











Datenbank-Schemas sind lebende Artefakte. Sie entwickeln sich gemeinsam mit der Geschäftslogik, die sie unterstützen. Im Laufe der Zeit, wenn sich Anforderungen ändern und neue Funktionen hinzukommen, wird die zugrundeliegende Datenstruktur oft komplex. Diese Komplexität äußert sich visuell als überwuchser Entity-Relationship-Diagramm (ERD). Ein aufgeblähtes ERD kann zu Leistungsabfall, Wartungsfahrten und einem erhöhten Risiko von Datenintegritätsproblemen führen.
Das Refactoring dieser Diagramme ist kein bloß ästhetisches Unterfangen. Es handelt sich um eine strukturelle Intervention, die Präzision erfordert. Das primäre Ziel besteht darin, das Schema zu vereinfachen, die Lesbarkeit zu verbessern und die Abfrageleistung zu optimieren, während sichergestellt wird, dass während des Übergangs absolut keine Daten verloren gehen oder beschädigt werden. Diese Anleitung bietet einen strukturierten Ansatz zur Steuerung dieses Prozesses.
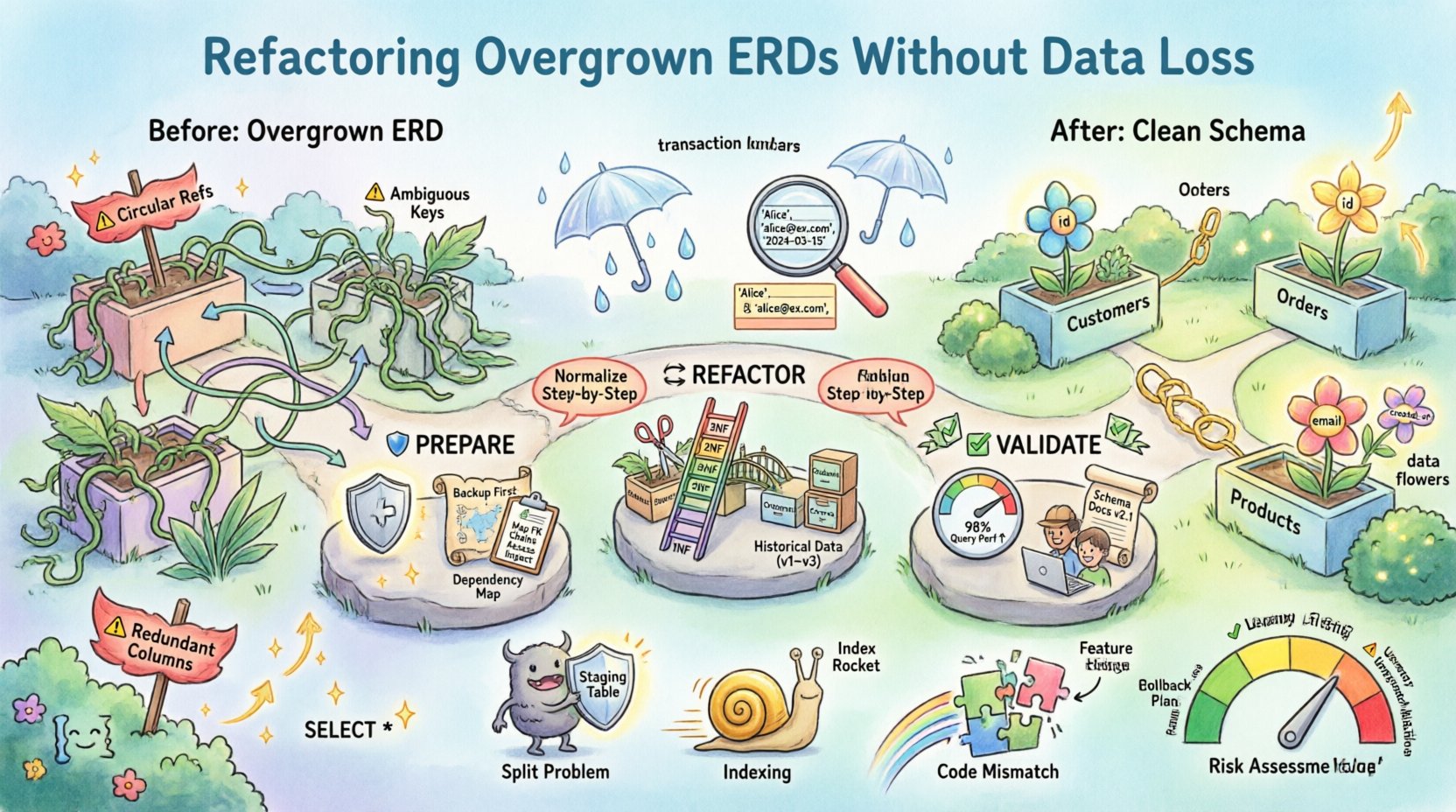
📉 Warum ERDs unübersichtlich werden
Das Verständnis der Ursachen für Schema-Bloat ist der erste Schritt zur Lösung. Ein ERD, das organisch ohne Governance gewachsen ist, zeigt oft spezifische Symptome. Die Erkennung dieser Muster ermöglicht gezielte Maßnahmen.
- Redundante Spalten: Der gleiche Datenpunkt wird in mehreren Tabellen gespeichert. Dies führt zu Synchronisierungsproblemen, bei denen die Aktualisierung einer Instanz die andere nicht aktualisiert.
- Übermäßige Denormalisierung: Während die Denormalisierung die Leseleistung verbessert, führt ihre übermäßige Verwendung zu komplexeren Schreiboperationen und erhöhtem Speicherbedarf.
