











El rendimiento de la base de datos a menudo permanece invisible hasta que se convierte en un cuello de botella crítico. Cuando los usuarios experimentan retrasos, tiempos de espera o interfaces no respondientes, la causa raíz frecuentemente reside bajo la superficie de la capa de aplicación. Está en la arquitectura de los datos mismos. El plano que rige cómo se estructuran, relacionan y almacenan los datos es el Diagrama de Relaciones de Entidades (ERD). Un ERD bien elaborado garantiza la integridad de los datos y una recuperación eficiente. Por el contrario, un diagrama defectuoso introduce latencia que ninguna cantidad de caché a nivel de aplicación puede resolver completamente.
Esta guía ofrece una exploración profunda de la solución de problemas de consultas lentas mediante el análisis del diseño de esquema subyacente. Exploraremos cómo las decisiones estructurales dentro del ERD influyen directamente en los planes de ejecución de consultas, las operaciones de E/S y la respuesta general del sistema. Al comprender la mecánica del diseño relacional, podrás diagnosticar los problemas de rendimiento en su origen en lugar de tratar solo los síntomas.
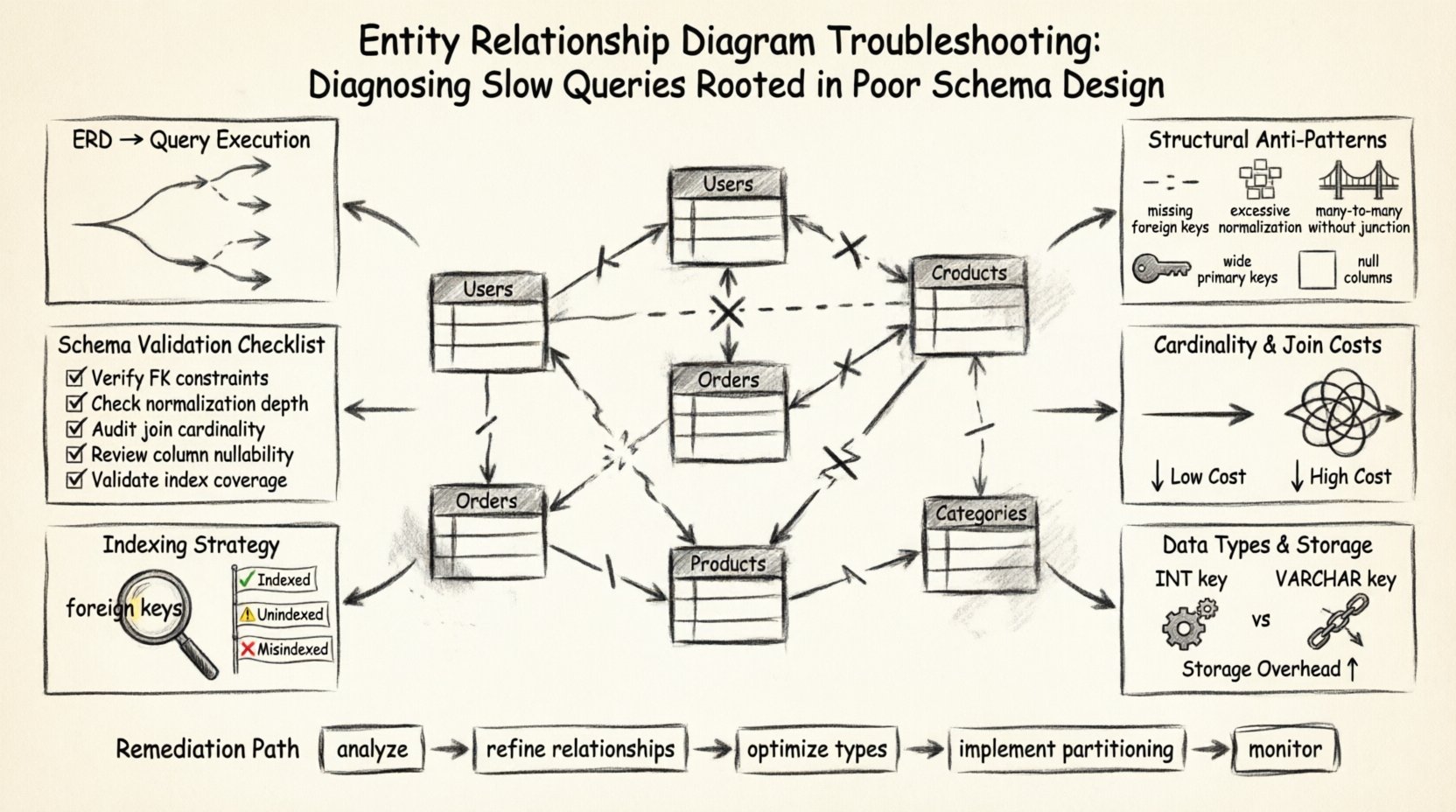
🏗️ La base: Cómo los ERD influyen en la ejecución de consultas
Antes de diagnosticar un problema, es esencial comprender la relación entre la representación visual de los datos y la ejecución física de los comandos. Un ERD no es meramente un diagrama para documentación; es un conjunto de reglas que el motor de base de datos debe aplicar. Cada línea trazada entre tablas, cada restricción definida y cada tipo de dato especificado determina cómo el motor de almacenamiento lee y escribe información.
