











Le paysage de la gestion des données a évolué de manière marquante au cours de la dernière décennie. À mesure que les applications ont grandi en échelle et en complexité, les structures rigides du passé ont commencé à montrer des signes de faiblesse. Les bases de données NoSQL sont apparues pour gérer de grandes quantités de données, des flux à haute vitesse et des informations non structurées que les modèles relationnels traditionnels peinaient à gérer efficacement. Cette évolution a suscité un débat persistant parmi les architectes et les développeurs :Le NoSQL éliminera-t-il le besoin de diagrammes de relation d’entité traditionnels (ERD) ? 🤔
Pour répondre à cette question, nous devons aller au-delà de la hype et examiner le but fondamental de la modélisation des données. Bien que les technologies NoSQL aient changé la manière dont nous stockons les données, la nécessité de visualiser les relations et d’organiser l’information reste une exigence fondamentale pour la stabilité du système. Ce guide explore les subtilités de la conception de schémas, le rôle des ERD dans un monde de persistance polyglotte, et les directions que l’industrie prend.
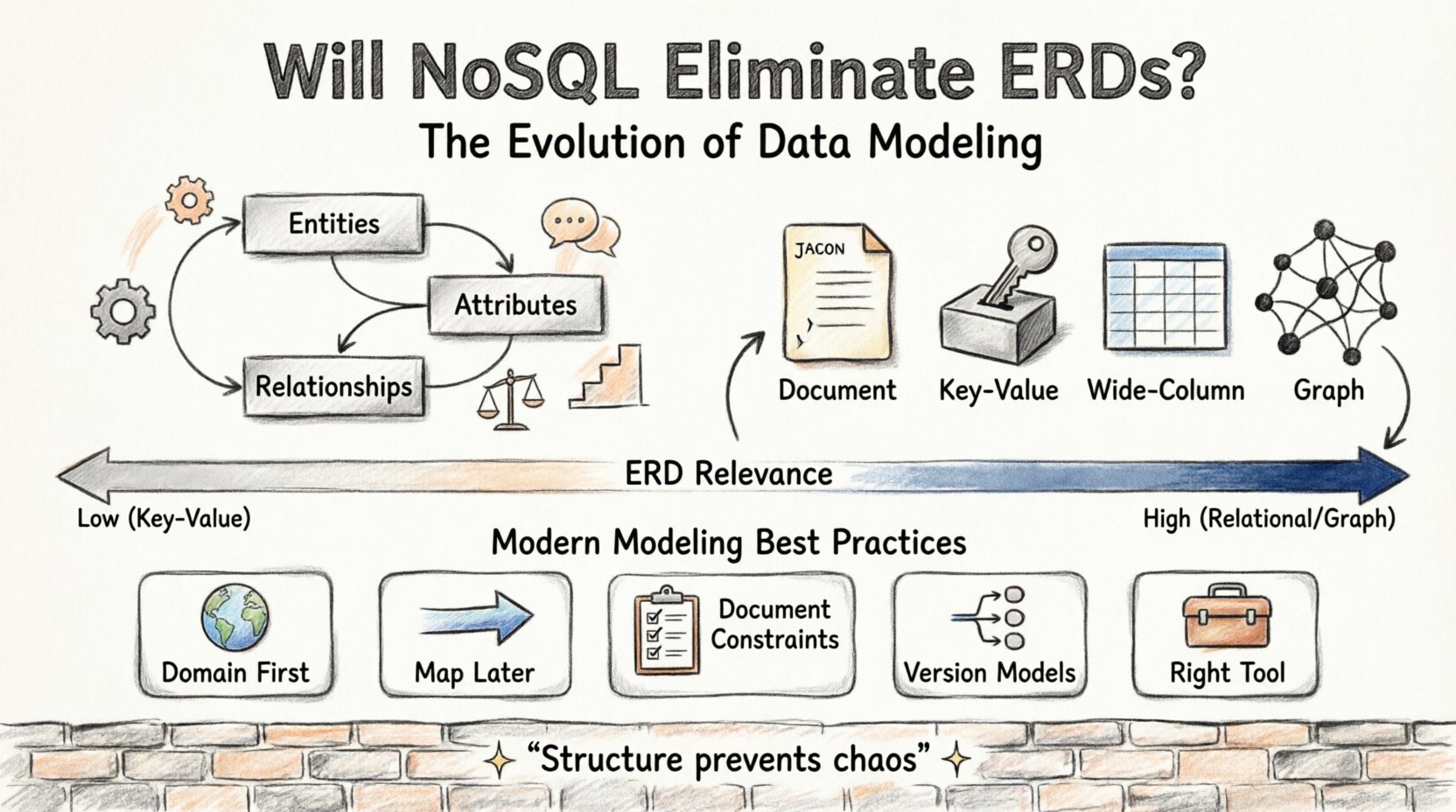
Comprendre les fondations : Qu’est-ce qu’un ERD ? 🏗️
Un diagramme de relation d’entité est une représentation visuelle des structures de données et de leurs interrelations. Développé au début des années 1970, il est devenu le plan directeur pour la conception des bases de données relationnelles. Un ERD utilise des symboles spécifiques pour représenter les entités (tables), les attributs (colonnes) et les relations (clés étrangères).
Les objectifs principaux d’un ERD incluent :
- Clarté :Fournir une carte visuelle aux développeurs pour comprendre le flux des données.
- Intégrité :Assurer que les règles de données sont appliquées avant que le système ne soit mis en production.
- Communication :Agir comme une langue universelle entre les parties prenantes métier et les équipes d’ingénierie.
- Normalisation :Organiser les données pour réduire la redondance et améliorer la cohérence.