- Schwache Beziehungen: Many-to-many-Beziehungen werden oft mit einzelnen Tabellen mit mehreren Fremdschlüsseln implementiert, anstatt mit korrekten Verbindungstabellen.
- Implizite Geschäftslogik: Datentypen und Einschränkungen können auf Überprüfungen auf Anwendungsebene statt auf Datenbankebene angewiesen sein, was das Schema anfällig macht.
- Verwaiste Entitäten: Tabellen existieren, die von keinem aktiven Anwendungsmodul mehr referenziert werden, aber weiterhin im physischen Speicher verbleiben.
Wenn diese Faktoren sich ansammeln, wird das ERD zu einem verworrenen Netz. Die Visualisierung der Beziehungen wird schwierig, und das Risiko, Fehler bei jeder Änderung einzuführen, steigt exponentiell.
🛡️ Vorbereitung auf Schema-Änderungen
Bevor eine einzige Zeile des DDL (Data Definition Language) berührt wird, ist eine strenge Vorbereitungsphase obligatorisch. Diese Phase minimiert das Risiko und stellt sicher, dass ein Rückgängigmachen möglich ist, falls Probleme auftreten.
1. Umfassende Sicherungsstrategie
Datensicherheit ist von höchster Bedeutung. Eine Sicherung ist nicht nur eine Datei; sie ist ein Überprüfungszeitpunkt.
- Logische Sicherungen: Exportieren Sie Schema-Definitionen und Daten im menschenlesbaren Format (z. B. SQL-Dumps).
- Physische Snapshots: Falls die Plattform dies unterstützt, erstellen Sie einen Zeitpunkt-Snapshot des Speichervolumens.
- Schreibgeschütztes Replikat: Falls möglich, stellen Sie eine Replikation der Produktionsumgebung bereit. Führen Sie hier zunächst alle Tests und Migrationsskripte durch.
2. Abhängigkeitskarte
Tabellen existieren nicht isoliert. Jede Entität wird von Anwendungscode, gespeicherten Prozeduren oder externen Berichtswerkzeugen referenziert. Sie müssen jeden Verbraucher der Daten identifizieren.
