











Les diagrammes de flux de données (DFD) restent une pierre angulaire de l’analyse et de la conception des systèmes. Bien qu’ils soient souvent introduits dans des cours d’introduction, leur application dans des environnements logiciels complexes exige une approche nuancée. Ce guide explore des techniques avancées pour concevoir, analyser et maintenir des diagrammes de flux de données. Nous allons au-delà des représentations basiques en boîtes et flèches pour aborder la concurrence, l’intégrité des données et l’alignement architectural. Que vous soyez en train de refactoriser des systèmes hérités ou de concevoir de nouvelles architectures de microservices, maîtriser ces diagrammes garantit une clarté dans la communication et une précision dans la mise en œuvre.
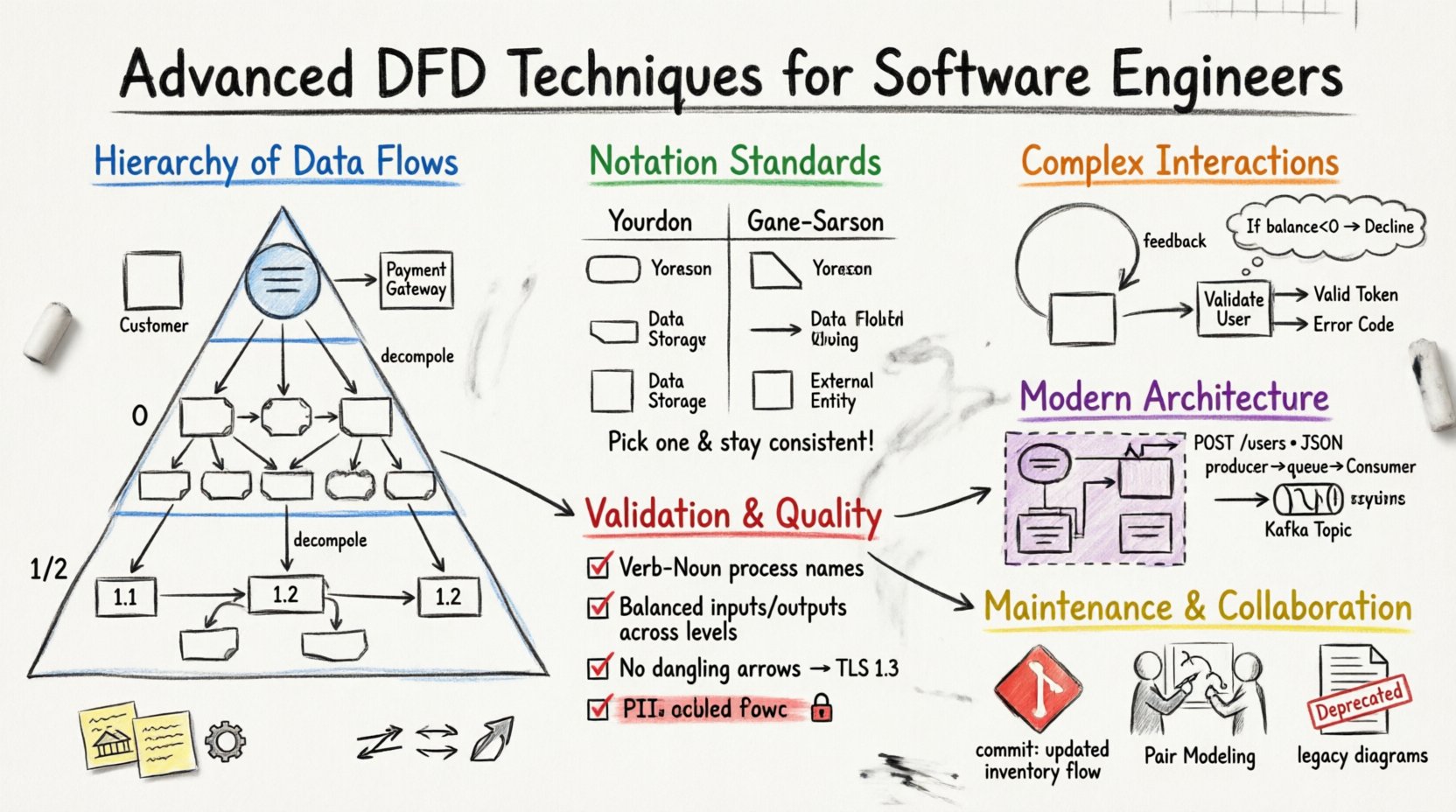
🏗️ Comprendre la hiérarchie des flux de données
Une stratégie solide de DFD repose sur une approche en couches. Visualiser un système à un seul niveau masque souvent des dépendances critiques. En décomposant le système en niveaux spécifiques, les ingénieurs peuvent gérer la complexité et maintenir leur attention sur les détails pertinents.