Dans un contexte relationnel, ces diagrammes ne sont pas facultatifs. Ils constituent le contrat entre l’application et le moteur de stockage. Sans eux, les jointures deviennent impossibles à planifier, et l’intégrité transactionnelle est compromise.
Le bouleversement NoSQL : un nouveau paradigme 📉
Les bases de données NoSQL n’ont pas été créées pour briser les règles par rébellion. Elles sont nées d’une nécessité. À mesure que le web s’est étendu, le besoin d’un agrandissement horizontal (ajout de serveurs) est devenu plus critique que l’agrandissement vertical (ajout de puissance à un serveur). Les bases de données relationnelles, qui peinent souvent à évoluer horizontalement, ont fait place à des alternatives.
Il existe plusieurs catégories de systèmes NoSQL, chacune ayant des exigences de modélisation différentes :
- Bases de documents :Stockent les données dans des documents similaires au JSON. Les relations sont souvent intégrées plutôt que liées via des clés étrangères.
- Bases clé-valeur :Recherches simples basées sur des identifiants uniques. Aucune relation complexe.
- Bases à colonnes larges :Optimisées pour de grandes quantités de données dans des systèmes distribués. Le schéma est souple et défini au moment de la lecture.
- Bases de graphes :Conçues spécifiquement pour les données fortement interconnectées. Les nœuds et les arêtes remplacent les tables et les lignes.
Dans plusieurs de ces modèles, le concept d’un schéma rigide et prédéfini est assoupli. Cette flexibilité a conduit à la croyance que les outils de planification traditionnels comme les ERD étaient obsolètes. Les développeurs pouvaient commencer à coder, envoyer des données, puis corriger la structure plus tard. Cette approche est souvent appelée « schéma à la lecture ».
Pourquoi le mythe du « pas d’ERD » persiste 🚫📄
L’idée selon laquelle les bases de données NoSQL n’ont pas besoin de conception provient de la facilité d’utilisation initiale. Dans un magasin orienté document, vous pouvez insérer un enregistrement sans définir les colonnes à l’avance. Cette rapidité est attrayante pour la phase de prototype. Cependant, au fur et à mesure que l’application grandit, ce manque de structure engendre une dette technique.
