











La construction de logiciels pour le cloud exige un changement de perspective. Les architectures monolithiques traditionnelles reposaient sur des composants étroitement couplés partageant la mémoire et les systèmes de fichiers locaux. Les applications natives du cloud, en revanche, fonctionnent dans des environnements distribués, souvent étendus sur plusieurs réseaux et frontières de sécurité. Pour naviguer cette complexité, les ingénieurs ont besoin de représentations visuelles claires du déplacement des informations à travers le système. C’est là que le diagramme de flux de données (DFD) devient un outil essentiel. En cartographiant le flux des données entre les processus, les magasins et les entités externes, les équipes peuvent concevoir des systèmes robustes, évolutifs et sécurisés sans se fier au hasard.
Ce guide explore comment appliquer les principes du DFD spécifiquement dans des contextes natifs du cloud. Nous examinerons les composants fondamentaux, les adaptations nécessaires aux systèmes distribués, ainsi que les étapes concrètes pour créer des diagrammes qui restent utiles au fur et à mesure de l’évolution de l’infrastructure. Que vous conceviez un écosystème de microservices ou une chaîne de fonctions serverless, comprendre le déplacement des données est la base d’une ingénierie fiable.
🌩️ Comprendre le passage à la modélisation native du cloud
Dans un environnement traditionnel sur site, un système existe souvent dans une seule frontière physique. Les données circulent localement entre les processus. Dans un environnement natif du cloud, les frontières sont floues. Une seule application logique peut être composée de dizaines de services indépendants fonctionnant dans des conteneurs, orchestrés à travers différentes régions ou zones de disponibilité. La latence réseau, la cohérence éventuelle et les politiques de sécurité introduisent des variables qui n’existent pas dans les conceptions monolithiques.
Lors de la création d’un diagramme de flux de données pour cet environnement, vous devez tenir compte de :
- Frontières réseau :Les données traversent souvent des réseaux publics ou des VPC sécurisés. Chaque saut représente un point potentiel de défaillance ou de latence.
- Gestion de l’état :Les services cloud sont souvent sans état. Les processus doivent récupérer l’état à partir de magasins externes plutôt que de le conserver en mémoire.
- Communication asynchrone :Les appels synchrones (requête-réponse) ne sont pas toujours les plus adaptés. Les files de messages et les flux d’événements modifient la manière dont les données circulent entre les composants.