🌐 Diagrammes de contexte : la vue d’ensemble
Le diagramme de contexte sert de définition de la frontière du système. Il représente le logiciel comme un seul processus et identifie toutes les entités externes interagissant avec lui. Ce niveau est crucial pour définir le périmètre d’un projet.
- Entités externes : Ce sont des utilisateurs, d’autres systèmes ou des périphériques matériels situés à l’extérieur de la frontière. Des exemples incluent un client, une passerelle de paiement ou une base de données héritée.
- Flux de données : Les flèches indiquent le déplacement d’informations vers l’intérieur ou l’extérieur du système. Les étiquettes doivent préciser le contenu, par exemple « Demande de commande » ou « Données de facture ».
- Processus unique : Le système lui-même est représenté par un rectangle arrondi unique, souvent étiqueté avec le nom du système.
Lors de la création d’un diagramme de contexte, évitez d’inclure des processus internes. L’objectif est d’établir le contrat d’interface. Si une entité envoie des données mais ne les reçoit jamais, vérifiez si ce flux est nécessaire. De même, assurez-vous que toutes les entrées requises provenant de sources externes sont bien capturées.
📉 Niveau 0 : Vue d’ensemble du système
Également appelé diagramme « de niveau supérieur » ou « parent », le niveau 0 étend le processus unique du diagramme de contexte en sous-systèmes majeurs ou zones fonctionnelles. Ce niveau fournit une carte de haut niveau des capacités du système sans détailler la logique interne.
Les caractéristiques clés du niveau 0 incluent :
- Processus majeurs :Typiquement entre 5 et 9 processus. Trop de processus indique la nécessité d’un regroupement au niveau supérieur ; trop peu suggère une fonctionnalité manquante.
- Stockages de données : Identifiez où les données persistantes sont stockées. Ce niveau montre *qu*elles sont stockées, mais pas nécessairement comment elles sont structurées.
- Consistance des flux : Tous les entrées et sorties du diagramme de contexte doivent apparaître ici. Cela garantit que la décomposition n’a pas modifié le contrat externe du système.
🧩 Niveaux 1 et 2 : Stratégies de décomposition
En descendant vers les niveaux 1 et 2, l’attention se concentre sur des fonctions spécifiques et la manipulation des données. C’est ici que la logique du travail d’ingénierie est documentée.
- Décomposition : Décomposez les processus du niveau 0 en sous-processus. Par exemple, « Traiter une commande » pourrait devenir « Valider l’inventaire », « Facturer le paiement » et « Générer le reçu ».
- Détail : Chaque processus doit être numéroté (par exemple, 1.0, 1.1, 1.2) pour suivre les relations entre les diagrammes.
- Accès aux stockages de données : Indiquez clairement quels processus lisent ou écrivent dans quels stockages de données. Évitez les connexions directes entre les entités externes et les stockages de données ; tout accès doit passer par un processus.
Lors de la décomposition, assurez-vous que les flux de données ne sont pas perdus. Une erreur courante consiste à omettre un flux de données dans un diagramme enfant qui existait dans le diagramme parent. Cela est connu comme une violation de « balancement ».