Les malentendus courants incluent :
- « C’est juste du JSON. » Bien que le chargement ressemble au JSON, le moteur de stockage sous-jacent nécessite toujours une organisation pour interroger efficacement.
- « Les relations n’ont pas d’importance. »Les données sont rarement isolées. Un utilisateur a des commandes, les commandes ont des articles, et les articles ont des catégories. Ignorer ces liens entraîne une duplication des données et une incohérence.
- « L’évolution du schéma est automatique. »Modifier la structure des données dans un système distribué sans planification peut entraîner une indisponibilité ou une corruption des données pendant la migration.
Le rôle des diagrammes entité-association dans l’architecture moderne 🔄
Bien que la correspondance stricte des diagrammes entité-association aux tables SQL s’estompe, le conceptdes diagrammes entité-association évolue. Il ne s’agit plus seulement de tables ; il s’agit de connectivité des données. Même dans les environnements NoSQL, comprendre comment les entités de données sont connectées est essentiel pour les performances et la maintenabilité.
Voici comment la fonction de modélisation des données évolue selon les différents types de stockage :
| Type de base de données | Focus de modélisation | Pertinence des diagrammes entité-association |
|---|---|---|
| Relationnel (SQL) | Normalisation, clés étrangères | Élevée (essentielle) |
| Magasin de documents | Dénormalisation, intégration | Moyenne (conceptuelle) |
| Base de données orientée graphe | Nœuds, arêtes, parcours | Élevée (visualisée différemment) |
| Magasin clé-valeur | Recherche par identifiant | Faible (minimale) |
| Colonnes larges | Clés de partition, regroupement | Moyen (structuré) |
Comme indiqué dans le tableau, l’importance du schéma évolue. Pour les bases de données graphes, un schéma visuel est en réalité plus critique que pour les magasins clé-valeur. La terminologie passe de « tables » à « nœuds », mais le besoin de comprendre les connexions demeure.
Lorsque les MCD restent critiques 🛡️
Il existe des scénarios spécifiques où sauter la phase de conception est une recette de l’échec. Même avec un stockage NoSQL souple, certaines contraintes s’appliquent.
1. Intégrité et cohérence des données
Dans les systèmes financiers ou la gestion des stocks, la précision des données est impérative. Si vous stockez une transaction dans un magasin de documents sans définir le schéma, vous risquez d’insérer un état invalide. Un schéma aide à identifier où des vérifications d’intégrité référentielle sont nécessaires, même si elles sont appliquées au niveau de la couche d’application plutôt que de la base de données.
2. Modèles de requêtes complexes
Interroger les données devient exponentiellement plus difficile à mesure que l’ensemble de données augmente. Si vous ne planifiez pas la manière dont vous récupérerez les données, vous risquez de réaliser des balayages complets de tables ou des recherches inefficaces. Comprendre les modèles de lecture permet de déterminer la structure des documents ou des colonnes.
3. Collaboration entre équipes
Les grandes équipes ne peuvent pas se fier à des accords verbaux concernant la structure des données. Un MCD sert de documentation. Lorsqu’un nouveau développeur rejoint l’équipe, il consulte le schéma pour comprendre le modèle métier. Sans cela, l’intégration prend plus de temps, et les bogues augmentent.
4. Persistence polyglotte
Les applications modernes utilisent souvent plusieurs types de bases de données simultanément. Vous pourriez utiliser un magasin relationnel pour les comptes utilisateurs, un magasin de documents pour les catalogues de produits, et un magasin graphique pour les moteurs de recommandation. Un schéma global d’architecture système est nécessaire pour cartographier le flux des données entre ces différents magasins.
Modélisation pour NoSQL : au-delà du MCD traditionnel 🧠
Adopter NoSQL exige un changement de mentalité. Les règles traditionnelles de normalisation (1NF, 2NF, 3NF) sont souvent inversées. La dénormalisation devient une meilleure pratique pour réduire le nombre de requêtes nécessaires. C’est là que le « schéma » change de forme.