- Überprüfen Sie den Anwendungscode auf direkte Tabellenreferenzen.
- Prüfen Sie auf Ansichten oder materialisierte Ansichten, die von bestimmten Spalten abhängen.
- Identifizieren Sie geplante Aufgaben oder ETL-(Extract, Transform, Load)-Prozesse, die Daten aus den betroffenen Tabellen einlesen oder daraus ausgeben.
3. Auswirkungsanalyse
Dokumentieren Sie den aktuellen Zustand. Erstellen Sie eine Basislinie für Zeilenanzahlen, Datenverteilung und Abfrageausführungszeiten. Diese Basislinie ermöglicht es Ihnen, den Systemzustand vor und nach der Umgestaltung zu vergleichen, um Konsistenz sicherzustellen.
| Prüfpunkt | Priorität | Hinweise |
|---|---|---|
| Vollständigkeit der Sicherung überprüfen | Hoch | Stellen Sie sicher, dass die Prüfsummen mit der Quelle übereinstimmen |
| Alle Fremdschlüssel abbilden | Hoch | Dokumentieren Sie Eltern-Kind-Beziehungen |
| Aktive Abfragen identifizieren | Mittel | Verwenden Sie Abfrageprotokolle, um die am stärksten belastenden Abfragen zu finden |
| Zugriffssteuerungen überprüfen | Mittel | Stellen Sie sicher, dass Berechtigungen nach der Migration erhalten bleiben |
🔄 Die Umgestaltungs-Methode
Der Kern der Umgestaltung besteht darin, das logische Modell neu zu strukturieren. Dies wird oft durch Normalisierung erreicht, wobei jedoch strategische Denormalisierung zur Leistungssteigerung beibehalten werden kann. Ziel ist Klarheit und Integrität.
1. Aktuelle Normalisierung analysieren
Die meisten älteren Schemata erfüllen nicht die Dritte Normalform (3NF). Die Annäherung an eine höhere Normalisierung reduziert Redundanz.
- Erste Normalform (1NF):Stellen Sie Atomarität sicher. Keine sich wiederholenden Gruppen oder mehrwertige Attribute innerhalb einer einzigen Zelle.
- Zweite Normalform (2NF):Entfernen Sie partielle Abhängigkeiten. Stellen Sie sicher, dass jedes Nicht-Schlüssel-Attribut vollständig vom Primärschlüssel abhängt.
- Dritte Normalform (3NF):Entfernen Sie transitive Abhängigkeiten. Nicht-Schlüssel-Attribute sollten sich nur vom Schlüssel, nicht von anderen Nicht-Schlüssel-Attributen, ableiten.
| Normalisierungsgrad | Wichtige Regel | Vorteil |
|---|---|---|
| 1NF | Nur atomare Werte | Beseitigt komplexe Analyselogik |
| 2NF | Vollständige Abhängigkeit von PK | Reduziert Aktualisierungsanomalien |
| 3NF | Keine transitiven Abhängigkeiten | Verbessert die Datenkonsistenz |
2. Große Entitäten zerlegen
Wenn eine einzelne Tabelle zu viele Spalten enthält, deutet dies oft darauf hin, dass unterschiedliche geschäftliche Konzepte vermischt werden. Teilen Sie diese in separate Tabellen auf.
- Identifizieren Sie Gruppen von Spalten, die unterschiedliche Entitäten beschreiben (z. B. Benutzerprofil im Vergleich zu Benutzereinstellungen).
- Erstellen Sie eine neue Tabelle für das unterschiedliche Konzept.
- Verschieben Sie die relevanten Spalten in die neue Tabelle.
- Stellen Sie eine Eins-zu-Eins-Beziehung mit einem Fremdschlüssel her.