🔣 Normes de notation et sémantique des symboles
Le choix du bon système de notation garantit que les diagrammes sont universellement compris par l’équipe de développement. Bien que les normes varient, deux écoles de pensée principales dominent l’industrie.
| Fonctionnalité | Notation Your-Donnell | Notation Gane-Sarson |
|---|---|---|
| Processus | Rectangles arrondis | Rectangles aux coins coupés |
| Bases de données | Rectangles ouverts | Rectangles ouverts |
| Entités externes | Carrés | Carrés |
| Flux de données | Lignes avec des flèches | Lignes avec des flèches |
| Étiquettes | Phrases nominales | Phrases nominales |
La cohérence est primordiale. Mélanger les notations au sein du même ensemble de documentation crée de la confusion. Choisissez une norme et respectez-la sur tous les diagrammes. Le choix dépend souvent de la culture ingénierie ou des modèles de documentation existants.
⚙️ Gestion des interactions de données complexes
Les systèmes du monde réel sont rarement linéaires. Ils impliquent des boucles, une logique conditionnelle et des événements asynchrones. Représenter ces dynamiques dans un diagramme statique nécessite des techniques spécifiques.
🔄 Gestion des boucles et des itérations
Les DFD ne sont pas des diagrammes de flux ; ils ne montrent pas explicitement le flux de contrôle (si-alors-sinon). Toutefois, les boucles de données sont fréquentes. Par exemple, un processus « Calculer la taxe » pourrait envoyer des données à un magasin « Recherche de taux » et recevoir le résultat en retour.
- Boucles de rétroaction :Utilisez des flèches qui reviennent vers un processus pour indiquer une réévaluation. Étiquetez-les clairement pour montrer quelles données sont mises à jour.
- Processus itératifs :Si un processus se répète jusqu’à ce qu’une condition soit remplie, indiquez cette condition dans la description du processus ou dans une annotation textuelle. Évitez de dessiner la boucle comme une ligne de flux de contrôle.
- Mises à jour des données :Montrez le flux de données revenant vers le magasin de données pour indiquer une opération de mise à jour.
🧭 Représentation des points de décision
La logique de décision appartient à la description du processus, pas au diagramme lui-même. Un processus nommé « Valider l’utilisateur » implique une logique interne. Ne divisez pas le processus en « Valider » et « Refuser ». Gardez le processus atomique.
- Différenciation des sorties :Si un processus envoie des données différentes en fonction d’une décision interne, utilisez des étiquettes distinctes pour les flux de données (par exemple, « Jeton valide » vs. « Code d’erreur »).
- Annotations :Utilisez des boîtes de texte pour clarifier les critères de décision. Par exemple, « Si le solde < 0, flux ‘Refuser’ ».
- Atomicité :Assurez-vous que chaque processus effectue une seule fonction logique. Si un processus gère plusieurs décisions distinctes, envisagez de le diviser en processus séparés.
🔗 Intégration des DFD avec les architectures modernes
L’ingénierie logicielle s’est développée. Le passage vers les systèmes distribués, le cloud computing et les conceptions pilotées par les API change la manière dont nous percevons les flux de données. Les DFD doivent évoluer pour refléter ces réalités sans devenir obsolètes.
☁️ Microservices et points d’entrée API
Dans une architecture monolithique, un processus peut représenter un module. Dans un environnement de microservices, un processus représente souvent une instance de service. Le flux de données devient un appel API.
- Frontières des services :Dessinez un cadre autour d’un ensemble de processus qui constituent un seul microservice. Les flux de données traversant cette frontière sont des requêtes réseau.
- Contrats API :Étiquetez les flux de données avec le point d’entrée API spécifique ou la structure du payload (par exemple, « POST /users », « Payload JSON »).
- Sans état :Si un service est sans état, ne montrez pas de magasin de données à l’intérieur de la frontière du service, sauf pour un cache temporaire. Le stockage persistant doit être externe.
📨 Messagerie asynchrone et files d’attente
Tous les flux de données ne se produisent pas en temps réel. Les tâches en arrière-plan et les architectures pilotées par les événements reposent sur des files d’attente.