Modèles de dénormalisation :
- Intégration : Stocker des données liées dans un seul document. Exemple : Stocker une adresse dans un profil utilisateur.
- Référencement : Garder un document séparé et le lier par ID. Exemple : Un ID utilisateur dans un document de commande.
- Agrégation : Pré-calculer les données pour éviter les calculs en temps réel. Exemple : Stocker le prix total du panier.
Lors de la conception de ces structures, les architectes créent souvent un Modèle de données logique plutôt qu’un MCD physique strict. Ce modèle se concentre sur les relations et la cardinalité sans s’engager sur des définitions spécifiques de tables. Il répond à des questions telles que :
- S’agit-il d’une relation un-à-un ou un-à-plusieurs ?
- Quel côté de la relation est le « propriétaire » ?
- Cette donnée est-elle lue ou écrite plus fréquemment ?
Défis liés à la création de schémas pour les systèmes NoSQL ⚠️
Créer un schéma pour un schéma souple présente des défis uniques. Les outils traditionnels s’attendent à des colonnes fixes. NoSQL s’attend à des structures dynamiques. Ce désaccord peut entraîner des frictions dans le processus de conception.
1. Évolution du schéma
Parce que NoSQL permet des modifications de schéma, les équipes ressentent souvent moins de pression pour planifier à l’avance. Toutefois, modifier une structure de données centrale dans un système distribué peut être coûteux. Les scripts de migration doivent être rédigés avec soin. Un diagramme aide à suivre les modifications de version au fil du temps.
2. Conception orientée requête
Dans NoSQL, vous concevez souvent la structure des données en fonction de la manière dont vous allez les interroger, et non seulement de la manière dont vous allez les stocker. Cela s’appelle la « conception pilotée par les requêtes ». Un ERD traditionnel se concentre sur l’efficacité du stockage. Un modèle NoSQL se concentre sur l’efficacité des requêtes. Le diagramme doit refléter les chemins de lecture, et non seulement les chemins d’écriture.
3. Complexité visuelle
Les bases de données orientées graphe peuvent produire des diagrammes incroyablement denses. Avec des milliers de nœuds, une image statique devient illisible. Des outils de visualisation automatisés sont nécessaires pour gérer cette échelle, mais les relations logiques doivent encore être définies.
Tendances futures en modélisation des données 🚀
L’industrie évolue vers une approche hybride. Nous ne renonçons pas à la structure, mais nous l’adaptons. Voici ce que l’avenir est susceptible de comporter.
- Niveaux de validation de schéma :De nombreux moteurs NoSQL proposent désormais une validation de schéma facultative. Cela permet de combiner la flexibilité de NoSQL avec la sécurité de SQL. Cela redonne toute sa place aux ERD, car vous devez définir les règles que vous souhaitez appliquer.
- Data Mesh : Ce trend architectural décentralise la propriété des données. Des équipes différentes possèdent leurs domaines de données. Les ERD deviennent des contrats spécifiques au domaine plutôt que des plans globaux.
- Modélisation assistée par l’IA :Les outils d’intelligence artificielle commencent à suggérer des conceptions de schéma à partir des journaux de requêtes. Ces outils peuvent générer des visualisations similaires à des ERD à partir des modèles d’utilisation réels.
- Moteurs de requête unifiés :De nouveaux moteurs permettent d’interroger simultanément différents types de bases de données (SQL et NoSQL). Cela nécessite une couche de métadonnées unifiée, qui fonctionne essentiellement comme un ERD global.
Meilleures pratiques pour la modélisation des données modernes 📝
Si vous concevez un système aujourd’hui, comment devez-vous aborder la documentation ? Voici des directives concrètes.
1. Commencez par le domaine, pas par la base de données
Définissez d’abord les entités métiers. Qu’est-ce qu’un « client » ? Qu’est-ce qu’un « produit » ? Cela est indépendant du fait de les stocker dans SQL ou NoSQL. Utilisez un ERD pour définir ces entités et leurs relations de manière abstraite.