- Zones de sécurité :Les données entrant dans une zone doivent être authentifiées et chiffrées avant d’atteindre les processus internes.
Visualiser ces contraintes tôt prévient la dette architecturale. Un diagramme qui ignore la segmentation réseau ou les exigences sans état aboutira à un système difficile à déboguer et à faire évoluer. L’objectif n’est pas seulement de montrer où vont les données, mais de mettre en évidence où elles sont transformées, stockées et sécurisées.
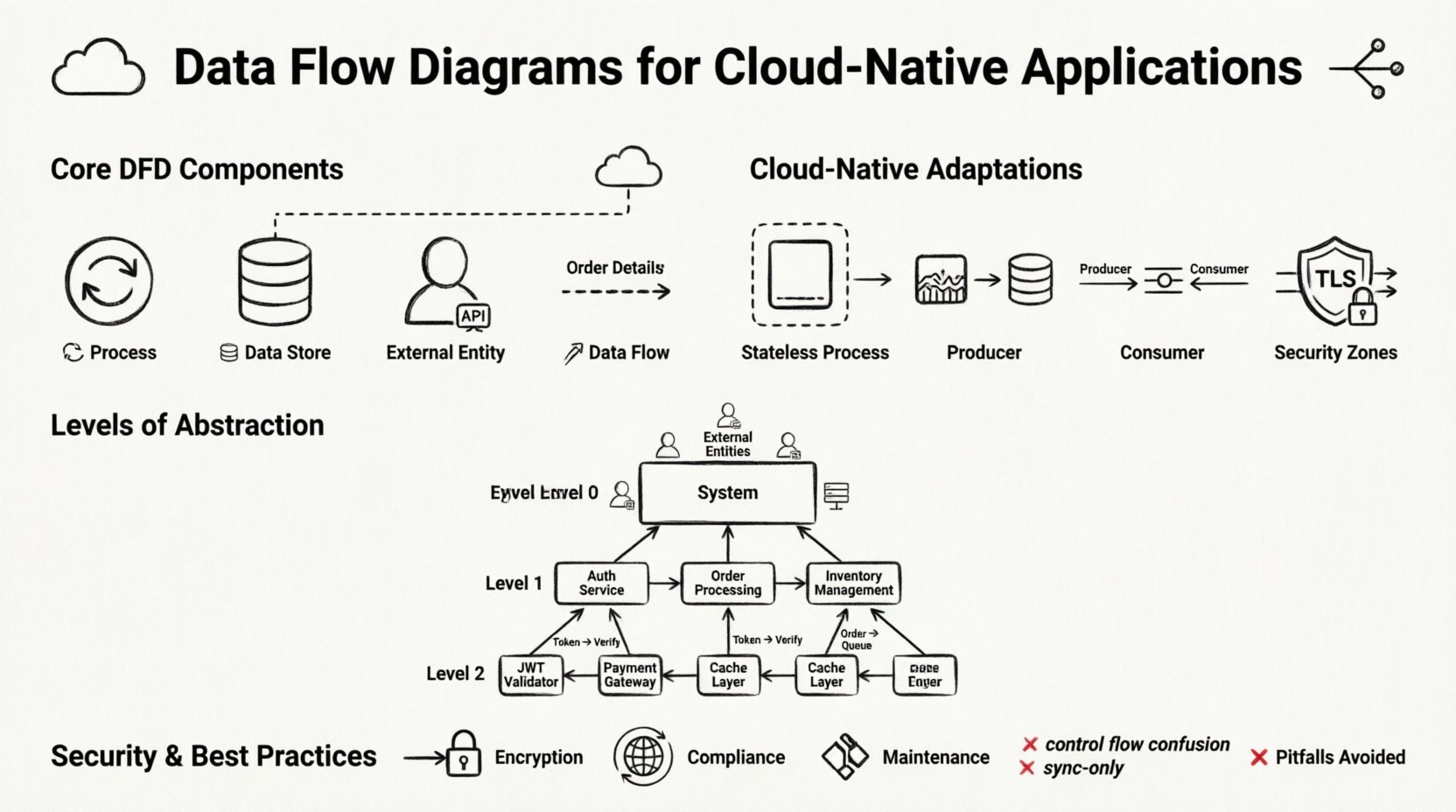
🧩 Composants fondamentaux d’un diagramme de flux de données
Avant d’adapter ces diagrammes au cloud, nous devons établir les éléments de base standard. Un DFD n’est pas un organigramme ; il ne montre ni la logique de contrôle ni le timing. Il illustre le déplacement des données. Les quatre éléments principaux restent constants, même dans les systèmes distribués.
1. Processus 🔄
Un processus représente une activité qui transforme des données d’entrée en données de sortie. Dans un contexte natif du cloud, un processus est souvent une fonction, une application conteneurisée ou une instance de microservice. Il est important de nommer les processus en fonction de ce qu’ils font, et non selon leur appellation technique. Par exemple, au lieu de « UserService API », utilisez « Valider les identifiants utilisateur ». Cela garde le diagramme centré sur la logique de transformation des données.
- Transformation :Chaque processus doit modifier les données d’une certaine manière. Si les données passent sans être modifiées, elles ne doivent pas être représentées comme un processus.
- Encapsulation :Dans les microservices, chaque processus est encapsulé. La logique interne est masquée ; seules les interfaces d’entrée et de sortie ont de l’importance pour le diagramme.
- Sans état :La plupart des processus cloud sont éphémères. Ils ne conservent pas la mémoire des interactions précédentes. Cela doit être reflété dans les exigences de flux de données.
2. Magasins de données 🗄️
Un magasin de données représente un endroit où les données reposent pendant qu’elles ne sont pas traitées. Dans le cloud, cela peut être une base de données relationnelle, un magasin de documents NoSQL, un conteneur de stockage d’objets ou un cache distribué. Contrairement à un système de fichiers, les magasins de données du cloud sont souvent accessibles via un réseau.
- Persistence :Les données doivent être sauvegardées dans un magasin si elles doivent survivre à une panne ou un redémarrage du processus.
- Schémas d’accès : Les magasins à lecture intensive diffèrent des magasins à écriture intensive. Le schéma doit indiquer le type d’accès si cela a un impact significatif sur l’architecture.