- Files d’attente comme magasins de données :Représentez les files de messages (par exemple, RabbitMQ, sujets Kafka) à l’aide du symbole de magasin de données. Cela clarifie que les données sont persistées temporairement.
- Producteur/Consommateur :Montrez le processus producteur écrivant dans la file d’attente et le processus consommateur lisant depuis celle-ci. Le flux est déconnecté.
- Implications de la latence :Indiquez dans les annotations que les données ne sont pas immédiatement disponibles après écriture. Cela est crucial pour comprendre le comportement du système lors de scénarios de défaillance.
🛡️ Validation et vérifications de cohérence
Un diagramme n’est utile que s’il reflète fidèlement le système. La validation assure que le modèle est mathématiquement et logiquement cohérent. Les ingénieurs doivent effectuer ces vérifications avant de finaliser la documentation.
⚖️ Vérification de l’équilibre des données
Chaque flux de données entrant dans un diagramme doit être pris en compte. C’est le principe de conservation des données.
- Correspondance entrée/sortie :Assurez-vous que chaque entrée provenant du diagramme parent apparaît dans le diagramme enfant. Aucune entrée ne peut disparaître.
- Complétude des sorties :Toutes les sorties définies au niveau supérieur doivent être présentes au niveau inférieur. Si un processus enfant génère une nouvelle sortie, celle-ci doit être justifiée comme une nouvelle exigence ou un effet secondaire interne.
- Consistance des stocks :Les magasins de données doivent être cohérents à travers les niveaux. Si un magasin est créé au niveau 1, il doit exister au niveau 0.
🏷️ Conventions de nommage
La clarté dans le nommage évite toute ambiguïté. Les étiquettes mal choisies sont la source la plus courante d’interprétation erronée dans la documentation technique.
- Format verbe-nom :Les processus doivent être nommés avec un verbe et un nom (par exemple, « Calculer la taxe », « Mettre à jour le profil »). Évitez les noms seulement (par exemple, « Taxe ») ou les phrases verbales sans objet (par exemple, « Calcul en cours »).
- Étiquettes des flux de données :Utilisez des noms spécifiques (par exemple, « ID de facture », « Session utilisateur »). Évitez les termes vagues comme « Données » ou « Informations ».
- Noms des entités :Les entités externes doivent être cohérentes. « Client » ne doit pas passer à « Client » ou « Utilisateur » au sein du même ensemble de diagrammes.
🔄 Maintenance et cycle de vie de la documentation
Les diagrammes de flux de données ne sont pas des artefacts statiques. Ils doivent évoluer avec les modifications du logiciel. Un diagramme obsolète est pire qu’aucun diagramme, car il crée un faux sentiment de compréhension.
📦 Contrôle de version pour les diagrammes
Traitez les diagrammes comme du code. Stockez-les dans un système de contrôle de version aux côtés du dépôt de code source.
- Messages de validation :Documentez les modifications dans les validations des diagrammes. « Ajout du processus passerelle de paiement », « Mise à jour du flux de gestion des stocks ».
- Diff visuel :Utilisez des outils permettant la comparaison visuelle des diagrammes pour détecter des modifications structurelles involontaires.
- Liens :Liez les diagrammes aux demandes de tirage ou aux tickets spécifiques qui ont provoqué le changement. Cela assure la traçabilité.
🤝 Stratégies de collaboration
La documentation est une tâche d’équipe. Se fier à un seul architecte pour maintenir les DFD entraîne des goulets d’étranglement et des informations obsolètes.
- Modélisation en binôme :Faites dessiner un diagramme par deux ingénieurs ensemble pendant la phase de conception. Cela permet de détecter les erreurs tôt.
- Cycles de revue :Inclure les revues de DFD dans le processus standard de revue du code. Si le code change, le diagramme doit être mis à jour ou indiqué comme étant hors synchronisation.