2. Cartographiez le stockage plus tard
Une fois le modèle métier clair, cartographiez-le vers la technologie de stockage. Décidez où dénormaliser. Décidez où normaliser. Cette séparation des préoccupations maintient la conception souple.
3. Documentez les contraintes de manière explicite
Même si la base de données ne force pas les contraintes, documentez-les. Précisez clairement : « L’ID utilisateur doit être unique » ou « La date de commande ne peut pas être dans le futur ». Cela garantit que la couche application impose ce que la couche de stockage autorise.
4. Versionnez vos modèles
Traitez vos modèles de données comme du code. Gardez-les sous contrôle de version. Lorsque vous modifiez une relation, effectuez un commit. Cela crée une trace d’audit de l’évolution du système.
5. Utilisez l’outil adapté à la tâche
N’essayez pas de forcer un outil ERD SQL pour modéliser une base de données orientée graphe. Utilisez des outils adaptés au type de données que vous utilisez. Pour les documents, utilisez des fichiers de définition de schéma. Pour les graphes, utilisez des diagrammes nœud-lien.
Comparaison des approches : une vue comparative 🔍
Comprendre les compromis aide à prendre la bonne décision pour votre projet spécifique. Le tableau ci-dessous compare les deux approches.
| Aspect | ERD traditionnel (relationnel) | Modélisation moderne NoSQL |
|---|---|---|
| Structure | Schéma fixe | Schéma flexible / dynamique |
| Relations | Clés étrangères | Intègre ou référence |
| Objectif de conception | Normalisation | Dénormalisation / Modèles de lecture |
| Coût des modifications | Élevé (migrations) | Moyen (logique d’application) |
| Documentation | Le diagramme est obligatoire | Le diagramme est fortement recommandé |
Cette comparaison met en évidence que le principe de modélisation reste constant, même si le implémentation varie. Vous devez toujours savoir comment les données sont connectées. Vous devez toujours savoir ce que représentent les données.
Répondre aux sceptiques 🗣️
Parfois, les développeurs affirment que les diagrammes ralentissent le développement. Ils préfèrent coder en premier et corriger les données plus tard. Bien que cela fonctionne pour de petits scripts, cela échoue pour les systèmes d’entreprise.
Pensez au coût du restructurage. Dans une base de données relationnelle, l’ajout d’une colonne nécessite une migration. Dans un système NoSQL, modifier la structure d’un document peut nécessiter une réécriture complète des données sur des millions d’enregistrements. Le coût de la correction d’un mauvais modèle est toujours supérieur à celui de sa planification. Les diagrammes réduisent le risque de ces corrections coûteuses.
Réflexions finales sur l’avenir 🌅
La question de savoir si NoSQL éliminera les ERD est résolue en examinant le but du diagramme. Si le but est de définir les colonnes des tables, alors NoSQL a effectivement réduit la nécessité de ce type spécifique de diagramme. Toutefois, si le but est de visualiser les relations, l’intégrité et le flux des données, alors la nécessité d’un diagramme reste forte.
La technologie évolue, mais la complexité des données ne diminue pas. À mesure que les systèmes deviennent plus distribués, la nécessité d’une documentation claire augmente. L’ERD ne meurt pas ; il se transforme. Il devient moins centré sur le stockage physique et davantage sur le domaine logique.
Les architectes qui ignorent la modélisation des données dans un environnement NoSQL risquent de créer des systèmes rapides à construire mais impossibles à maintenir. L’avenir appartient à ceux qui équilibrent flexibilité et structure. Nous continuerons à dessiner des diagrammes, mais ils auront un aspect différent, se concentreront sur des métriques différentes et s’adapteront à des moteurs de stockage variés.
Le choix ne se situe pas entre les diagrammes et NoSQL. Le choix se situe entre une modélisation disciplinée et une improvisation chaotique. Dans un monde de données infinies, la structure est la seule chose qui empêche le chaos. 🧱✨