- Sécurité : Les magasins de données sensibles nécessitent des contrôles d’accès différents. Cette distinction est essentielle pour les audits de sécurité.
3. Entités externes 👥
Les entités externes sont des sources ou des destinations de données situées en dehors de la frontière du système. Il peut s’agir d’utilisateurs humains, d’API tierces, de systèmes hérités ou de périphériques matériels. Dans un schéma natif du cloud, les entités externes représentent souvent la périphérie d’internet ou d’autres services cloud.
- Fiable vs. Non fiable :Différencier les données provenant d’un service interne connu des flux de trafic provenant d’internet public.
- Déclenchement :Les entités déclenchent souvent le flux. Une requête utilisateur déclenche un processus ; un travail planifié déclenche une synchronisation des données.
4. Flux de données 📡
Les flux de données sont les flèches reliant les composants. Elles représentent la transmission des données. Dans les environnements cloud, ces flux traversent souvent des réseaux. Les étiquettes sur les flèches sont essentielles. Elles doivent décrire le paquet de données, et non le protocole. Par exemple, étiquetez la flèche « Détails de la commande » plutôt que « HTTP POST ». Cela maintient le schéma indépendant du protocole et prêt pour l’avenir.
- Directionnalité :Les flux sont unidirectionnels. Si les données circulent dans les deux sens, dessinez deux flèches distinctes.
- Volume :Les flux de données à haut volume pourraient nécessiter une infrastructure différente (par exemple, une bande passante dédiée) par rapport aux flux de contrôle à faible volume.
- Chiffrement :Les flux traversant des frontières de sécurité doivent être marqués comme chiffrés pour souligner les exigences de conformité.
☁️ Adaptation des DFD aux systèmes distribués
Les DFD standards supposent un système cohérent. Les systèmes natifs du cloud sont distribués. Pour rendre un DFD utile dans ce contexte, vous devez modéliser explicitement la nature distribuée de l’infrastructure. Cela implique d’ajouter des niveaux d’abstraction représentant la topologie du réseau et les frontières des services.
Frontières des services
Les microservices sont les blocs de construction standards des applications natives du cloud. Chaque service devrait idéalement être un processus distinct dans votre schéma. Toutefois, dessiner chaque service individuellement peut entraîner un encombrement. Une approche courante consiste à regrouper les services liés dans un domaine logique, tel que « Domaine de facturation » ou « Domaine de gestion des utilisateurs ». Cela vous permet de visualiser le flux de haut niveau tout en cachant la complexité interne.
Passerelles d’API
La plupart des applications natives du cloud sont situées derrière une passerelle d’API ou un équilibreur de charge. Ce composant agit comme point d’entrée unique. Dans un DFD, la passerelle est un processus qui achemine les requêtes. Elle gère l’authentification, le contrôle de débit et la traduction de protocole. Ne traitez pas la passerelle comme un simple tuyau ; elle modifie activement le flux des données.
Architectures événementielles
De nombreux systèmes modernes utilisent des modèles événementiels. Un producteur génère un événement, puis un consommateur le traite ultérieurement. Cela rompt le lien synchrone entre le processus et le flux de données. Dans un DFD, vous représentez cela en utilisant une file d’événements ou un flux comme magasin de données. Le producteur écrit l’événement ; le consommateur le lit. Ce découplage est crucial pour la résilience.
| Composant | Monolithe traditionnel | Adaptation native du cloud |
|---|---|---|
| Processus | Fonction en mémoire | Microservice conteneurisé / Fonction sans serveur |
| Magasin de données | Fichier local / Base de données SQL | Base de données cloud gérée / Stockage d’objets |
| Flux | Appel à la mémoire locale | HTTP / gRPC / File d’attente de messages |
| État | Mémoire partagée | Magasin d’état externalisé |
📉 Niveaux d’abstraction dans l’architecture cloud
Les systèmes complexes nécessitent plusieurs niveaux de diagrammes. Essayer de capturer tous les détails dans une seule vue conduit à la confusion. La méthode standard DFD des niveaux 0, 1 et 2 fonctionne bien pour les systèmes cloud lorsqu’elle est appliquée correctement.