Cuando se envía una consulta, el optimizador de la base de datos analiza la solicitud frente a los metadatos del esquema. Si el esquema es ambiguo o ineficiente, el optimizador puede elegir un camino subóptimo. Esto suele manifestarse como un escaneo completo de tabla en lugar de una búsqueda en índice, o como una unión de bucle anidado que multiplica exponencialmente el tiempo de procesamiento.
Las áreas clave en las que el ERD afecta el rendimiento incluyen:
- Complejidad de las uniones: El número de relaciones definidas determina el número de uniones necesarias para recuperar datos relacionados.
- Restricciones de integridad de datos: Las claves foráneas y las restricciones únicas añaden sobrecarga a las operaciones de escritura, pero pueden optimizar las operaciones de lectura.
- Niveles de normalización: El grado en que los datos se dividen entre tablas afecta el volumen de datos que se escanean durante la recuperación.
- Estrategia de indexación: El diseño del esquema determina dónde se pueden colocar lógicamente los índices para respaldar patrones comunes de consulta.
🔍 Identificación de anti-patrones estructurales
Muchos problemas de rendimiento provienen de patrones que eran aceptables durante la fase inicial de diseño, pero se convierten en pasivos a medida que crece el volumen de datos. Estos anti-patrones a menudo aparecen sutiles en el diagrama, pero generan fricción significativa en el motor de consultas. A continuación se presenta un análisis de los defectos estructurales comunes y su impacto directo en la velocidad.
| Anti-patrón | Indicador visual en el ERD | Impacto en el rendimiento |
|---|---|---|
| Faltan claves foráneas | Líneas que conectan tablas sin definiciones de restricciones. | Permite registros huérfanos, obligando a consultas complejas a filtrar manualmente datos inválidos. |
| Normalización excesiva | Alto número de tablas con relaciones de una sola columna. | Requiere un número excesivo de uniones para reconstruir una sola entidad lógica, aumentando el uso de la CPU. |
| Muchos a muchos sin tabla de unión | Líneas directas de relación muchos a muchos entre dos entidades. | Los motores de bases de datos requieren típicamente una tabla de unión; su ausencia lleva a soluciones ineficientes. |
| Claves primarias amplias | Claves compuestas con múltiples columnas grandes. | Aumenta el tamaño de todos los índices que hacen referencia a esta clave, ralentizando las búsquedas. |
| Columnas con valores nulos | Atributos marcados como nulos sin razón lógica. | Puede impedir el uso de índices o reducir la selectividad del índice, lo que conduce a escaneos completos. |
🔗 Cardinalidad de relaciones y costos de unión
La cardinalidad define cuántas instancias de una entidad se relacionan con instancias de otra. Este es el aspecto más crítico del ERD en cuanto al rendimiento de las consultas. Las definiciones incorrectas de cardinalidad obligan al sistema a procesar más filas de las necesarias para satisfacer una consulta.
Al depurar consultas lentas, debe verificar que las relaciones en el diagrama coincidan con los requisitos lógicos de la aplicación. Si una relación se define como Muchos a Muchos cuando debería ser Uno a Muchos, el motor de consultas preparará una unión a través de una tabla de unión que podría no existir o estar poblada de forma ineficiente.
Problemas comunes de cardinalidad
- Cardinalidad no definida:Si el diagrama no especifica si una relación es obligatoria o opcional, el optimizador de consultas podría asumir el peor escenario, añadiendo comprobaciones adicionales para valores nulos.
- Relaciones recursivas:Las tablas que se refieren a sí mismas (por ejemplo, una tabla de Empleados que se refiere a sí misma para un Gerente) pueden causar un anidamiento profundo en las consultas. Sin un índice adecuado en la columna de referencia, estas consultas se vuelven exponencialmente más lentas.
- Dependencias circulares:Redes complejas de relaciones donde la Tabla A se vincula con B, B con C y C vuelve a A. Esta estructura dificulta el recorrido del grafo de datos para el motor, a menudo provocando la creación de tablas temporales en memoria.