3. Lösen Sie viele-zu-viele-Beziehungen auf
Das direkte Verknüpfen zweier Tabellen über eine Spalte in jeder ist ein häufiger Anti-Pattern. Dies sollte durch eine Verbindungstabelle ersetzt werden.
- Erstellen Sie eine neue Tabelle, die als Brücke fungiert.
- Fügen Sie die Primärschlüssel aus beiden Eltern-Tabellen als Fremdschlüssel in der Brückentabelle hinzu.
- Fügen Sie alle spezifischen Attribute hinzu, die der Beziehung selbst gehören (z. B. das Datum, an dem eine Beziehung hergestellt wurde).
4. Umgang mit historischen Daten
Refactoring verändert die Datenspeicherung oft. Historische Aufzeichnungen müssen genau erhalten bleiben.
- Löschen Sie alte Daten nicht einfach. Sie können für Prüfungsprotokolle oder rechtliche Vorgaben erforderlich sein.
- Verwenden Sie Migrierungsskripte, um bestehende Daten in das neue Format zu transformieren, bevor Sie die Anwendungskonfiguration wechseln.
- Archivieren Sie alte Tabellen, wenn sie nicht mehr benötigt werden, aber zur Aufzeichnungspflicht beibehalten werden müssen.
✅ Sicherstellen der Datenintegrität
Während der Transformation ist das Risiko von Datenkorruption am höchsten. Integritätsbeschränkungen sind Ihre Sicherheitsnetz.
1. Fremdschlüsselbeschränkungen
Stellen Sie die Referenzintegrität auf Datenbankebene sicher. Dies verhindert verwaiste Datensätze, bei denen ein Kind-Datensatz auf ein Eltern-Datensatz verweist, das nicht mehr existiert.
- Aktivieren
CASCADEAktualisierungen oder Löschungen nur dort, wo logisch notwendig. - Verwenden Sie
RESTRICToderKEINE Aktionum Änderungen zu blockieren, die Beziehungen zerstören würden.
2. Transaktionsverwaltung
Umgeben Sie alle Migrationsschritte mit Transaktionen. Dadurch wird sichergestellt, dass entweder alle Änderungen angewendet werden oder gar keine. Teilweise Updates führen zu inkonsistenten Zuständen.
- Starten Sie eine Transaktion vor dem ersten DDL-Befehl.
- Führen Sie einen Commit erst aus, nachdem alle Überprüfungen bestanden wurden.
- Rollen Sie sofort zurück, wenn ein Fehler auftritt.
3. Skripte zur Datenüberprüfung
Führen Sie nach der Migration Skripte aus, um die Daten zu überprüfen.
- Vergleichen Sie die Zeilenanzahlen zwischen der alten und der neuen Tabelle.
- Berechnen Sie Prüfsummen für kritische Spalten, um exakte Übereinstimmungen sicherzustellen.
- Überprüfen Sie auf NULL-Werte in Spalten, die zuvor nicht NULL-Werte zuließen.
- Stellen Sie sicher, dass alle eindeutigen Einschränkungen erfüllt sind.
⚠️ Häufige Fallen und Lösungen
Selbst bei sorgfältiger Planung können Probleme auftreten. Die Vorhersehung dieser Probleme reduziert die Ausfallzeiten.
1. Das „Split“-Problem
Beim Aufteilen einer Tabelle können Sie auf doppelte Schlüssel stoßen. Wenn ein zusammengesetzter Schlüssel aufgeteilt wird, stellen Sie sicher, dass die neuen Schlüssel die Eindeutigkeit innerhalb der neuen Struktur bewahren.
- Lösung: Verwenden Sie temporäre Staging-Tabellen, um die Daten vor der Anwendung des neuen Schemas neu zu organisieren.
2. Indexleistung
Neue Beziehungen erfordern neue Indizes. Ohne sie werden Abfragen auf den neuen Verknüpfungstabellen langsam sein.
- Lösung: Erstellen Sie Indizes für Fremdschlüsselspalten unmittelbar nach deren Erstellung. Verlassen Sie sich nicht allein auf den Primärschlüsselindex.