Niveau 0 : Diagramme de contexte
Le diagramme de contexte représente l’ensemble du système comme un seul processus. Il met en évidence les entités externes interagissant avec le système. Pour une application cloud, cela définit le périmètre. Il répond à la question : « Qu’est-ce qui entre dans le système, et ce qui en sort ? » Il s’agit de la vue de plus haut niveau, utile pour les parties prenantes qui doivent comprendre le périmètre sans détails techniques.
- Focus : Les limites du système et les interfaces externes.
- Détail : Minimal. Un processus central.
- Cas d’utilisation : Définition du périmètre du projet et planification de sécurité de haut niveau.
Niveau 1 : Principaux processus
Le niveau 1 divise le processus central en sous-processus majeurs. Dans un contexte cloud-native, ce sont généralement les principaux domaines fonctionnels. Par exemple, un diagramme au niveau 1 pour une plateforme de commerce électronique pourrait montrer « Traitement des commandes », « Gestion des stocks » et « Gestion des paiements » comme des processus distincts. Ce niveau révèle comment les données circulent entre les principaux groupes de services.
- Focus : Les principaux modules fonctionnels et leurs interactions.
- Détail : Entrées et sorties pour chaque module majeur.
- Cas d’utilisation : Revue architecturale et décomposition des services.
Niveau 2 : Logique détaillée
Le niveau 2 descend en détail dans des sous-processus spécifiques. C’est là que les détails d’implémentation technique deviennent pertinents. Par exemple, le processus « Gestion des paiements » pourrait être développé pour montrer « Valider la carte », « Débiter le compte » et « Mettre à jour le reçu ». Ce niveau est utilisé par les développeurs qui mettent en œuvre des services spécifiques.
- Focus : Logique interne de services spécifiques.
- Détail : Transformations spécifiques des données et magasins de données locaux.
- Cas d’utilisation : Scénarios d’implémentation de développement et de test.
🔒 Sécurité et conformité dans le mapping des données
La sécurité n’est pas une considération secondaire dans le développement cloud-native ; elle est une exigence de conception. Un diagramme de flux de données est un excellent outil pour identifier les risques de sécurité. En suivant le parcours des données, vous pouvez repérer les endroits où des informations sensibles pourraient être exposées ou mal stockées.
Identification des données sensibles
Tous les flux de données ne sont pas équivalents. Les informations personnelles identifiables (PII), les enregistrements financiers et les données de santé nécessitent un traitement plus strict. Dans votre diagramme, marquez les flux contenant des données sensibles. Cela garantit que chaque processus interagissant avec ces données est examiné pour la conformité.
- Chiffrement en transit : Les flux traversant les frontières réseau doivent être chiffrés (TLS/SSL). Marquez clairement ces flux.
- Chiffrement au repos : Les magasins de données contenant des informations sensibles doivent être chiffrés. Indiquez-le dans l’étiquette du magasin de données.
- Contrôle d’accès : Identifiez quels processus sont autorisés à lire ou écrire dans des magasins de données spécifiques. Cela aide à mettre en place un contrôle d’accès basé sur les rôles (RBAC).
Frontières de conformité
Les différentes régions ont des lois différentes en matière de souveraineté des données. Les données pourraient devoir rester dans une frontière géographique spécifique. Un DFD aide à visualiser ces contraintes. Si un processus dans la région A envoie des données vers la région B, ce flux doit être signalé pour une revue juridique. Cela évite les violations accidentelles de réglementations telles que le RGPD ou le CCPA.
⚠️ Pièges courants et comment les éviter
La création de DFD pour les systèmes cloud est difficile. Il existe des erreurs courantes que les équipes commettent, souvent en essayant de mapper des anciens schémas dans de nouveaux environnements. Éviter ces pièges garantit que vos diagrammes restent précis et utiles.
1. Mélanger la logique de contrôle et le flux de données
Les DFD ne doivent pas montrer la logique de contrôle. Ne dessinez pas des flèches pour indiquer « si cela, alors cela ». Utilisez des points de décision ou des notes externes pour la logique, mais gardez les flèches centrées sur le déplacement des données. Dans les systèmes cloud, où la logique de contrôle est souvent gérée par des plateformes d’orchestration, le DFD doit se concentrer sur le contenu des données.
2. Ignorer les flux asynchrones
Les systèmes cloud sont rarement entièrement synchrones. Les tâches s’exécutent en arrière-plan. Si vous ne dessinez que les flux de requête-réponse synchrones, votre diagramme sera incomplet. Incluez toujours les tâches en arrière-plan et les flux d’événements comme des flux de données entrant ou sortant des magasins de données.