Para mitigar estos problemas, asegúrese de que el ERD distinga claramente entre enlaces opcionales y obligatorios. Los enlaces obligatorios permiten al optimizador omitir las comprobaciones de nulos, lo que mejora la velocidad de ejecución. Los enlaces opcionales requieren lógica adicional para manejar los casos en los que la relación no existe.
📏 Tipos de datos y eficiencia de almacenamiento
La elección de tipos de datos dentro de la definición del esquema tiene un efecto profundo en el tamaño de almacenamiento y la velocidad de comparación. Una consulta que compara dos columnas de tipos diferentes suele desencadenar conversiones implícitas. Estas conversiones impiden el uso de índices y obligan al motor a procesar cada fila.
Implicaciones de almacenamiento
Cuando el esquema utiliza un tipo de datos genérico para todas las columnas, como un campo de texto grande para códigos cortos, consume más espacio en disco y memoria. Esto reduce el tamaño efectivo del grupo de búferes, lo que significa que se pueden mantener menos páginas de datos activas en memoria. En consecuencia, el sistema debe leer más datos desde el subsistema de disco más lento.
Rendimiento de comparación
Las comparaciones de enteros son significativamente más rápidas que las comparaciones de cadenas. Si el ERD define una clave foránea como una cadena (por ejemplo, VARCHAR) en lugar de un entero (por ejemplo, INT), la operación de unión debe comparar carácter a carácter en lugar de usar una comparación numérica binaria. Esto añade ciclos de CPU a cada fila procesada.
- Use tipos de longitud fija:Para campos como códigos de país o marcas de estado, use cadenas de longitud fija. Las cadenas de longitud variable introducen sobrecarga para calcular la longitud en cada lectura.
- Evite texto largo en claves:Nunca use una columna con mucho texto como clave primaria o foránea. Esto agranda cada índice que la referencia.
- Alinee los tipos de padres e hijos:Asegúrese de que el tipo de datos en la tabla hija coincida exactamente con el de la tabla padre. Incluso una pequeña diferencia (por ejemplo, INT frente a BIGINT) puede obligar a una conversión durante las uniones.
🔑 Visibilidad e estrategia de indexación
Un ERD es la representación visual de la estructura lógica, pero también debe informar la estrategia de indexación física. Aunque los índices a menudo se agregan después de construir el esquema, la fase de diseño debe anticipar dónde se necesitan. Una consulta que filtra por una columna no indexada es un indicador principal de una brecha de diseño.
Oportunidades de indexación en el ERD
Al revisar el diagrama para identificar cuellos de botella de rendimiento, busque columnas que se usen con frecuencia en condiciones de búsqueda o en uniones.
- Claves foráneas:Estas casi siempre deben estar indexadas. Si una consulta une la tabla A con la tabla B mediante una clave foránea, y la clave en la tabla B no está indexada, el motor debe escanear toda la tabla B para cada fila en la tabla A.
- Marcadores de estado:Las columnas que definen el estado de un registro (por ejemplo, Is_Active, Order_Status) suelen usarse en cláusulas WHERE. Si estas no están indexadas, la filtración se convierte en un escaneo completo de la tabla.
- Rangos de fechas:Las tablas con registros de auditoría o registros de transacciones suelen consultar por fecha. La columna de fecha debe estar indexada para permitir escaneos eficientes por rango.
Es crucial equilibrar el número de índices con el rendimiento de escritura. Cada índice añade sobrecarga a las operaciones INSERT, UPDATE y DELETE. Sin embargo, un esquema con lecturas intensivas mal indexado causará latencia del sistema que superará el costo de escritura. El ERD ayuda a visualizar qué tablas son de lectura intensiva (por ejemplo, tablas de búsqueda) frente a tablas de escritura intensiva (por ejemplo, registros de transacciones), guiando la decisión de indexación.
🚫 La patología de la unión
Una de las fuentes más comunes de consultas lentas es la ruta de unión. Esto se refiere a la secuencia en la que el motor de base de datos conecta tablas para cumplir con una solicitud. Un esquema mal diseñado puede obligar al motor a seguir una ruta lógicamente correcta pero computacionalmente costosa.
Productos cartesianos
Si el esquema carece de restricciones adecuadas o si la lógica de la consulta no especifica correctamente las condiciones de unión, el motor puede generar un producto cartesiano. Esto ocurre cuando cada fila de la tabla A se combina con cada fila de la tabla B. El conjunto de resultados crece exponencialmente, y la consulta podría caducar o consumir toda la memoria disponible.
En el ERD, esto suele ocurrir cuando una relación muchos a muchos no está debidamente mediada por una tabla de unión, o cuando la tabla de unión carece de las restricciones de clave foránea necesarias.