- Documents vivants :Évitez d’archiver les anciens diagrammes. En revanche, marquez-les comme « Obsolètes » ou « Héritage » au sein du dépôt. Cela préserve l’historique sans encombrer la vue actuelle.
🧠 Considérations avancées pour l’implémentation
Au-delà de la représentation visuelle, les structures de données et la logique sous-jacentes déterminent le flux. Les ingénieurs doivent tenir compte des contraintes physiques des données.
📏 Volume des données et débit
Les DFD décrivent le flux logique, et non les performances. Toutefois, les flux à fort volume ont un impact sur la conception.
- Flux de données volumineux :Si un flux implique de grands fichiers ou des journaux, indiquez-le avec une étiquette. Cela pourrait déclencher une décision d’utiliser un mécanisme de transport différent.
- Compression :Indiquez si les données sont compressées avant transmission. Cela affecte la charge de traitement au niveau du récepteur.
- Encodage :Précisez les encodages de caractères si le flux traverse des frontières de plateforme (par exemple, UTF-8 vs. ASCII).
🔒 Sécurité et contrôle d’accès
La sécurité n’est pas une réflexion tardive. Elle doit être visible dans le flux de données.
- Chiffrement :Marquez les flux qui nécessitent un chiffrement. Utilisez une étiquette comme « Flux chiffré » ou « TLS 1.3 ».
- Gestion des données personnelles :Mettez en évidence les flux contenant des informations personnelles identifiables. Cela garantit que les exigences de conformité sont respectées dans la conception.
- Authentification :Indiquez où les identifiants sont transmis. Évitez de montrer les mots de passe dans des flux en clair ; utilisez l’étiquette « Jeton d’authentification ».
📝 Liste de contrôle pour la qualité du diagramme
Avant de finaliser un ensemble de diagrammes de flux de données, passez en revue cette liste de validation.
- Toutes les entités externes sont-elles clairement définies ?
- Tous les flux de données ont-ils des étiquettes descriptives ?
- Chaque processus est-il nommé selon une structure Verbe-Nom ?
- Y a-t-il des lignes croisées pouvant être redirigées pour plus de clarté ?
- Chaque entrée du diagramme parent apparaît-elle dans le diagramme enfant ?
- Les magasins de données sont-ils correctement séparés des processus ?
- Le diagramme est-il équilibré par rapport au diagramme de contexte ?
- Y a-t-il des flèches pendantes (flux sans destination) ?
- La notation est-elle cohérente dans l’ensemble des documents ?
- Les contraintes de sécurité ont-elles été notées sur les flux sensibles ?
En suivant ces techniques avancées, les ingénieurs logiciels peuvent produire une documentation qui sert de plan fiable pour le développement. Les diagrammes de flux de données (DFD) combler le fossé entre les exigences abstraites et la mise en œuvre concrète. Ils facilitent la communication entre les parties prenantes, réduisent l’ambiguïté logique et fournissent une base de référence pour les tests. Lorsqu’ils sont maintenus avec rigueur et mis à jour de manière rigoureuse, ils restent un outil puissant dans le arsenal de l’ingénierie.
🚀 Réflexions finales sur la modélisation des systèmes
La valeur d’un diagramme de flux de données réside dans sa capacité à simplifier la complexité. Il élimine le bruit lié à la syntaxe et aux détails d’implémentation pour se concentrer sur le déplacement de la valeur. Pour les ingénieurs logiciels, ce focus est essentiel. Il permet la détection précoce des défauts de conception, un onboarding plus clair pour les nouveaux membres de l’équipe, et un modèle mental partagé de l’architecture du système. Engagez-vous dans le processus de modélisation. Cela demande des efforts, mais le retour sur investissement en clarté du système est important.
Souvenez-vous que le diagramme est un moyen, pas une fin en soi. Il soutient le code, et non l’inverse. Gardez les diagrammes minces, précis et accessibles. Au fur et à mesure que le système évolue, laissez les diagrammes évoluer avec lui. Cette approche dynamique garantit que la documentation reste un actif vivant, et non une charge statique.