3. Sur-optimisation pour des outils spécifiques
Ne concevez pas votre diagramme en fonction des capacités d’un outil ou d’une plateforme spécifique. Si vous choisissez une base de données ou un broker de messages spécifique, le diagramme pourrait devenir obsolète lorsque vous changerez de technologies. Concentrez-vous sur le flux logique des données, et non sur l’implémentation physique.
4. Négliger les flux d’erreurs
Les chemins réussis sont faciles à dessiner. Les chemins d’échec sont plus difficiles mais nécessaires. Dans un environnement cloud, les services échouent fréquemment. Indiquez où les données d’erreur sont journalisées ou où les mécanismes de réessai sont déclenchés. Cela aide à concevoir des systèmes de surveillance et d’alerte robustes.
🔄 Maintenance des diagrammes au fil du temps
Un diagramme n’est utile que s’il est précis. Les applications cloud-native évoluent rapidement. De nouveaux services sont ajoutés, d’autres sont dépréciés, et les modèles de données évoluent. Si le diagramme ne correspond pas au système en cours d’exécution, il devient une documentation trompeuse. Voici comment les maintenir.
- Contrôle de version :Traitez les diagrammes comme du code. Stockez-les dans votre système de contrôle de version aux côtés de votre code d’application. Cela garantit l’historique et la traçabilité.
- Cycles de revue :Intégrez les mises à jour des diagrammes dans votre processus de revue de code. Si un développeur modifie un flux de données, le diagramme doit être mis à jour dans le même commit ou la même demande de fusion.
- Génération automatisée :Lorsque c’est possible, générez les diagrammes à partir du code ou des définitions d’infrastructure en tant que code. Cela réduit l’écart entre la documentation et la réalité.
- Alignement des parties prenantes :Revoyez régulièrement les diagrammes avec les parties prenantes non techniques. Cela garantit que le niveau d’abstraction reste adapté au public.
📋 Comparaison des DFD avec d’autres vues architecturales
Il est fréquent de confondre les DFD avec d’autres diagrammes tels que les diagrammes de séquence ou les diagrammes d’architecture système. Comprendre la différence vous aide à choisir l’outil adapté à la tâche.
| Type de diagramme | Objectif principal | Meilleure utilisation |
|---|---|---|
| Diagramme de flux de données | Déplacement et transformation des données | Conception du système, audit de sécurité, cartographie des données |
| Diagramme de séquence | Interaction basée sur le temps entre les objets | Intégration d’API, débogage des chaînes d’appel |
| Architecture du système | Infrastructure et déploiement | DevOps, mise à l’échelle, exigences matérielles |
| Entité-Relation | Structure et relations des données | Conception de base de données, planification de schéma |
Un DFD complète ces vues. Alors qu’un diagramme d’architecture montre où se trouvent les serveurs, un DFD montre comment les informations circulent entre eux. Alors qu’un diagramme de séquence montre l’ordre des appels, un DFD montre le contenu des données. Les utiliser ensemble fournit une vision complète du système.
🚀 Tendances futures en modélisation cloud
À mesure que les technologies cloud évoluent, les exigences en matière de modélisation évoluent également. L’essor du calcul sans serveur et du calcul aux bords introduit de nouveaux défis. Les flux de données deviennent de plus en plus décentralisés. Les processus s’exécutent plus près de l’utilisateur. Ce changement impose aux DFD de tenir compte des nœuds aux bords et des ressources informatiques temporaires.
En outre, l’intégration de l’intelligence artificielle dans les flux de travail ajoute de la complexité. Les modèles d’IA consomment des données et produisent des insights. Ces processus nécessitent souvent de grandes quantités de données et des matériels spécialisés. Les futurs DFD devront représenter ces processus intensifs en calcul ainsi que les pipelines de données qui les alimentent. Les principes fondamentaux restent les mêmes, mais la granularité et la portée s’élargiront.
En respectant les fondamentaux des diagrammes de flux de données tout en s’adaptant aux réalités du cloud, les équipes d’ingénierie peuvent construire des systèmes transparents, sécurisés et évolutifs. Visualiser les données n’est pas seulement une opération de documentation ; c’est une étape cruciale du processus de conception qui prévient les erreurs avant qu’elles n’atteignent la production.