Subconsulta frente a unión
El diseño del esquema influye en si una consulta puede ejecutarse como una unión simple o requiere una subconsulta. Las subconsultas suelen ejecutar la consulta interna una vez por cada fila de la consulta externa, lo que conduce a una complejidad temporal cuadrática. Generalmente se prefiere un esquema normalizado que permita uniones directas frente a estructuras denormalizadas que obliguen al uso de subconsultas.
✅ Lista de verificación de validación de esquema
Para diagnosticar de forma sistemática consultas lentas basadas en el ERD, realice una revisión estructurada. Esta lista de verificación garantiza que examine cada componente crítico del diseño.
1. Revisar las restricciones de clave foránea
- ¿Todas las claves foráneas están definidas explícitamente en el diagrama?
- ¿Incluyen reglas de propagación que podrían causar movimientos no deseados de datos?
- ¿Es el tipo de dato idéntico en ambos lados de la relación?
2. Analizar la frecuencia de unión
- Identifique las tablas que se unen con mayor frecuencia en la lógica de la aplicación.
- ¿Están estas tablas adyacentes en el diagrama, o la ruta requiere atravesar múltiples tablas intermedias?
- ¿Se pueden consolidar algunas de estas tablas intermedias para reducir la profundidad de unión?
3. Verificar la posibilidad de nulos
- ¿Las columnas que nunca son nulas están marcadas explícitamente como NOT NULL?
- ¿El esquema permite valores NULL en columnas que forman parte de un índice?
4. Verificar tipos de datos
- ¿Las columnas numéricas utilizan el tamaño más pequeño adecuado (por ejemplo, TINYINT frente a BIGINT)?
- ¿Las columnas de texto utilizan la longitud correcta para evitar truncamiento o almacenamiento excesivo?
5. Evaluar el cubrimiento de índices
- ¿Tienen índices las claves primarias y las claves foráneas?
- ¿Las columnas frecuentemente filtradas están indexadas?
- ¿Existe un índice compuesto para consultas comunes de múltiples columnas?
🛠️ Pasos prácticos para la corrección
Una vez que se ha analizado el ERD y se han identificado los problemas, la siguiente fase es la corrección. Esto implica modificar el esquema para alinearlo con los requisitos de rendimiento sin sacrificar la integridad de los datos.
Perfeccionar relaciones: Si el ERD muestra relaciones excesivamente complejas, considere simplificarlas. Esto podría significar introducir desnormalización en áreas específicas con alta carga de lectura para reducir la necesidad de uniones. Por ejemplo, almacenar un recuento almacenado en caché de elementos relacionados en la tabla principal puede eliminar la necesidad de unir y contar cada vez.
Optimizar tipos de datos: Cambie los tipos de datos por alternativas más eficientes. Si una fecha solo se almacena por día, utilice un tipo de fecha sin hora en lugar de un datetime con hora. Si una ID es numérica, asegúrese de que no se almacene como cadena.
Implementar particionamiento: Para tablas muy grandes, el ERD podría necesitar reflejar una estrategia de particionamiento. Aunque el particionamiento suele ser un detalle de implementación física, el diseño lógico debe tener en cuenta cómo se agrupan los datos. El particionamiento por fecha o región permite que el motor escanee solo los segmentos relevantes de los datos.
🔎 Consideraciones finales
La depuración del rendimiento es un proceso iterativo. El ERD sirve como el artefacto central en este proceso. Al tratar el diagrama como un documento vivo que refleja tanto la estructura lógica como las restricciones de rendimiento física, puede mantener un sistema de base de datos que permanezca reactivo a medida que los datos crecen.
Recuerde que ninguna única diseño se adapta a todos los escenarios. Un esquema optimizado para escrituras de alta frecuencia puede comportarse de forma diferente que uno optimizado para consultas analíticas complejas. El objetivo es alinear el diseño del esquema con los patrones específicos de acceso de su aplicación. Revise periódicamente el ERD frente a métricas reales de rendimiento de consultas para detectar desviaciones tempranas.
Al centrarse en la integridad estructural del modelo de datos, elimina las causas raíz de la latencia. Este enfoque es más sostenible que aplicar parches a la capa de aplicación. Una base de esquema sólida garantiza que el sistema pueda escalar, adaptarse y funcionar de forma confiable con el tiempo.
Siga monitoreando los planes de ejecución de consultas después de realizar cambios. Visualizar el plan de ejecución puede confirmar que el optimizador está utilizando correctamente los nuevos índices y restricciones. Este bucle de retroalimentación completa el ciclo de depuración, asegurando que las mejoras teóricas en el ERD se traduzcan en mejoras de rendimiento tangibles en el entorno en vivo.