3. Abweichung im Anwendungscode
Die Datenbank ändert sich, aber der Anwendungscode wird nicht sofort aktualisiert. Dies führt zu Laufzeitfehlern.
- Lösung: Implementieren Sie während der Übergangsphase eine Feature-Flag- oder Dual-Write-Strategie. Erlauben Sie es, dass alte und neue Schemata kurzzeitig nebeneinander existieren.
4. Datentypen-Abweichungen
Beim Refactoring geht es oft darum, Datentypen zu ändern (z. B. VARCHAR in INT). Wenn die Daten in einem Feld, das konvertiert wird, nicht-numerische Zeichen enthalten, schlägt die Migration fehl.
- Lösung: Bereinigen Sie die Daten in einem Vor-Migrations-Schritt. Erstellen Sie eine Liste ungültiger Daten für die manuelle Überprüfung.
🚀 Nach dem Refactoring-Validierung
Die Arbeit ist nicht getan, wenn der Migrations-Skript abgeschlossen ist. Das System muss in einer Produktions-ähnlichen Umgebung validiert werden.
- Leistungsbenchmarking: Führen Sie dieselbe Reihe von Abfragen aus, die beim Baseline-Check verwendet wurden. Vergleichen Sie Ausführungszeiten und Ressourcenverbrauch.
- Benutzerakzeptanztest: Lassen Sie Anwendungsnutzer Standardarbeitsabläufe durchführen, um sicherzustellen, dass die Daten korrekt in der Benutzeroberfläche angezeigt werden.
- Überwachungseinrichtung: Aktivieren Sie erweiterte Protokollierung und Überwachung für die beteiligten Tabellen. Achten Sie auf Fehler-Spitzen oder Latenzsteigerungen.
- Dokumentationsaktualisierung: Aktualisieren Sie die ERD-Diagramme, Datenwörterbücher und API-Dokumentation, um die neue Struktur widerzuspiegeln.
📝 Risikobewertungsmatrix
| Risikofaktor | Auswirkung | Minderungsstrategie |
|---|---|---|
| Unerwarteter Datenverlust | Kritisch | Sicherungen vor Beginn überprüfen; Transaktionen verwenden |
| Ausfallzeit | Hoch | Während Wartungszeiten planen; Blue-Green-Deployment verwenden |
| Leistungsverschlechterung | Mittel | Mit Daten in Produktionsgröße testen; Indizes optimieren |
| Anwendungsabbruch | Hoch | Feature-Flags; schrittweise Einführung |
Das Refactoring eines Entity-Relationship-Diagramms ist eine disziplinierte ingenieurtechnische Aufgabe. Es erfordert ein Gleichgewicht zwischen theoretischen Prinzipien der Datenmodellierung und praktischen operativen Beschränkungen. Durch die Einhaltung eines strukturierten Ansatzes, die strikte Durchführung von Datenintegritätsprüfungen und eine gründliche Vorbereitung auf den Übergang können Sie Ihre Datenarchitektur modernisieren, ohne die Zuverlässigkeit Ihrer Informationsressourcen zu gefährden.
Die Komplexität moderner Systeme verlangt von uns, wachsam zu bleiben. Regelmäßige Überprüfungen des ERD sollten Teil des Entwicklungszyklus sein, um zu verhindern, dass Überwucherung erneut zu einem kritischen Problem wird. Behandeln Sie das Schema als kritischen Bestandteil der Infrastruktur der Anwendung, der ebenso viel Sorgfalt und Aufmerksamkeit verdient wie der Code selbst.
Erfolg bei dieser Aufgabe wird an der Stabilität des Systems nach der Migration und der weiterhin korrekten Datenhaltung gemessen. Mit Geduld und Genauigkeit ist der Weg zu einer saubereren, effizienteren Datenbankstruktur erreichbar.