaque petit module en une boîte de composant. Cependant, les composants doivent représenter des unités significatives de fonctionnalité. Si un composant ne possède qu’une seule classe, il est probablement trop petit pour être un composant. Il devrait être regroupé avec d’autres.
2. Traiter chaque service comme un conteneur
Tout service n’a pas besoin de son propre conteneur. Dans certaines architectures, plusieurs services s’exécutent dans le même conteneur afin de réduire la charge. La décision de créer un nouveau conteneur doit être motivée par les besoins de déploiement, et non seulement par un regroupement logique.
3. Ignorer le réseau
Lorsqu’on dessine des conteneurs, les gens oublient souvent de dessiner les lignes représentant le trafic réseau. La communication entre les conteneurs est la partie la plus critique de l’architecture. Assurez-vous de montrer comment les données circulent entre eux.
4. Surcharger le diagramme de composants
Les diagrammes de composants peuvent rapidement devenir encombrés. Si vous avez trop de composants, vous êtes probablement en train de modéliser au mauvais niveau. Pensez à regrouper les composants en unités logiques plus grandes si le diagramme devient illisible.
Architectures évoluant 🔄
Les architectures ne sont pas statiques. Elles évoluent au fil du temps. Un composant peut grandir pour devenir un conteneur, ou un conteneur peut se réduire en plusieurs composants.
Du monolithe aux microservices
Dans une architecture monolithique, vous pouvez avoir un seul conteneur et de nombreux composants. Au fur et à mesure que le système grandit, vous pouvez décider de scinder le conteneur. Les composants qui étaient auparavant internes peuvent désormais devenir des conteneurs externes. Cette transition nécessite une planification soigneuse pour garantir l’intégrité des données et la stabilité des contrats de service.
Des microservices au sans serveur
Dans les architectures sans serveur, le concept de conteneur change. Vous pouvez avoir de nombreuses petites fonctions agissant comme des conteneurs. Le niveau des composants reste pertinent pour organiser le code au sein de ces fonctions. La distinction reste valable, même si l’infrastructure sous-jacente change.
Communication et collaboration 🤝
La valeur principale du modèle C4 est la communication. Les différents acteurs ont besoin de visions différentes du système. La distinction entre conteneurs et composants facilite cela.
Pour les acteurs métier
Les acteurs métiers s’intéressent généralement au contexte du système. Ils veulent savoir comment le système s’intègre dans l’écosystème métier. Ils ont rarement besoin de voir les conteneurs, mais si c’est le cas, cela aide à comprendre la structure de haut niveau.
Pour les équipes DevOps et infrastructure
Ces équipes se concentrent fortement sur les conteneurs. Elles doivent savoir quoi déployer, où le déployer et comment il communique. Le diagramme de conteneur est leur plan.
Pour les développeurs
Les développeurs évoluent au niveau des composants. Ils doivent savoir comment organiser leur code, comment écrire des tests et comment implémenter des fonctionnalités. Le diagramme de composants guide leur travail quotidien.
Considérations techniques en matière d’implémentation 🛠️
Comprendre la différence influence la manière dont vous écrivez du code. Cela influence la manière dont vous structurez vos dépôts et la manière dont vous gérez les dépendances.
Structure du dépôt
Chaque conteneur correspond souvent à un dépôt distinct ou à une chaîne de déploiement différente. Les composants au sein d’un conteneur partagent le même dépôt et la même chaîne de déploiement. Cette séparation permet une versioning et un déploiement indépendants des conteneurs.
Gestion des dépendances
Les composants situés dans un conteneur peuvent avoir des dépendances étroites les uns envers les autres. Ils peuvent partager des bibliothèques et la mémoire. Les conteneurs doivent avoir des dépendances lâches. Ils communiquent via des API. Cette séparation favorise un couplage lâche entre les conteneurs et une cohésion plus forte au sein des composants.
Résumé de la valeur 💡
Une clarté dans l’architecture conduit à un meilleur logiciel. En distinguant clairement les conteneurs et les composants, les équipes peuvent éviter toute ambiguïté dans leurs documents et leurs conceptions. Le modèle C4 fournit le cadre, mais la discipline réside dans l’application du bon niveau d’abstraction.
- Conteneurs définissent la frontière de déploiement et l’environnement d’exécution.
- Composants définissent l’organisation logique et la fonctionnalité à l’intérieur de cette frontière.
Lorsque vous dessinez votre prochain diagramme, prenez un instant pour vous demander :Est-ce que je montre où le code s’exécute, ou comment le code est organisé ? Si vous pouvez répondre à cette question, vous utilisez probablement le bon niveau du modèle C4.
Cette distinction soutient une croissance évolutif. Au fur et à mesure que votre système s’agrandit, vos diagrammes évolueront. Vous ajouterez plus de conteneurs au fur et à mesure que vous diviserez les services. Vous ajouterez plus de composants au fur et à mesure que vous refactoriserez la logique. Garder ces concepts distincts garantit que votre documentation reste précise tout au long du cycle de vie du projet.
En fin de compte, l’objectif n’est pas la perfection. L’objectif est la compréhension. Que vous soyez en train d’intégrer un nouveau développeur ou de planifier un grand refacto, une distinction claire entre les conteneurs et les composants économise du temps et réduit les erreurs. Cela transforme une architecture abstraite en plans concrètement actionnables.
En vous conformant à ces principes, vous construisez des systèmes plus faciles à comprendre, plus faciles à maintenir et plus faciles à mettre à l’échelle. L’effort investi dans une modélisation précise rapporte des bénéfices en productivité à long terme.